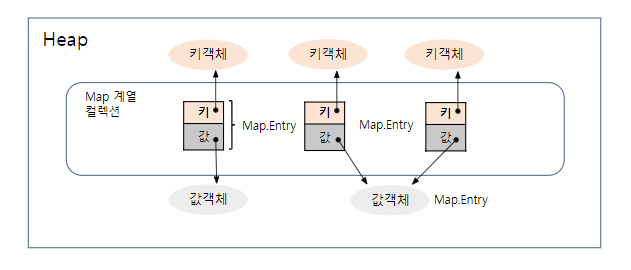
Map
인터페이스
출석부
키(key)와 값(value)으로 구성되어 있으며, 키와 값은 모두 객체
키는 중복 저장을 허용하지 않고(Set방식), 값은 중복 저장 가능(List방식)
키가 중복되는 경우, 기존에 있는 키에 해당하는 값을 덮어 씌움
구현 클래스로 HashMap, HashTable, LinkedHashMap, Properties, TreeMap이 있음
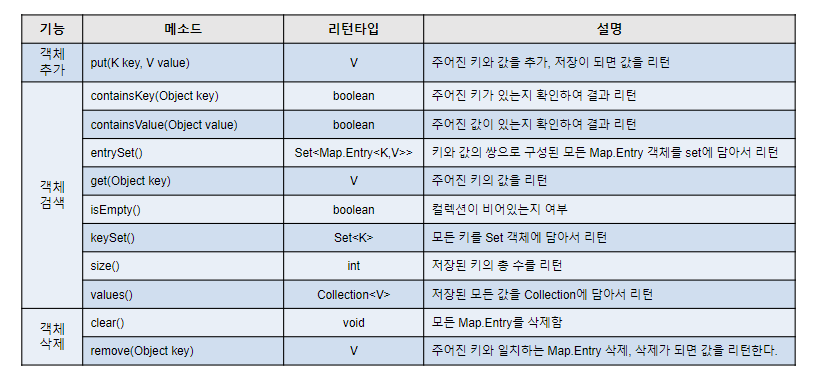
Map 계열 주요 메소드
Set, List 는 .add()
Map 은 Put(key,value)
Map에 담겨있는 요소들을 순차적으로 접근하는 방법 두가지
- keySet() 이용하기 -> key를 담은 Set을 Iterator로 접근하는 방법
- entrySet() 이용하기 -> k:v 를 담은 Set을 Iterator로 접근하는 방법
HashMap (대표타입)
hash 들어가져 있으면 hashCode() equals() 오버라이드 해야함
키 객체는 hashCode()와 equals()를 재정의해 동등 객체가 될 조건을 정해야 함
때문에 키 타입은 hashCode와 equals() 메서드가 재정의되어 있는 String타입을 주로 사용
ex) Map<K, V> map = new HashMap<K, V>();
- V put(K k, V v) : Map 에 추가
- Map 에 추가 시
중복되는 key 가 없으면 null
중복되는 key 가 있으면 이전 value 반환
public void method1() {
Map<Integer, String> map = new HashMap<Integer, String>();
System.out.println(map.put(1, "에그마요"));
System.out.println(map.put(2, "로티세리바베큐"));
System.out.println(map.put(3, "스테이크앤치즈"));
System.out.println(map.put(3, "스파이시쉬림프")); // Key 3 중복출력 결과
null
null
null
스테이크앤치즈 -> 이전 value 반환 System.out.println(map);출력 결과
{1=에그마요, 2=로티세리바베큐, 3=스파이시쉬림프}{K=V, K=V, K=V} 형태 K=V 한쌍은 entry 라고 부름
- V get(K k) : Key 에 해당하는 Value 반환
일치하는 Key 가 없다면 null 반환
System.out.println(map.get(1));
System.out.println(map.get(2));
System.out.println(map.get(3));
System.out.println(map.get(0));출력 결과
에그마요
로티세리바베큐
스파이시쉬림프
nullString temp = map.get(2);
System.out.println(temp);출력 결과
로티세리바베큐- int size() : Map 에 저장된 Entry(K:V)의 개수
System.out.println("size : " + map.size());출력 결과
size : 3- V remove(K k) :
- Key 가 일치하는 Entry 를 제거
- 일치하는 Key 가 있다면 Value, 없다면 null 반환
System.out.println("remove(2) : " + map.remove(2));
System.out.println("remove(5) : " + map.remove(5)); System.out.println(map);출력 결과
remove(2) : 로티세리바베큐
remove(5) : null
{1=에그마요, 3=스파이시쉬림프}- void clear() : 모든 Entry 삭제
- boolean isEmpty() : 비어있는지 확인
System.out.println("clear() 전 isEmpty() : " + map.isEmpty());출력 결과
clear() 전 isEmpty() : falsemap.clear(); // 모든 Entry 삭제함
System.out.println("clear() 후 isEmpty() : " + map.isEmpty());출력 결과
clear() 후 isEmpty() : trueMap 요소(Entry) 순차 접근 하기 1
- Map.keySet() 이용하기
public void method2() {
Map<String, String> map = new HashMap<String, String>();
map.put("학원", "서울시 중구");
map.put("집", "서울시 영등포구");
map.put("롯데타워", "서울시 송파구");
map.put("63빌딩", "서울시 영등포구");
// Set<K> Map.keySet() :
// - Map 에 있는 Key 만 뽑아내서 Set 형태로 만들어 반환
Set<String> set = map.keySet();
System.out.println("keySet : " + set);출력 결과
keySet : [집, 63빌딩, 학원, 롯데타워]
// 순서는 무작위향상된 for 문 + Set
for(String key : set) {
System.out.println(key + " : " + map.get(key));
}출력 결과
집 : 서울시 영등포구
63빌딩 : 서울시 영등포구
학원 : 서울시 중구
롯데타워 : 서울시 송파구Map 요소 (Entry) 순차 접근 하기 2
- Map.entrySet() 이용하기
public void method3() {
Map<String, String> map = new HashMap<String, String>();
map.put("학원", "서울시 중구");
map.put("집", "서울시 영등포구");
map.put("롯데타워", "서울시 송파구");
map.put("63빌딩", "서울시 영등포구");
Set<Entry<String, String>> entrySet = map.entrySet();
// 향상된 for 문 + EntrySet
// Entry.getKey() : Key 만 얻어오기
// Entry.getValue() : Value 만 얻어오기
for(Entry<String, String> entry : entrySet) {
System.out.printf("key : %s, value : %s\n",
entry.getKey(),entry.getValue()
);
}
}출력 결과
key : 집, value : 서울시 영등포구
key : 63빌딩, value : 서울시 영등포구
key : 학원, value : 서울시 중구
key : 롯데타워, value : 서울시 송파구Map 활용 하기 - DTO 대체하기
- 서로 다른 데이터를 한 번에 묶어서 관리해야하는 경우
DTO/VO 이용 방법
public void method4() {
Person p1 = new Person();
p1.setName("홍길동");
p1.setAge(25);
p1.setGender('남');
System.out.printf("이름 : %s, 나이 : %d, 성별 : %c\n",
p1.getName(), p1.getAge(), p1.getGender()
);출력 결과
이름 : 홍길동, 나이 : 25, 성별 : 남DTO 대신 Map 활용하기
- Key 는 무조건 String 을 활용하는 게 Best
- Value 의 타입이 모두 다름
-> Object 를 부모 타입 참조 변수로 활용
Map<String, Object> p2 = new HashMap<String, Object>();
// 데이터 추가
p2.put("name", "김길순");
p2.put("age", 22); // int -> Integer 변환
p2.put("gender", '여'); // char -> Character 변환
// 데이터 얻어오기
System.out.printf("이름 : %s, 나이 : %d, 성별 : %c\n",
p2.get("name"), p2.get("age"), p2.get("gender")
);출력 결과
이름 : 김길순, 나이 : 22, 성별 : 여Hashtable
키 객체 만드는 법은 HashMap과 동일하나 Hashtable은 스레드 동기화가 된 상태이기 때문에, 복수의 스레드가 동시에 Hashtable에 접근해 객체를 추가, 삭제 하더라도 스레드에 안전 (Thread safe)
ex) Map<K, V> map = new HashTable<K, V>();
Properties
(Key : Value) 형태
키와 값을 String타입으로 제한한 Map컬렉션
주로 Properties는 프로퍼티(*.properties)파일을 읽어 들일 때 주로 사용
프로퍼티(*.properties) 파일
- 옵션정보, 데이터베이스 연결정보, 국제화(다국어)정보를 기록하여 텍스트 파일로 활용
- 애플리케이션에서 주로 변경이 잦은 문자열을 저장하여 관리하기 때문에 유지보수를 편리하게 만들어 줌
- 키와 값이 ‘=‘기호로 연결되어 있는 텍스트 파일로 ISO 8859-1 문자셋으로 저장되고, 한글은 유니코드(Unicode)로 변환되어 저장
JavaAPI
Wrapper Class
-
wrap : 감싸다, 포장하다
-
기본 자료형을 객체로 감싸는 클래스
-> 기본 자료형의 객체화
-> 왜? 컬렉션처럼 객체만 취급하는 상황에서 기본 자료형도 취급 가능한 형태로 바꾸기 위해서--> BoxingUnboxing<--
boolean <--> Boolean
byte <--> Byte
short <--> Short
int <--> Integer
long <--> Long
float <--> Float
double <--> Double
char <--> Character
Boxing, Unboxing 을 자동으로 수행되도록 구현되어 있음
-> Auto Boxing, Auto Unboxing
Auto Boxing, Auto Unboxing 확인
import java.util.ArrayList;
import java.util.List;
public class JavaAPIService {
public void method1() {
int num1 = 100; // int
// 삭제 예정인 방법 (안 씀)
// Integer wrap1 = new Integer(num1);
Integer wrap1 = num1; // 컴파일러가 Auto Boxing 수행 코드 추가
// (int) num1 -> (Integer) num1
int num2 = wrap1; // 컴파일러가 Auto Unboxing 수행 코드 추가
// (Integer) wrap1 -> (int) wrap1 에 저장된 값
long num3 = 10_000_000_000L; // 100억
Long wrap2 = num3; // Auto Boxing
long num4 = wrap2; // Auto Unboxing
// Integer 객체만 저장하는 List
List<Integer> list = new ArrayList<Integer>();
list.add(1000); // (int) 1000 -> (Integer) 1000 Auto Boxing
list.add(2000); // (int) 2000 -> (Integer) 2000 Auto Boxing
list.add(3000); // (int) 3000 -> (Integer) 3000 Auto Boxing
System.out.println(list.get(0) + list.get(1) + list.get(2));
// 6000
// print 구문 내에서
// Wrapper 클래스로 만든 객체를 참조할 때
// .toString() 호출하는 것이 아닌
// Auto Unboxing 을 진행해서 기본 자료형으로 변경한다.
}Wrapper Class 가 제공하는 필드, 메소드
-> 대부분이 static
-> 클래스명.필드명 / 클래스명.메서드명() 사용
public void method2() {
// 정수형, 실수형 공통
System.out.println("byte의 용량 : " + Byte.BYTES + "바이트");
// byte의 용량 : 1바이트
System.out.println("byte의 용량 : " + Byte.SIZE + "비트");
// byte의 용량 : 8비트
System.out.println("byte의 최대값 : " + Byte.MAX_VALUE);
System.out.println("byte의 최소값 : " + Byte.MIN_VALUE);
// byte의 최대값 : 127
// byte의 최소값 : -128
// 실수형만 사용 가능 (딱히 쓸 일은 없음)
System.out.println(Double.NaN); // Not a Number
// NaN
System.out.println(Double.NEGATIVE_INFINITY); // 음수 무한대
System.out.println(Double.POSITIVE_INFINITY); // 양수 무한대
// Boolean(논리형)은 true/false 밖에 없음
System.out.println(Boolean.FALSE);
System.out.println(Boolean.TRUE);
// false
// true
System.out.println("[String -> 기본 자료형 변환]");
// HTML 연결 시 (요청 데이터 처리) 많이 사용
// -> HTML 에 관련된 모든 값은 String
// 단, char(Character)는 별도로 존재하지 않음.
byte b = Byte.parseByte("1"); // "" 안에 값이 HTML에서 넘겨준 값
short s = Short.parseShort("2");
int i = Integer.parseInt("3"); // 중요
long l = Long.parseLong("4"); // 중요
float f = Float.parseFloat("0.1");
double d = Double.parseDouble("0.2"); // 중요
boolean bool = Boolean.parseBoolean("true");
System.out.println("[기본 자료형 -> String 변환]");
// String 이어쓰기를 이용한 방법
// -> 코드는 짧으나 효율이 좋지 않음 (속도 down, 메모리 소모 up)
long test1 = 12345678910L;
String change1 = test1 +""; // long + String -> String
// Wrapper Class 를 이용하는 방법
// -> 코드는 길지만 효율이 좋음
int test2 = 400;
String change2 = Integer.valueOf(test2).toString();
double test3 = 4.321;
String change3 = Double.valueOf(test3).toString();
}String 의 불변성(immutable, 변하지 않는 성질 == 상수)
문자열이 수정되면 새로운 String 객체가 생성됨
public void method3() {
// System.identityHashCode(str)
// -> 주소 값을 이용해서 만든 해시코드(식별번호)
// -> 같은 객체에 저장된 값이 변했다면 주소는 일정해야 된다.
// identityHashCode 도 일정해야된다.
String str = "hello";
System.out.println(str);
System.out.println(System.identityHashCode(str));
// 1651191114
str = "world";
System.out.println(str);
System.out.println(System.identityHashCode(str));
// 1586600255
str += "!!!";
System.out.println(str);
System.out.println(System.identityHashCode(str));
// 943010986
}String 리터럴("")로 생성된 객체 활용
동일한 리터럴을 이용해 String 객체를 생성한 경우
추가적으로 객체를 생성하지 않고 기존에 존재하는 String 객체의 주소를 반환(재활용)
public void method4() {
String temp1 = "Hello!!";
String temp2 = "Hello!!";
System.out.println(System.identityHashCode(temp1));
System.out.println(System.identityHashCode(temp2));
// 1865127310
// 1865127310
// 객체의 필드 값을 비교
System.out.println("저장된 값 비교 : " + temp1.equals(temp2));
// 저장된 값 비교 : true
// 변수에 저장된 값(주소) 비교
System.out.println("주소를 비교 : " + (temp1 == temp2));
// 주소를 비교 : true
}사용자(개발자)가 관리하는 String 객체 생성
"" 리터럴로 생성된 String -> 상수풀 (JVM 관리)
new 연산자로 생성된 String -> Heap 영역 (사용자 관리)
public void method5() {
String temp1 = "abcd"; // 리터럴로 생성
String temp2 = new String("abcd"); // new 연산자로 생성
String temp3 = new String("abcd"); // new 연산자로 생성
System.out.println("temp1 : " + System.identityHashCode(temp1));
System.out.println("temp2 : " + System.identityHashCode(temp2));
System.out.println("temp3 : " + System.identityHashCode(temp3));
// temp1 : 1865127310
// temp2 : 1744347043
// temp3 : 1254526270
// 셋 다 주소가 다름 == "abcd" 를 재활용하지 않음
// -> 값은 같지만 전부 다른 객체
temp2 += "efg";
System.out.println("efg temp2 : " + System.identityHashCode(temp2));
// efg temp2 : 1618212626
// 이어쓰기 했어도 Heap 영역에 새 객체 생성
// 기존 temp2 해시코드와 다르다 --> 다른 객체
}StringBuilder / StringBuffer 클래스
String 의 불변성 문제를 해결한 클래스
-> 가변성(mutable)
기본 16글자 저장할 크기로 생성
저장되는 문자열의 길이에 따라 크기가 증가/감소
-> 마음대로 문자열 수정, 삭제 가능
-> 수정, 삭제를 해도 추가적인 객체 생성이 없어 효율 좋음
StringBuilder : Thread Safe 미제공 (비동기)
: 속도면에서는 StringBuffer 보다 성능 좋음
-> 멀티쓰레드 환경에서는 StringBuilder 사용 시
쓰레드 충돌 가능성 있음 -> 글자가 깨지거나 오류 발생
-> 단일쓰레드 환경에서 유리 (추천) (멀티쓰레드를 안 만들어서)
StringBuffer : Thread Safe 제공 (동기)
: 속도면에서는 StringBuilder 보다 성능 떨어짐
-> 멀티쓰레드 환경에서 안전하게 동작할 수 있음
-> 멀티쓰레드 환경에서 유리
public void method6() {
// StringBuilder 객체 생성
StringBuilder sb = new StringBuilder();
// StringBuilder 객체에 문자열을 쌓아 나가는 방식으로 사용
// -> 뒤에 추가(append), 앞에 추가(insert)
sb.append("오늘 점심은 "); // "오늘 점심은 "
System.out.println(System.identityHashCode(sb));
// 1865127310
sb.append("무엇을 먹을까요?"); // "오늘 점심은 무엇을 먹을까요?"
System.out.println(System.identityHashCode(sb));
// 1865127310
sb.insert(0, "2월 21일 "); // 0번 인덱스에 삽입 == 제일 앞에 추가
System.out.println(System.identityHashCode(sb));
// 1865127310
// 해시코드 같음 같은 객체 참조
System.out.println(sb);
// identityHashCode 값이 일정함
// == 참조하는 객체가 변하지 않음
// == 객체 내에 값만 수정되고 있다 == 가변성
// StringBuilder -> String 변환
String temp = sb.toString(); // 객체에 저장된 필드를 문자열로 반환
// String[] 만자열.split("구분자")
// - 문자열을 "구분자"를 기준으로 쪼개어 String[]로 반환
String[] arr= temp.split(" ");
for(String str : arr) {
System.out.println(str);
}
System.out.println("=======================================");
//equalsIgnoreCase() : 문자열을 비교할 때 대소문자를 무시하고 비교하는 메서드
String str1 = "hello";
String str2 = "HELLO";
if(str1.equalsIgnoreCase(str2)) {
System.out.println("두 문자열은 동일합니다.");
} else {
System.out.println("두 문자열은 다릅니다.");
}
}
}