
Scikit-Learn이란?
Scikit-Learn(sklearn)은 파이썬에서 사용하는 머신러닝 라이브러리이다.
다양한 머신 러닝 알고리즘과 데이터 전처리 기능을 제공하며, 간단하고 일관된 API를 사용하여 사용자가 모델링 작업을 쉽게 수행할 수 있도록 지원한다.
Scikit Learn 사용 방법
기본적인 5단계
0. Data Preprocessing
1. Model Import
2. Model Declaration
3. Model Fitting(Training)
4. Model Predict
5. Model Evaluation
Data Preprocessing
1. EDA
- head, tail, describe, info 함수를 사용해서 데이터를 탐색한다.
2. Train-Test Split
- 전체 데이터를 학습용 데이터(train data)와 모델성능 평가용 데이터(test data)로 분리해야한다.
- Train data 중 일부를 다시 분리해서 valid dataset을 만든다.
- Valid dataset은 학습 도중 학습이 잘되고 있는지 중간에 평가할 용도로 사용한다.
- Test data는 한번도 본적 없는 데이터라고 가정하고, 전처리 코드 이외에 절대 학습에 사용하지 않는다.
- 대략 train data 6: valid data 2: test data 2 정도의 비율로 나눈다.
- 대부분 scikit-learn의 train_test_split 함수를 이용해서 split을 하지만, 시계열 등 연속성이 필요한 데이터셋의 경우, 순차적으로 자르기도 한다.
from sklearn.model_selection import train_test_split
# 꼭 이 순서대로 변수를 지정해야 한다.
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = testdata비율, random_state = 난수고정값)
3. One Hot Encoding
- Pandas에서 get_dummies로 one hot encoding을 적용했지만, ML modeling을 할 때는 scikit-learn의 preprocessing의 OneHotEncoder 함수를 더 많이 사용한다.
- Scikit-learn의 OneHotEncoder 함수에는 Pandas의 get_dummies 함수에 없는 기능이 있다. scikit-learn의 OneHotEncoder 함수는 보지 못한 데이터가 있을 경우 자동으로 처리해주는 기능이 있다.
- 일반적으로 scaling 전에 one hot encoding을 많이 하는 편이다.
## one hot encoding 적용
from sklearn.preprocessing import OneHotEncoder
oe = OneHotEncoder()
oe.fit(train_df['category칼럼명'])
train_encoded = oe.transform(train_df['category칼럼명'])
test_encoded = oe.transform(test_df['category칼럼명'])
## 원래 DataFrame과 concat
train_encoded_df = pd.DataFrame(train_encoded, columns = encoder.get_feature_names(['category칼럼명']))
test_encoded_df = pd.DataFrame(test_encoded, columns = encoder.get_feature_names(['category칼럼명']))
train_df = pd.concat([train_df, train_encoded_df], axis = 1)
test_df = pd.concat([test_df, test_encoded_df], axis = 1)
4. Scaling
- 대부분의 데이터들의 칼럼별 분포를 보면 제각각이다. 분포가 제각각인 상태에서 모델링을 하게되면 각 변수들의 영향도가 제대로 고려되지 못한 채 학습될 것이다.
- 따라서 각 변수들의 영향도를 일원화하는 작업 scaling이 필요하다.
Scaling 종류
- Min-Max Scaler
- 각 column을 0과 1 사이 범위로 맞춰주는 scaling으로, 가장 일반적으로 사용되는 scaling이다.
- 각 column의 데이터들에서 최솟값을 빼로 각 column의 최댓값과 최솟값의 차이로 나눠준다.

- Standard Scaler
- 각 coulmn의 데이터를 평균이 0, 표준편차가 1인 정규분포로 데이터들을 스케일링하는 방법으로, 이상치가 많은 데이터들일 때 사용하는 scaling이다.
- 각 칼럼의 데이터들에서 평균값을 빼고 표준편차값으로 나누어주면 된다.
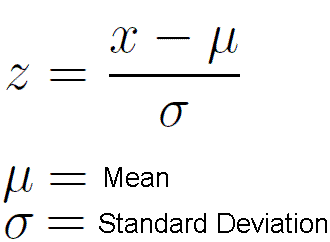
## scaler import
from sklearn.preprocessing import StandardScaler, MinMaxScaler
## scaler 선언
mm_scaler = MinMaxScaler()
sd_scaler = StandardScaler()
## scaler 학습
mm_scaler.fit(x_train)
sd_scaler.fit(x_train)
## scaler로 데이터에 적용
x_train_mm = mm_scaler.transform(x_train)
x_test_mm = mm_scaler.transform(x_test)
x_val_mm = mm_scaler.transform(x_val)
x_train_sd = sd_scaler.transform(x_train)
x_test_sd = sd_scaler.transform(x_test)
x_val_sd = sd_scaler.transform(x_val)Regression Model 회귀 모델
Logistic Regression 선형 회귀
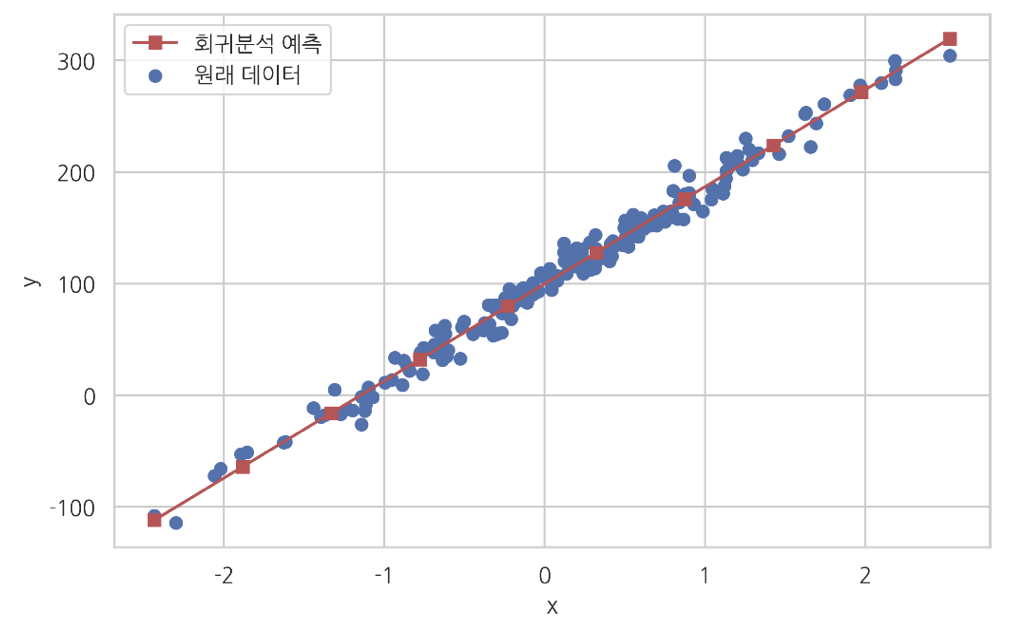
- 선형 회귀 모델은 데이터의 선형 관계를 기반으로 예측을 수행하는 모델로, 독립 변수와 종속 변수 사이의 선형 관계를 설명한다.
- 선형 회귀는 주어진 데이터와 예측 데이터의 오차 평균을 최소화할 수 있는 최적의 기울기와 절편을 찾는 것을 목적으로 한다.
- 선형 회귀에서 최적의 기울기와 절편을 찾는 대표적인 방식에는 정규 방정식(normal equation)과 경사하강법(gradient descent)이 있다.
# model import
from sklearn.linear_model import LinearRegression
# model 선언
lr = LinearRegression()
# model fitting
x_train = df.iloc[:, :-1] # 임의로 x 정의
y_train = df.iloc[:, -1] # 임의로 y 정의
lr.fit(x_train, y_train)
# model predict
y_test_pred = lr.predict(x_test)Classification Model 분류 모델
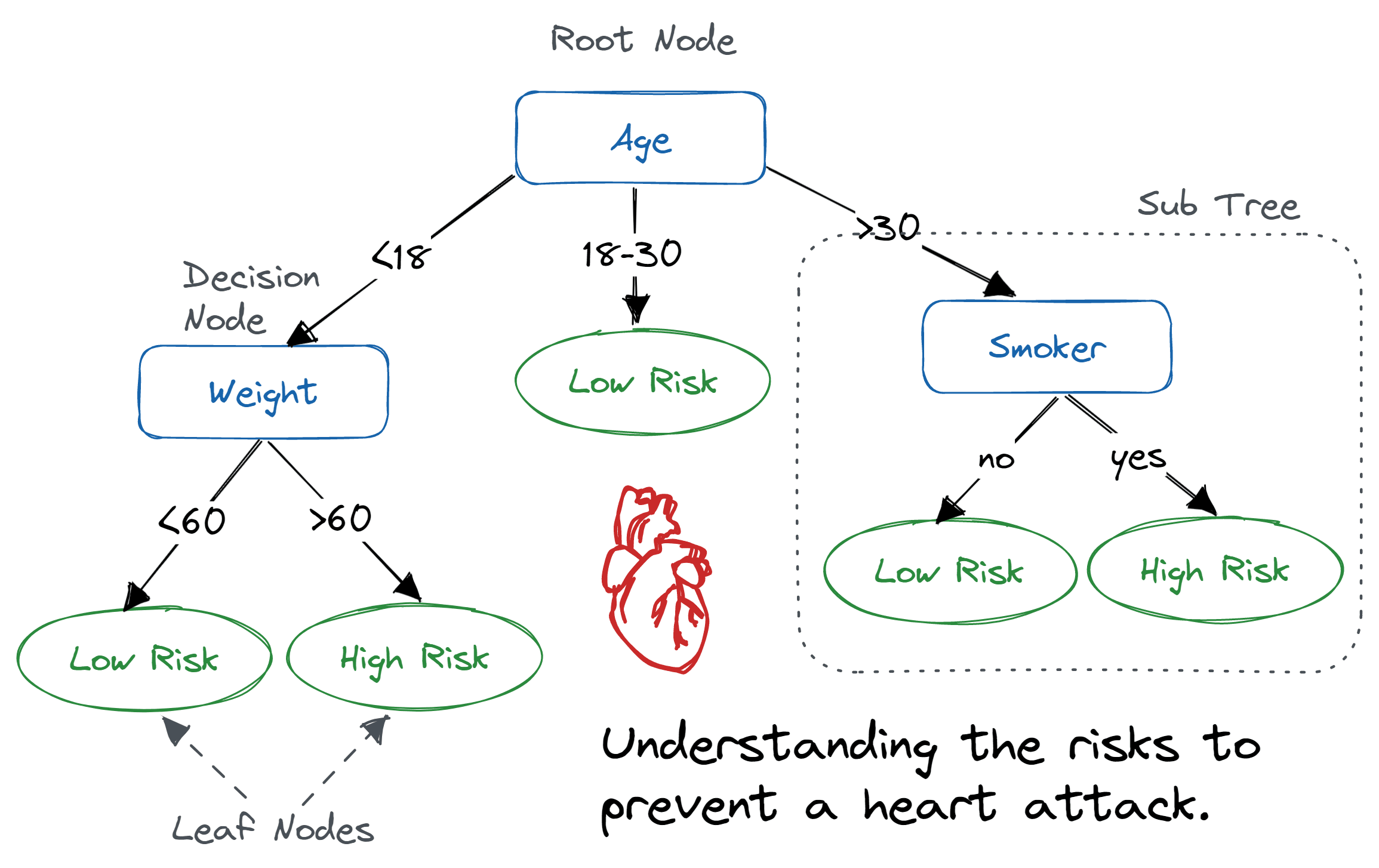
Decision Tree Algorithm
- Decision Tree Algorithm이란 마인드맵 처럼 노드에서 가지를 쳐서 뻗어나가는 형태의 알고리즘으로, 전체 시스템의 Impurity를 정의하고, 각 Feature(Column)별로 가장 Impurity를 낮출수 있는 Feature와 기준값을 찾아 가지를 뻗어나가며 전개해나가는 알고리즘이다.
- 알고리즘의 특성상, 가지를 뻗어나가다보니 데이터에 대한 overfitting이 발생할 소지가 높은 알고리즘이다.
Underfitting이란? model이 데이터의 패턴을 덜 학습한 상태(추가 학습의 여지가 남아있는 상태), 즉 loss가 최저점에 도착하지 못한 상태를 의미한다.
Balanced(Ideal) Fitting이란? model이 이상적으로 데이터의 패턴을 학습한 상태, 신규 데이터가 들어오더라도 유연하게 받아줄 수 있는 상태. 즉, training data loss와 test data loss가 비슷한 상태를 의미한다.
Overfitting이란? 기존의 데이터 패턴들만 너무 딱 떨어지게 학습을 해버려서, 신규 데이터 패턴에는 유연하게 대응할 수 없는 상태. 즉, training data에 대한 loss는 최저일 수 있으나, test data에 대한 loss가 증가하거나 발산하는 상태를 의미한다. - Decision Tree Algorithm의 Hyperparameter max_depth는 가지가 몇단계까지 뻗어나갈지를 제어하는 parameter이다. 너무 많은 가지가 뻗어나가게되면 overfitting이 발생할 여지가 있으므로, max_depth를 제어하며 test_loss를 관찰해볼 필요가 있습니다.
# model import
from sklearn.tree import DecisionTreeClassifier
# model 선언
dtc = DecisionTreeClassifier() # dtc = DecisionTreeClassifier(max_depth=2)
# model fitting
x_train = df.iloc[:, :-1] # 임의로 x 정의
y_train = df.iloc[:, -1] # 임의로 y 정의
dtc.fit(x_train, y_train)
# model predict
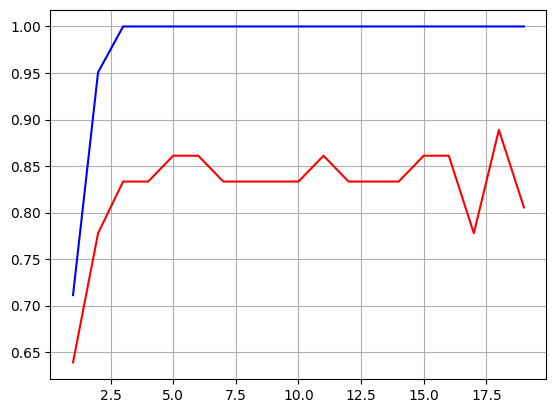
y_val_pred = dtc.predict(x_test)# 그래프를 그려보면 max_depth에 따른 성능을 볼 수 있다.
import matplotlib.pyplot as plt
import seaborn as sns
plt.figure()
sns.lineplot(x = range(1, 20), y = train_accuracy_list, color = 'blue')
sns.lineplot(x = range(1, 20), y = test_accuracy_list, color = 'red')
plt.grid(True)
plt.show()예시로 아래의 그래프에서 max_depth가 18일 때 가장 높은 성능을 낼 수 있다는 것을 확인할 수 있다.
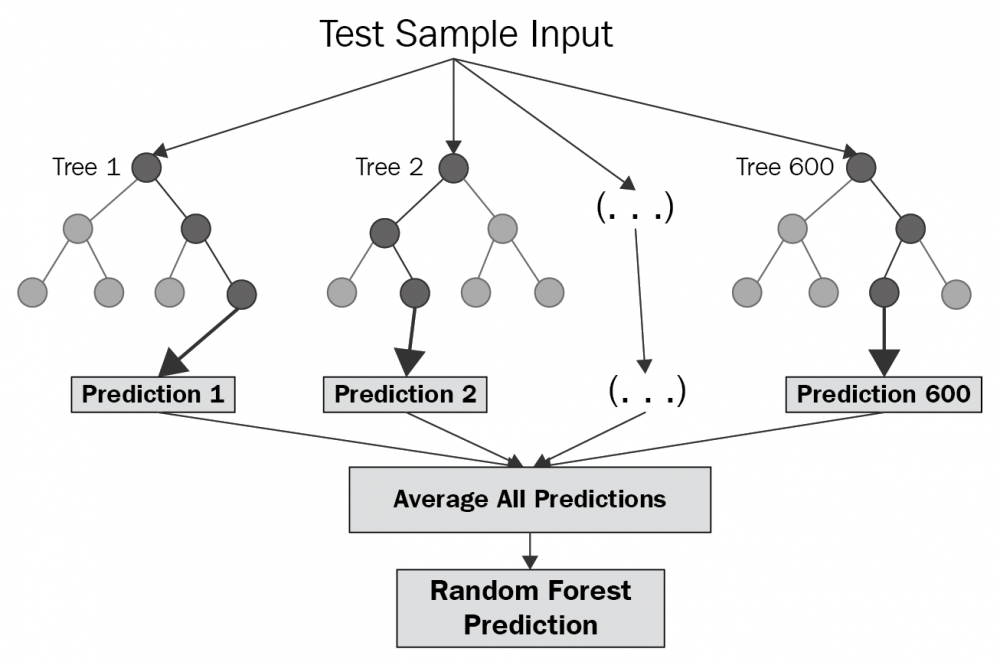
Random Forest Algorithm
- Random Forest는 앙상블(ensemble) 학습 방법 중 하나로, 여러 개의 decision tree를 조합하여 더 강력한 분류 모델을 구축하는 방법이다.
- 앙상블 학습이란 다수의 기초 알고리즘(base algorithm)을 결합하여 더 나은 성능의 예측 모델을 형성하는 것을 말한다. 앙상블 학습은 사용 목적에 따라 bagging, boosting, stacking으로 분류된다.
- 랜덤 포레스트에 사용된 bagging은 분산(variance)을 줄이기 위해 사용된다. 이는 과접합(overfitting)을 줄이고 예측 성능을 향상시키는데 효과적이다.
- 계산 비용이 높고 규칙이 많아 추론 로직을 설명하기 어렵다는 단점있다.
- Hyperparameter Tuning
- n_estimators : 생성할 tree의 개수(클수록 좋다)- max_features : 각 tree별 추출할 최대 feature의 개수(feature 수를 많이 뽑으면 각 tree들이 비슷해지고, feature 수를 적게 뽑으면 각 tree들이 각기 다른 작은 feature들을 갖게 되어 random성이 커진다.)
- max_features : 각 tree별 추출할 최대 feature의 개수(feature 수를 많이 뽑으면 각 tree들이 비슷해지고, feature 수를 적게 뽑으면 각 tree들이 각기 다른 작은 feature들을 갖게 되어 random성이 커진다.)
# model import
from sklearn.ensemble import RandomForestClassifier
# model 선언
rfc = RandomForestClassifier()
# model fitting
x_train = df.iloc[:, :-1] # 임의로 x 정의
y_train = df.iloc[:, -1] # 임의로 y 정의
rfc.fit(x_train, y_train)
# model predict
y_test_pred = rfc.predict(x_test)Gradient Boosting Classifier
- Boosting 알고리즘은 여러 개의 약한 학습기(weak learner)를 순차적으로 학습-예측하면서 잘못 예측한 데이터에 가중치를 부여해 오류를 개선해나가며 학습하는 방식을 말한다.
- Boosting 알고리즘에는 대표적으로 AdaBoost, Gradient Boosting Machine, XGBoost 등이 있다.
- AdaBoost는 Adaptive Boost의 줄임말로 약한 학습기(weak learner)의 오류 데이터에 가중치를 부여하면서 부스팅을 수행하는 대표적인 알고리즘이다. 속도와 성능 측면에서 decision tree를 약한 학습기로 사용한다.
- Gradient Boosting Machine(GBM)은 AdaBoost와 유사하지만, 가중치 업데이트를 경사하강법(Gradient Descent)을 이용하여 최적화된 결과를 얻는 알고리즘이다. GBM은 예측 성능이 높지만 Greedy 알고리즘으로 과적합이 빠르게 되고, 시간이 오래 걸린다는 단점이 있다.
- 경사 하강법 Gradient Descent이란 경사 즉 기울기를 줄여나감으로써 오류를 최소화하는 방법을 의미한다.

# model import
from sklearn.ensemble import GradientBoostingClassifier
# model 선언
gbc = GradientBoostingClassifier()
# model fitting
x_train = df.iloc[:, :-1] # 임의로 x 정의
y_train = df.iloc[:, -1] # 임의로 y 정의
gbc.fit(x_train, y_train)
# model predict
y_test_pred = gbc.predict(x_test)Model Evaluation
- 각 model별로 다른 평가 지표를 사용한다.
- Regression/Classification model의 평가 지표, Object Detection model의 평가 지표, NMT model의 평가 지표 모두 다르다.
- 각 model별로 평가지표(metric)을 이해하고, 비교분석하는 것이 중요하며, 그 근간이 되는 regression/classification model의 평가지표를 정확히 이해하는 것이 중요하다.
Regression metrics 회귀 평가 지표
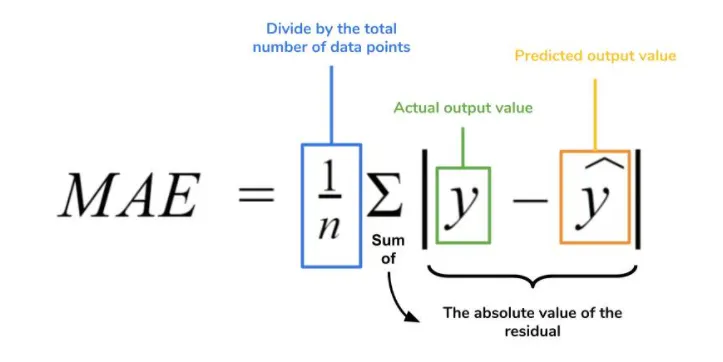
1. Mean Absolute Error 평균절대오차
- 줄여서 MAE라고 한다.
- 모델의 예측값과 실제값의 차이을 모두 더하는 개념이다.
- 절대값을 취하기 때문에 직관적으로 알 수 있는 지표다.
- MSE보다 특이치에 robust하다.(특이치에 영향을 많이 안 받는다는 의미다.)
- MAE는 절대값을 취하는 지표이기에 실제보다 낮은 값(underperformance)인지 큰 (overperformance)값인지 알 수 없다.
- Modeling을 할 때 잘 사용하지는 않지만, mean squared error가 직관성이 떨어지다보니 직관성을 높이기 위해 제곱값 대신 절대값을 사용하여 error의 마이너스값을 보정하여 최종 metric을 구하는 방식이다.
from sklearn.metrics import mean_absolute_error as mae
mae(y_test, y_pred)
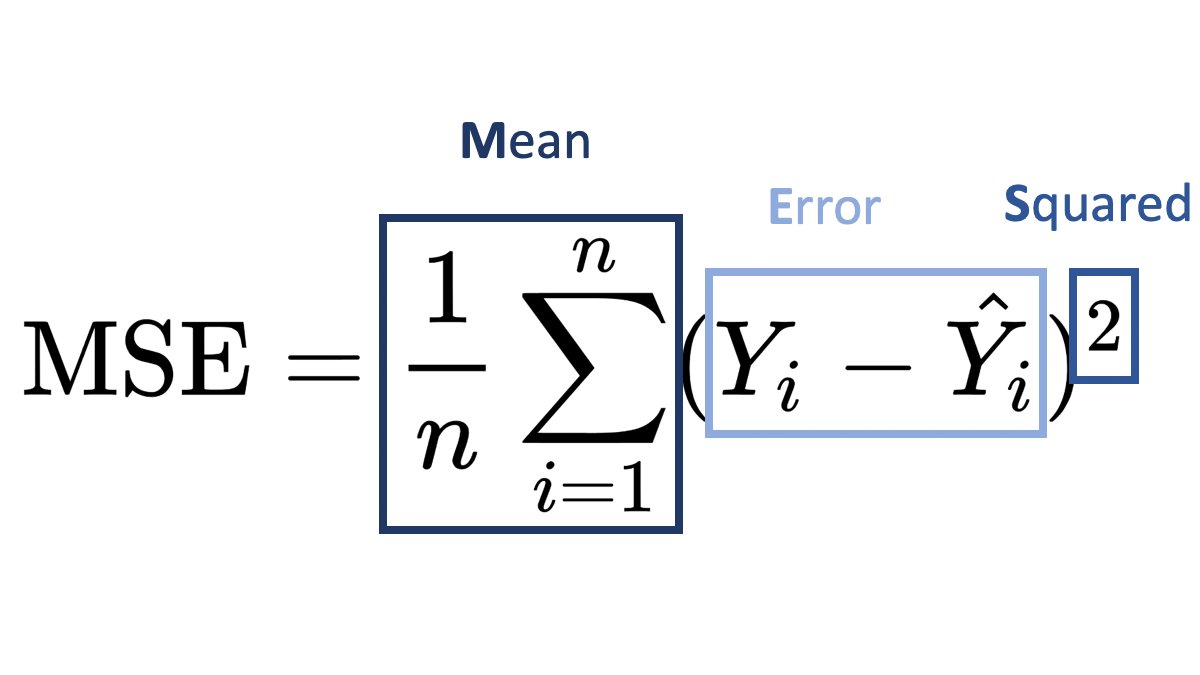
2. Mean Squared Error 평균제곱오차
- 줄여서 MSE라고 한다.
- MAE와는 다르게 제곱을 하기 때문에 모델의 실제값과 예측값의 차이의 면적의 합, 즉 실측값에서 예측값을 뺀 error들의 제곱의 합에 대한 평균이다.
- 제곱을 하기 때문에 특이값이 존재하면 수치가 많이 늘어난다.(즉 특이치에 민감하다는 의미이다.)
- Error들을 그대로 합하게 되면 무한대 값으로 발산할 수 있기 때문에 항상 양의 값을 만들어주기 위해 제곱의 값을 사용하고, 이를 평균을 취해준 값을 최종 metric 값으로 사용한다.
- 이때 제곱을 해서 합을 구하기 때문에 실제 데이처의 range와는 제곱수만큼 차이가 있어 직관적이지는 않다.
from sklearn.metrics import mean_squared_error as mse
import numpy as np
# mean squared error 평가지표
mse(y_test, y_pred)
3. Root Mean Squared Error 평균 오차
- 줄여서 RMSE라고 한다.
- MSE를 구한 값에 루트를 씌운다.
- 오류 지표를 실제 값과 유사한 단위로 변환하여 해석을 쉽게 한다.
from sklearn.metrics import mean_squared_error as mse
import numpy as np
# mean squared error 평가지표
mse(y_test, y_pred)
# mse에 제곱근연산을 한 rmse 함수 정의
def rmse(y_test, y_pred):
return np.sqrt(mse(y_test, y_pred))
# rmse 평가지표
rmse(y_val, y_val_pred)
Classification metrics 분류 평가 지표
1. Accuracy Score
실제 데이터 중 맞게 예측한 데이터의 비율을 말한다.
from sklearn.metrics import accuracy_score
accuracy_score(y_test, y_test_pred)2. Classification Report
- Precision
- 불량으로 예측한 것 중에 진짜 불량 개수를 계산한다. 즉, 분류 모형이 불량을 진단하기 위해 얼마나 잘 작동했는지 보여주는 지표다.
- Recall
- 불량 데이터 중 실제로 불량이라고 진단한 제품의 비율. 즉, 진단 확률을 보여주는 지표다.
- 만약 탐지 실패 시 risk가 탐지 비용보다 클 경우 recall을 중요하게 보고, risk가 탐지 비용보다 작을 경우 precision을 중요하게 본다.
- Speciality
- 분류 모형이 정상을 진단하기 위해 잘 작동하는지를 보여주는 지표다.
- F1-score
- Recall과 precision의 조화평균이다. Recall과 precision은 서로 trade-off 관계에 있어서, 한쪽을 높이면 반대쪽이 떨어지는 구조이다.
- Imbalance class 데이터의 경우 한쪽이 급격하게 낮아질 경우가 있기 때문에 f1 score를 고려하여 model을 튜닝하곤 한다.
from sklearn.metrics import classification_report, f1_score
print(classification_report(y_test, y_test_pred))
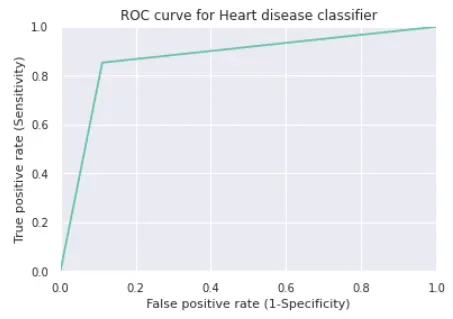
3. ROC Curve
- Receiver Operating Characteristic(ROC) Curve는 Binary Classification Model에서 recall과 precision의 변화에 대한 그래프이다.
- 그래프 하단의 영역을 AUC(Area Under the Curve)라고 부르며, AUC로 성능을 평가하기도 한다.
실습
scikit-learn 설치
!pip uninstall scikit-learn --y
!pip install scikit-learn==1.2.20. Data Load & Preprocessing
데이터 가져오기
import pandas as pd
import numpy as np
df = pd.read_csv('breast-cancer.csv')데이터 확인
df.head()
df.info()
df.describe()
df.shape데이터 전처리 : Train Test Split
x = df.loc[:, 'radius_mean':]
y = df['diagnosis'].astype('int')
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size= 0.2, random_state= 2023)데이터 전처리 : Scaling
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
scaler.fit(x_train)
x_train_sc = scaler.transform(x_train)
x_test_sc = scaler.transform(x_test)1. Model Import
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier2. Model Declaration
# 함수 형태로 변수에 저장
lr = LogisticRegression()
dtc = DecisionTreeClassifier()
rfc = RandomForestClassifier()
gbc = GradientBoostingClassifier()3. Model Fitting(Training)
for model in [lr, dtc, rfc, gbc]:
model.fit(x_train, y_train)4. Model Predict
for model in [lr, dtc, rfc, gbc]:
y_test_pred = model.predict(x_test)5. Model Evaluation
from sklearn.metrics import accuracy_score, f1_score, classification_report
for model in [lr, dtc, rfc, gbc]:
print(accuracy_score(y_test, y_test_pred))
print(f1_score(y_test, y_test_pred))
print(classification_report(y_test, y_test_pred))https://mozenworld.tistory.com/entry/머신러닝-모델-소개-1-선형-회귀-모델-Linear-Regression
https://mozenworld.tistory.com/entry/머신러닝-모델-소개-4-랜덤-포레스트-Random-Forest
https://dacon.io/en/competitions/official/235946/codeshare/5623
