1. STANDARD SQL 개요
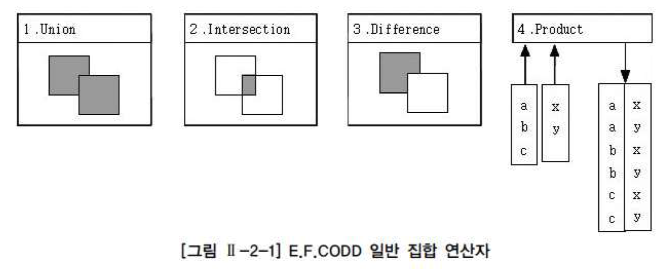
가. 일반 집합 연산자
현재 사용하는 SQL의 많은 기능이 관계형 데이터베이스의 이론을 수립한 E.F.Codd 박사의 논문에 언급이 되어 있다.
논문에 언급된 8가지 관계형 대수는 다시 각각 4개의 일반 집합 연산자와 순수 관계 연산자로 나눌 수 있으며, 관계형 데이터베이스 엔진 및 SQL의 기반 이론이 되었다.
일반 집합 연산자를 현재의 SQL과 비교하면
- UNION 연산은 UNION
- INTERSECTION 연산은 INTERSECT
- DIFFERENCE 연산은 EXCEPT(Oracle은 MINUS)
- PRODUCT 연산은 CROSS JOIN
UNION
-
UNION
수학적 합집합을 제공하기 위해, 공통 교집합의 중복을 없애기 위한 사전 작업으로 시스템에 부하를 주는 정렬 작업이 발생한다. -
UNION ALL
UNION 이후 기능이 추가되었는데, 특별한 요구 사항이 없다면 공통집합을 중복해서 그대로 보여 주기 때문에 정렬 작업이 일어나지 않는 장점을 가진다. -
UNION과 UNION ALL의 출력 결과가 같다면
응답 속도 향상이나 자원 효율화 측면에서 데이터 정렬 작업이 발생하지 않는 UNION ALL을 사용하는 것을 권고한다.
INTERSECTION
수학의 교집합으로써 두 집합의 공통집합을 추출한다.
DIFFERNECE
수학의 차집합으로써 첫 번째 집합에서 두 번째 집합과의 공통 집합을 제외한 부분이다.
대다수 벤더는 EXCEPT를, Oracle은 MINUS 용어를 사용한다.
PRODUCT
CROSS PRODUCT라고 불리는 곱집합으로, JOIN 조건이 없는 경우 생길 수 있는 모든 데이터의 조합을 말한다. 양쪽 집합의 M*N건의 데이터 조합이 발생하며, CARTESIAN(수학자 이름) PRODUCT라고도 표현한다.
나. 순수 관계 연산자
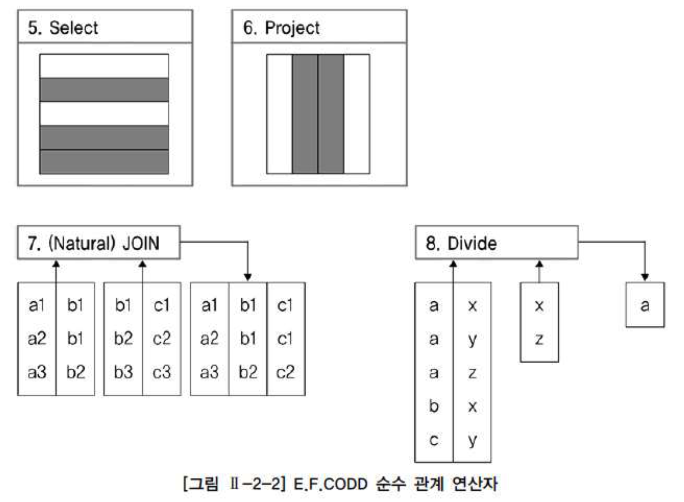
순수 관계 연산자는 관계형 데이터베이스를 구현하기 위해 새롭게 만들어진 연산자이다.
순수 관계 연산자를 현재의 SQL 문장과 비교하면 다음과 같다.
- SELECT 연산은 WHERE 절로 구현
- PROJECT 연산은 SELECT 절로 구현
- (NATURAL) JOIN 연산은 다양한 JOIN 기능으로 구현
DIVIDE 연산은 현재 사용되지 않는다.
SELECT
SQL 문장에서는 WHERE 절의 조건절 기능으로 구현이 되었다.
(SELECT 연산과 SELECT 절의 의미가 다름을 유의)
PROJECT
SQL 문장에서는 SELECT 절의 칼럼 선택 기능으로 구현이 되었다.
JOIN
WHERE 절의 INNER JOIN 조건과 함께 FROM 절의 NATURAL JOIN, INNER JOIN, OUTER JOIN, USING 조건절, ON 조건절 등으로 가장 다양하게 발전하였다.
DIVIDE
나눗셈과 비슷한 개념으로 왼쪽의 집합을 'XZ'로 나누었을 때, 'XZ'를 모두 가지고 있는 'A'가 답이 되는 기능이다. 현재 사용되지 않는다.
관계형 데이터베이스의 경우 요구사항 분석, 개념적 데이터 모델링, 논리적 데이터 모델링, 물리적 데이터 모델링 단계를 거치게 되는데, 이 단계에서 엔티티 확정 및 정규화 과정, 그리고 M:M (다대다) 관계를 분해하는 절차를 거치게 된다.
특히 정규화 과정의 경우 데이터 정합성과 데이터 저장 공간의 절약을 위해 엔티티를 최대한 분리하는 작업으로, 일반적으로 3차 정규형이나 보이스코드 정규형까지 진행하게 된다.
이런 정규화를 거치면 하나의 주제에 관련 있는 엔티티가 여러 개로 나누어지게 되고, 이 엔티티들이 주로 테이블이 되는데 이렇게 흩어진 데이터를 연결해서 원하는 데이터를 가져오는 작업이 바로 JOIN이라고 할 수 있다.
2. FROM 절 JOIN 형태
ANSI/ISO SQL에서 표시하는 FROM 절의 JOIN 형태는 다음과 같다.
- INNER JOIN
- NATURAL JOIN
- USING 조건절
- ON 조건절
- CROSS JOIN
- OUTER JOIN
ANSI/ISO SQL에서 규정한 JOIN 문법은 WHERE 절을 사용하던 기존 JOIN 방식과 차이가 있다. 사용자는 기존 WHERE 절의 검색 조건과 테이블 간의 JOIN 조건을 구분 없이 사용하던 방식을 그대로 사용할 수 있으면서, 추가된 선택 기능으로 테이블 간의 JOIN 조건을 FROM 절에서 명시적으로 정의할 수 있게 되었다.
INNER JOIN은 WHERE 절에서부터 사용하던 JOIN의 DEFAULT 옵션으로 JOIN 조건에서 동일한 값이 있는 행만 반환한다. DEFAULT 옵션이므로 생략이 가능하지만, CROSS JOIN, OUTER JOIN과는 같이 사용할 수 없다.
NATURAL JOIN은 INNER JOIN의 하위 개념으로 NATURAL JOIN은 두 테이블 간의 동일한 이름을 갖는 모든 칼럼들에 대해 EQUI(=) JOIN을 수행한다. NATURAL INNER JOIN이라고도 표시할 수 있으며, 결과는 NATURAL JOIN과 같다.
새로운 SQL JOIN 문장 중에서 가장 중요하게 기억해야 하는 문장은 ON 조건절을 사용하는 경우이다. 과거 WHERE 절에서 JOIN 조건과 데이터 검증 조건이 같이 사용되어 용도가 불분명한 경우가 발생할 수 있었는데, WHERE 절의 JOIN 조건을 FROM 절의 ON 조건 절로 분리하여 표시함으로써 사용자가 이해하기 쉽도록 한다.
ON 조건절의 경우 NATURAL JOIN처럼 JOIN 조건이 숨어있지 않고, 명시적으로 JOIN 조건을 구분할 수 있고, NATURAL JOIN이나 USING 조건절처럼 칼럼명이 똑같아야 된다는 제약 없이 칼럼명이 상호 다르더라도 JOIN 조건으로 사용할 수 있으므로 앞으로 가장 많이 사용될 것으로 예상된다.
다만, FROM 절에 테이블이 많이 사용될 경우 다소 복잡하게 보여 가독성이 떨어지는 단점이 있다.
그런 측면에서 SQL Server의 경우 ON 조건절만 지원하고 NATURAL JOIN과 USING 조건절을 지원하지 않고 있는 것으로 보인다.
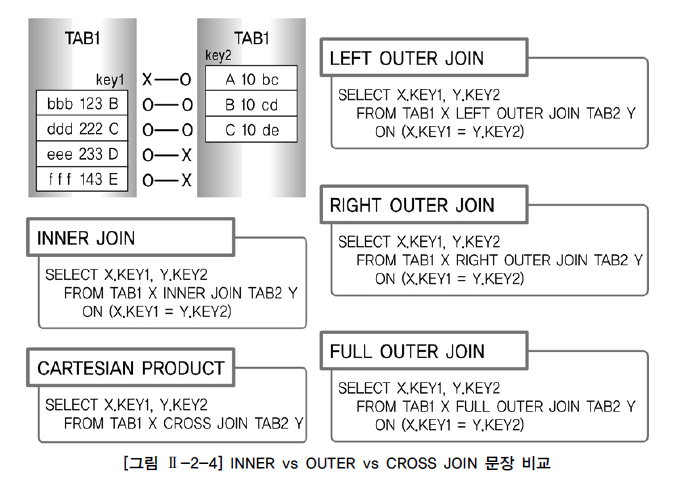
3. INNER JOIN
INNER JOIN은 OUTER(외부) JOIN과 대비하여 내부 JOIN이라고 하며 JOIN 조건에서 동일한 값이 있는 행만 반환한다. INNER JOIN 표시는 그 동안 WHERE 절에서 사용하던 JOIN 조건을 FROM 절에서 정의하겠다는 표시이므로 USING 조건절이나 ON 조건절을 필수적으로 사용해야 한다.
WHERE 절 JOIN 조건
SELECT EMP.DEPTNO, EMPNO, ENAME, DNAME
FROM EMP, DEPT
WHERE EMP.DEPTNO = DEPT.DEPTNO;
FROM 절 JOIN 조건
SELECT EMP.DEPTNO, EMPNO, ENAME, DNAME
FROM EMP INNER JOIN DEPT
ON EMP.DEPTNO = DEPT.DEPTNO;
INNER는 JOIN의 디폴트 옵션이므로 생략 가능하다.
SELECT EMP.DEPTNO, EMPNO, ENAME, DNAME
FROM EMP JOIN DEPT
ON EMP.DEPTNO = DEPT.DEPTNO; 4. NATURAL JOIN
NATURAL JOIN은 두 테이블 간의 동일한 이름을 갖는 모든 칼럼들에 대해 EQUI(=) JOIN을 수행한다. NATURAL JOIN이 명시되면, 추가로 USING 조건절, ON 조건절, WHERE 절에서 JOIN 조건을 정의할 수 없다. 그리고 SQL Server에서는 지원하지 않는 기능이다.
SELECT DEPTNO, EMPNO, ENAME, DNAME
FROM EMP NATURAL JOIN DEPT;별도의 JOIN 칼럼을 지정하지 않았지만, 두 개의 테이블에서 DEPTNO라는 공통된 칼럼을 자동으로 인식하여 JOIN을 처리한 것이다. JOIN에 사용된 칼럼들은 같은 데이터 유형이어야 하며, ALIAS나 테이블 명과 같은 접두사를 붙일 수 없다.
NATURAL JOIN은 JOIN이 되는 테이블의 데이터 성격(도메인)과 칼럼명 등이 동일해야 하는 제약 조건이 있다. 간혹 모델링 상의 부주의로 인해 동일한 칼럼명이라도 다른 용도의 데이터를 저장하는 경우도 있으므로 주의해서 사용해야 한다.
'*' 와일드카드처럼 별도의 칼럼 순서를 지정하지 않으면 NATURAL JOIN의 기준이 되는 칼럼 들이 다른 칼럼보다 먼저 출력된다.
5. USING 조건절
NATURAL JOIN에서는 모든 일치되는 칼럼들에 대해 JOIN이 이루어지지만, FROM 절의 USING 조건절을 이용하면 같은 이름을 가진 칼럼들 중에서 원하는 칼럼에 대해서만 선택적으로 EQUI JOIN을 할 수가 있다. 다만, 이 기능은 SQL Server에서는 지원하지 않는다.
6. ON 조건절
JOIN 서술부(ON 조건절)와 비 JOIN 서술부(WHERE 조건절)를 분리하여 이해가 쉬우며, 칼럼명이 다르더라도 JOIN 조건을 사용할 수 있는 장점이 있다.
NATURAL JOIN의 JOIN 조건은 기본적으로 같은 이름을 가진 모든 칼럼들에 대한 동등 조건이지만, 임의의 JOIN 조건을 지정하거나, 이름이 다른 칼럼명을 JOIN 조건으로 사용하거나, JOIN 칼럼을 명시하기 위해서는 ON 조건절을 사용한다.
USING 조건절을 이용한 JOIN에서는 JOIN 칼럼에 대해서 ALIAS나 테이블 명과 같은 접두사를 사용하면 SYNTAX 에러가 발생하지만, 반대로 ON 조건절을 사용한 JOIN의 경우는 ALIAS나 테이블 명과 같은 접두사를 사용하여 SELECT에 사용되는 칼럼을 논리적으로 명확하게 지정해주어야 한다. (DEPTNO → E.DEPTNO)
가. WHERE 절과의 혼용
ON 조건절과 WHERE 검색 조건은 충돌 없이 사용할 수 있다.
SELECT
E.ENAME,
E.DEPTNO,
D.DEPTNO,
D.DNAME
FROM EMP E
JOIN DEPT D
ON E.DEPTNO = D.DEPTNO
WHERE E.DEPTNO = 30;나. ON 조건절 + 데이터 검증 조건 추가
ON 조건절에 JOIN 조건 외에도 데이터 검색 조건을 추가할 수는 있으나, 검색 조건 목적인 경우 WHERE 절을 사용할 것을 권고한다. (다만, 아우터 조인에서 조인의 대상을 제한하기 위한 목적으로 사용되는 추가 조건의 경우는 ON 절에 표기되어야 한다.)
-- ON절 내 데이터 검색 조건 작성
SELECT
E.ENAME,
E.MGR,
D.DEPTNO,
D.DNAME
FROM EMP E
JOIN DEPT D
ON E.DEPTNO= D.DEPTNO
AND E.MGR = 7698;
-- WHERE절 내 데이터 검색 조건 작성
SELECT
E.ENAME,
E.MGR,
D.DEPTNO,
D.DNAME
FROM EMP E
JOIN DEPT D
ON E.DEPTNO= D.DEPTNO
WHERE E.MGR = 7698;다. ON 조건절 예제
SELECT
TEAM_NAME,
TEAM_STADIUM_ID,
STADIUM_NAME
FROM TEAM
JOIN STADIUM
ON TEAM.STADIUM_ID = STADIUM.STADIUM_ID
ORDER BY STADIUM_ID;
-- STADIUM_ID라는 공통된 칼럼이 있기 때문에 USING 조건절로 구현 가능
SELECT
TEAM_NAME,
TEAM_STADIUM_ID,
STADIUM_NAME
FROM TEAM
JOIN STADIUM
USING(STADIUM_ID)
ORDER BY STADIUM_ID;
-- WHERE 절로 구현 가능
SELECT
TEAM_NAME,
TEAM_STADIUM_ID,
STADIUM_NAME
FROM
TEAM,
STADIUM
WHERE TEAM.STADIUM_ID = STADIUM.STADIUM_ID
ORDER BY STADIUM_ID;라. 다중 테이블 JOIN
SELECT
E.EMPNO,
D.DEPTNO,
D.DNAME,
T.DNAME New_DNAME
FROM EMP E
JOIN DEPT D
ON E.DEPTNO = D.DEPTNO
JOIN DEPT_TEMP T
ON E.DEPTNO = T.DEPTNO;
-- WHERE 절로 구현 가능
SELECT
E.EMPNO,
D.DEPTNO,
D.DNAME,
T.DNAME New_DNAME
FROM
EMP E,
DEPT D,
DEPT_TEMP T
WHERE E.DEPTNO = D.DEPTNO
AND E.DEPTNO = T.DEPTNO;7. CROSS JOIN
CROSS JOIN은 E.F.CODD 박사가 언급한 일반 집합 연산자의 PRODUCT의 개념으로 테이블 간 JOIN 조건이 없는 경우 생길 수 있는 모든 데이터의 조합을 말한다.
두 개의 테이블에 대한 CARTESIAN PRODUCT 또는 CROSS PRODUCT와 같은 표현으로, 결과는 양쪽 집합의 M*N 건의 데이터 조합이 발생한다.
sssssssssssssssssssssss
SELECT
ENAME,
DNAME
FROM EMP
CROSS JOIN DEPT
ORDER BY ENAME;
NATURAL JOIN의 경우 WHERE 절에서 JOIN 조건을 추가할 수 없지만, CROSS JOIN의 경우 WHERE 절에 JOIN 조건을 추가할 수 있다. 그러나, 이 경우는 CROSS JOIN이 아니라 INNER JOIN과 같은 결과를 얻기 때문에 CROSS JOIN을 사용하는 의미가 없어지므로 권고하지 않는다.
정상적인 데이터 모델이라면 CROSS PRODUCT가 필요한 경우는 많지 않지만, 간혹 튜닝이나 리포트를 작성하기 위해 고의적으로 사용하는 경우가 있을 수 있다. 그리고 데이터 웨어하우스의 개별 DIMENSION(차원)을 FACT(사실) 칼럼과 JOIN하기 전에 모든 DIMENSION의 CROSS PRODUCT를 먼저 구할 때 유용하게 사용할 수 있다.
8. OUTER JOIN
INNER JOIN과 대비하여 OUTER JOIN이라고 불리며, JOIN 조건에서 동일한 값이 없는 행도 반환할 때 사용할 수 있다.
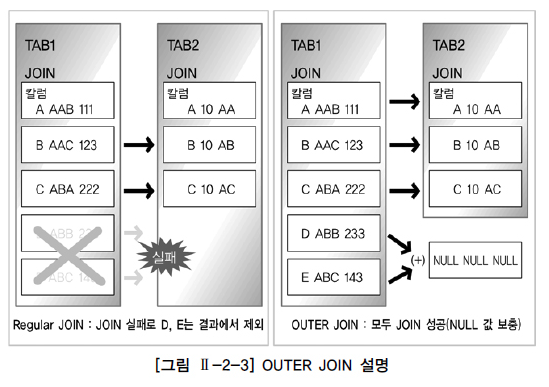
TAB1 테이블이 TAB2 테이블을 JOIN 하되, TAB2의 JOIN 데이터가 있는 경우는 TAB2의 데이터를 함께 출력하고, TAB2의 JOIN 데이터가 없는 경우에도 TAB1의 모든 데이터를 표시하고 싶은 경우이다.
TAB1의 모든 값에 대해 TAB2의 데이터가 반드시 존재한다는 보장이 없는 경우 OUTER JOIN을 사용하여 해결이 가능하다.
LEFT/RIGHT OUTER JOIN의 경우에는 기준이 되는 테이블이 조인 수행시 무조건 드라이빙 테이블이 된다. 옵티마이저는 이 원칙에 위배되는 다른 실행계획을 고려하지 않는다.
가. LEFT OUTER JOIN
조인 수행시 먼저 표기된 좌측 테이블에 해당하는 데이터를 먼저 읽은 후, 나중 표기된 우측 테이블에서 JOIN 대상 데이터를 읽어 온다.
즉, Table A와 B가 있을 때(Table 'A'가 기준이 됨), A와 B를 비교해서 B의 JOIN 칼럼에서 같은 값이 있을 때 그 해당 데이터를 가져오고, B의 JOIN 칼럼에서 같은 값이 없는 경우에는 B 테이블에서 가져오는 칼럼들은 NULL 값으로 채운다.
SELECT
STADIUM_NAME,
STADIUM.STADIUM_ID,
SEAT_COUNT,
HOMETEAM_ID,
TEAM_NAME
FROM STADIUM
LEFT OUTER JOIN TEAM
ON STADIUM.HOMETEAM_ID = TEAM.TEAM_ID
ORDER BY HOMETEAM_ID;INNER JOIN이라면 홈팀이 배정된 경기장만 출력 되었겠지만, LEFT OUTER JOIN을 사용하였기 때문에 홈팀이 없는 정보가 있다면 그 정보까지 추가로 출력된다.
나. RIGHT OUTER JOIN
조인 수행시 LEFT JOIN과 반대로 우측 테이블이 기준이 되어 결과를 생성한다.
즉, TABLE A와 B가 있을 때(TABLE 'B'가 기준이 됨), A와 B를 비교해서 A의 JOIN 칼럼에서 같은 값이 있을 때 그 해당 데이터를 가져오고, A의 JOIN 칼럼에서 같은 값이 없는 경우에는 A 테이블에서 가져오는 칼럼들은 NULL 값으로 채운다.
SELECT
E.ENAME,
D.DEPTNO,
D.DNAME
FROM EMP E
RIGHT OUTER JOIN DEPT D
ON E.DEPTNO = D.DEPTNO;다. FULL OUTER JOIN
조인 수행시 좌측, 우측 테이블의 모든 데이터를 읽어 JOIN하여 결과를 생성한다.
즉, TABLE A와 B가 있을 때(TABLE 'A', 'B' 모두 기준이 됨), RIGTH OUTER JOIN과 LEFT OUTER JOIN의 결과를 합집합으로 처리한 결과와 동일하다. 단, UNION ALL이 아닌 UNION 기능과 같으므로 중복되는 데이터는 삭제한다.
SELECT *
FROM DEPT
FULL OUTER JOIN DEPT_TEMP
ON DEPT.DEPTNO = DEPT_TEMP.DEPTNO;9. INNER vs OUTER vs CROSS JOIN 비교