1. 프로세스
프로세스 = 실행중인 프로그램 인스턴스
프로세스와 프로그램이 헷갈릴수도 있는데 프로그램은 hdd 혹은 ssd같은 보조 메모리에 저장된 기계어를 칭하는 말입니다. 그리고 이 프로그램이 구동되면 주 메모리인 ram에 올라갑니다. 이 때 메모리에서 실행되는 작업의 단위를 프로세스라고 합니다. 프로세스는 작업(Task) 라고 부르기도 합니다.
이렇게 아래처럼 메모리 위에 올라간 녀석들이 전부 프로세스입니다.
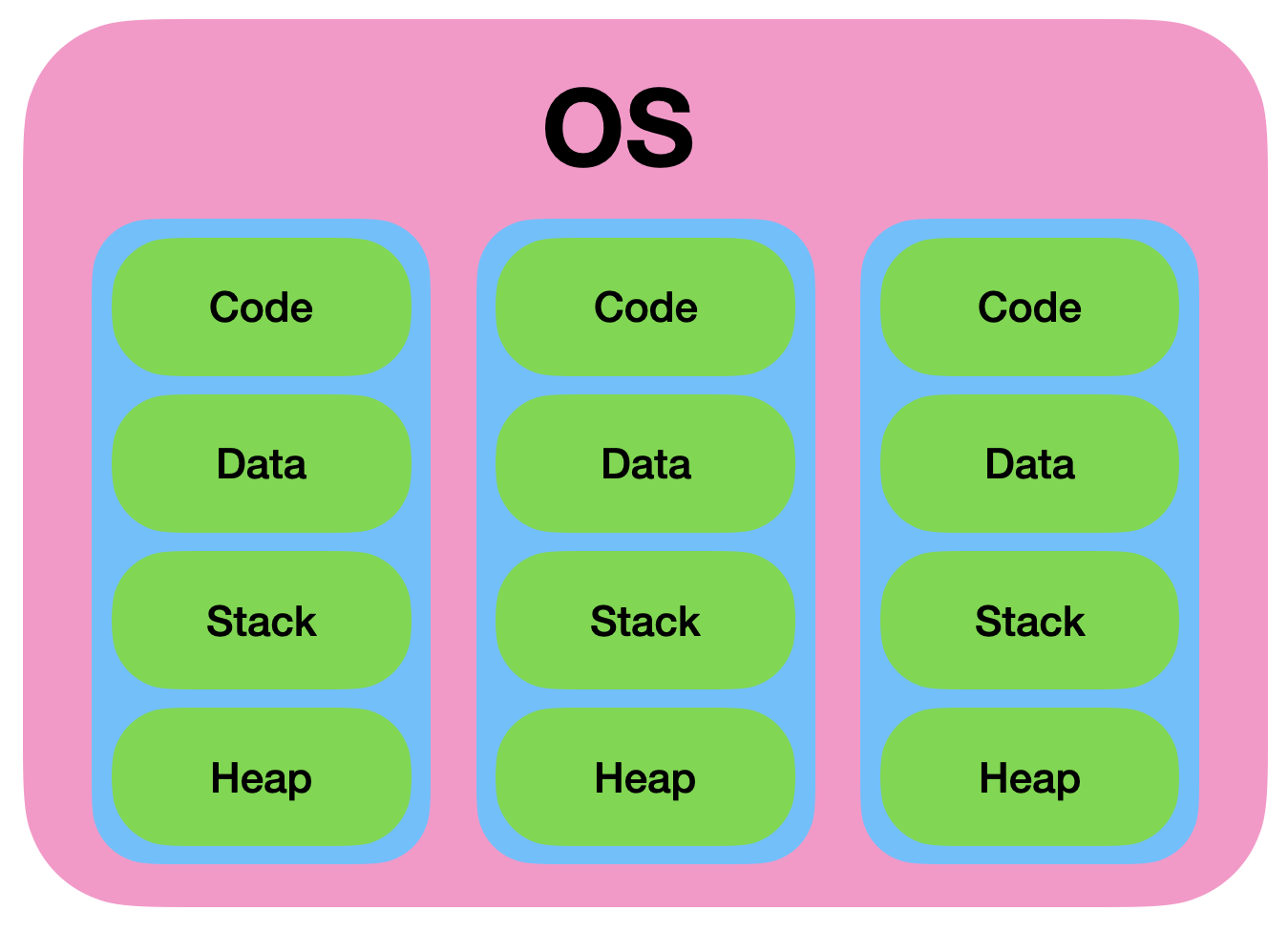
그리고 프로세스는 code, data, stack, heap 등의 구조가 독립되어 있습니다.
그래서 한 프로세스는 다른 프로세스의 변수나 자료구조에 접근할 수가 없습니다.
만약 접근을 하고싶다면 IPC(Inter Process Communication)을 사용해야 합니다.
IPC에는 소켓, 파일, 파이프 등을 이용한 통신방법이 있습니다.
상태
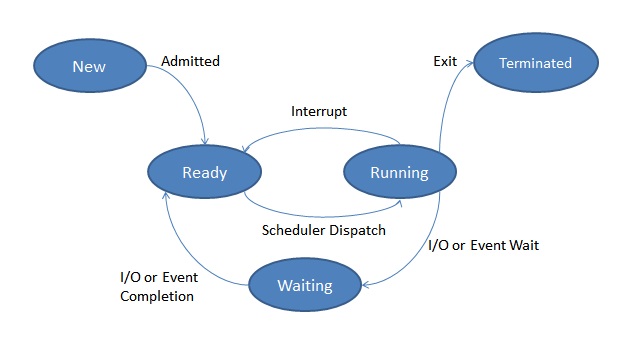
상태의 종류는 크게 new, ready, wait, run, exit이 있고, new는 생성할 때의 상태입니다.
- new(생성): 프로세스가 생성만 됐고, 메모리에 적재되지 않았습니다.
- read(준비): 실행된 프로세스가 메모리에 적제되고, cpu할당을 기다리는 중입니다.
- run(실행): 프로세스가 cpu를 할당 받아 명령어를 실행중 입니다.
- wait(block, 대기): 실행중이던 프로세스가 인터럽트에 의해 실행을 일시적으로 멈춘 상태입니다.
- exit(terminated, 종료): 프로세스가 성공적으로 끝나 종료된 상태입니다.
그리고 이 상태는 특정 이벤트에 의해 변화됩니다. 이를 프로세스의 상태전이라고 합니다.
- admitted: new -> ready
- 생성된 프로세스가 승인을 받아 실행됩니다.
- scheduler dispatch: ready -> running
- readyQueue 맨 앞에 있는 프로세스가 cpu를 점유합니다.
- interrupt: running -> ready
- 실행중인 프로세스가 특정 이벤트에 의해 준비상태로 넘어갑니다. 이벤트에는 할당된 시간안에 명령을 모두 실행하지 못해 발생하는 time out 등이 있습니다.
- I/O or event wait: running -> wating
- i/o 등을 위해 cpu가 다른 프로세스를 할당하게될 때 context switching을 합니다.
- I/O or event completion: wating -> ready
- i/o 등의 이벤트가 종료되면 다시 pcb에서 값을 꺼내 reqdyQueue에 넣어줍니다.
- exit: running -> terminated
- 성공적으로 명령이 모두 실행되고 종료되는 상황입니다.
PCB(pcocess control block)
cpu는 한번에 하나의 프로세스만 실행합니다.
만약, 운영체제가 A 프로세스를 실행하다가 갑자기 긴급한 작업을 해아 한다면 기존에 작업하던 내용을 PCB에 저장합니다. 그 후 긴급한 프로세스의 작업이 전부 끝나면 PCB의 값이 다시 스케줄 되어 시작됩니다.
PCB에는 다양한 정보가 저장됩니다.
- PID : 프로세스의 고유 번호
- 상태 : 준비, 대기, 실행 등의 상태
- 포인터 : 다음 실행될 프로세스의 포인터
- Register save area : 레지스터 관련 정보
- Priority : 스케줄링 및 프로세스 우선순위
- 할당된 자원 정보
- Account : CPU 사용시간, 실제 사용된 시간
- 입출력 상태 정보
context switching
cpu가 이전 프로세스 상태를 pcb에 보관하고, 다른 프로세스의 정보를 pcb에서 읽어 레지스터에 적재하는 과정을 말합니다.
context switching은 인터럽트가 발생하거나, TimeQuantum(cpu가 사용을 허가받은 시간)을 모두 소모하거나, I/O 입출력을 위해 대기해야할 때 발생합니다.
현재 수행중인 프로세스가 인터럽트가 발생해서 pc, sp, 레지스터등 굉장히 많은 내용을 pcb에 전부 저장해 뒀다가 다시 꺼내서 쓰려면 당연히 지연시간이 발생할 수 밖에 없습니다.
이 때 발생하는 지연시간을 context switching overhead라고 말합니다.
2. 스레드
스레드 = 프로세스 내에서 실행되는 흐름의 단위
보통 프로그램은 하나의 스레드를 가지고 있습니다. 하지만 프로그램에 따라 둘 이상의 스레드를 동시에 실행할 수도 있습니다. 이 방식을 멀티스레드라고 합니다.
즉, 프로세스 내부에는 무조건 하나 이상의 스레드가 존재합니다.
스레드가 하나면 단일 스레드, 두개 이상이면 멀티 스레드라고 말합니다.
장점
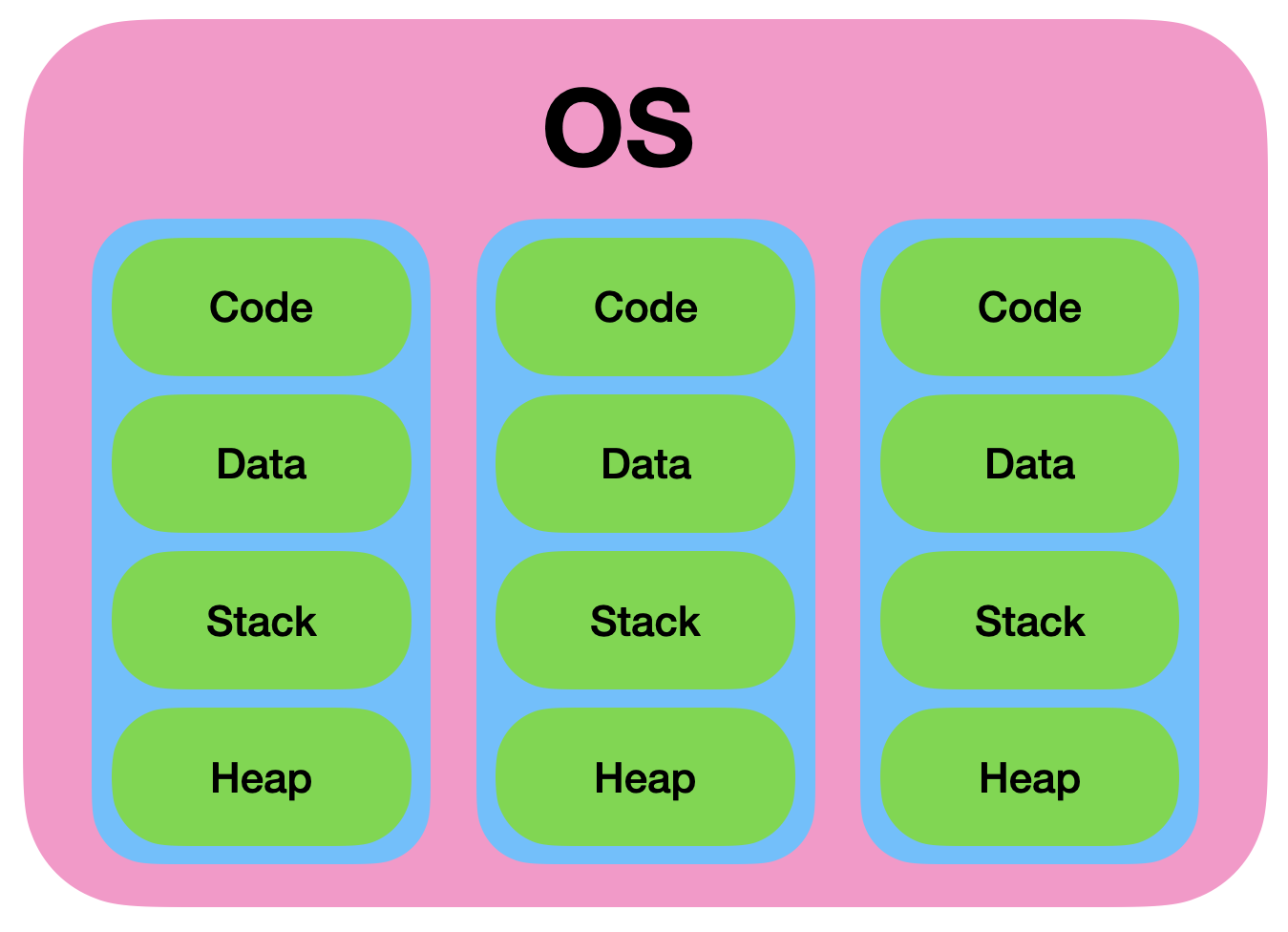
스레드는 code, data, heap 영역이 공유되기 때문에 멀티스레드 메모리를 효율적으로 사용할 수 있게 됩니다. 그리고, 프로세스간의 전환 속도보다 훨씬 빠르게 전환이 이루어집니다.
마지막으로 응답 시간을 단축할 수 있게 됩니다. 여러개의 스레드가 하나의 프로세스 내에서 요청처리를 하기 때문입니다.
단점
안정성
하지만 안정성 문제가 발생할 수 있습니다.
프로세스같은 경우 프로세스 하나가 문제가 발생해도 다른 프로세스에는 영향을 끼치지 않지만, 스레드는 같은 프로세스 안에서 동작하기 때문에 만약 하나의 스레드에서 문제가 발생하면 다른 스레드들도 영향을 받아 프로그램이 종료될 수 있습니다.
만약 적절한 예외처리를 한다면 극복할 수 있지만, 새로운 스레드의 생성 혹은 사용되지 않는 스레드의 처리등에 추가 비용이 들게됩니다.
동기화로 인한 성능저하
그리고 동기화로 인한 성능저하가 발생할 수 있습니다. 만약 여러개의 스레드가 동시에 한개의 자원을 변경하면 이상한 값을 읽어버리게 될수도 있습니다. 그래서 이러한 문제는 동기화를 통해 순차적으로 접근을 통제하면 동시수정 문제는 발생하지 않게 되지만 병목현상이 발생해 성능이 저하될 가능성이 높습니다.
이를 해결하기 위해 임계영역에 뮤텍스 또는 세마포어 방식을 활용합니다.
- 임계영역: 공유 자원을 접근하는 코드영역 ( 전역변수 혹은 힙 메모리 영역 )
- 뮤텍스: 임계영역 진입전 lock을 획들해 수정을 막고, 나올 때 lock을 해제한다.
- 세마포어: 동시 접근 가능한 스레드 개수를 지정한다.
데드락 ( 교착상태 )
여러개의 프로세스 혹은 스레드가 서로 자원을 점유하고, 서로 자원을 사용하려고 할 때 발생되는 상황입니다. 서로 절대로 자원을 획득할 수 없는데 계속해서 기다리는 상황을 데드락이라고 합니다.
아래는 이 상황을 잘 표현한 사진입니다.

이 문제는 공유 자원에 대한 동시 액세스로 인한 문제로 상호배제, 점유와 대기, 비선점, 순환대기 등의 알고리즘을 사용해 해결해야 합니다.
context switching overhead
멀티 프로세스보다 컨텍스트 스위칭 오베헤드가 적어 성능에 유리하지만 비용이 발생하기는 한다. 스레드 수가 많을수록 스위칭이 많이 발생해서 성능 저하로 이어질 수 있습니다.
그래서 이를 잘 생각하고 멀티 스레드를 사용해야 합니다.
3. 스케줄링
맨 위에서 말했던 것처럼 cpu는 한번에 하나의 명령만 실행할 수 있습니다. 그래서 적절한 우선순위에 따라 프로세스 혹은 스레드에 cpu를 할당해 주는 작업이 필요한데 이를 스케줄링이라 합니다.
그리고 스케줄러는 단기, 중기, 단기 스케줄러로 뉩니다.
장기는 스케줄러는 메모리 <-> 디스크 사이의 스케줄링을 담당해 admitted exit오 관련이 있습니다.
중기는 어떤 프로세스가 cpu를 할당받을지 결정하는데 할당은 하지 않습니다. 즉, 할당받을 수 있는 상황을 조절하는 스케줄러 입니다.
단기는 Dispatcher가 readyQueue 안에 있는 프로세스를 선택해 cpu를 할당해줍니다. 보통 스케줄러는 이 단기 스케줄러를 말합니다.
이 때 스케줄러는 제한된 자원을 여러 프로세스가 효울적으로 사용하게 해야하므로 다양한 정책을 가지고 cpu를 할당합니다. 다양한 정책은 특정한 우선순위를 말합니다.그리고 스케줄링 방법은 쿠게 선점과 비선점 방식으로 나뉩니다.
선점 스케줄링
실행중인 프로세스가 강제로 실행권을 빼앗길 수 있다.
프로세스가 자원을 사용하고 있더라도 우선순위가 더 높은 프로세스가 있다면, 자원을 뺏을 수 있는 스케줄링 방법입니다. 빠른 응답시간을 요구하는 대화식 시분할 시스템에 유용하며, 선점 상황이 잦다면 context switching overhead가 발생할 수 있습니다.
선점 스케줄링에는 RoundRobin, SRTF(Shortest Remaining Time First), 다단계 큐, 다단계 피드백 큐 등이 있습니다.
RoundRobin
일정 시간마다 프로세스를 중단하고 다음 프로세스를 실행합니다.
우선순위가 없는것이 특징이며, 순서대로 CPU를 할당합니다. 보통 시간단위는 10~100ms정도가 된다고 하며, 수행한 프로세스는 readQueue 맨 끝에 다시 넣습니다. 컨텍스트 스위칭 오버헤드가 큰 편이지만 응답시간이 짧다는 장점이 있습니다. 그래서 실시간 시스템에 유리하고, 할당되는 시간이 클 경우 FIFO 기법과 같아지게 됩니다.
SRTF(Shortest Remaining Time First)
선점형 SJF 스케줄링 입니다. 평균 대기시간과 응답 대기시간이 짧지만 실행 시간을 추정하는 작업이 추가로 필요하게 됩니다.
각 task의 남은 시간을 따져서 가장 남은시간이 짧은 task에게 cpu를 할당해줍니다.
다단계 큐
프로세스를 특정한 그룹으로 분류할 수 있을 경우 그룹에 따라 모두 다른 readQueue를 사용하는 스케줄링 방식입니다. 다른 그룹의 readQueue로 이동할 수 없고, 하위 readQueue에 있는 프로세스를 실행하던 도중이어도 상위 readQueue에 프로세스가 들어오면 상위 프로세스에게 먼저 CPU를 할당 해줘야 합니다.
다단계 피드백 큐
큐 사이의 이동이 가능한 다단계 큐입니다. cpu 시간 할당량이 끝나면 한단계 아래의 준비큐에 들어가고 단계가 내려갈수록 시간 할당량이 증가합니다. 가장 아래있는 큐는 FCFS 방식으로 동작합니다.
그런데 만약 맨 아래 큐에서 너무 오래 대기하게 된다면 다시 상위큐로 이동합니다. 기아상태를 예방하기 위해서 입니다.
그런데 매우 복잡한 판단을 요구하기 때문에 실제로 사용을 하는 경우는 적습니다.
비선점 스케줄링
실행중인 프로세스가 자발적으로 실행권을 내려놓는다.
실행중인 프로세스가 종료될 경우 혹은 인터럽트가 발생해 대기상태가 발생할 때만 대기상태로 돌아갑니다.
그래서 응답 시간의 예측이 가능하며, 일괄 처리방식에 적합합니다. 하지만 중요한 작업이 중요하지 않은 작업을 기다리는 경우가 발생할 수 있습니다.
비선점 스케줄링네는 FCFS, SJF(Shortest Job First), HRN(Highest Response Ratio Next) 등이 있습니다.
FCFS(First Come First Service)
이름에서 알 수 있듯 가장 먼더 들어온 순으로 스케줄링 합니다. 일괄처리 시스템에 적합하지만 CPU를 오래 사용하는 프로세스가 오게 된다면 다른 프로세스들이 CPU를 오랫동안 사용하지 못해 대기 시간이 커지는 현상이 일어날 수 있습니다.
SJF(Shortest Job First)
우선순위 큐를 사용해 작업 시간이 가장 짧은 프로세스 순으로 스케줄링 합니다. 그런데 기아현상이 일어날 수 있으며, 프로세스 생성 시 총 실행시간에 대한 정확한 계산이 어렵습니다.
HRN(Highest Response Ratio Next)
SJF의 기아현상을 해결하기 위해 있는 스케줄링입니다.
작업 시간이 가장 짧은 순으로 스케줄링 하지 않고 (대시시간 + 실행시간) / 실행시간을 우선순위로 지정해 대기시간이 길면 점점 우선순위가 높아지는 방식으로 스케줄링을 해줍니다.
배운점/실수한점
- 월요일
- 상속관계를 표현하는데 abstract class를 사용하자.
- 클래스의 구조를 설명할 때 interface를 사용하자
- 보드 등을 탐색할 때 중간에 break하지 않도록 다시 체크해보자.
- 클래스 설계에 조금 더 신경쓰자
- 화요일
- console.table을 사용하면 로그를 더 이쁘게 찍을 수 있다.
- 불변성(immutable)을 지키려면 다른 메모리에 할당해주면 된다.
- 참조 투명성은 입력에 대해서만 계산이 이뤄져야하고 외부에는 영향을 주지 않는걸 말한다.
- 수요일
- 요구사항이 복잡하고 많으면 테스트 코드를 작성해보자!
- 목요일
- 아는것과 모르는것 그리고 안다고 착각하는것을 정확히 구분하자
참조
- https://ko.wikipedia.org/wiki/%ED%94%84%EB%A1%9C%EC%84%B8%EC%8A%A4
https://inpa.tistory.com/entry/%F0%9F%91%A9%E2%80%8D%F0%9F%92%BB-multi-process-multi-thread#%EB%A9%80%ED%8B%B0_%EC%8A%A4%EB%A0%88%EB%93%9C%EC%9D%98_%EC%9E%A5%EC%A0%90 - https://jjangsungwon.tistory.com/106
- https://woo-dev.tistory.com/148
- https://velog.io/@tyjk8997/%EB%B9%84%EC%84%A0%EC%A0%90-%EC%8A%A4%EC%BC%80%EC%A4%84%EB%A7%81%EA%B3%BC-%EC%84%A0%EC%A0%90-%EC%8A%A4%EC%BC%80%EC%A4%84%EB%A7%81

많은 도움이 되었습니다, 감사합니다.