tokenizer, lexer, parser란?
이 세개는 AST (Abstract Syntax Tree) 를 만들기 위한 개념이다.
-
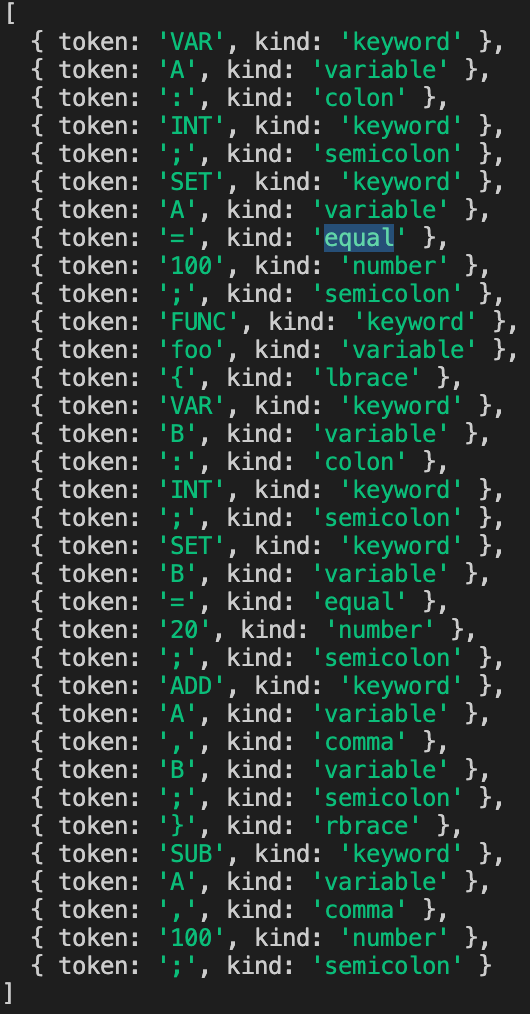
tokenizer: 문장을 경계로 나눠 토큰으로 변환한다 ( Ex- 공백, 엔터, 탭)
변환된 토큰은 아래와 같은 모양을 가진다.

-
lexer: 변환한 토큰에 의미를 부여한다.
- 예를들어 예약어는 reserved, 변수는 variable 등의 의미를 부여해준다.
-
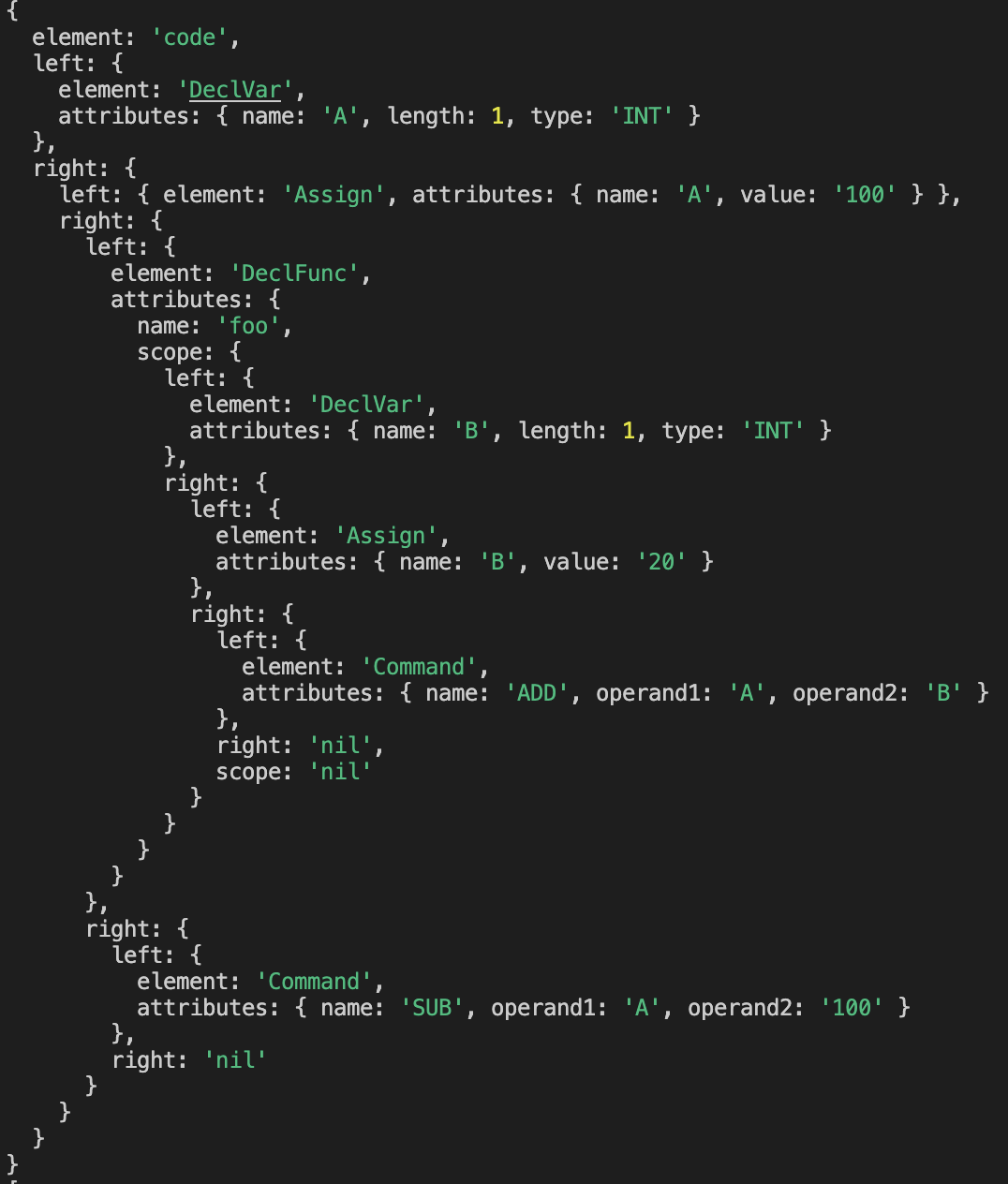
parser: 최종적으로 의미가 부여된 토큰을 가지고 AST를 생성한다.
이렇게 어렵게 만든 AST는 어디에 쓰일까?
AST ( 추상 구문 트리 )
컴퓨터 과학에서 추상 구문 트리, 또는 간단히 구문 트리는 프로그래밍 언어로 작성된 소스 코드의 추상 구문 구조의 트리이다. 이 트리의 각 노드는 소스 코드에서 발생되는 구조를 나타낸다.
https://ko.wikipedia.org/wiki/%EC%B6%94%EC%83%81_%EA%B5%AC%EB%AC%B8_%ED%8A%B8%EB%A6%AC
이게 중요한 이유는 자바스크립트 동작 원리와 깊게 관련이 있기떄문이다.
자바스크립트로 코드를 작성해서 웹 혹은 nodejs 환경에서 실행을 하면 파싱을해서 트리를 만든다.
종류는 2가지인데 DOM 트리와 CSS 돔트리다.
DOM 트리는 웹페이지에 보여지는 태그들의 구조를 나타내고, CSS 돔트리는 그 트리의 스타일을 나타낸다.
그 후 이 둘을 가지고 렌더트리를 생성한다.
근데 만약 HTML 파싱 도중에 CSS를 파싱하게 된다면 CSSDOM 생성 후 HTML 파싱이 진행된다.
그래서 html 파일을 작성할 때에 맨 위에 style을 전부 작성해두는것이다.
그러고서 JS를만나게 되면 제어권을 JS 엔진에게 넘겨준 후 JS파싱으로 들어간다.
여기서 중간레벨의 코드인 AST가 생성되며 이를 가지고 레이아웃 계산 후 페인팅을 한다.
참고로 전부 그려진 이후에 다시 레이아웃이 계산되면 리플로우 + 리페인트가 일어나고
만약 색상등만 바뀌면 리페인트가 일어난다.
리페인팅은 돔트리를 바꿔버리므로 비용이 비싸고, 리페인트는 상대적으로 그 비용이 낮다.
그러므로 css 속성을 변경할 때 이를 신경써서 변경해 줘야 한다.
regexp
파싱은 해봤어도 AST를 만든적은 없어서 어떻게 만들지 처음에 정말 많이 고민했다.
토큰을 어떤 식으로 만들지가 고민의 시작이었다.
토큰은 금방 만들었다. 화면상에 있는 모든 문자를 공백 혹은 의미있는 기호로 나누면 됐기 때문이다.
그런데 여기서 의미를 어떤식으로 부여해줘야 할지 몰라서 다른 사례들을 많이 찾아봤다.
그런데 이건 더 별거 없었다 ㅋㅋㅋㅋㅋㅋㅋㅋ
그냥 만든 토큰에서 공백을 제외하고 문자들이 어떤건지 어떻게 쓰일건지 적어주면 됐다.
처음에는 정규식을 사용해서 문자를 한칸씩 읽어들여 맞는게 있는지 확인해볼려 했다.
그래서 아래와 같은 정규식부터 만들었다.
const SC = {
whitespace0: "( |\t|\n){0,}",
whitespace1: "( |\t|\n){1,}",
colon: ":",
comma: ",",
equal: "=",
lbrace: "{",
rbrace: "}",
semicolon: ";",
number: "[1-9][\\d]{0,}",
keyword: "(VAR|SET|FUNC|ADD|SUB|INT|FLOAT)",
variable: "([A-Za-z][A-Za-z\\d_]{0,}){1,}",
};
const regs = {
VAR: `^VAR${SC.whitespace1}${SC.variable}${SC.whitespace0}${SC.colon}${SC.whitespace0}${SC.keyword}$`,
SET: `^SET${SC.whitespace1}${SC.variable}${SC.whitespace0}${SC.equal}${SC.whitespace0}(${SC.variable}|${SC.number})$`,
ADD: `^ADD${SC.whitespace1}${SC.variable}${SC.whitespace0}${SC.comma}${SC.whitespace0}(${SC.variable}|${SC.number})$`,
SUB: `^SUB${SC.whitespace1}${SC.variable}${SC.whitespace0}${SC.comma}${SC.whitespace0}(${SC.variable}|${SC.number})$`,
};RegExp의 test 메소드를 쓸 생각으로 저렇게 만들었었는데 결국 관짝으로 들어갔다...
토큰을 분리해서 의미를 부여해준 시점에서 쓸모가 없었기 때문이다.
tokonizer와 lexer로 토큰을 만들고 의미를 부여했으니 이제 ast를 만들 차례다.
원래 재귀로 만들려 했는데 스택을 사용해야 한다고 해서 정말 이것때문에 쓸데없이 더 고민을했다.
근데 계속 고민하다 결국 재귀도 콜스택이 쌓이니까 스택은 이런식으로 구현하는걸 말헀던것같다.
ast는 이진트리로 생성된다. 왼쪽에는 어떤 값이 있고, 오른쪽에는 다음 노드에 대한 정보만 있다.
그래서 이걸 구현하는 방법은 아래와 같았다.
- 왼쪽 노드에 현재 토큰을 채워준다.
- 오른쪽 노드에 빈값을 채워준다.
- 오른쪽 노드로 이동한다.
- 1 ~ 3까지 모든 토큰을 사용할 때 까지 반복한다.
아이디어는 짧았지만 구현은 생각보다 오래 걸렸다.
예외처리 때문이다.
변수명, 세미콜론, 괄호 여닫기 이부분 예외처리에 시간을 많이 썼다.
변수명 예외처리는 어떤 예약어를 만났을 떄 바로 다음에 변수명이 오니까 이걸 체크해줬다.
세미콜론도 예약어를 만났을 때 그 끝에 세미콜론이 있는지 체크해줬다.
마지막으로 괄호 여닫기는 { 를 만났을 때 count++ 해주고 } 를 만났을 떄 count--를 해줬다.
그러고서 모든 토큰을 사용했을 때 count가 0이면 예외가 발생한 것이다.
json과 xml
json은 텍스트 기반의 오브젝트 표현 방법이고 키, 값을 쌍으로 가지고 있다.
xml은 다목적 마크업 언어이다.
그리고 이둘은 모두 데이터를 전송할 때 사용될 수 있다. 데이터 전송을 위해 고안됐기 때문이다. 그래서 기계뿐 아니라 사람도 쉽게 읽을수가 있다.
차이점은 xml은 닫는 태그를 사용해야 하므로 json보다 길고, xml 분석은 json보다 느리다는 점이다. 그리고 xml은 보안에서도 json보다 취약한점이 많다.
그래서 요즘 api로 데이터를 받는곳들을 보면 예전보다 확실히 json으로 보내는곳이 많은것같다.
그리고 xml 문법을 지킨 문서를 well-formed xml이라 한다. 비슷한것으로 valid xml document가 있는데 well-formed xml에 더해 dtd, xml schema 등으로 정의된 문서의 구조까지 지킨 문서다.
만약 well-formed 하지 않다면 xml parser는 fartal 에러를 방생시키고 파싱을 중단한다.
또, 문법은 지켜졌지만 dtd, xml schema등으로 정의된 문서의 구조를 지키지 않았다면 그냥 에러를 발생시키고 끝까지 파싱은 진행한다.
- DTD: 작성하는 문서가 어떤 문서인지 정의하는것, xml 데이터 구조를 정의해 유효성 점검할 때 사용
<?xml version="1.0" encoding="UTF-8" standalone="yes" ?> - xml schema: xml 문서의 구조, 엘리먼트, 속성들의 관계를 정의해 다양한 자료형을 사용할 수 있도록 정의된 문서.
오늘을 마치며
오늘은 확실히 어제에 비해서 시간 관리를 잘했다고 느꼈다.
어제는 학습은 뒤로 미루고 구현에 온 힘을 다 쏟아서 결국 이도저도 못했기 때문이다.
근데 오늘은 학습할것도 다 하고 구현할것도 다 해서 뿌듯하다.
하지만 결국 시간을 오버해서 구현을 다 했다...
앞으로는 설계에 더 힘을 써서 구현 시간도 줄여보자!!!!
끗
