
Matplotlib 공식 문서
https://matplotlib.org/stable/api/pyplot_summary.html
Matplotlib이란?
파이썬 기반 시각화 라이브러리로 numpy나 pandas에서 사용되는 자료구조를 쉽게 시각화 할 수 있다.
설치
pip install matplotlib==3.7.1Import
import matplotlib.pyplot as plt한글 글꼴 적용하기
matplotlib에서는 한글을 정상적으로 인식하지 못하기 때문에 다음과 같은 코드를 실행해야 한다.
# 윈도우의 경우
plt.rcParams['font.family'] = "Malgun Gothic"
plt.rcParams['axes.unicode_minus'] = False
# mac의 경우
from matplotlib import rc
%matplotlib inline
rc('font', family='AppleGothic')
plt.rcParams['axes.unicode_minus'] = False파일 읽기
import pandas as pd
# 원하는 변수명으로 csv 파일 불러오기
df = pd.read_csv('파일 경로', encoding = 'cp949')- csv파일을 읽어올때, decode error, encoding error 등이 발생하면, encoding type을 바꿔줘야한다.
- encoding type은 최초에 파일을 저장했던 OS의 encoding type을 따라간다.
- 최초에 저장했던 OS의 encoding타입과 현재 내가 사용하고있는 OS의 encoding type이 맞지 않을 경우 에러가 발생한다.
- windows계열은 encoding type을 'cp949'를 사용하고, linux/unix계열은 utf-8을 사용한다.
Line Chart
# x 정의
# y 정의
plt.figure(figsize = (가로사이즈,세로사이즈))
plt.plot(x, y)
plt.show()- 시간의 흐름에 따른 데이터의 연속적인 변화에 대해 보고싶을 때 사용하는 차트이다.
- chart의 전,후로 plt.figure 함수와 plt.show 함수를 작성한다.
- figure 함수는 새로운 차트를 생성할 때 작성하는 함수이다. 차트의 사이즈, 배경색 등을 지정할 수 있다.
- show 함수는 그래프를 표시하기 위해 작성하는 함수이다. (for문에서 차트를 그릴 경우 plt.show를 작성하지 않으면 그래프가 출력되지 않는 경우가 있다.)
<예제>
# 데이터 입력
x = range(1, 11, 1)
y = range(2, 21, 2)
# plt 함수 호출
plt.figure(figsize = (5,3))
plt.plot(x, y)
plt.show()
Chart 내에 grid 설정
plt.grid(True)<예제>
x = range(1, 11, 1)
y = range(2, 21, 2)
plt.figure(figsize = (5,3))
plt.plot(x, y)
plt.grid(True) # grid 설정
plt.show()
Line 색상
plt.plot(x,y, color = "color code/color명")<예제>
x = range(1, 11, 1)
y = range(2, 21, 2)
plt.figure(figsize = (6,3))
plt.plot(x, y, color = "#81F7D8") ## HTML Color Code (https://htmlcolorcodes.com)
plt.show()
Line Marker
plt.plot(x, y, marker = "marker 종류", markersize = 원하는크기의정수)
<예제>
x = range(1, 11, 1)
y = range(2, 21, 2)
plt.figure(figsize = (6,3))
plt.plot(x, y, marker='*', markersize = 10)
plt.show()
Line style
plt.plot(x, y, linestyle = "line 종류")- line 종류
- - : solid line
- -- : dashed line
- -. : dash-dot line
- : : dotted line
<예제>
x = range(1, 11, 1)
y = range(2, 21, 2)
plt.figure(figsize = (6,3))
plt.plot(x, y, linestyle = ":") # 점선 스타일
plt.show()
여러 그래프 그리기
plt.figure(figsize = (6,3))
plt.plot(x, y)
plt.plot(x, y1)
plt.plot(x, y2)
plt.show()- plt.show를 작성하기 전에 plt.plot을 여러개 작성하면 한 차트화면 내에 여러개의 그래프를 겹쳐 그릴 수 있다.
- 이때 주의할 점은 그래프들의 x축이 동일해야 의미가 있다.
<예제>
x = range(1, 11, 1)
plt.figure(figsize = (6,3))
plt.plot(x, x, color = "black")
plt.plot(x, list(map(lambda x : x**2, x)), color = "blue")
plt.plot(x, list(map(lambda x : x**3, x)), color = "red")
plt.grid(True)
plt.show()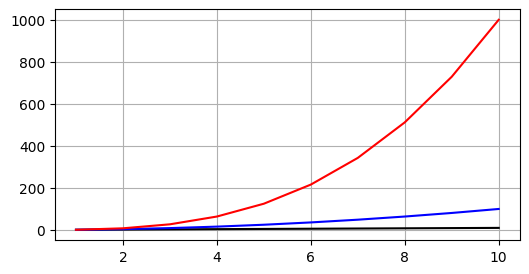
차트 범례(legend)
plt.figure()
plt.plot(x, y, label = "그래프 이름")
plt.xlabel("x축 이름")
plt.ylabel("y축 이름")
plt.legend()
plt.show()<예제1>
x = np.linspace(0, 10, 100)
plt.figure(figsize = (6,3 ))
plt.plot(x, np.sin(x), label = "sin")
plt.plot(x, np.cos(x), label = "cos", color = "red")
plt.xlabel("input")
plt.ylabel("output")
plt.legend()
plt.show()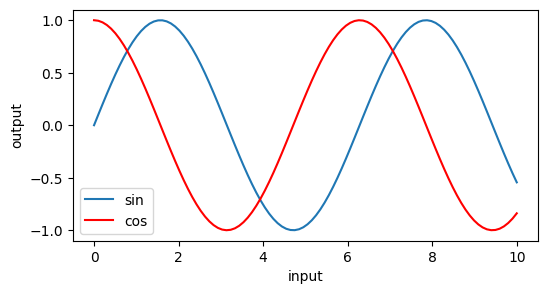
<예제2> 주가 차트 예시
# df 데이터프레임에서 슬라이싱
x = df.iloc[0:200, :]['date']
y1 = df.iloc[0:200,:]['close']
y2 = df.iloc[0:200,:]['5day_MA_close'] # 5일 단순 이동평균
y3 = df.iloc[0:200,:]['60day_MA_close'] # 60일 단순 이동편균
plt.figure(figsize = (12,6))
plt.plot(x, y1, color = 'black')
plt.plot(x, y2, color = 'blue')
plt.plot(x, y3, color = 'red')
plt.show()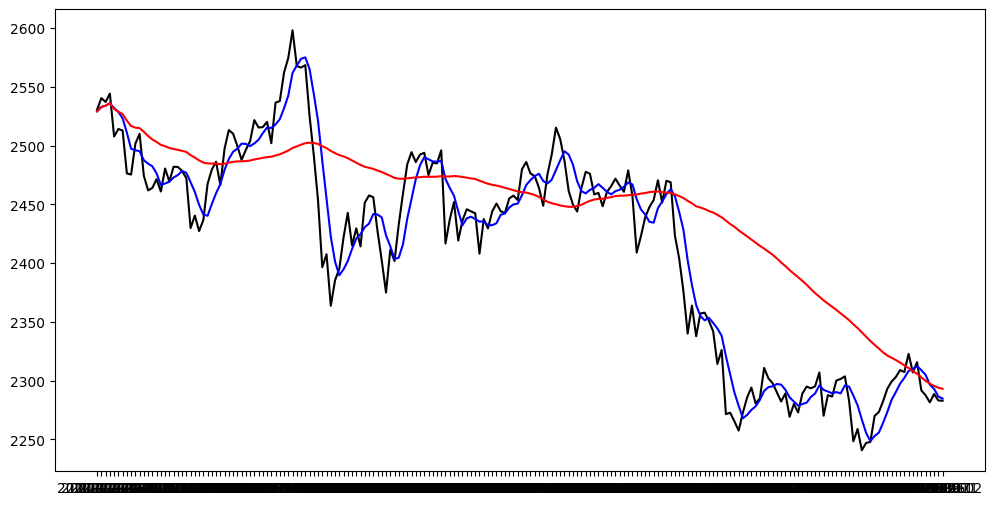
- 이동평균은 해당 일일 종가를 합산하고 그 수치를 해당 일로 나누어 매일 새로운 평균을 의미한다.
- 이동평균선(Moving average)을 그리면 Data의 up and down을 smoothing 시키는 효과가 있다. 그래서, 과거에는 moving average를 Data를 Denoising 시키는 기법으로 사용하기도 했다.
Bar Chart
- bar chart도 시간상의 흐름을 볼 수는 있지만, 주로 discrete한 카테고리 데이터의 분포를 보거나, 빈도/양의 상대적인 비교가 필요할 때 주로 사용한다.
- bar차트는 수직,수평 차트 2종류로 그릴 수 있다.
- plt.bar함수가 수직 차트, plt.barh함수가 수평차트다.
수직 바 차트
plt.figure(figsize = (가로사이즈,세로사이즈))
plt.bar(x, y)
plt.show()<예제>
x = sales_sum_by_category.index
y = sales_sum_by_category['구매금액']
plt.figure(figsize = (6,3))
plt.bar(x, y)
plt.show()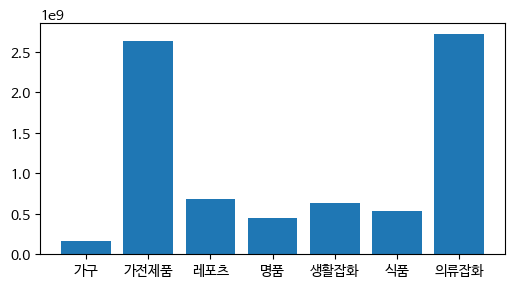
수평 바 차트
plt.figure(figsize = (6,3))
plt.barh(x, y)
plt.show()<예제>
plt.figure(figsize = (6,3))
plt.barh(x, y)
plt.show()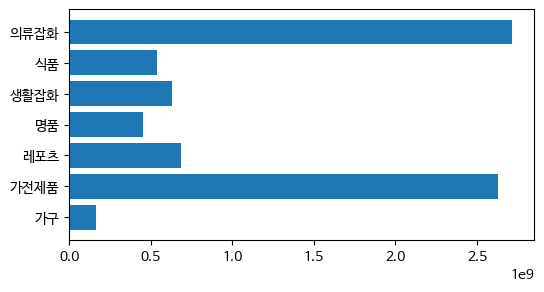
차트 막대 컬러
## item의 길이만큼 random한 컬러코드값을 추출하는 함수
import random
def random_rgb(length):
color_code_list = []
for i in range( length):
color_code = []
for j in range(3):
color_code += [random.random()]
color_code_list.append(tuple(color_code))
return color_code_list
colors = random_rgb(len(x))plt.figure(figsize = (6,3))
plt.barh(x, y, color = colors)
plt.show()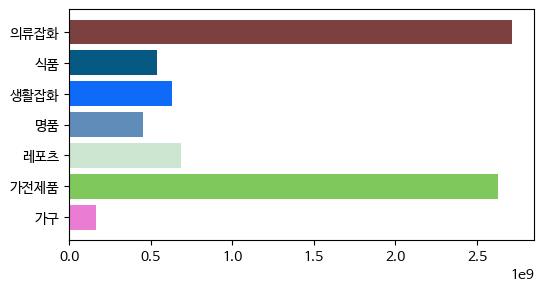
Subplot
Subplot은 여러개의 차트를 축을 나눠서 하나의 figure에 배치하는 차트이다.
plt.figure()
plt.subplot(row, column, index)
plt.bar(x,y)
plt.subplot(row, column, index)
plt.bar(x,y)
plt.show()
<예제>
x = sales_sum_by_category.index
y1 = sales_sum_by_category['구매금액']
y2 = sales_sum_by_category['구매수량']
sales_mean_by_category = sales_df.groupby("상품대분류명").mean()
y3 = sales_mean_by_category['구매금액']
y4 = sales_mean_by_category['구매수량']
row = 2
column = 2
plt.figure(figsize = (10,10))
plt.subplot(row, column, 1)
plt.bar(x, y1, label = '구매금액합계', color = 'blue')
plt.legend()
plt.subplot(row, column, 2)
plt.bar(x, y2, label = '구매수량합계', color = 'red')
plt.legend()
plt.subplot(row, column, 3)
plt.bar(x, y3, label = '구매금액평균', color = 'orange')
plt.legend()
plt.subplot(row, column, 4)
plt.bar(x, y4, label = '구매수량평균', color = 'green')
plt.legend()
plt.show()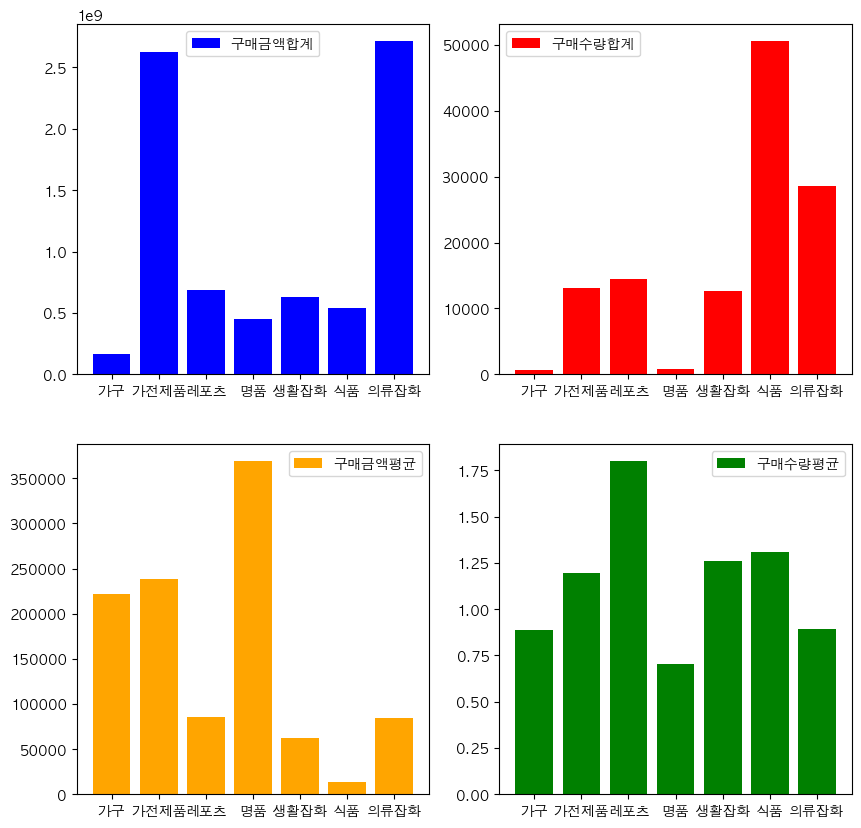
Box Plot
-
box plot은 통계 데이터를 그래프상에서 확인하고 싶을 때, 이상치 여부를 체크하고 싶을 때 등의 상황에서 사용합니다.
-
최솟값, 4분위수, 최댓값 등을 한꺼번에 확인할 수 있습니다.
-
upper band, lower band는 IQR outlier 계산법에 의해 계산된 band값입니다.
- IQR : Q3 - Q1
- Upper Band : Q3 + 1.5 * IQR
- Lower Band : Q1 - 1.5 * IQR

plt.figure()
plt.boxplot(x)
plt.show()<예제>
x = salary_df['salary_in_usd']
plt.figure()
plt.boxplot(x)
plt.show()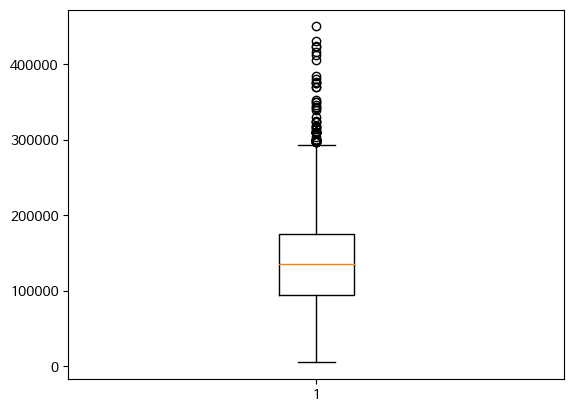
최상단 upper band 위로 윗꼬리가 많이 달려서 그려진 모습을 볼 수 있다. (ML Modeling시 이 값들을 이상치로 간주하고, IQR값으로 Smoothing시키는 방법도 고려해볼 수 있다.)
여러 box plot
plt.figure()
plt.boxplot([chart1, chart2,...])
plt.show()<예제>
chart_1 = salary_df.loc[salary_df['job_title'] == 'Data Engineer', "salary"] / 1000
chart_2 = salary_df.loc[salary_df['job_title'] == 'Data Scientist', "salary"] / 1000
chart_3 = salary_df.loc[salary_df['job_title'] == 'Data Analyst', "salary"] / 1000
chart_4 = salary_df.loc[salary_df['job_title'] == 'Machine Learning Engineer', "salary"] /1000
import numpy as np
plt.figure()
plt.boxplot([chart_1, chart_2, chart_3, chart_4], labels=['DE', 'DS', 'DA', 'MLE'])
plt.yticks(np.arange(0, 1100, 100))
plt.ylim([0, 1000])
plt.show()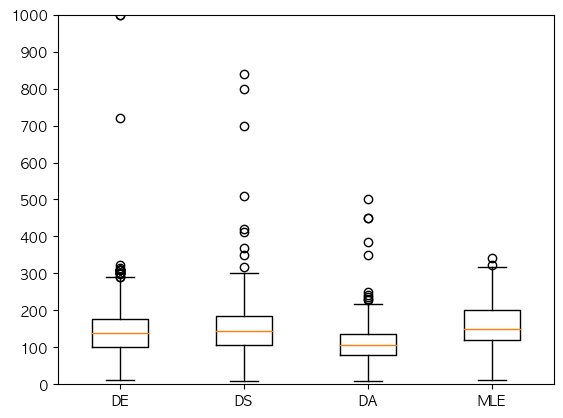
Scatter Plot
scatterplot은 주로 데이터간의 상관관계를 보거나, 데이터의 클러스터링 여부를 확인하는데 사용한다.
<예제>
# 증권 데이터 수집 라이브러리 설치
pip install yfinance==0.2.32
import yfinance as yf
start = "2000-01-01"
end = "2020-12-31"
ss_df = yf.download("005930.KS", start, end)
dollar_df = yf.download("USDKRW=X", start, end)
interest_10y_df = yf.download("^TNX", start,end)
# data join
df = pd.merge(ss_df.loc[:, 'Close'], dollar_df.loc[:, 'Close'], how = 'inner', on = 'Date', suffixes = ('_SS', '_Dollar'))
x = df['Close_Dollar']
y = df['Close_SS']
plt.figure()
plt.scatter(x, y)
plt.show()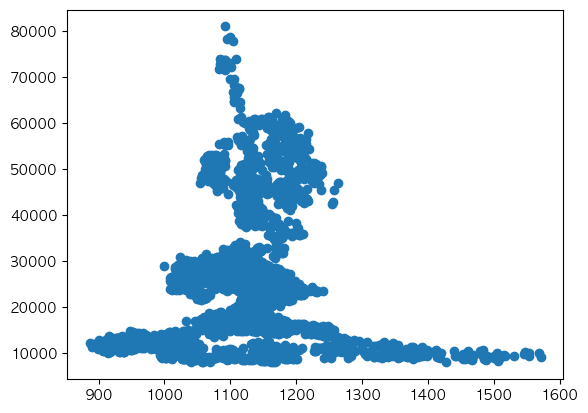

천천히 꾸준히 기록