
✅ 한눈에 보는 정규식
| 패턴 | 의미 |
|---|---|
| a-zA-Z | 영어알파벳(-으로 범위 지정) |
| ㄱ-ㅎ가-힣 | 한글 문자(-으로 범위 지정) |
| 0-9 | 숫자(-으로 범위 지정) |
| . | 모든 문자열 |
\d | 숫자 |
\D | 숫자가 아닌 것 |
\w | 영어 알파벳, 숫자, 언더스코어(_) |
\W | \w 가 아닌 것 |
\s | space 공백 |
\S | space 공백이 아닌 것 |
\특수기호 | 특수기호 |
| ^문자열 | 특정 문자열로 시작 |
| 문자열$ | 특정 문자열로 종료 |
| [^문자열] | 괄호안의 문자열를 제외 |
| [문자열] | 괄호 안의 문자열중 하나(OR) |
| {m,n} | m이상 n이하 |
| {m,} | m개 이상 |
| ? | 최대 한 번만 나타남(없거나 한 번) |
| + | 최소 한 번 이상 반복 |
🖋️ 정규표현식
- 정규 표현식은 일정한 패턴을 가진 문자열의 집합을 표현하기 위해 사용하는 형식 언어다.
- 정규 표현식은 문자열을 대상으로 패턴 매칭 기능을 제공한다. 패팅 매칭 기능이란 특정 패턴과 일치하는 문자열을 검색하거나 추출 또는 치환할 수 있는 기능을 말한다.
숫자 3개 + ' - ' + 숫자 4개 + ' - ' + 숫자 4개라는 일정한 패턴으로 이루어진 휴대폰 전화번호 패턴을 확인하고자 할 때 정규식을 사용할 수 있다.const tel = '010-1234-567팔'; const regExp = /^\d{3}-\d{4}-\d{3}$/; regExp.test(tel); // false
🖋️ 정규 표현식의 생성
정규 표현식 객체를 생성하기 위해서는 정규 표현식 리터럴과 RegExp 생성자 함수를 사용할 수 있다. 일반적인 방법은 정규 표현식 리터럴을 사용하는 것이다.
✒️ 정규 표현식 리터럴
const target = 'Is this all there is?'; //패턴 : is //플래그: i => 대소문자를 구별하지 않고 검색한다. const regexp = /is/i; regexp.test(target); // true
✒️ RegExp 생성자 함수
new RegExp(pattern [, flags])const target = 'Is this all there is?'; const regexp = new RegExp(/is/i); regexp.test(target); //true
- 동적으로 RegExp 객체를 생성할 수 있다.
const count = (str, char) => (str.match(new RegExp(char, 'gi')) ?? []).length; console.log(count('is this is good', 'is')); //3
🖋️ RegExp 메서드
✒️ exec
- exec 메서드는 인수로 전달받은 문자열에 대해 정규 표현식의 패턴을 검색하여 매칭 결과를 배열로 반환한다. 매칭 결과가 없는 경우 null을 반환한다. ❗ g플래그가 반영되지 않는다.
const target = 'Is this all there is?'; const regExp = /is/; regExp.exec(target); // [ 'is', index: 5, input: 'Is this all there is?', groups: undefined ]
✒️ test
- test 메서드는 인수로 전달받은 문자열에 대해 정규 표현식의 패턴을 검색하여 매칭 결과를 boolean 값으로 반환한다.
regExp.test(target)const target = 'Is this all there is?'; const regExp = /is/; regExp.test(target); // true
✒️ match
- String 표준 빌트인 객체가 제공하는
match메서드는 대상 문자열과 인수로 전달받은 정규 표현식과의 매칭결과를 배열로 반환한다.target.test(regExp)const target = 'Is this all there is?'; const regExp = /is/; target.match(regExp); // [ 'is', index: 5, input: 'Is this all there is?', groups: undefined ]
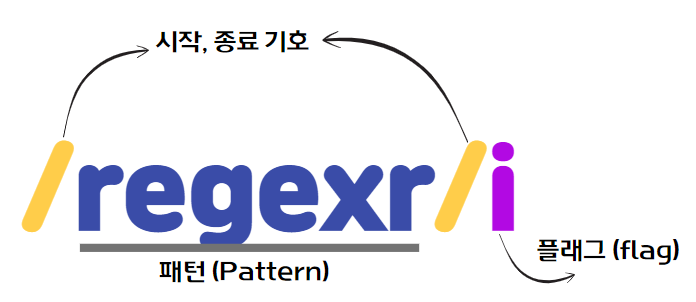
🖋️ 플래그(Flag)
- 패턴과 함께 정규 표현식을 구성하는 플래그는 정규 표현식의 검색 방식을 설정하기 위해 사용한다.
플래그 의미 설명 i Ignore case 대소문자를 구별하지 않고 패턴을 검색한다. g Global 대상 문자열 내에서 패턴과 일치하는 모든 문자열을 전역 검색한다. m Multi line 문자열의 행이 바뀌더라도 패턴 검색을 계속한다. const targetStr = 'Is this all there is?'; // 문자열 is를 대소문자를 구별하여 한번만 검색한다. let regexr = /is/; console.log(targetStr.match(regexr)); // [ 'is', index: 5, input: 'Is this all >there is?' ] // 문자열 is를 대소문자를 구별하지 않고 대상 문자열 끝까지 검색한다. regexr = /is/ig; console.log(targetStr.match(regexr)); // [ 'Is', 'is', 'is' ] console.log(targetStr.match(regexr).length); // 3
🖋️ 패턴(Patter)
- 패턴은 /로 열고 닫으며 문자열의 따옴표는 생략한다. 따옴표를 포함하면 따옴표까지도 패턴에 포함되어 검색된다.
- 또한 패턴은 특별한 의미를 가지는 메타문자(Metacharacter) 또는 기호로 표현할 수 있다.
✒️ 문자열 검색
- 정규 표현식의 패턴에 문자 또는 문자열을 지정하면 검색 대상 문자열에서 패턴으로 지정한 문자 또는 문자열을 검색한다.
const target = 'Is this all there is?'; const regExp = /is/; //대소문자를 구별하여 is가 있는지. const regExp2 = /is/i; //대소문자를 구별하지 않고 is가 >있는지 const regExp3 = /is/ig; //대소문자를 구별하지 않고 모든 >문자열에서 검색 regExp.test(target); // true target.match(regExp2); // [ 'Is', index: 0, input: 'Is >this all there is?', groups: undefined ] target.match(regExp3); // ["Is", "is", "is"]
✒️ 임의의 문자열 검색
.은 임의의 문자 한 개를 의미한다. 문자의 내용이 무엇이든 상관없다.const target = 'Is this all there is?'; const regExp = /.../g; //3자리의 문자열을 전체에서 >찾는다. target.match(regExp); // [ 'Is ', 'thi', 's a', 'll >', 'the', 're ', 'is?' ]
✒️ 반복 검색
- {m,n}은 앞선 패턴이 최소 m번, 최대 n번 반복되는 문자열을 의미한다.
*는 앞선 문자가 0 회 이상 반복되는 부분과 대응한다.const target = 'A AA B BB Aa Bb AAA'; //A가 최소 1번, 최대 2번 반복되는 문자열을 전역 검색한다. const regExp = /A{1,2}/g; console.log(target.match(regExp)); // [ 'A', 'AA', 'A', 'AA', 'A' ] //{n}은 앞선 패턴이 n번 반복되는 문자열을 의미한다. const regExp2 = /A{2}/g; console.log(target.match(regExp2));// [ 'AA', 'AA' ] //{n,}은 앞선 패턴이 최소 n번 이상 반복되는 문자열을 의미한다. const regExp3 = /A{2,}/g; console.log(target.match(regExp2));// [ 'AA', 'AAA' ] // +는 앞선 패턴이 최소 한번 이상 반복되는 문자열을 의미한다.즉, +는 { 1,}과 같다. const target = 'A AA B BB Aa Bb AAA'; const regExp = /A+/g; //A가 한 번 이상 반복되는 문자열 -> A로만 이루어진 문자열을 의미. target.match(regExp); // [ 'A', 'AA', 'A', 'AAA' ] // ?는 앞선 패턴이 최대 한 번이상 반복되는 문자열을 의미한다. 즉, ? 는 { 0, 1 }과 같다. const target = 'color colour colouur'; const regExp = /colou?r/g; //colouur은 해당되지 않는다. u가 2번 반복되기 때문이다. target.match(regExp); // [ 'color', 'colour' ] target = 'aasfdfvaeh111'; console.log(target.match(/[A-Za-z]*/)); //[ >'aasfdfvaeh']
✒️ OR 검색
- /A|B/는 A또는 B를 의미한다.
const target = 'A AA B BB Aa Bb AAA'; const regExp = /A|B/g; target.match(regExp); // [ 'A', 'A', 'A', 'B', 'B', 'B', 'A', 'B', 'A', 'A', 'A' ] //범위를 지정하려면 [] 내에 -를 사용한다. const target = 'A AA B BB Aa Bb AAA'; const regExp = /[A-Z]+/g; // 대문자 판별 정규 표현식 target.match(regExp); // [ 'A', 'AA', 'B', 'BB', 'A', 'B', 'AAA' ] const target = 'A AA B BB Aa Bb AAA'; const regExp = /A|B/g; target.match(regExp); // [ 'A', 'A', 'A', 'B', 'B', 'B', 'A', 'B', 'A', 'A', 'A' ] //분해되지 않은 단어 레벨로 검색하려면 +를 함께 사용한다. const regExp2 = /A+|B+/g; //A가 1번 이상 B가 1번 이상. //위 코드와 아래 코드는 동일하다. const regExp3 = /[AB]+/g; //[]내의 문자는 or로 동작한다. target.match(regExp); //['A', 'AA', 'B', 'BB', 'Aa', 'Bb', 'AAA'] //범위를 지정하려면[] 내에 - 를 사용한다. const target = 'A AA B BB Aa Bb AAA'; const regExp = /[A-Z]+/g; // 대문자 판별 정규 표현식 const regExp2 = /[A-Za-z]+/g; //알파벳 판별 target.match(regExp); // [ 'A', 'AA', 'B', 'BB', 'A', 'B', 'AAA' ]
✒️ 그룹핑
- ( )는 문자열을 묶음 처리할 때 사용
- ( )로 둘러싼 부분은 각각 하나의 덩어리로 취급해서,
검색시 ( ) 안에 해당되는 내용들을 변경할 내용에서 그대로 가져다 이용할 수 있다.a(bc)* a 다음에 bc가 0개 이상 (묶음 처리) a(bc){1,5} a 다음에 bc가 1개에서 5개 사이 // \1은 이전에 일치한 그룹을 의미한다. 이전에 일치한 문자가 1번 이상 반복될 때 매칭한다. /(.)\1+/g => ssongs 의 경우 ss
✒️ 숫자 검색 방법
const target1 = 'AA BB 12,345'; const regExp = /[0-9]+/g; let regExp2 = /[\d]+/g; //모든 숫자를 찾아라. target1.match(regExp); // ["12", "345"] let regExp32 = /[\D]+/g; //d와 반대로 동작. -> 숫자가 아닌 문자를 찾아라. console.log(target1.match(regExp32)); // ["AA BB ", ',']
✒️ 알파벳, 숫자, 언더스코어 검색방법
const target = 'Aa Bb 12,345 _$%&'; let regExp = /[\w,]+/g; // == [A-Za-z0-9_] let regExp2 = /[\W]+/g; //알파벳, 숫자, 언더스코어가 아닌 문자열을 찾아라. target.match(regExp); // [ 'Aa', 'Bb', '12,345', '_' ]
✒️ NOT 검색
- [...]내의 ^ 은 not의 의미를 갖는다.
const target = 'AA BB 12 Aa Bb'; const regExp = /[^0-9]+/g; // 숫자를 제외한 문자열 target.match(regExp); // ["AA BB Aa Bb"]
✒️ 문자열 시작 판별
- [...]밖의 ^ 은 문자열의 시작을 의미한다.
const target = 'https://google.com'; const regExp = /^https/; //http로 시작하는지. regExp.test(target); // true
✒️ 문자열 마지막 판별
- $는 문자열의 마지막을 의미한다.
const target = 'https://google.com'; const regExp = /com$/; //com으로 끝나는지. regExp.test(target); // true
🖋️ 자주 사용하는 정규표현식
✒️ 특정 단어로 시작하는지
const url = 'http://example.com'; // 'http'로 시작하는지 검사 // ^ : 문자열의 처음을 의미한다. console.log(/^http/.test(url)); // true
✒️ 특정 단어로 끝나는지
const fileName = 'index.html'; // 'html'로 끝나는지 검사 // $ : 문자열의 끝을 의미한다. console.log(/html$/.test(fileName)); // true
✒️ 숫자인지 검사
const targetStr = '12345'; // 모두 숫자인지 검사 // 처음과 끝이 숫자이고 하나 이상 반복되는가? console.log(/^\d+$/.test(targetStr)); // true
✒️ 하나 이상의 공백으로 시작하는지 검사
const targetStr = ' Hi!'; // 1개 이상의 공백으로 시작하는지 검사 // \s : 여러 가지 공백 문자를 의미한다.(스페이스, 탭 등) === [\t\r\n\v\f] console.log(/^[\s]+/.test(targetStr)); // true
✒️ 아이디로 사용 가능한지 검사(영문자, 숫자만 허용, 4~10자리)
const id = 'abc123'; // 알파벳 대소문자 또는 숫자로 시작하고 끝나면서 4 ~10자리인지 검사 // {4,10}: 4 ~ 10자리 console.log(/^[A-Za-z0-9]{4,10}$/.test(id)); // true
✒️ 메일 주소 형식에 맞는지 검사
const email = 'songdh21@gmail.com'; const regexr = /^[0-9a-zA-Z]([-_\.]?[0-9a-zA-Z])*@[0-9a-zA-Z]([-_\.]?[0-9a-zA-Z])*\.[a-zA-Z]{2,3}$/; console.log(regexr.test(email)); // true
✒️ 핸드폰 번호 형식에 맞는지 검사
console.log(/^\d{3}-\d{3,4}-\d{4}$/.test(cellphone)); // true
✒️ 특수 문자 포함 여부 검사
const targetStr = 'abc#123'; // A-Za-z0-9 이외의 문자가 있는지 검사 console.log((/[^A-Za-z0-9]/gi).test(targetStr)); // true // 아래 방식도 동작한다. 이 방식의 장점은 특수 문자를 선택적으로 검사할 수 있다. regexr = /[\{\}\[\]\/?.,;:|\)*~`!^\-_+<>@\#$%&\\\=\(\'\"]/gi; console.log(regexr.test(targetStr)); // true // 특수 문자 제거 console.log(targetStr.replace(regexr, '')); // abc123
<모던 자바스크립트 deepdive와, 추가 탐구한 내용을 정리한 포스트입니다.>

wanna be bright person✨ Front-End developer