
Intro
- 객체와 테이블 연관관계의 차이를 이해해야 한다.
- 객체의 참조와 테이블의 외래키를 매핑하는 것이 이 장의 목표이다.
- 용어 이해
방향(Direction): 단방향, 양방향
다중성(Multiplicity): 다대일(N:1), 일대다(1:N), 일대일(1:1), 다대다(N:M)
연관관계의 주인(Owner): 객체 양방향 연관관계는 관리 주인이 필요
연관관계의 필요성?
'객체지향 설계의 목표는 자율적인 객체들의 협력 공동체를 만드는 것이다.'
조영호(객체지향의 사실과 오해)
객체를 테이블에 맞춰 모델링하면, 협력 관계를 만들 수 없다.
예제 시나리오?
- 회원과 팀이 있다.
- 회원은 하나의 팀에만 소속될 수 있다.
- 회원과 팀은 다대일 관계이다.
다음은 연관관계가 없는 객체로, 객체를 테이블에 맞추어 모델링하는 경우이다.
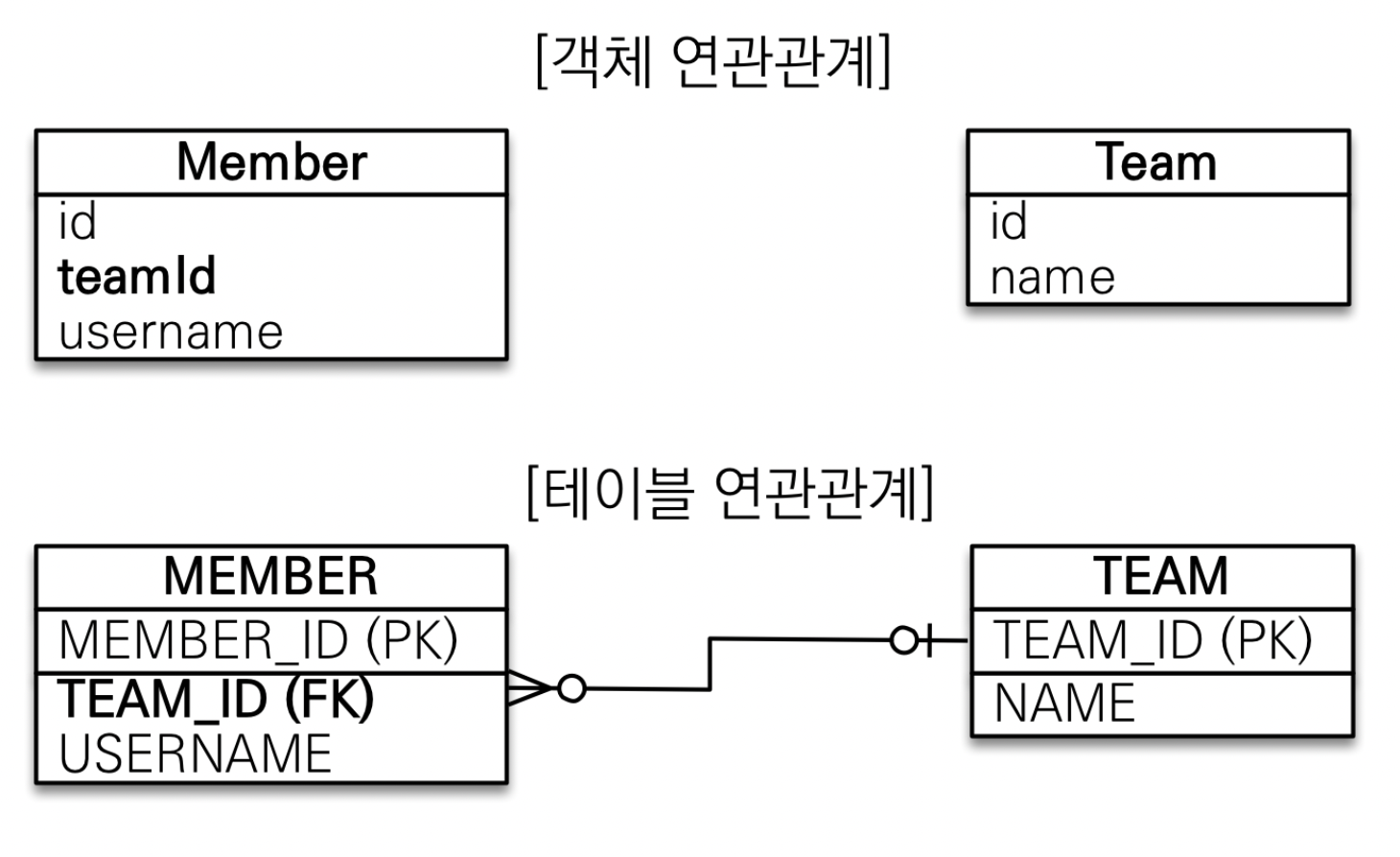
// Member.java
@Entity
@Getter @Setter
public class Member {
@Id @GeneratedValue
private Long id;
@Column(name = "USERNAME")
private String name;
@Column(name = "TEAM_ID")
private Long teamId;
...
}
// Team.java
@Entity
@Getter @Setter
public class Team {
@Id @GeneratedValue
private Long id;
private String name;
...
}참조 대신에 외래키를 그대로 사용하게 된다.
// JpaMain.java
public class JpaMain {
public static void main(String[] args) {
EntityManagerFactory emf = Persistence.createEntityManagerFactory("hello");
EntityManager em = emf.createEntityManager();
EntityTransaction tx = em.getTransaction();
tx.begin();
try {
// 팀 저장
Team team = new Team();
team.setName("TeamA");
em.persist(team);
// 회원 저장
Member member = new Member();
member.setName("member1");
member.setTeamId(team.getId());
em.persist(member);
tx.commit();
} catch (Exception e) {
tx.rollback();
} finally {
em.close();
}
}
}외래키 식별자를 직접 다루게 된다. 이럴 경우 문제는 조회할 때 역시 해당 외래키를 가지고 조인 쿼리를 직접 짜야한다.
// 조회
Member findMember = em.find(Member.class, member.getId());
Long findTeamId = findMember.getTeamId();
// 연관관계가 없음
Team findTeam = em.find(Team.class, findTeamId);매번 member를 우선 조회한 뒤 외래키를 뽑아 그것으로 팀의 정보를 조회해야 한다. 이렇게 되면 협력관계를 만들 수 없다.
정리하자면, 객체를 테이블에 맞추어 데이터 중심으로 모델링하면, 협력 관계를 만들 수 없다.
테이블은 외래키로 조인을 사용해서 연관된 테이블을 찾지만, 객체는 참조를 사용해서 연관된 객체를 찾기에 테이블과 객체 사이의 큰 간격이 존재하게 된다. 이 말은 객체지향 프로그래밍 패러다임을 정면으로 반박하는 것이다.
단방향 연관관계
다대일(N:1) 단방향 관계를 가장 먼저 이해해야 한다.
객체 연관관계를 사용해서 객체 지향적으로 엔티티를 설계해보자.
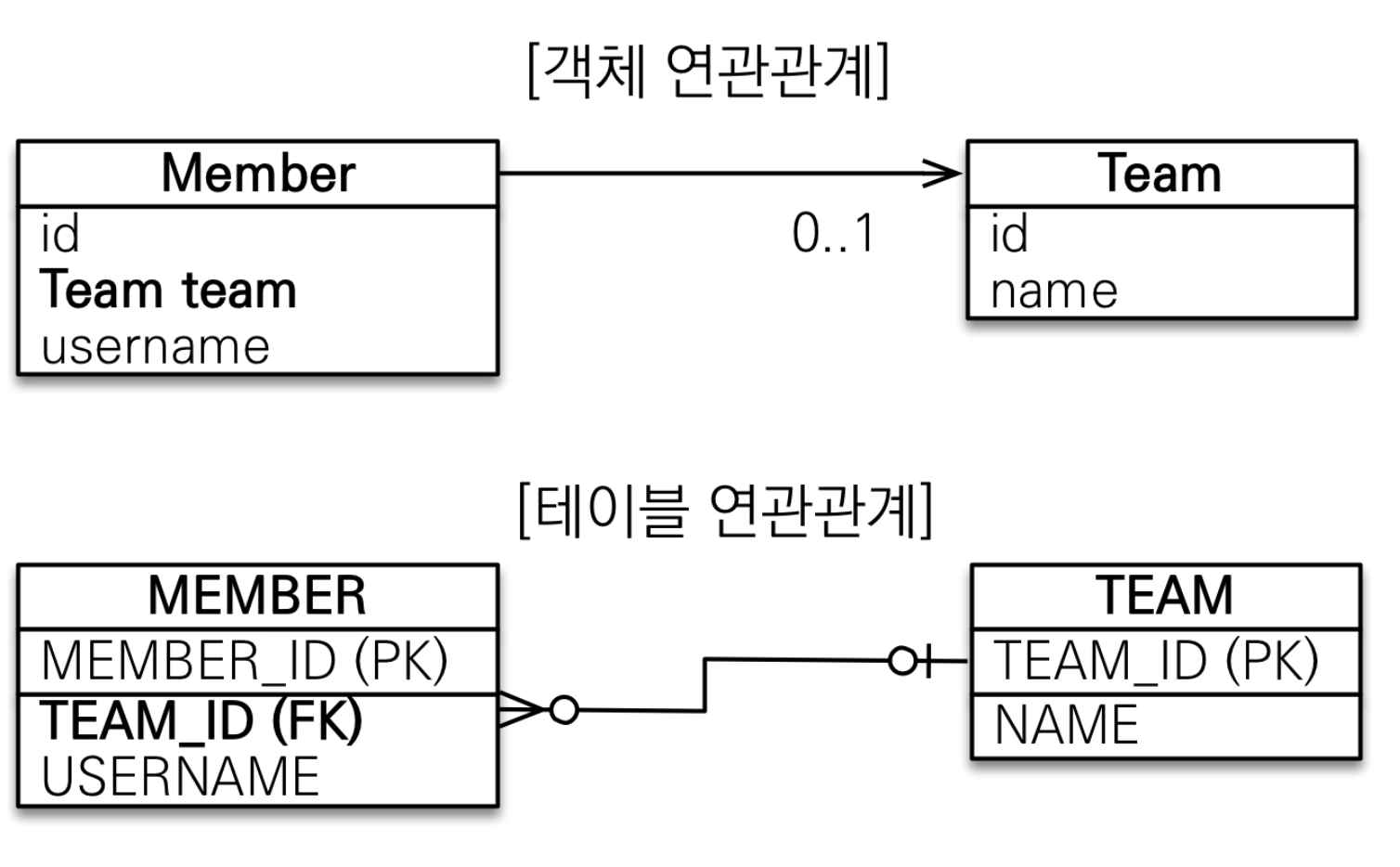
-
객체 연관관계
- 회원 객체는
Member.team필드(멤버변수)로 팀 객체와 연관관계를 맺는다. - 회원 객체와 팀 객체는 단방향 관계다. 회원은
Member.team필드로 팀을 알 수 있지만, 팀은 회원을 알 수 없다. team->member를 접근하는 필드가 없다.
- 회원 객체는
-
테이블 연관관계
- 회원 테이블은
TEAM_ID외래키로 팀 테이블과 연관관계를 맺는다. - 회원 테이블과 팀 테이블은 양방향 관계다. 회원 테이블의
TEAM_ID외래키로 회원과 팀을 조인할 수 있고, 반대로 팀과 회원도 조인할 수 있다.
- 회원 테이블은
객체 연관관계와 테이블 연관관계의 가장 큰 차이는 다음과 같다.
- 참조를 사용하는 객체의 연관관계는 언제나 단방향
- 외래키를 사용하는 테이블의 연관관계는 양방향
객체를 양방향으로 참조하려면 단방향 연관관계를 2개 만들어야 한다.
// 서로 다른 단방향 관계 2개
class A { B b; }
class B { A a; }// 참고로 객체는 참조를 사용해서 연관관계를 탐색할 수 있는데 이를 객체 그래프 탐색이라 한다.
이를 토대로 기존의 코드를 변경하면 다음과 같다.
// Member.java
@Entity
@Getter @Setter
public class Member {
@Id @GeneratedValue
private Long id;
@Column(name = "USERNAME")
private String name;
@ManyToOne
@JoinColumn(name = "TEAM_ID")
private Team team;
...
}@ManyToOne, @JoinColumn을 통해 멤버에서 팀을 참조하도록 했다.
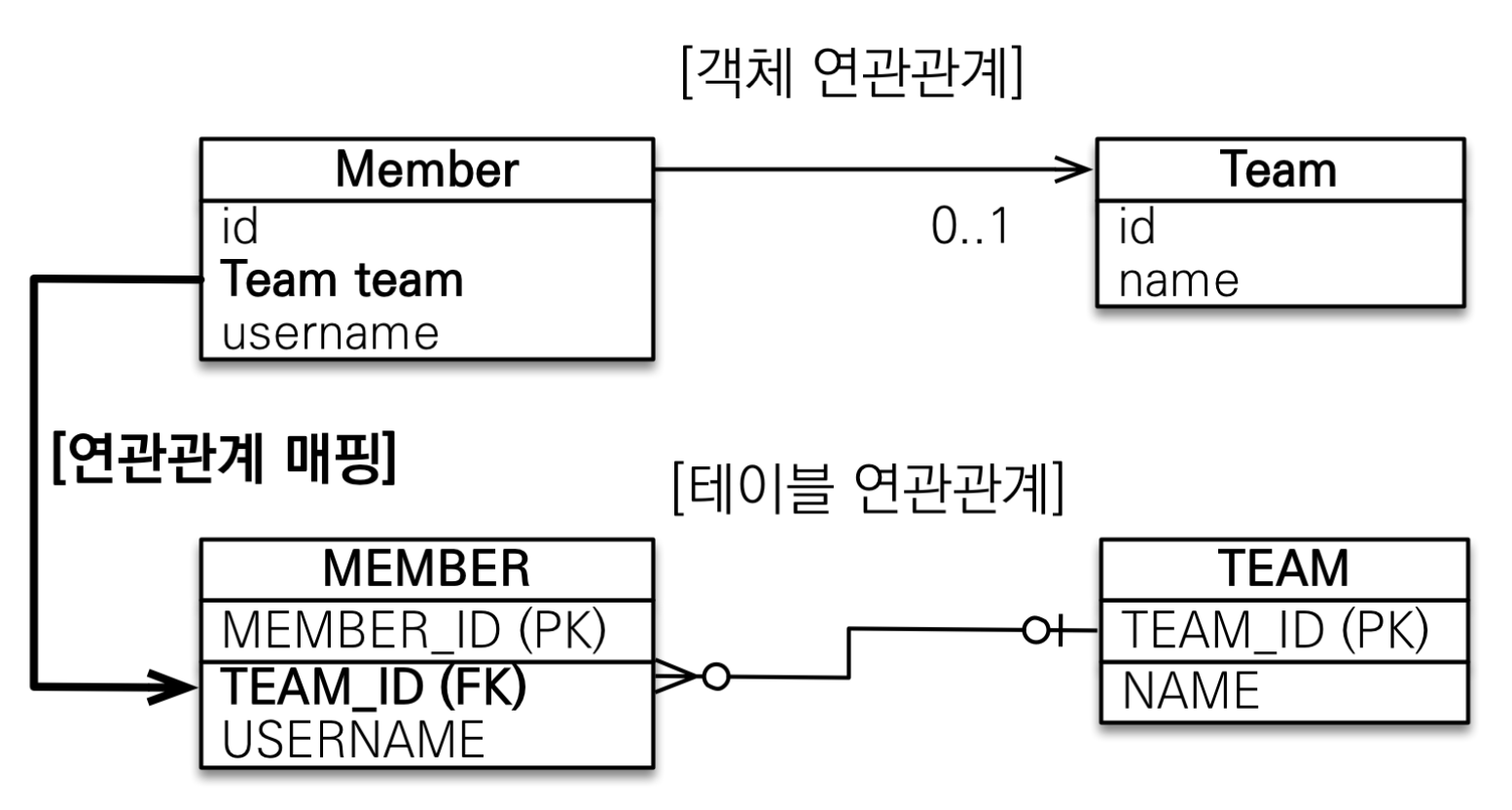
// JpaMain.java
public class JpaMain {
public static void main(String[] args) {
EntityManagerFactory emf = Persistence.createEntityManagerFactory("hello");
EntityManager em = emf.createEntityManager();
EntityTransaction tx = em.getTransaction();
tx.begin();
try {
// 팀 저장
Team team = new Team();
team.setName("TeamA");
em.persist(team);
// 회원 저장
Member member = new Member();
member.setName("member1");
member.setTeam(team); // 단방향 연관관계 설정, 참조 저장
em.persist(member);
em.flush();
em.clear();
// 조회
Member findMember = em.find(Member.class, member.getId());
// 참조를 사용해서 연관관계 조회
Team findTeam = findMember.getTeam();
tx.commit();
} catch (Exception e) {
tx.rollback();
} finally {
em.close();
}
}
}연관관계를 수정하고 싶을 때는 다음과 같다.
// 새로운 팀
Team teamB = new Team();
teamB.setName("TeamB");
em.persist(teamB);
// 회원1에 새로운 팀B 설정
member.setTeam(teamB);결과적으로 update 쿼리가 날아간다.
연관관계 매핑 어노테이션
@JoinColumn
@JoinColumn은 외래키를 매핑할 때 사용한다.
주요 속성은 다음과 같다.
| 속성 | 기능 | 기본값 |
|---|---|---|
| name | 매핑할 외래키 이름 | 필드명 + _ + 참조하는 테이블의 기본키 컬럼명 |
| referencedColumnName | 외래키가 참조하는 대상 테이블의 컬럼명 | 참조하는 테이블의 기본키 컬럼명 |
| foreignKey(DDL) | 외래키 제약조건을 직접 지정할 수 있다. 이 속성은 테이블을 생성할 때만 사용한다. | |
| unique, nullable, insertable, updatable, columnDefinition, table | @Column의 속성과 같다. |
@ManyToOne
@ManyToOne은 다대일 관계에서 사용한다.
주요 속성은 다음과 같다.
| 속성 | 기능 | 기본값 |
|---|---|---|
| optional | false로 설정하면 연관된 엔티티가 항상 있어야 한다. | true |
| fetch | 글로벌 페치 전략을 설정한다. | @ManyToOne=FetchType.EAGER, @OneToMany=FetchType.LAZY |
| cascade | 영속성 전이 기능을 사용한다. | |
| targetEntity | 연관된 엔티티의 타입 정보를 설정한다. 이 기능은 거의 사용하지 않음. 컬렉션을 사용해도 제네릭으로 타입 정보를 알 수 있다. |
양방향 연관관계
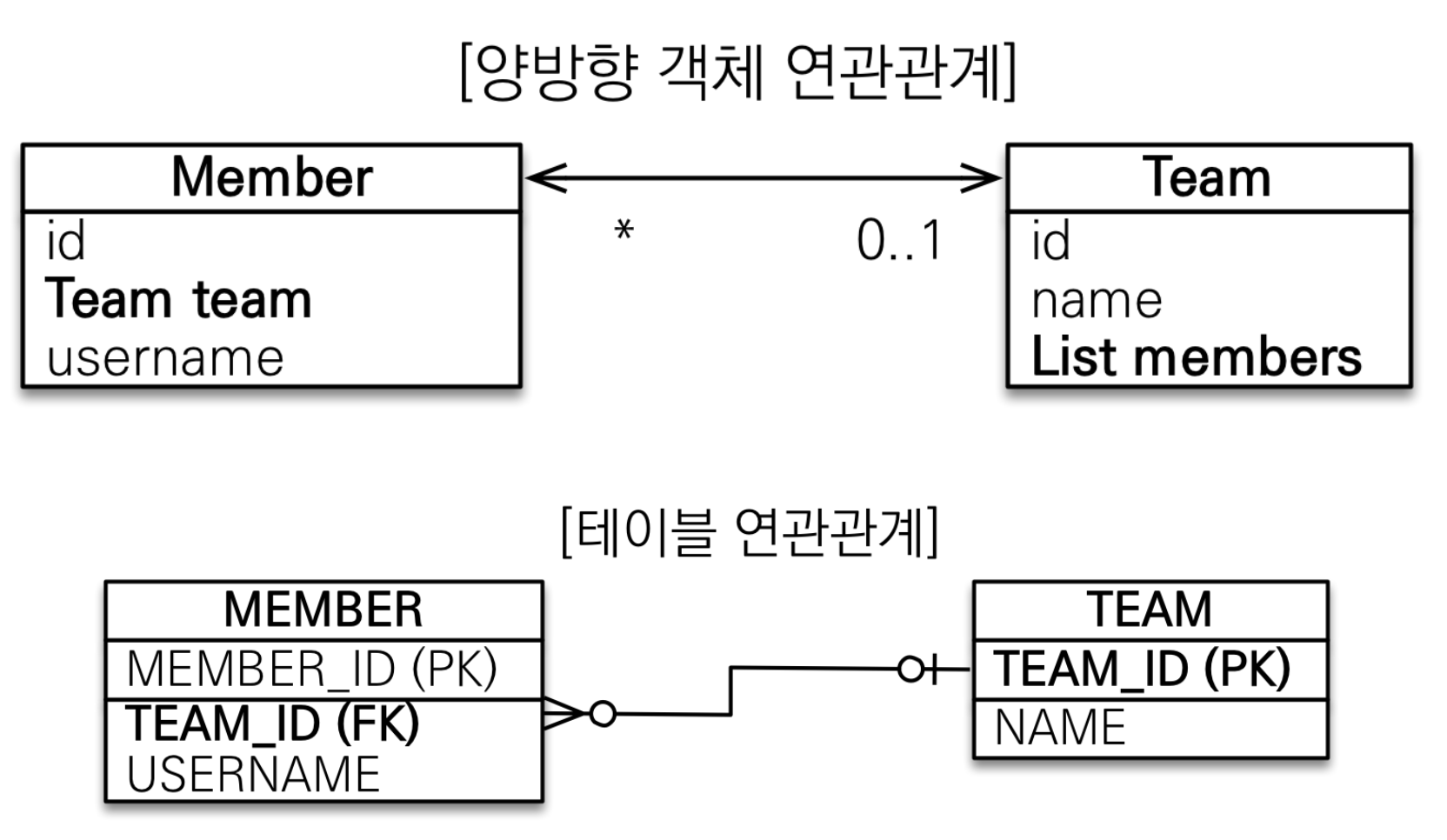
단방향에서 양방향이 된다는 것의 의미는 양측에서 서로를 참조할 수 있다는 것이다. 객체 연관관계를 보면, 회원과 팀은 다대일(N:1) 관계이다. 반대로 팀에서 회원은 일대다(1:N) 관계이다. 일대다 관계는 여러 건과 연관관계를 맺을 수 있으므로 컬렉션을 사용해야 한다.
반면, 테이블 연관관계를 보면, 데이터베이스 테이블은 외래키 하나로 양방향으로 조회할 수 있다.
이를 고려하여 코드를 추가하면 다음과 같다.
// Member.java
@Entity
@Getter @Setter
public class Member {
@Id @GeneratedValue
private Long id;
@Column(name = "USERNAME")
private String name;
@ManyToOne
@JoinColumn(name = "TEAM_ID")
private Team team;
}
// Team.java
@Entity
@Getter @Setter
public class Team {
@Id @GeneratedValue
private Long id;
private String name;
@OneToMany(mappedBy = "team")
List<Member> members = new ArrayList<Member>();
}아래 코드처럼 반대방향으로도 객체 그래프 탐색이 가능해졌다.
// 조회
Team findTeam = em.find(Team.class, team.getId());
int memberSize = findTeam.getMembers().size(); // 역방향 조회연관관계의 주인과 mappedBy
mappedBy는 연관관계의 개념에 대해 이해를 어렵게 만든다. 이를 이해하려면 객체와 테이블간의 연관관계를 맺는 차이를 이해해야 한다.
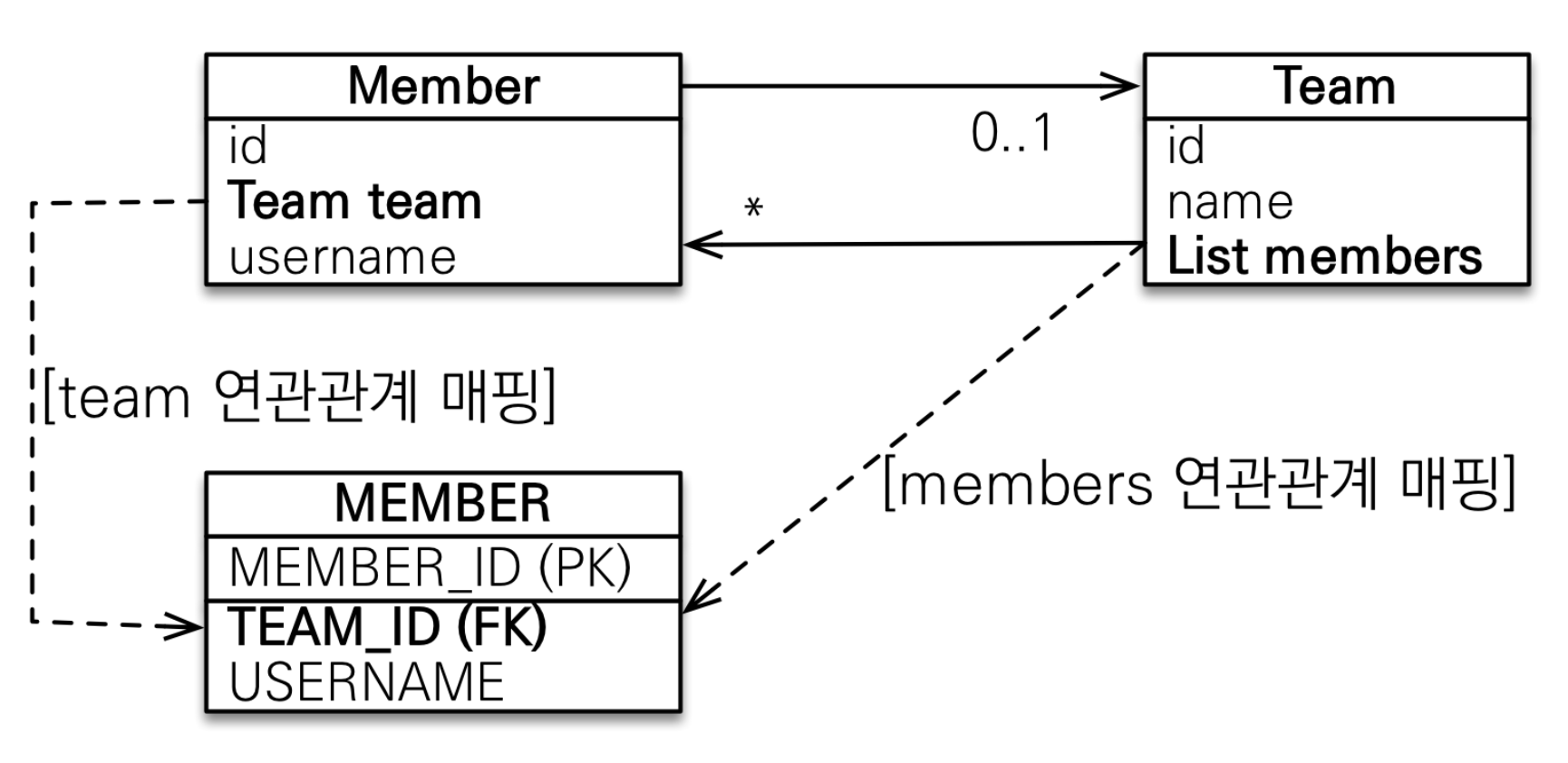
테이블은 외래키 하나로 두 테이블의 연관관계를 관리한다. 엔티티를 단방향으로 매핑하면 참조를 하나만 사용하므로 이 참조로 외래키를 관리하면 된다.
하지만, 엔티티를 양방향으로 매핑하면 회원->팀, 팀->회원 두 곳에서 서로를 참조한다.
엔티티를 양방향 연관관계로 설정하면 객체의 참조는 둘인데 외래키는 하나다. 따라서 둘 사이에 차이가 발생한다.
이런 차이로 인해 JPA에서는 두 객체 연관관계 중 하나를 정해서 테이블의 외래키를 관리해야 하는데 이것을 연관관계의 주인(Owner)이라 한다.
양방향 매핑 규칙
- 객체의 두 관계중 하나를 연관관계의 주인으로 지정
- 연관관계의 주인만이 외래키를 관리(등록, 수정)
- 주인이 아닌쪽은 읽기만 가능
- 주인은
mappedBy속성을 사용하지 않는다. - 주인이 아니면
mappedBy속성으로 주인을 지정한다.
정리하자면, 연관관계의 주인을 정한다는 것은 외래키 관리자를 선택하는 것이다.
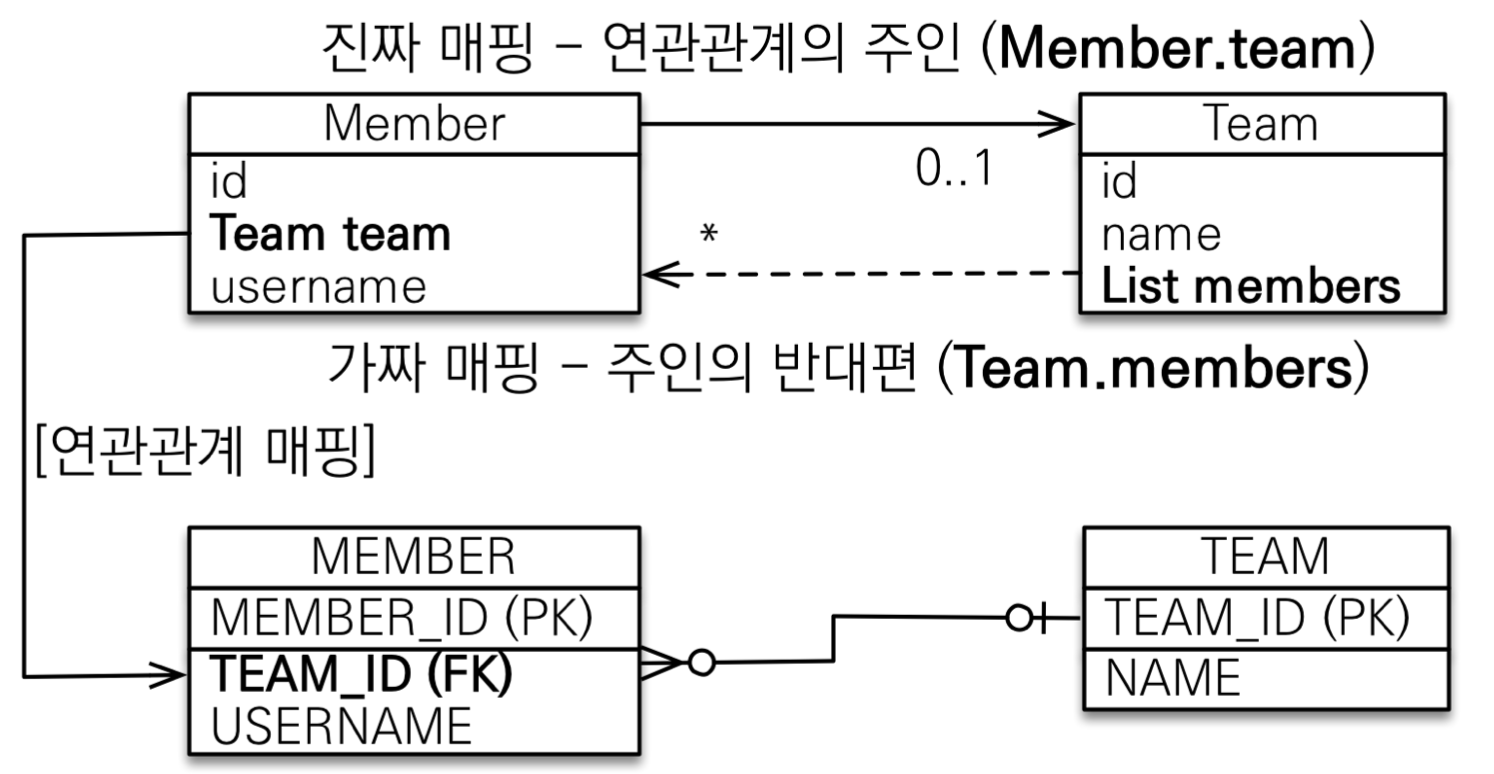
연관관계의 주인은 외래키가 있는 곳
연관관계의 주인은 테이블에 외래키가 있는 곳으로 정해야 한다. 위 예시에선 Member.team이 연관관계의 주인이다.
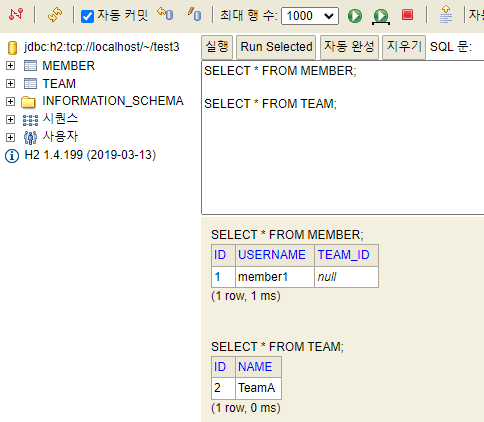
Team team = new Team();
team.setName("TeamA");
em.persist(team);
Member member = new Member();
member.setName("member1");
// 역방향(주인이 아닌 방향)만 연관관계 설정
team.getMembers().add(member);
em.persist(member);위 코드처럼 연관관계의 주인에 값을 입력하지 않는 경우 다음과 같이 MEMBER 테이블의 TEAM_ID값이 null값인 결과가 나타난다.
따라서 양방향 매핑시 연관관계의 주인에 값을 입력해야 한다.
Team team = new Team();
team.setName("TeamA");
em.persist(team);
Member member = new Member();
member.setName("member1");
// 연관관계의 주인에 값 설정
member.setTeam(team);
em.persist(member);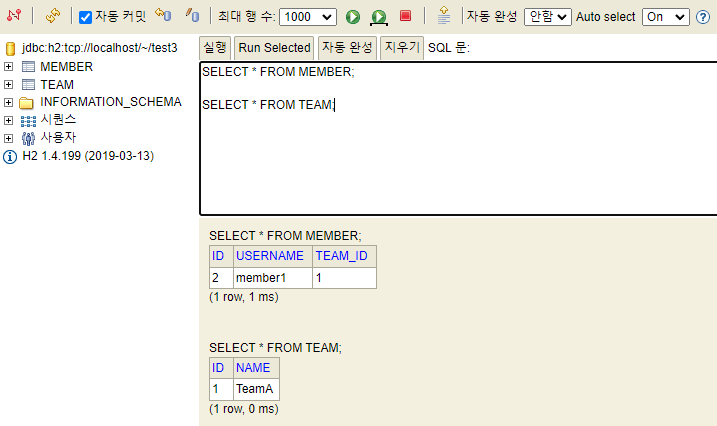
순수한 객체까지 고려한 양방향 연관관계
바로 위 코드에선, team.getMembers().add(member)라는 코드가 없어도 결과는 잘 나왔다. 하지만, 순수한 객체 관계를 고려하면 항상 양쪽 모두(member, team 모두) 값을 입력해야 한다.
왜 그럴까??
// JpaMain.java
public class JpaMain {
public static void main(String[] args) {
EntityManagerFactory emf = Persistence.createEntityManagerFactory("hello");
EntityManager em = emf.createEntityManager();
EntityTransaction tx = em.getTransaction();
tx.begin();
try {
// 저장
Team team = new Team();
team.setName("TeamA");
em.persist(team);
Member member = new Member();
member.setName("member1");
member.setTeam(team);
em.persist(member);
Team findTeam = em.find(Team.class, team.getId()); // 1차 캐시
List<Member> members = findTeam.getMembers();
System.out.println("==============");
for (Member m : members) {
System.out.println("m = " + m.getName());
}
System.out.println("==============");
tx.commit();
} catch (Exception e) {
tx.rollback();
} finally {
em.close();
}
}
}JPA에 저장한 team 객체 인스턴스는 순수한 객체 상태이다.
또한 team.members에 값을 넣어준 적이 없다. 따라서 JPA에서 해당 team 객체 인스턴스를 다시 조회하더라도 members에는 값이 없다. em.persist(member)를 호출하면 JPA는 member 인스턴스 객체를 현재 상태 그대로 영속성 컨텍스트에 저장한다. (DB에 반영하는데 문제가 생기진 않는다.)
member.getTeam()을 호출하면 team을 찾을 수 있는데, team.getMembers()를 호출하면 여기에는 아무것도 없는 상태이다.
영속성 컨텍스트는 한번 저장하면 영속성 컨텍스트를 삭제하기 전까지 유지된다. 당연히 그 안의 객체들도 유지된다. 이후 em.find(member)를 호출하면, 방금 영속성 컨텍스트에 저장해둔 그 member 인스턴스가 조회된다. 따라서 member는 아무것도 없다. 영속화 컨텍스트의 1차 캐시에 저장된 team에선 members에 해당 Member가 추가되지 않은 상태이기 때문이다. 따라서 위 코드의 실행 결과는 다음과 같이 원하는대로 쿼리가 수행되지 않음을 알 수 있다.
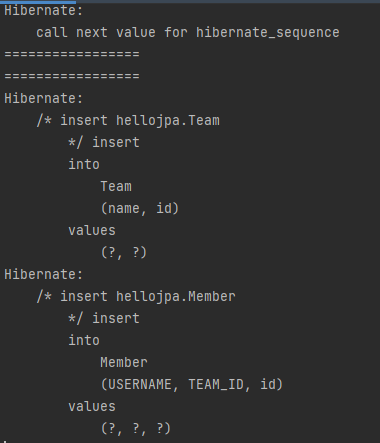
// JpaMain.java
public class JpaMain {
public static void main(String[] args) {
EntityManagerFactory emf = Persistence.createEntityManagerFactory("hello");
EntityManager em = emf.createEntityManager();
EntityTransaction tx = em.getTransaction();
tx.begin();
try {
// 저장
Team team = new Team();
team.setName("TeamA");
em.persist(team);
Member member = new Member();
member.setName("member1");
member.setTeam(team);
em.persist(member);
team.getMembers().add(member);
em.flush();
em.clear(); // 1차 캐시에 아무것도 없게됨.
Team findTeam = em.find(Team.class, team.getId()); // 1차 캐시
List<Member> members = findTeam.getMembers();
System.out.println("==============");
for (Member m : members) {
System.out.println("m = " + m.getName());
}
System.out.println("==============");
tx.commit();
} catch (Exception e) {
tx.rollback();
} finally {
em.close();
}
}
}저장 요청이 완전히 끝나고 새로운 요청이 왔을 때 새로운 영속성 컨텍스트에서 em.find(member)를 호출하면 새로운 영속성 컨텍스트는 member가 없기 때문에 DB에서 새로 member를 조회하고, JPA가 member 객체를 생성한다. 또한 연관관계 매핑이 되어있기 때문에 member.getTeam()은 물론이고, team.getMembers() 모두 값을 채워주게 된다. 위 코드의 실행 결과는 다음과 같이 정상적으로 쿼리가 수행된 것을 확인할 수 있다.
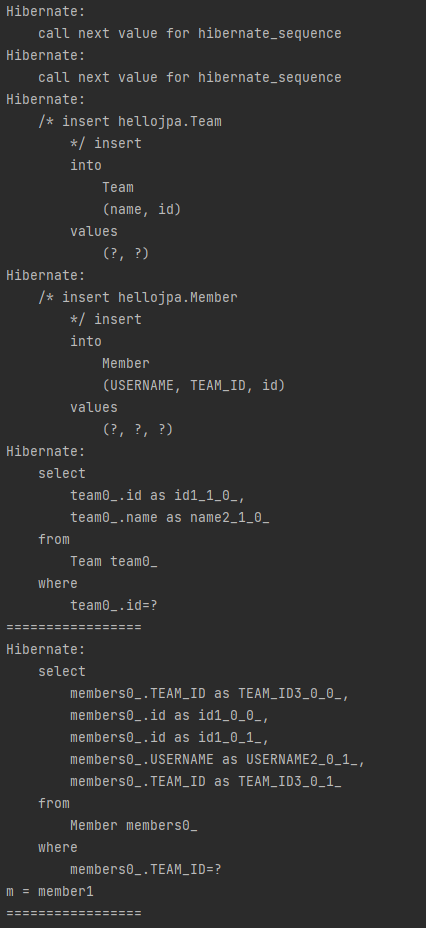
따라서 양방향 연관관계에서는 양쪽에 값을 설정해주어야 한다. 이 방법이 가장 안전하다. 양방향 모두 값을 입력하지 않으면 JPA를 사용하지 않는 순수한 객체 상태에서 심각한 문제가 발생할 수 있기 때문이다.
연관관계 편의 메소드
member.setTeam(team)과 team.getMembers().add(member)를 각각 호출하다 보면 실수로 둘 중 하나만 호출해서 양방향이 깨질 수 있기 때문에 다음과 같이 연관관계 편의 메소드를 추가하자.
// Member.java
@Entity
@Getter @Setter
public class Member {
@Id @GeneratedValue
private Long id;
@Column(name = "USERNAME")
private String name;
@ManyToOne
@JoinColumn(name = "TEAM_ID")
private Team team;
// 연관관계 편의 메소드 추가
// lombok의 @Setter 때문에 메소드 네이밍을 이처럼 해둠.
// changeTeam으로 네이밍 하는게 헷갈리지 않을 것임.
public void setTeam(Team team) {
this.team = team;
team.getMembers().add(this);
}
}이처럼 한 번에 양방향 관계를 설정하는 메소드를 연관관계 편의 메소드라 한다.
양방향 매핑시에 무한 루프를 조심해야 한다.(순환 참조)
ex) toString(), lombok, JSON 생성 라이브러리
// Member.java
@Entity
public class Member {
...
@Override
public String toString() {
return "Member{" + "id=" + id +
", name='" + name + '\'' +
", team=" + team +
'}';
}
...
}
// Team.java
@Entity
public class Team {
...
@Override
public String toString() {
return "Team{" + "id=" + id +
", name='" + name + '\'' +
", members=" + members +
'}';
}
...
}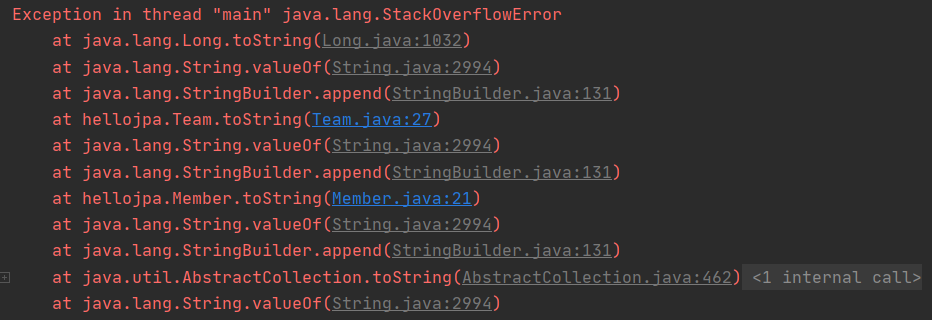
실행 결과 다음과 같이 무한 루프가 발생한다.(스택오버플로우)
양방향 매핑 정리
- 단방향 매핑만으로도 이미 연관관계 매핑은 완료
- 양방향 매핑은 반대 방향으로 조회(객체 그래프 탐색) 기능이 추가 된 것 뿐이다.
- JPQL에서 역방향으로 탐색할 일이 많다.
- 단방향 매핑을 잘 하고 양방향은 필요할 때 추가해도 된다. (테이블에 영향을 주지 않음)
- 연관관계의 주인은 외래키의 위치를 기준으로 정해야 함
(비즈니스 로직을 기준으로 연관관계의 주인을 선택하면 안됨)
References
