
1. Pandas
- Panel Datas 의 약자
- 다양한 파일 형식 지원(excel, csv, DB...)
- 데이터 정제 및 조작 특화
- 데이터 이상치, 결측치, 중복 제거 등 필요한 기능을 제공
- 데이터 필터링, 병합, 피벗 등을 지원하여 복잡한 데이터를 쉽게 분석할 수 있음.
- Series와 DataFrame 자료구조 제공
- 기본 적으로 ndarray를 기반으로 만들어져 있음 -> numpy 함수 활용 가능
1.1. Series
- 1차원 배열 형태의 데이터 구조
- index + value 구조
- Series들의 모임 -> DataFrame
1.2. DataFrame
- 2차원 배열 형태의 데이터 구조
- column + row 구조
2. Series (1차원 배열 데이터) 다루기
- import
# numpy 라이브러리 불러오기
import numpy as np
# pandas 라이브러리 불러오기
import pandas as pd- 데이터 활용 해보기 !
# 배열 생성
pd.Series([9668465, 3391946, 2942828, 1450062])
# 인덱스에 지역이름 넣기
pop = pd.Series([9668465, 3391946, 2942828, 1450062],
index = ['서울', '부산', '인천', '광주'])
# Series index 확인
pop.index
=> Index(['서울', '부산', '인천', '광주'], dtype='object')
# Serise에 이름 지정 (= column 명 지정)
pop.name = '인구'
# Series index들의 이름 지정
pop.index.name = '도시'
pop
=> 도시
서울 9668465
부산 3391946
인천 2942828
광주 1450062
Name: 인구, dtype: int64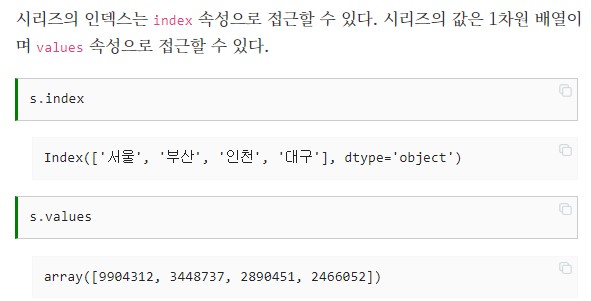
2.1. Series 연산
# Series 연산
pop / 1000000
# Series Boolan 인덱싱
# 250만 이상인 데이터를 추출
pop[pop >= 2500000]
# 인구수가 250만 이상, 500만 이하인 데이터 추출
# and 는 비교 연산자, 단일 값에 대해서만 가능
# &는 논리 (비트) 연산자, 다중 값에 대해서만 가능
# (Series는 기본적으로 다중 값)
(pop >= 2500000) & (pop < 5000000)2.2. Series Boolan 인덱싱
인구 250만 이상인 데이터를 추출
pop[pop >= 2500000]도시
서울 9668465
부산 3391946
인천 2942828
Name: 인구, dtype: int64
인구수가 250만 이상, 500만 이하인 데이터 추출
- and 는 비교 연산자, 단일 값에 대해서만 가능
- &는 논리 (비트) 연산자, 다중 값에 대해서만 가능(Series는 기본적으로 다중 값)
(pop >= 2500000) & (pop < 5000000)도시
서울 False
부산 True
인천 True
광주 False
Name: 인구, dtype: bool
2.3. Series 다루기 실습!
# 딕셔너리 방식으로, Series 생성
# 월 급여
data1 = {'IT기획자':8644000 ,
'데이터분석가':7158000 ,
'응용SW개발자':6426000 ,
'IT품질관리자':8294000 }
data2 = {'IT기획자':9543000 ,
'데이터분석가':11226000 ,
'시스템SW개발자':5100000 ,
'IT마케터':7801000 }
# 형변환 방식으로..
com1 = pd.Series(data1)
com2 = pd.Series(data2)
com1
com2IT기획자 8644000
데이터분석가 7158000
응용SW개발자 6426000
IT품질관리자 8294000
dtype: int64
IT기획자 9543000
데이터분석가 11226000
시스템SW개발자 5100000
IT마케터 7801000
dtype: int64
# 일 평균임금 계산
# 실제 일평균 임금은 3개월 간의 총 임글을 그기간의 총 일수로 나눠서 산정
# 근데 우리는 실습이니까 대충 일한 일수로 계산해보자 !
(com1 / 23).astype(int)
# 또는 com1 // 23IT기획자 375826
데이터분석가 311217
응용SW개발자 279391
IT품질관리자 360608
dtype: int32
# 두 회사의 차이 비교
# 짝이 없는 경우 NaN(Not a Number)값을 반환
wege_minus = com1 - com2
wege_minusIT기획자 -899000.0
IT마케터 NaN
IT품질관리자 NaN
데이터분석가 -4068000.0
시스템SW개발자 NaN
응용SW개발자 NaN
dtype: float64

3. DataFrame
pandas에서 제공하는 2차원 자료구조
# 첫 번째 방법 : 딕셔너리 -> 컬럼 단위로 생성
data = {'ITPM':[463,9543,57],
'업무분석가':[544,11226,68],
'IT아키텍트':[518,10672,64],
'UIUX개발자':[291,6003,36]}
# DataFram화 하여 생성
df = pd.DataFrame(data)
# DataFrame index명 수정
df.index = ['일평균 임금','월평균임금','시간평균임금']
df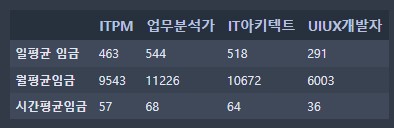
# 두번째 방법 : list -> 행(row)단위로 생성
data2 = [[463,455,518,291],
[9543,11226,10672,6003],
[57,68,64,36]]
columns = ['ITPM','업무분석가','IT아키텍트','UIUX개발자']
row = ['일평균임금','월평균임금','시간평균임금']
df = pd.DataFrame(data2, index=row, columns=columns)
df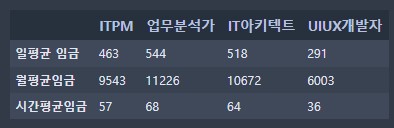
Transpose -> T
- 실행자체로는 데이터가 변형되진 않음
- 행열의 위치를 뒤 바꿈 -> 전치
df.T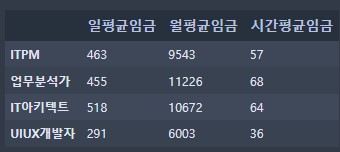
- 해당 방식으로 데이터 값 확인가능
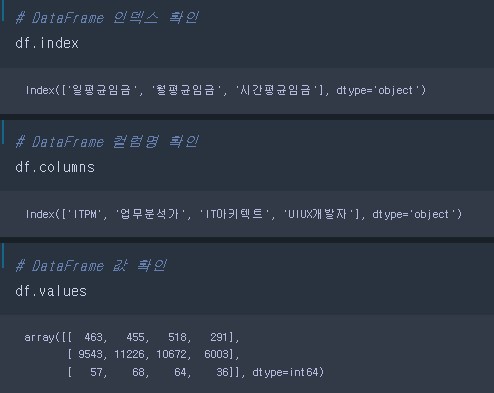
3.1. DataFrame 인덱싱, 슬라이싱
- DataFrame은 Series들의 모임
- DataFrame 인덱싱(열 접근) : 하나의 Series를 가져옴
- DataFrame 슬라이싱 : 여러개의 Series(DataFrame) 반환
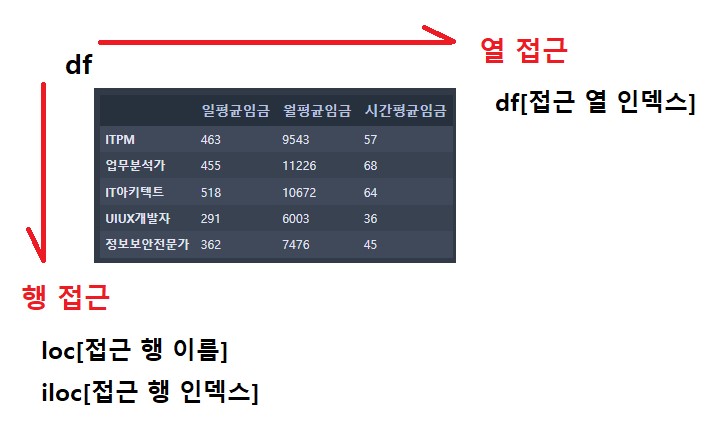
열 접근 방식
# DataFrame 인덱싱(열 접근)
df[['ITPM']]
# 다중 인덱싱
# 다중으로 인덱싱을 진행할 경우 Series로는 표현할 수 없음...
# 그래서 대괄호로 한번 더 감싸서 2차원 DataFrame으로 반환 할 수 있음 !
df[['ITPM','IT아키텍트']]열 접근 방식 2
# 1. 과목별 합계를 구하여 '합계'라는 컬럼 생성
score['합계'] = score.loc[:'Web',:'5반'].sum(axis=1)
score| 1반 | 2반 | 3반 | 4반 | 5반 | 합계 | |
|---|---|---|---|---|---|---|
| 과목 | ||||||
| 파이썬 | 45 | 44 | 73 | 39 | 85 | 286 |
| DB | 76 | 92 | 45 | 69 | 88 | 370 |
| 자바 | 47 | 92 | 45 | 69 | 93 | 346 |
| 크롤링 | 92 | 81 | 85 | 40 | 99 | 397 |
| Web | 11 | 79 | 47 | 26 | 90 | 253 |
3.2. DataFrame 슬라이싱 -> index(인덱서)활용
-
loc[] 인덱서(속성)
- location(위치) : 인덱스명, 컬럼명을 가지고 값을 인덱싱/슬라이싱을 도와주는 인덱서
- DataFrame명.loc[행의시작 이름 : 행의끝 이름 , 열의시작 이름: 열의끝 이름]
- 끝 값을 포함 !
-
iloc[] 인덱서
- integer location(정수 위치) : 인덱스 번호, 컬럼 번호를 가지고 값을 인덱싱/슬라이싱을 도와주는 인덱서
- DataFrame명.iloc[행의시작 번호 : 행의끝 번호 , 열의시작 번호: 열의끝 번호]
- 끝값을 미포함 !
행 접근 방식
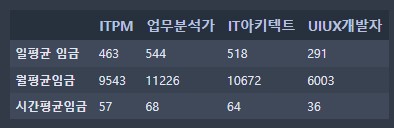
# 인덱서 활용 -> 인덱싱
df.loc['시간평균임금'] # 행 접근
df.iloc[2]행 접근 방식 2
# 2. 반별로 평균을 구해서 '반평균'이라는 행 생성
score.loc['반평균'] = score.loc[:'Web',:'5반'].mean(axis=0)
score| 1반 | 2반 | 3반 | 4반 | 5반 | 합계 | |
|---|---|---|---|---|---|---|
| 과목 | ||||||
| 파이썬 | 45.0 | 44.0 | 73.0 | 39.0 | 85.0 | 286.0 |
| DB | 76.0 | 92.0 | 45.0 | 69.0 | 88.0 | 370.0 |
| 자바 | 47.0 | 92.0 | 45.0 | 69.0 | 93.0 | 346.0 |
| 크롤링 | 92.0 | 81.0 | 85.0 | 40.0 | 99.0 | 397.0 |
| Web | 11.0 | 79.0 | 47.0 | 26.0 | 90.0 | 253.0 |
| 반평균 | 54.2 | 77.6 | 59.0 | 48.6 | 91.0 | NaN |
# 행과 열 접근 방식 실습문제
# 실습 1. 일평균 임금이 400 이상인 DataFeame을 반환 !
df[(df['일평균임금'] >= 400)]
# 실습 2. 직업이 업무분석가와 정보보안전문가 만 DataFrame 추출 후
# 시간평균 임금이 50이상인 직업을 불리언 인덱싱 하라 !
temp = df.loc[['업무분석가','정보보안전문가']]
temp[temp['시간평균임금'] >= 50]4. population 실습 - 값의 카운팅, 정렬
# 자료 불러오기
# read_000("경로(파일명.확장자)") -> 해당 파일 불러오기
# index_col : 해당 컬럼을 인덱스 명으로 사용하겠다 !
pop = pd.read_csv('./data/population.csv', index_col='도시')
pop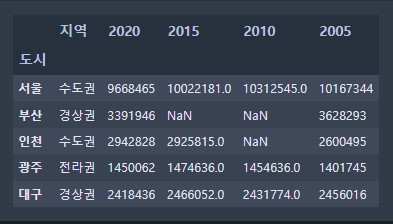
pop['열'].value_counts()
# 각각의 값이 나온 횟수를 세어주는 기능
pop['지역'].value_counts()수도권 2
경상권 2
전라권 1
Name: 지역, dtype: int64
# value_counts 는 NaN의 경우 count 되지 않음 !
pop['2010'].value_counts()2431774.0 1
10312545.0 1
1454636.0 1
Name: 2010, dtype: int64
pop.sort_index()
- pop.sort_values(by='2005', ascending=False)
# 정렬
# 인덱스를 기준으로 정렬
# ascending = True -> 오름차순, False -> 내림차순(기본값)
# ascending에서 NaN 값은 항상 오름차순 , 내림차순 관계 없이 항상 마지막에 정렬 !
display(pop.sort_index())
display(pop.sort_index(ascending=False))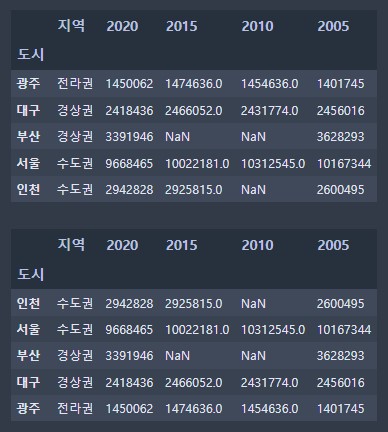
pop.sort_values()
# 정렬
# 값을 기준으로 정렬
# DataFrame
# by : 기준이될 컬럼 지정
display( pop.sort_values(by='2005', ascending=False) )
# Series
# Series로 접근시 by 속성은 필요 없음 !
display( pop['2015'].sort_values( ascending=False) )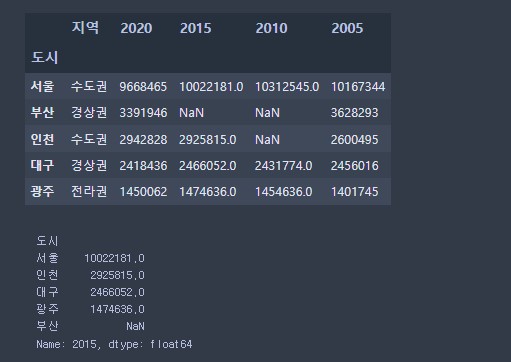
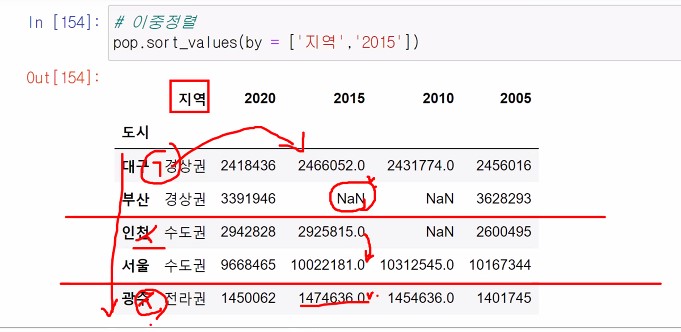
# 이중정렬
pop.sort_values(by = ['지역','2015'])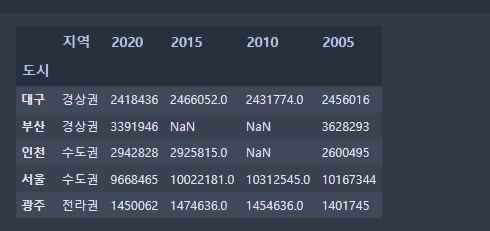
- 이중 정렬 다음과 같이 정리해줌
5. pandas 축 (axis)
- 교육에서는 3차원 않함.
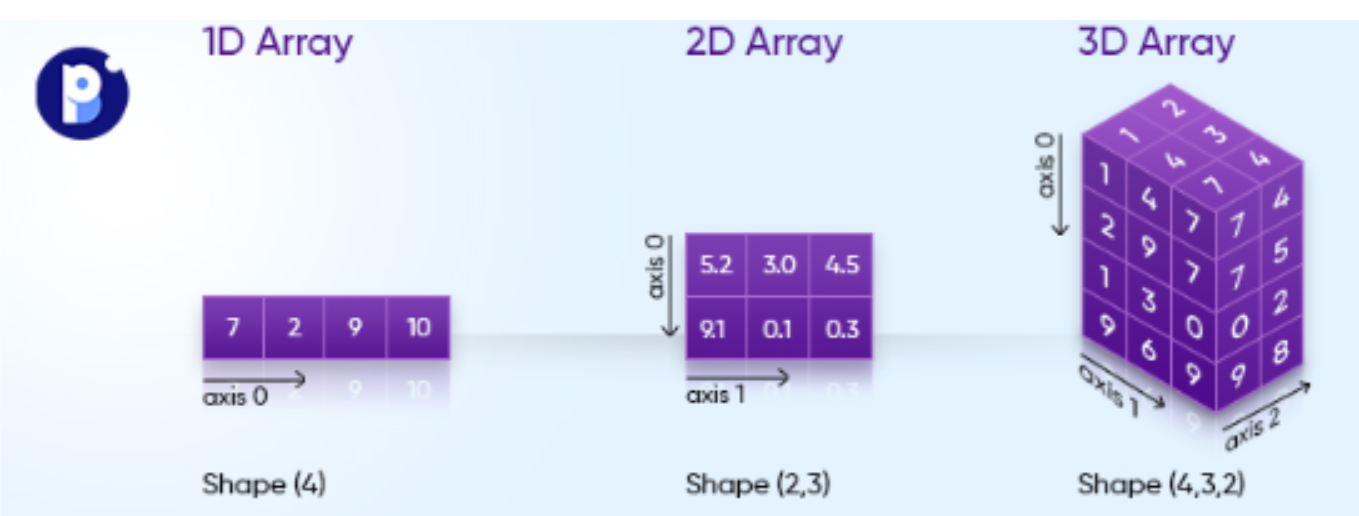
# 합 계 : sum()
# axis = 0 : 기본값, 위아래(행방향)
# aixs = 1 : 양옆(열방향)
score.sum()1반 271
2반 388
3반 295
4반 243
dtype: int64
# 컬럼(열) 추가
score['5반'] = [85,88,93,99,90]실습
# 1. 과목별 합계를 구하여 '합계'라는 컬럼 생성
score['합계'] = score.loc[:'Web',:'5반'].sum(axis=1)
# 2. 반별로 평균을 구해서 '반평균'이라는 행 생성
score.loc['반평균'] = score.loc[:'Web',:'5반'].mean(axis=0)
score| 1반 | 2반 | 3반 | 4반 | 5반 | 합계 | |
|---|---|---|---|---|---|---|
| 과목 | ||||||
| 파이썬 | 45.0 | 44.0 | 73.0 | 39.0 | 85.0 | 286.0 |
| DB | 76.0 | 92.0 | 45.0 | 69.0 | 88.0 | 370.0 |
| 자바 | 47.0 | 92.0 | 45.0 | 69.0 | 93.0 | 346.0 |
| 크롤링 | 92.0 | 81.0 | 85.0 | 40.0 | 99.0 | 397.0 |
| Web | 11.0 | 79.0 | 47.0 | 26.0 | 90.0 | 253.0 |
| 반평균 | 54.2 | 77.6 | 59.0 | 48.6 | 91.0 | NaN |
# 삭제
# 컴럼 삭제시 del 객체 활용
del score['반평균']
# del 객체로는 행 삭제불가...
# del score.loc['반평균']
# drop('행이름') -> 행 삭제하는 기능
# inplace = True -> 반영(함수 사용 시 즉시 적용)
score.drop('반평균', inplace = True)
# astype() inplace 속성이 없음 !
# 속성이 있는 경우 활용해서 반영, 아니면 새로 대입
score = score.astype(np.int64)
score. apply()
apply() 사용 예시 (1)
- pandas 객체에 열 혹은 행 방향으로 함수를 적용하게 해주는 함수
- 다른 라이브러리의 함수를 적용 시킬 수 있는 방법
# apply() 적용 안하는 경우
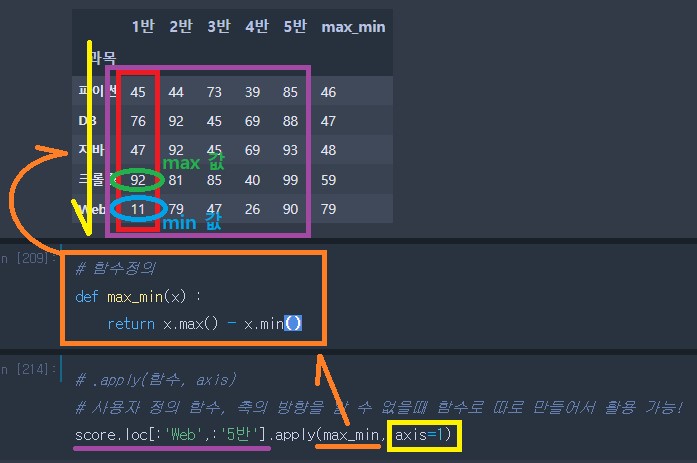
# 과목별로 최대값과 최소값의 차이를 'max_min'이라는 컬럼으로 추가!
score_max = score.loc[:'Web',:'5반'].max(axis=1)
score_min = score.loc[:'Web',:'5반'].min(axis=1)
score['max_min'] = score_max - score_min
score| 1반 | 2반 | 3반 | 4반 | 5반 | max_min | |
|---|---|---|---|---|---|---|
| 과목 | ||||||
| 파이썬 | 45 | 44 | 73 | 39 | 85 | 46 |
| DB | 76 | 92 | 45 | 69 | 88 | 47 |
| 자바 | 47 | 92 | 45 | 69 | 93 | 48 |
| 크롤링 | 92 | 81 | 85 | 40 | 99 | 59 |
| Web | 11 | 79 | 47 | 26 | 90 | 79 |
# .apply() 적용예시
# 함수정의
def max_min(x) :
return x.max() - x.min()
# 사용자 정의 함수, 축의 방향을 알 수 없을때 함수로 따로 만들어서 활용 가능!
score.loc[:'Web',:'5반'].apply(max_min, axis=1)과목 파이썬 46 DB 47 자바 48 크롤링 59 Web 79 dtype: int64
- 위 과목 apply() 과정
apply() 사용 예시 (2)
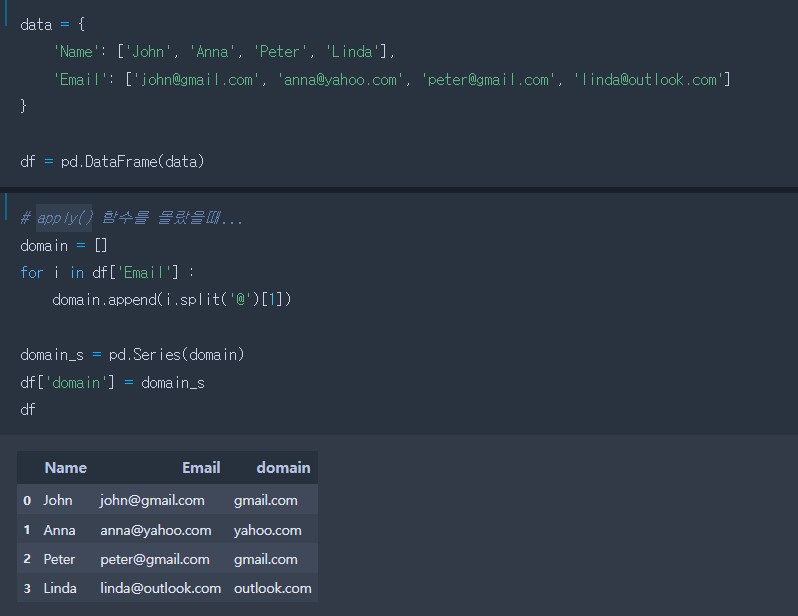
# apply 함수 활용 !
def extract_domain(email) :
# '@'기호를 기준으로 이메일 주소를 분할하는 함수를 정의
return email.split('@')[1]
# str -> 문자열 함수를 다룰 수 있게씀 인식
# str로 수행할 경우 반복문 사용햐여 함...
df['Email'].str.split('@')
df['domain'] = df['Email'].apply(extract_domain)
df| Name | domain | ||
|---|---|---|---|
| 0 | John | john@gmail.com | gmail.com |
| 1 | Anna | anna@yahoo.com | yahoo.com |
| 2 | Peter | peter@gmail.com | gmail.com |
| 3 | Linda | linda@outlook.com | outlook.com |
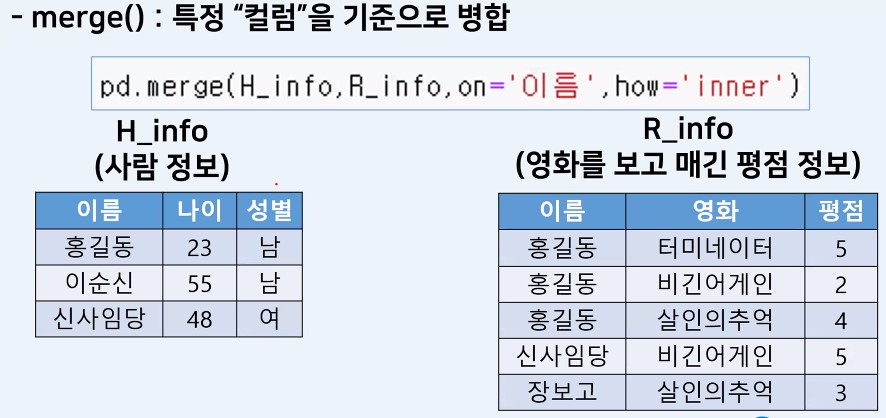
병합
- merge() : 특정 컬럼을 기준으로 병합
- concat() : 축의 방향을 기준으로 이어 붙이다.
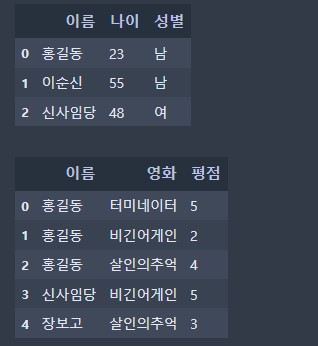
다음과 같은 데이터를 병합 하고자 한다.
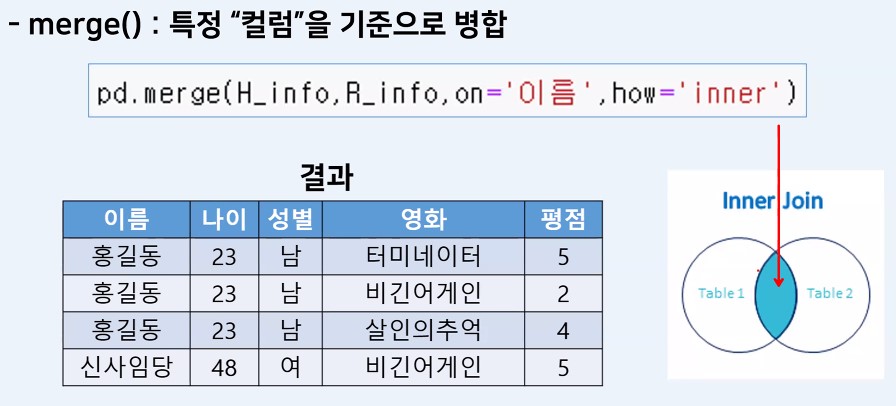
# merge(left, right, how='inner', on='컬럼명')
pd.merge(h_info, r_info, how='inner', on='이름')| 이름 | 나이 | 성별 | 영화 | 평점 | |
|---|---|---|---|---|---|
| 0 | 홍길동 | 23 | 남 | 터미네이터 | 5 |
| 1 | 홍길동 | 23 | 남 | 비긴어게인 | 2 |
| 2 | 홍길동 | 23 | 남 | 살인의추억 | 4 |
| 3 | 신사임당 | 48 | 여 | 비긴어게인 | 5 |
# merge() how = 'left'
pd.merge(h_info, r_info, how='left', on='이름')| 이름 | 나이 | 성별 | 영화 | 평점 | |
|---|---|---|---|---|---|
| 0 | 홍길동 | 23 | 남 | 터미네이터 | 5 |
| 1 | 홍길동 | 23 | 남 | 비긴어게인 | 2 |
| 2 | 홍길동 | 23 | 남 | 살인의추억 | 4 |
| 3 | 이순신 | 55 | 남 | NaN | NaN |
| 4 | 신사임당 | 48 | 여 | 비긴어게인 | 5 |
# how = 'outer'
pd.merge(h_info, r_info, how='outer', on='이름')| 이름 | 나이 | 성별 | 영화 | 평점 | |
|---|---|---|---|---|---|
| 0 | 홍길동 | 23 | 남 | 터미네이터 | 5 |
| 1 | 홍길동 | 23 | 남 | 비긴어게인 | 2 |
| 2 | 홍길동 | 23 | 남 | 살인의추억 | 4 |
| 3 | 이순신 | 55 | 남 | NaN | NaN |
| 4 | 신사임당 | 48 | 여 | 비긴어게인 | 5 |
| 5 | 장보고 | NaN | NaN | 살인의추억 | 3 |
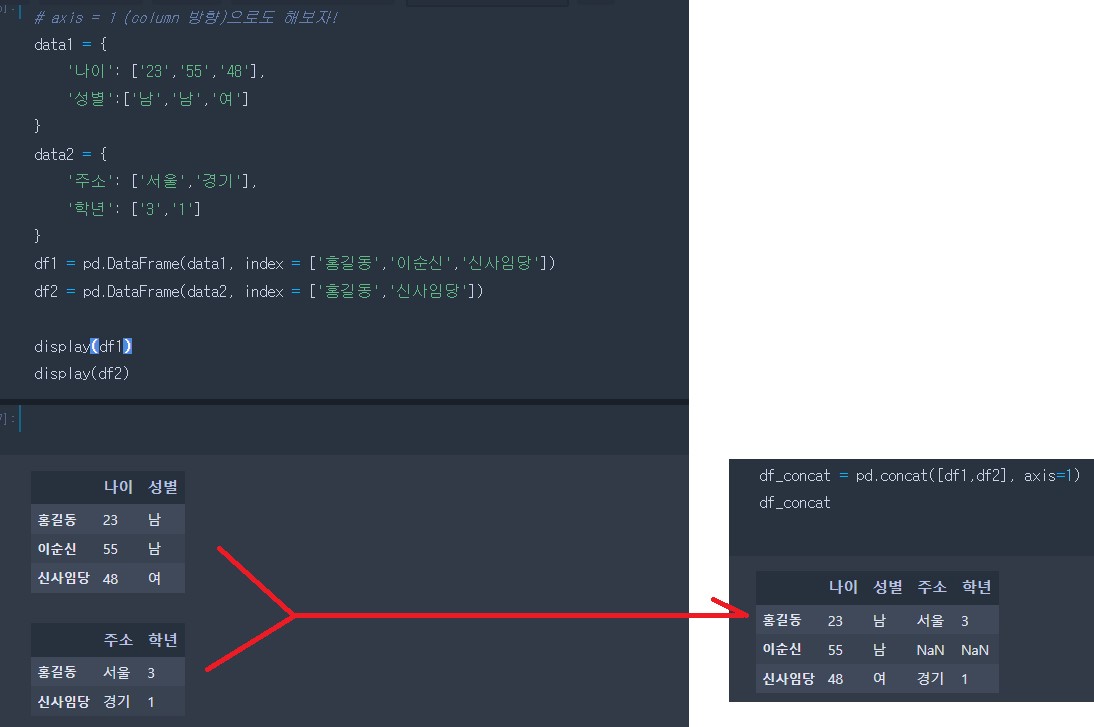
ignore_index = True, False
# ignore_index = False -> True로 변경시 인덱스 이름을 순차적으로 새롭게 부여
pd.concat([df1,df2],axis=0, ignore_index=True)| 이름 | 나이 | 성별 | |
|---|---|---|---|
| 0 | 홍길동 | 23 | 남 |
| 1 | 이순신 | 55 | 남 |
| 2 | 신사임당 | 48 | 여 |
| 3 | 장보고 | 22 | 남 |
결측치(NaN) 채우기, 제외
- 다음과 같이 데이터를 병합하게되면 결측치가 생김
결측치 채우기
# fillna(값) : 결측치(NaN)가 존재하는 경우 해당 값으로 채움
df_concat = pd.concat([df1,df2], axis=1)
df_concat.fillna(0)| 나이 | 성별 | 주소 | 학년 | |
|---|---|---|---|---|
| 홍길동 | 23 | 남 | 서울 | 3 |
| 이순신 | 55 | 남 | NaN | NaN |
| 신사임당 | 48 | 여 | 경기 | 1 |
결측치 제외
# concat의 기본 join방식은 outer이기 때문에, inner로 변경 !
pd.concat([df1,df2], axis=1 , join='inner')| 나이 | 성별 | 주소 | 학년 | |
|---|---|---|---|---|
| 홍길동 | 23 | 남 | 서울 | 3 |
| 신사임당 | 48 | 여 | 경기 | 1 |
그외. 한글파일로 적용해서 불러오기
# score.csv 파일 불러오기
# 주피터 노트북에서는 한글을 기본적으로 지원하지 않기 때문에,
# 속성으로 인코딩 방식을 설정
# 한글은 크게 3가지 방식 : UTF-8, cp949, euc-kr
score = pd.read_csv('./data/score.csv ', encoding='cp949', index_col='과목')
score