특가 정보만 모아 판매하는 딜리버리(Dealivery) 서비스를 개발하는 프로젝트를 진행하면서, 사용자의 토큰을 리프레시 토큰으로 관리하고, 대기열을 처리를 위해 Redis를 사용하기로 결정했다.

스터디는 📕개발자를 위한 레디스 라는 책을 단원별로 공부하고, 각자가 학습한 내용을 정리해 발표하는 방식으로 진행한다.
이번에 학습한 내용은 Redis의 기본 개념인 자료 구조로, 그 내용을 정리해서 공유한다! 🤓
1. String
String은 키와 값이 일대일로 연결되는 유일한 자료 구조로, 단순한 문자열부터 숫자까지 저장할 수 있다.
다른 자료 구조에서는 하나의 키에 여러 개의 아이템을 저장할 수 있지만, String은 단일 값을 저장한다.
- SET : string 데이터를 저장하는 명령어
- GET : 저장된 string 데이터를 조회하는 명령어
> SET 꽁치가 천원
OK
> GET 꽁치가
"천원"NX 옵션은 키가 존재하지 않을 때만 값을 저장하고, XX 옵션은 키가 존재할 때에만 값을 덮어쓴다.
> SET 꽁치가 만원 **NX
(nil)**> SET 꽁치가 오천원 XX
OKRedis는 내부적으로 문자열로 값을 저장하지만, 숫자 연산이 필요한 경우 자동으로 변환해 처리한다.
> SET 취소표 100
OK
> INCR 취소표
(integer) 101“100”을 숫자 100으로 변환한 뒤, 1을 더해서 101로 바꾼 후 다시 문자열 “101”로 저장한다.
INCRBY 취소표 50
(integer) 151INCR과 INCRBY 명령어는 숫자를 원자적(atomic)으로 조작한다.
이때, INCR과 INCRBY 커맨드는 string 자료 구조에 저장된 숫자를 ⭐️원자적⭐️으로 조작한다.
Redis에서 원자적이라는 것은 INCR이나 INCRBY 명령이 다른 작업이랑 섞이지 않고 한 번에 완전하게 실행된다는 뜻이다.
레디스는 싱글 스레드 이벤트 루프 기반의 시스템이기때문에 하나의 명령어를 한 번에 하나씩 처리한다.
→ 경쟁 상태(Race Condition)를 피할 수 있음
→ 여러 클라이언트가 동시에 같은 키에 대해 명령을 보낼 때도 데이터의 일관성을 유지할 수 있음
예를 들어서, 두 클라이언트가 동시에 INCR 취소표 명령을 보내도, Redis는 두 명령을 순차적으로 처리해서 중간에 다른 클라이언트가 접근할 수 없음을 보장한다. 그래서 취소표 값은 정확하게 1씩 두 번 증가해 결과적으로 2가 더해진다.
2. List
리스트는 스택과 큐의 역할을 모두 할 수 있는 자료 구조로, 양쪽에서 데이터를 추가하거나 제거할 수 있다.
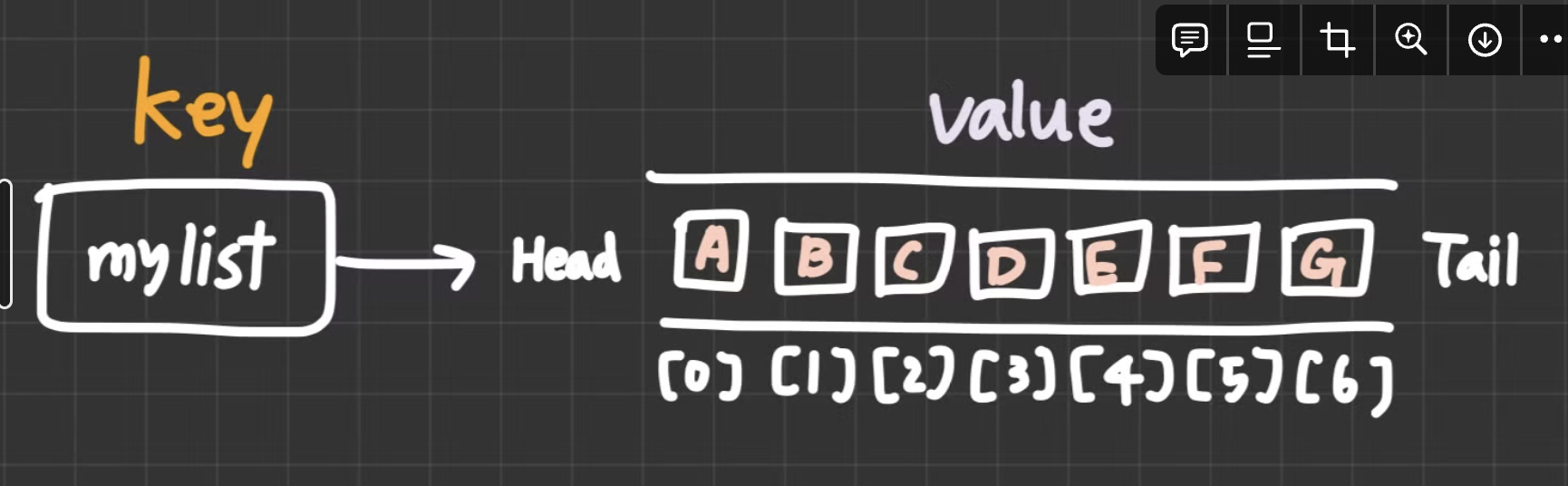
- LPUSH: 리스트 왼쪽(head)에 데이터 추가
- RPUSH: 리스트 오른쪽(tail)에 데이터 추가
- LRANGE: 리스트에서 특정 범위의 데이터를 조회
> LRANGE mylist 0 -1
1) "A"
2) "B"
3) "C"
4) "D"
5) "E"
6) "F"
6) "G"- LPOP : 리스트에서 첫 번째 아이템을 반환하고 동시에 해당 아이템을 삭제함. 숫자와 함께 사용하면, 지정한 숫자만큼의 아이템을 반복해서 반환하고 삭제함
> LPOP mylist
"A"
> LPOP myplist 2
1) "B"
2) "C"- LTRIM : 시작과 끝 인덱스를 인자로 받아, 지정한 범위 밖에 모든 아이템을 삭제. 그러나 LPOP과는 달리 삭제된 아이템을 반환하진 않음.
2.1 LPUSH와 LTRIM 커맨드를 함께 사용하면, 고정된 길이의 큐를 쉽게 유지할 수 있다!!💡
예를 들어, 채팅방에 최근 1000개의 메시지만 저장하고싶다고 가정 했을 때,
LPUSH 심키즈단톡 “오점뭐먹”
⇒ 새로운 채팅 메시지를 왼쪽에 추가LTRIM 심키즈단톡 0 999
⇒ 채팅 메시지가 1000개를 넘으면, 가장 오래된 메시지를 삭제해서 1000개의 메시지만 유지하게 함
⇒ 저장 공간 절약 + 빠른 메시지 관리 🤩
- LINSERT : 원하는 값의 앞이나 뒤에 데이터를 삽입할 수 있음.
BEFORE옵션을 사용하면 지정한 값 앞에,AFTER옵션을 사용하면 지정한 값 뒤에 데이터를 추가 - LSET : 리스트의 특정 인덱스에 저장된 값을 새로운 값으로 변경
LSET key index new-value이런식으로 - LINDEX : 리스트의 특정 인덱스에 저장된 값을 조회
LINDEX key index
3. Hash
Hash는 필드-값 쌍을 저장하는 구조로, 데이터를 객체처럼 다룰 수 있다.
객체를 표현하기 좋고, 필드를 자유롭게 추가할 수 있어서 관계형 DB보다 유연하게 사용 가능하다!
> HSET 심키즈 이름 "송나갱"
> HSET 심키즈 나이 50
> HSET 심키즈 취미 "산책"필드별로 데이터를 조회할 수 있으며, 여러 필드를 동시에 조회하는 것도 가능하다.
> HGET 심키즈 이름
"송나갱"
> HMGET 심키즈 이름 나이
1) "송나갱"
2) "50"4. Set
Redis에서 Set은 중복 없이 정렬되지 않은 문자열 모음이다.
교집합, 합집합, 차집합 등의 집합 연산을 제공하기때문에 객체 간 관계 계산이나 유일한 요소 추출에 유용하다.
- SADD : Set에 아이템을 저장. 여러 아이템도 한 번에 추가할 수 있음
> SADD 복권1등 송나갱
(integer) 1
> SADD 복권1등 송나갱 송나갱 유키즈 오키즈 강키즈
(integer) 3- SMEMBERS : set에 저장된 전체 아이템 출력. 순서 관계 X. 랜덤한 순서
> SMEMBERS 복권 1등
1) 강키즈
2) 송나갱
3) 오키즈
4) 유키즈- SREM : set에서 원하는 데이터 삭제.
- SPOP : set 내부 아이템 중 하나를 랜덤으로 반환하면서 삭제.
집합 간의 연산으로 교집합(SINTER), 합집합(SUNION), 차집합(SDIFF)을 사용할 수 있다.
- SUNION : 합집합
- SINTER : 교집합
- SDIFF : 차집합
5. Sorted Set
Sorted Set은 각 아이템이 스코어와 함께 저장되고, 스코어에 따라 자동으로 정렬된다.
스코어가 같으면 사전순으로 정렬되는데, Set처럼 중복 없이 고유한 값을 저장하면서도, Hash와 List처럼 인덱스 접근이 가능하다.
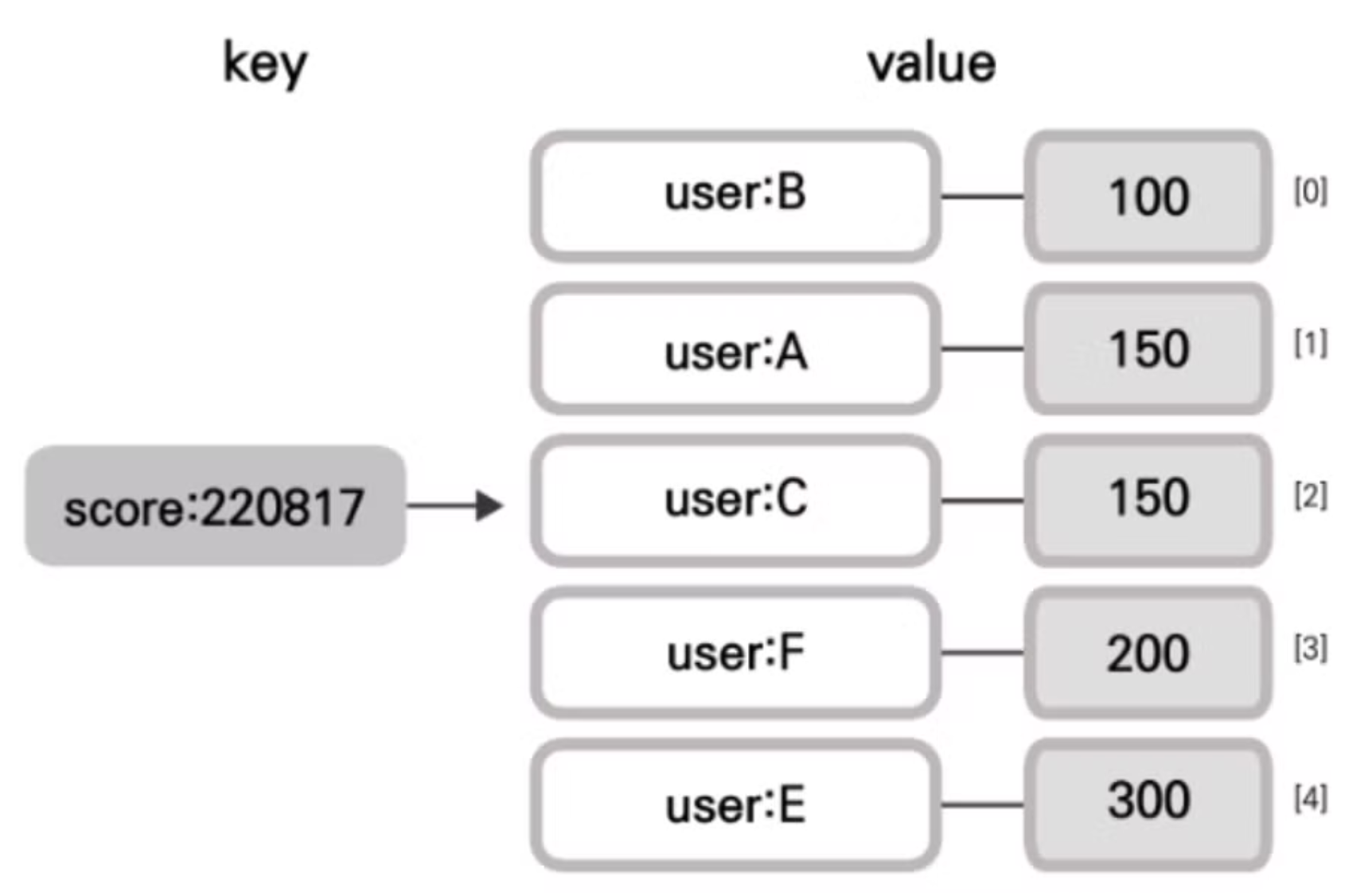
List는 O(n) 시간이 걸리지만, Sorted Set은 O(log(n))으로 더 효율적이다.
- ZADD : Sorted Set에 스코어-값 쌍으로 아이템을 저장. (여러 아이템 한 번에 입력 가능)
이미 존재하는 아이템은 스코어가 업데이트되어 재정렬됨.
# "highscores"라는 Sorted Set에 게임 점수 추가
ZADD highscores 1500 "손흥민"
ZADD highscores 1800 "황희찬" 2000 "호날두" 2500 "메시"
(integer) 3
# 이미 존재하는 플레이어의 점수를 업데이트
ZADD highscores 2200 "손흥민"
(integer) 0 # "손흥민"의 점수가 업데이트되고 재정렬됨- ZRANGE : Sorted Set에서 데이터를 조회할 때 사용함. start와 stop 범위를 입력
조회 방식에는 여러 옵션이 있다🤓
5.1 인덱스로 조회 (기본 조회 방식)
ZRANGE key start stop : Sorted Set에서 인덱스 범위로 데이터를 조회함. start는 시작 인덱스, stop은 끝 인덱스를 의미
ZRANGE highscores 0 25.2 스코어로 조회 (BYSCORE 옵션)
ZRANGE key start stop BYSCORE : 스코어를 기준으로 데이터를 조회. start와 stop에 스코어 범위를 입력해야함.
ZRANGE highscores 1000 2000 BYSCORE5.3 사전 순으로 조회** (BYLEX 옵션)
ZRANGE users [a [z BYLEX 