.png)
단변량 분석 시 확인해야할 사항
값의 범위를 확인한다.- 데이터가 밀집 또는 희박한
구간(또는 범주)을 확인한다. - 범주형 데이터에 대해서
category로 데이터타입을 변경한다. 이상치를 확인 후 조치 방안을 강구한다(feat. boxplot).결측치를 확인 후 조치 방안을 강구한다.- 확인:
df.info() / df.isna().sum() - 조치:
최빈값(보통 범주형에서) / SimpleImputer / KnnImputer 등
- 확인:
비즈니스 관점에서 특이사항을 도출한다.추가 분석 대상이 있을지 고민해본다.
참고사항
cf) CDA & EDA 하기 전에 test 셋을 따로 분리시켜둬야한다.
why? test셋은 정답지와 같은 것으로, 학습할 때 정답지를 보고 한다는 건 말이 안 되기 때문!
라이브러리 불러오기
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns타이타닉 데이터 불러오기
titanic = pd.read_csv('titanic_train.csv')
# 확인
titanic.tail(2)
데이터 출처:https://www.kaggle.com/c/titanic
x와 y 분리
target = 'Survived'
x0 = titanic.drop(target, axis=1)
y0 = titanic[target]train, val, test 셋 분할
# 필요한 라이브러리 불러오기
from sklearn.model_selection import train_test_split- test_size 속성값으로 소수점을 주면 비율로, 정수로 주면 개수로 분할해준다.
- random_state 속성값은 난수 설정값이다.
# 필요한 라이브러리 불러오기
x, x_test, y, y_test = train_test_split(x0, y0, test_size=.1, random_state=2022)
x_train, x_val, y_train, y_val = train_test_split(x, y, test_size=80, random_state=2022)
pd.info()
- 전체 데이터 수(행의 수), 결측치 존재여부, 변수 타입 등을 확인할 수 있다.
x_train.info()
숫자형 변수
기초통계량
- pd.describe()으로 숫자형 변수들에 대해서만 확인할 수 있다.
- 데이터 개수, 평균, 표준편차, 최소값, 1~3분위수, 최대값을 확인할 수 있다.
x_train.describe()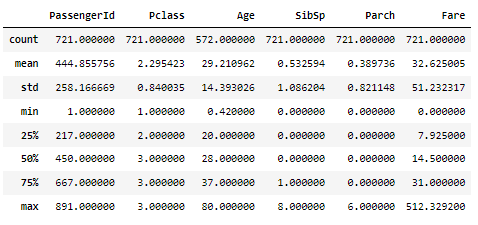
시각화
histogram
plt.hist(x_train[['Age']], bins=16, edgecolor='gray')
plt.show()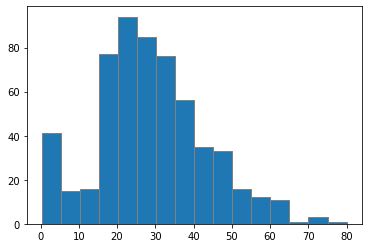
추가: 빈도수, 구간값 확인하기
hist = plt.hist(x_train[['Age']], bins=16, edgecolor='gray')
print('빈도수 : ', hist[0]) # y축 경계값
print('구간값 : ', hist[1]) # x축 경계값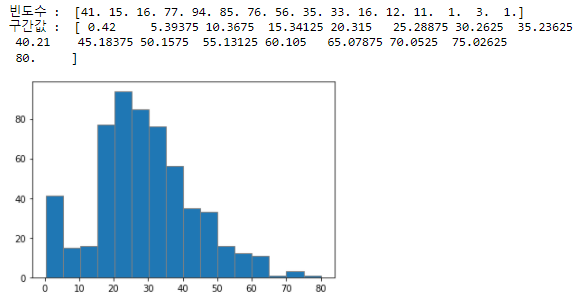
추가: 변수 여러 개를 사용할 경우
- 색은 1. 블루, 2. 주황, 3. 녹색 순서가 디폴트
- cf) Age와 Fare는 의미가 많이 다르기때문에 보통 이런 식으로 안 하고 남자의 Age, 여자의 Age를 나눠야하는 경우 등에 사용
plt.hist(x_train[['Age', 'Fare']], bins=16, edgecolor='gray')
plt.legend(['Age', 'Fare'])
plt.show()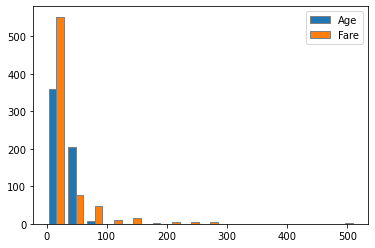
densityplot
- hue속성을 안 쓸 경우
sns.kdeplot(data=x_train, x='Age')
plt.show()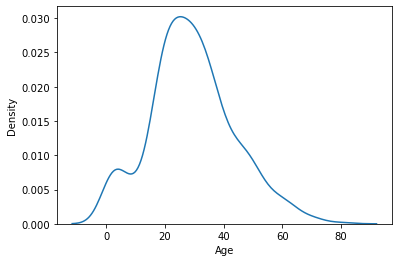
- hue속성을 쓸 경우
sns.kdeplot(data=x_train, x='Age', hue=y_train)
plt.show()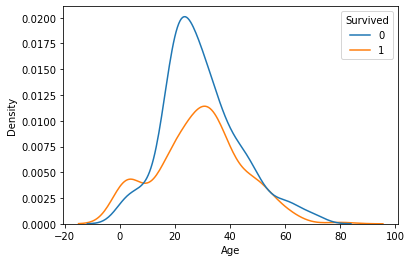
- cf) Series.plot(kind='kde')
- kind='hist'하면 히스토그램이 그려짐, 단 권장하진 않음
x_train['Age'].plot(kind = 'kde')
plt.show()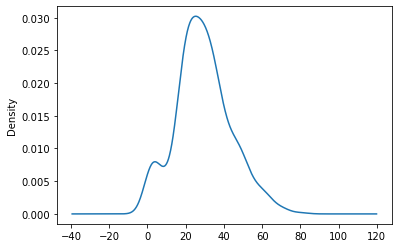
boxplot - 이상치 확인
 이미지 출처: https://towardsdatascience.com/understanding-boxplots-5e2df7bcbd51
이미지 출처: https://towardsdatascience.com/understanding-boxplots-5e2df7bcbd51
- 보통 boxplot
수염 끝(fence, 해당 이미지에서 "Minimum"과 "Maximum") 밖의 값들을 이상치로 봄.
- 정규분포라면, 수염 끝은 약 3 * (표준편차)이다. - 보통 데이터의 분포가
정규분포에 가깝다면 3 * 바깥을 이상치로 본다.
cf) plt.boxplot으로 그릴 경우, 결측치(NaN)이 있으면 그래프가 그려지지 않는다.- cf) sns.boxplot으로 그릴 경우, NaN 관계없이 그려진다.
결측치를 채운 후 그리면 달라지기때문에,결측치를 처리한 후 plt.boxplot으로그리도록 하자.
- 현재 Age 변수에 NaN이 있기 때문에 plt.boxplot으로 그릴 경우 그려지지 않는다.
plt.boxplot(x_train['Age'])
plt.show()
- NaN을 처리 안 하고 sns.boxplot으로 그릴 경우, 그려짐을 확인할 수 있다.
sns.boxplot(data=x_train, y='Age')
plt.show()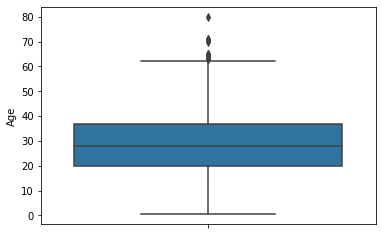
추가: 결측치 채운 후 plt.boxplot
- KNNImputer, SimpleImputer를 이용해 채우는 방법은 뒤에서 다룬다.
- 여기서는 Age의 평균값으로 Age 변수의 NaN을 채우고 진행해보자.
- 평균값으로 NaN 채우기
x_train['Age'] = x_train['Age'].fillna(x_train['Age'].mean())
x_train.isna().sum()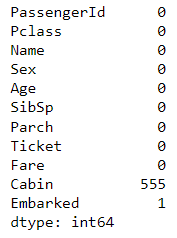
- 결측치 채운 후 plt.boxplot 그리기
plt.boxplot(x_train['Age'])
plt.show()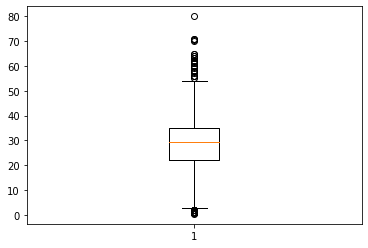
바이올린 플롯
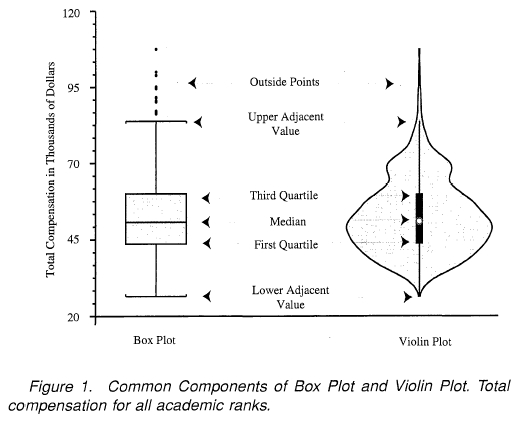 이미지 출처: https://junklee.tistory.com/9
이미지 출처: https://junklee.tistory.com/9
plt.violinplot(x_train['Age'], showmeans=True)
plt.show()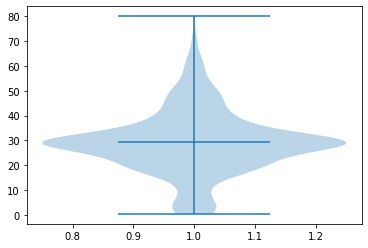
- cf) vert=False 속성을 주면 가로로 눕힐 수 있다.
plt.violinplot(x_train['Age'], vert=False, showmeans=True)
plt.show()
시계열 데이터 시각화
- titanic에는 시계열 데이터가 없기 때문에 airquality 데이터를 사용한다.
- 회귀문제에서
예측값과 실제값을 비교할 때 시각화로 사용할 수 있다.
air = pd.read_csv('https://bit.ly/3qmthqZ')
air['Date'] = pd.to_datetime(air['Date']) # 날짜 형식으로 변환
plt.plot('Date', 'Ozone', 'g-', data = air, label = 'Ozone')
plt.plot('Date', 'Temp', 'r-', data = air, label = 'Temp')
plt.xlabel('Date', size=10)
plt.legend()
plt.show()데이터 출처: https://github.com/DA4BAM/dataset

범주형 변수
category로 데이터타입 변경
데이터 이해를 하면서 category로 데이터타입을 변경한다.
- 이후
가변수화를 위한 사전작업 - cf) https://velog.io/@songjeongwoo/%EA%B0%80%EB%B3%80%EC%88%98%ED%99%94#%EA%B0%80%EB%B3%80%EC%88%98%ED%99%94%EC%9D%98-%ED%95%A8%EC%A0%95
x_train['Embarked'] = pd.Categorical(x_train['Embarked'], categories=['S', 'Q', 'C'], ordered=False)
titanic.info()
시각화
barplot
- plt.bar()를 사용하기 위해선
집계 먼저해야한다. - index(x)와 values(height) 순서를 지켜서 써야한다.
sns.countplot()을 사용하면 집계를 알아서 해준다.
cnt = x_train['Sex'].value_counts() # 집계
# width : 막대의 폭 지정, barh일 때는 사용불가
plt.bar(cnt.index, cnt.values, color = ['b', 'r'], width=0.7)
plt.show()
- cf) 집계 결과
x_train['Age'].value_counts()
- plt.barh()를 쓰면 가로 막대 그래프를 그릴 수 있다.
cnt = x_train['Sex'].value_counts() # 집계
plt.barh(cnt.index, cnt.values)
plt.show()
sns.countplot을 활용한 시각화
sns.countplot(x='Pclass', data=x_train, palette = sns.color_palette("pastel"),
order = x_train['Pclass'].value_counts().index)
plt.show()
그래프에 값 표시
- 세로 막대 그래프
ax = sns.countplot(x='Pclass', data=x_train, palette = sns.color_palette("pastel"),
order = x_train['Pclass'].value_counts().index)
# countplot에 값 표시
for p in ax.patches:
height = p.get_height()
ax.text(p.get_x() + p.get_width() / 2., height + 30, height, ha = 'center', size = 12)
ax.set_ylim(0, 450)
plt.show()
- 가로 막대 그래프
-x와 y를 바꿔준다.
ax = sns.countplot(y='Pclass', data=x_train, palette = sns.color_palette("pastel"),
order = x_train['Pclass'].value_counts().index)
for p in ax.patches:
x, y, width, height = p.get_bbox().bounds
ax.text(width*1.01, y+height/2, int(width), va='center')
ax.set_xlim(0, 450)
plt.show()
pie chart
그래프를 그리기는 이유는 한 눈에 시각화를 하기 위함인데 pie chart의 경우엔 한 눈에 보기 힘든 경우가 많다.
이로 인한 이유때문에 실무에선 잘 안 쓰인다고 한다. 이런 게 있다는 것만 알고 넘어가도록 하자.
- startangle=90 추가하면 '90도부터 시작'
- counterclock=False 추가하면 '시계방향으로'
- explode = [0.05, 0.05] 추가하면 '중심으로부터 male과 female을 얼마나 띄울지'
- shadow=True 추가하면 '그림자 추가'
cnt = x_train['Sex'].value_counts() # 집계
plt.pie(cnt.values, labels = cnt.index, autopct = '%.2f%%',
colors = sns.color_palette("pastel"), explode = [0.05, 0.05])
plt.show()
