1. 라이브러리 불러오기
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
from matplotlib import rc
rc('font', family = 'Malgun Gothic')2. 데이터 불러오기
# 데이터 불러오기(한글설정)
df = pd.read_csv('./data/Traffic_Accident_2017.csv', encoding='euc-kr')3. 데이터 확인
# 전체보기
df
# 상단의 10 개의 행만 보고 싶다 !
df.head(10)
# 하단의 10 개의 행만 보고 싶다 !
df.tail(10)# df 정보확인
df.info()- Non-Null Count : 데이터의 결측치 여부를 각 컬럼별로 확인
- RangeIndex(행의 개수)와 비교하여 결측치 확인!

4. 시각화 실습해보기
4.1. 요일별 사망 교통사고 시각화 실습을 해보자 !
# 교통사고 사망자수를 count 해보자 !!
df['사망자수'].value_counts()
# 사망자가 1인인 사고가 교통사고의 대부분을 차지하고 있는 걸 알 수 있다 !
# 요일별 사고건수 count
y = df['요일'].value_counts()
# 내 맘대로 정렬 팁 !
# 요일을 순서대로 변경(다중 인덱싱 방법 사용)
y = y[['월','화','수','목','금','토','일']]
# x에는 y의 요일을 대입시킴
x = y.index
plt.bar(x,y, color='red')
# y축 범위 설정
plt.ylim(450,650)
# 차트 이름 설정
plt.title('요일별 교통사고 건수')
# 축이름 설정
plt.xlabel('요일')
plt.ylabel('사고건수',rotation=0)
plt.show()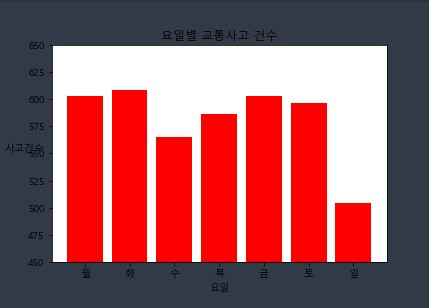
4.2. '차대차'(차와 차의 사고) 사고 중 사상자 수가 많은 발생지시도를 알아보고 시각화 해보자!
# 불리안 인덱싱을 활용하여, 사고유형_대분류 컬럼이 차대차 값을 가진 행만 추출
car = df[df['사고유형_대분류'] == '차대차']
# 발생지시도, 사상자 수 데이터 접근하기
region_cnt = car[['발생지시도','사상자수']].groupby(['발생지시도']).sum()
# line chart
# x = 지역명
# y = 건수
x = region_cnt.index
#y = region_cnt['사상자수']
y = region_cnt.values
# figure 사이즈 조정 -> plot 위에 생성하기 !
plt.figure(figsize=(15, 8))
plt.plot(x, y)
plt.title('차대차 교통사고 사상자수_지역별')
plt.xlabel('지역명')
plt.ylabel('사상자수', rotation=0)
plt.grid()
plt.show()
- 정렬되기 전 그래프
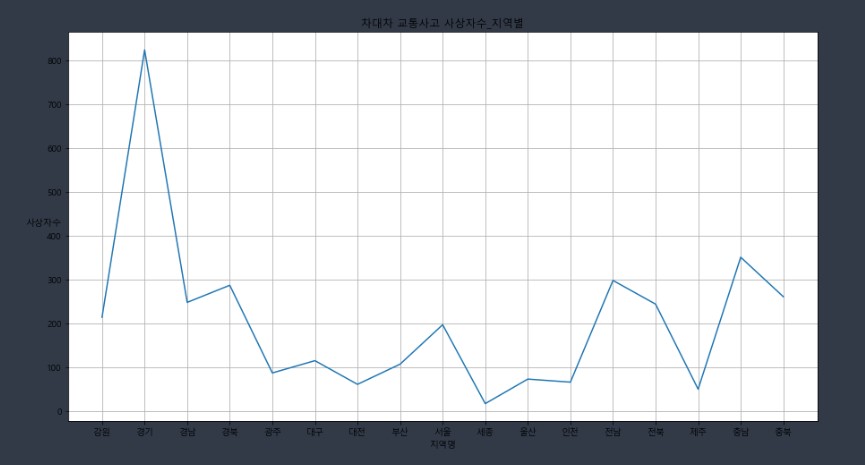
4.2.1. 이전 그래프, 막대 그래프로 출력하기
# 시리즈로 변환
y_bar = [y[i][0] for i in range(len(y))]
# 막대차트
plt.bar(x, y_bar)
plt.title('차대차 교통사고 사상자수_지역별')
plt.xlabel('지역명')
plt.ylabel('사상자수', rotation=0)
plt.show()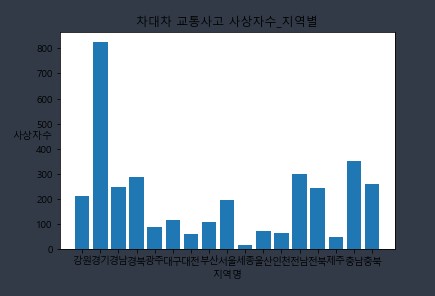
4.2.2. 내림차순 정렬하고 막대 그래프로 출력
# 그래프를 내림차순으로 정렬 !
# region_cnt.sort_values(by='사상자수', ascanding=False)
region_cnt = region_cnt.sort_values(by='사상자수')[::-1]
x = region_cnt.index
y = region_cnt['사상자수']
plt.figure(figsize=(15, 8))
plt.bar(x, y)
plt.title('차대차 교통사고 사상자수_지역별')
plt.xlabel('지역명')
plt.ylabel('사상자수', rotation=0)
plt.grid()
plt.show()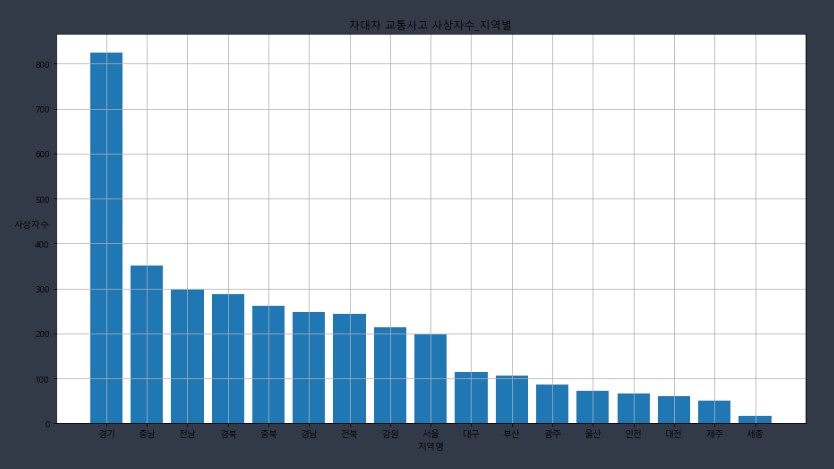
4.3. 교통사고가 가장 많이 발생하는 시간대를 pie로 시각화해보자 !
df['발생년월일시'] #yyyymmddhh0 2017010101
1 2017010102
2 2017010102
3 2017010102
4 2017010104
...
4060 2017123118
4061 2017123118
4062 2017123119
4063 2017123120
4064 2017123123
Name: 발생년월일시, Length: 4065, dtype: int64
# 시간데이터 뽑아오기 !
time = df['발생년월일시']%100
# 시간을 카테고리화(범주화 시켜보기!)
np.sort(time.unique())
# cut(데이터, bins=[값 분류], labels = [각 범주의 이름]) : 범주화하는 도구
# 시간 데이터를 확인해보니 0 ~ 23, 8개의 시간 구간으로 나눠보자 !
bins = [-1,2,5,8,11,14,17,20,23]
labels = ['0~2','3~5','6~8','9~11','12~14','15~17','18~20','21~23']
time_cut = pd.cut(time, bins=bins, labels=labels)
# 값을 카운팅 한 후, index를 기준으로 정렬
pie_data = time_cut.value_counts().sort_index()
# pie 차트화!
# labels = [라벨] 카테고리 범주 지어주기
# autopct = '%정수.소수자릿수f%%' -> 표기법 !
plt.pie(pie_data, labels=labels, autopct='%1.2f%%')
plt.title('시간대별 교통사고 발생비율')
plt.show()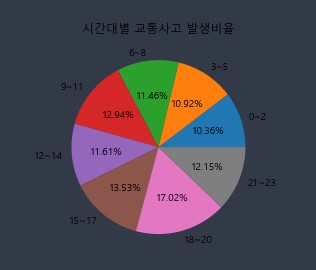

제가 한 번 해보겠습니다.