
📌 DynamoDB란?
- NoSQL(Not Only SQL) 데이터베이스
- 매우 빠른 쿼리 속도
- Auto-Scaling 기능 탑재
중요한 특징, 처음 데이터베이스를 만들면 크기가 정해지는데, Auto-Scaling의 경우는 데이터 크기 초과/축소될 때 테이블이 알아서 늘어나고 줄어든다. 비용 이점 - Key-Value 데이터 모델 지원
- 테이블 생성시 스키마 생성 필요 없음
실시간으로 들어오는 데이터를 보관하는데 탁월 - 모바일, 웹, IoT데이터 사용시 추천됨
- SSD 스토리지 사용
따라서 읽고 쓰는데 속도 빠름
DynamoDB의 구성

- 테이블 (Table)
- 아이템 (Items) - 행(row)과 개념이 비슷함
- 특징 (Attributes) - 열(column)과 개념이 비슷함
- Key-Value (Key : 데이터의 이름, Value : 데이터 자신)
예시) JSON, XML와 같이 Key-Value 형식
Primary Keys (PK)
- PK를 사용하여 데이터 쿼리
- DynamoDB에는 두가지의 PK 유형이 있음
1. 파티션키 (Partition Key)- 데이터를 나누고 분리시키는 키
- 고유 특징 (Unique Attribute)
- 실제 데이터가 들어가는 위치를 결정해줌
테이블 만들 때 파티션 키를 설정하면 데이터가 들어오는데, 데이터가 어디로 저장될지 파티션 키 내부에 들어 있는 해시함수를 돌리고 해시값이 반환되는데 이는 데이터가 저장될 주소값이다. 우리는 주소값으로 데이터를 찾는다. - 파티션키 사용시 동일한 두개의 데이터가 같은 위치에 저장될 수 없음. 파티션키 중복 불가!
- 복합키 (Composite Key)
- 파티션키(Partition Key) + 정렬키(Sort Key)
- 예시 : 똑같은 고객이 다른 날짜에 다른 물건을 구매
- 파티션키 : 고객아이디, 정렬키 : 날짜(Timestamp)
- 같은 파티션키의 데이터들은 같은 장소에 보관, 그다음 정렬키에 의해 데이터가 정렬됨
데이터 접근권한
- DynamoDB의 데이터는 AWS IAM으로 관리할 수 있음
- 테이블 생성과 접근 권한을 부여할 수 있음
- 특정 테이블만, 특정 데이터만 접근 가능케 해주는 특별한 IAM 역할 존재
📌 DynamoDB의 Index
- 특정 컬럼만을 사용하여 쿼리
- 테이블 전체가 아닌 기준점(pivot)을 사용해 쿼리가 이루어짐
- 매우 큰 쿼리 성능 효과
- 두가지의 Index 유형 존재
- Local Secondary Index (LSI)
- 테이블 생성시에만 정의해줄 수 있음
- 따라서 테이블 생성 후 변경, 삭제가 불가능
- 똑같은 파티션키 사용, 그러나 다른 정렬키 사용
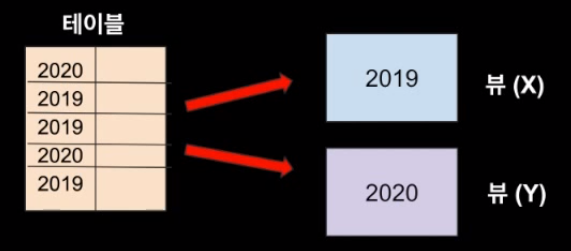
테이블을 기반으로 2019년도 데이터와 2020년도 데이터로 똑같은 파티션키로 다른 정렬키를 사용하여 두가지 뷰를 생성했을 때 정렬키(시간)를 기반으로 쿼리 진행시 속도가 빠르다. - Global Secondary Index (GSI)
- 테이블 생성후에도 추가, 변경, 삭제 가능
- 다른 파티션키, 정렬키 사용
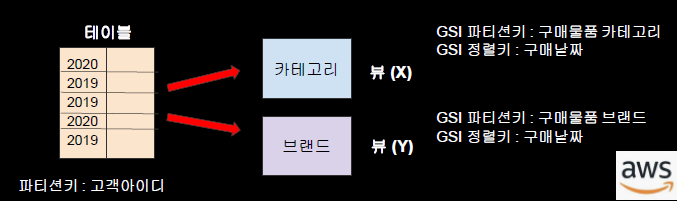
뷰를 만들 수 있다는 것은 Index 정의하면 기존 테이블에서 다른 파티션키와 정렬키를 가지고 있는 뷰를 복제할 수 있다는 뜻이다. GSI를 통해 새로운 뷰를 만들 때에는 만약 테이블에서 데이터 변경시 변화 인식하고 받아드린다. 뷰를 상대로 쿼리를 한다면 훨씬 빠르고 정확한 결과를 얻을 수 있다.
📌 Query Vs Scan
DynamoDB에서 데이터를 읽어오는 2가지 방식
- Query
- Primary Key를 사용하여 데이터 검색
- Query사용시 모든 데이터(컬럼) 반환
- ProjectionExpression 파라미터
우리가 보고 싶은 컬럼만 볼 수 있도록 수정, 일종의 필터링 역할
- Scan
- 모든 데이터를 불러옴 (primary key 사용 X)
- ProjectionExpression 파라미터
- 순차적방법 (Sequential)
- 테이블 크기가 상대적으로 크지 않고 테이블에 primary key의 정의가 필요없을 경우 사용
- Query VS Scan
- Query가 Scan보다 훨씬 효율적임
- Scan은 데이터의 크기 일정치 않음
- 따라서 Query 사용 추천
📌 DAX란?
DynamoDB Accelerator의 약자
- 클러스터 In-memory 캐시
In-memory는 데이터를 캐시에 보관하는 것, 필요한 데이터를 찾을때 빠르게 찾을 수 있다. - 10배 이상의 속도 향상
- 읽기 요청만 해당사항 (X 쓰기요청에서는 예외)
읽기 요청이 클 때 사용
Ex) Black Friday날 쇼핑 웹사이트 운영 (수많은 읽기 요청 예상)
DAX의 원리
- DAX 캐싱 시스템
직접 캐시에 데이터를 넣는 것이 아니라 DynamoDB 테이블에 데이터 삽입 & 업데이트시 DAX에도 반영 - 읽기 요청에 맞는 데이터가 DAX에 들어있을시 DAX에서 데이터 즉시 반환 (Cache Hit : 찾고픈 데이터가 캐시에 들어 있을 경우) <-> (Cache Miss)
DAX의 단점
- 쓰기 요청이 많은 어플리케이션에서는 부적절함
- 읽기 요청이 많지 않은 어플리케이션에서 부적절함
- 아직 모든 지역에서 제공하지 않음
📌 DynamoDB Stream란?
- DynamoDB 테이블에서 일어나는 일들(삽입, 수정, 삭제 등 = 이벤트)이 일어날 시 시간적 순서에 맞게 Streams에 기록
- Log는 즉각 암호화가 일어나며 24시간동안 보관됨
- 주로 이벤트를 기록하고 이벤트 발생을 외부로 알리는 용도 (예시 : Lambda Function)
- 이벤트 전&후에 대한 상황 보관
 하나의 API는 하나의 Endpoint와 연결
하나의 API는 하나의 Endpoint와 연결
왼쪽의 DynamoDB 테이블에 데이터를 넣거나 삭제와 같은 소통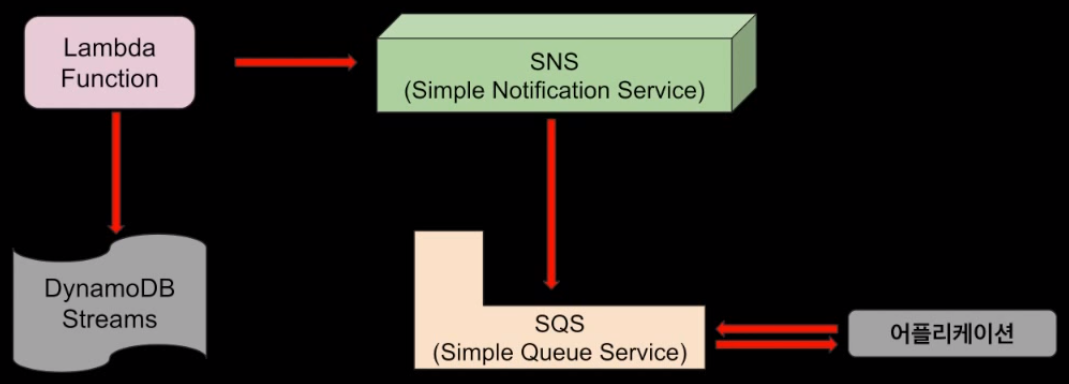 결제창의 내용은 SNS으로 부터 가져온 것
결제창의 내용은 SNS으로 부터 가져온 것
DynamoDB Stream을 통해 DynamoDB 테이블에 어떤 이벤트가 발생 시 대응할 수 있는 아키텍처를 가능케 해준다.
📌 후기
이번주까지 Lambda, CloudFront, DynamoDB의 개념은 연관이 많아 강의를 연속으로 들어서 편했던 것 같다. 이번 DynamoDB의 강의에서는 데이터베이스 수업 내용이 생각이 나서 반가웠지만, CloudFront의 실습은 익숙치 않아 조금 헷갈린다. 다시 한번 실습을 따라해보면서 개념을 익혀야겠다는 생각을 했다. 벌써 강의가 얼마 남지 않았다! 조금만 더 힘내자!

금융권 개발자
어떤 강의인지 알려주실 수 있을까요?