Kafka
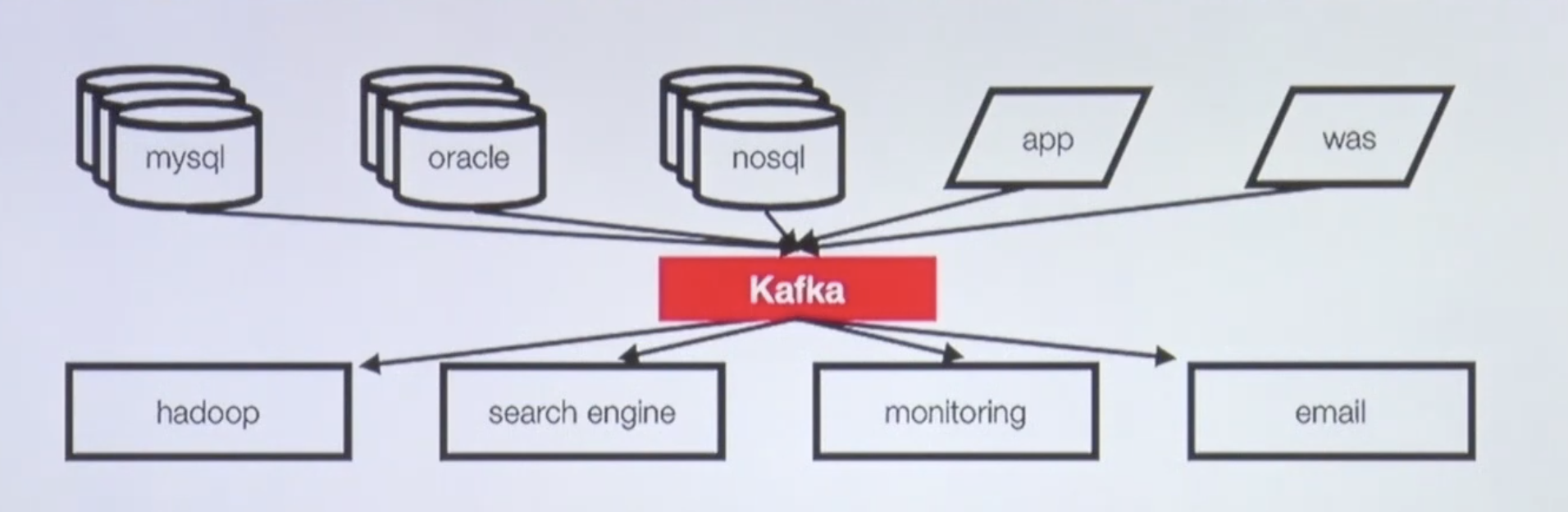
- 프로듀서/컨슈머 분리
- 메시지 데이터를 여러 컨슈머에게 허용
- 어떤 데이터가 카프카에 들어간 이후에는 여러번 사용할 수 있음
- 높은 처리량을 위한 메시지 최적화
- 스케일 아웃 가능
- 매우 중요한데, 카프카 클러스터를 만든 후 데이터가 많아지면 클러스터링을 해야하는데 무중단으로 가능
- 관련 생태계 제공
Kafka Broker
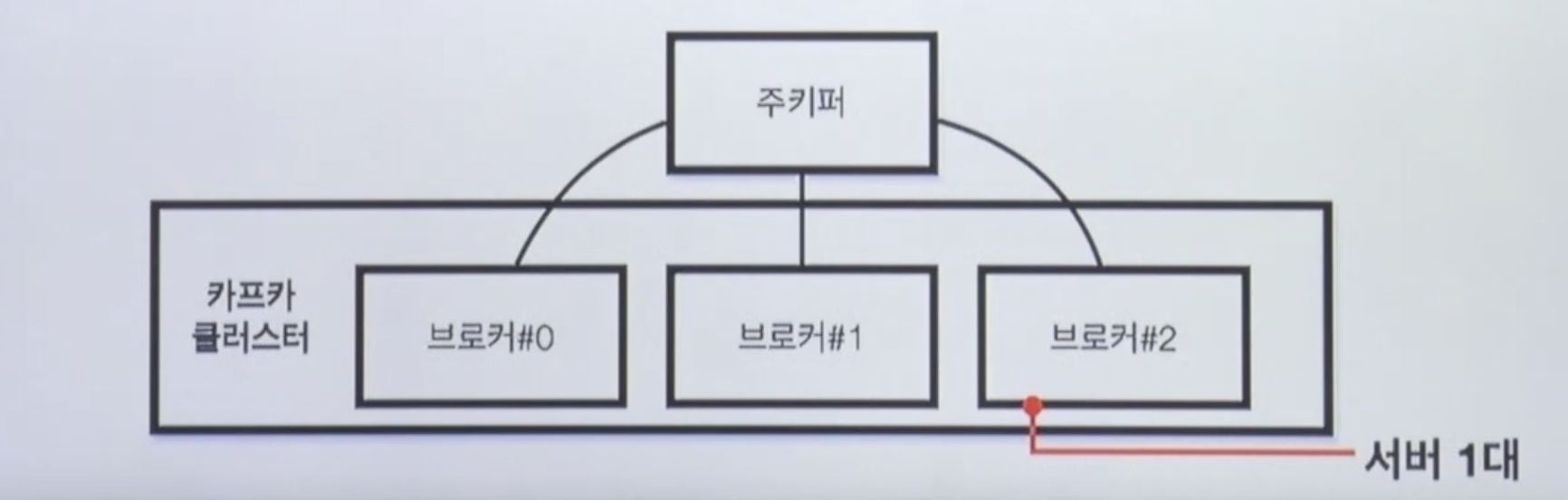
- 카프카 브로커란 실행된 카프카 어플리케이션 서버 중 한대
- 카프카 어플리케이션은 JVM으로 올라가서 서버에 카프카 어플리케이션이 2대이상 있을수도 있지만 실제로 그렇게 운영하는 경우는 없다고 보면 됨.
- 3대 이상의 브로커로 클러스터를 구성
- 주키퍼와 연동(~2.5.0 버전)
- 주키퍼의 역할 : 메타데이터(브로커id, 컨트롤러id 등) 저장
- 추후에는 카프카 클러스터, 브로커에 저장하지만 일단 주키퍼와의 연동은 필요함
- 주키퍼의 역할 : 메타데이터(브로커id, 컨트롤러id 등) 저장
- n개 브로커 중 한대는 컨트롤러(Controller)기능 수행
- 컨트롤러 : 각 브로커에게 담당파티션 할당 수행.
브로커 정상 동작 모니터링 관리.
누가 컨트롤러 인지는 주키퍼에 저장.
- 컨트롤러 : 각 브로커에게 담당파티션 할당 수행.
Record
어떤 데이터를 보내냐면, 아래에 보면 ProducerRecord이 있는데, 토픽/키/메시지를 정하게된다.

Topic이라는건 데이터가 보내지는 테이블같은 저장소라고 보면 되는데 키를 적고 메시지를 지정한다. 이렇게 보내면 ConsumerRecords를 통해서 이 topic의 데이터를 Record로 받아온다. 그럼 레코드도 key와 value일 땐 둘 다 스트링으로 받아와 진다.
그 이유는,
객체를 프로듀서에서 컨슈머로 전달하기 위해 Kafka 내부에서 byte 형태로 저장하기 때문에 직렬화/역직렬화가 필요하기 때문이다.
- 기본 제공 직렬화 class : StringSerializer, ShortSerializer 등
- 혹은 POJO(Play Of Java Object)를 사용하려면 커스텀 직렬화 class를 통해 Custom Object 직렬화/역직렬화 가능
중요한건, Produce 할 때랑 Consume 할 때 직렬화/역직렬화를 동일하게 맞춰줘야한다.
참고: SK 데이터 플랫폼에서는 Key는 Null, Value는 JSON으로 된 자체 형식으로 사용 중이다.
String으로 되어있는 JSON이지만 ByteArray로 serialize, deSerialize 해서 사용하고 있다.
Topic & Partition
토픽은 지금 파티션 3개로 되어있다. 토픽에선 파티션이 무조건 1개이상 존재해야하는데, 파티션에 각각 들어있는 숫자들은 각 파티션에 붙는 오프셋 번호다.

- 메시지 분류 단위
- n개의 파티션 할당 가능
- 각 파티션마다 고유한 오프셋(offaset)을 가짐.
- 메시지 처리순서는 파티션 별로 유지 관리됨.
- 이 말은 즉 파티션이 한개일 때는 Que와 같이 FIFO으로 처리된다.
- 파티션이 여러개인 경우 메시지 처리 순서가 완벽하게 FIFO로 보장되지 않는 다는 점 참고.
Producer & Consumer
프로듀서는 이렇게 들어간 파티션의 오프셋이 지정된 레코드들을 각각 가져간다.
Consumer A는 offset 9번 Record를 가져갔고, Consumer B는 offset 11번 Record를 가져 갔다.
각각의 다른 기능을 가진 Consumer는 동일한 데이터를 여러번 가져갈 수도 있다.
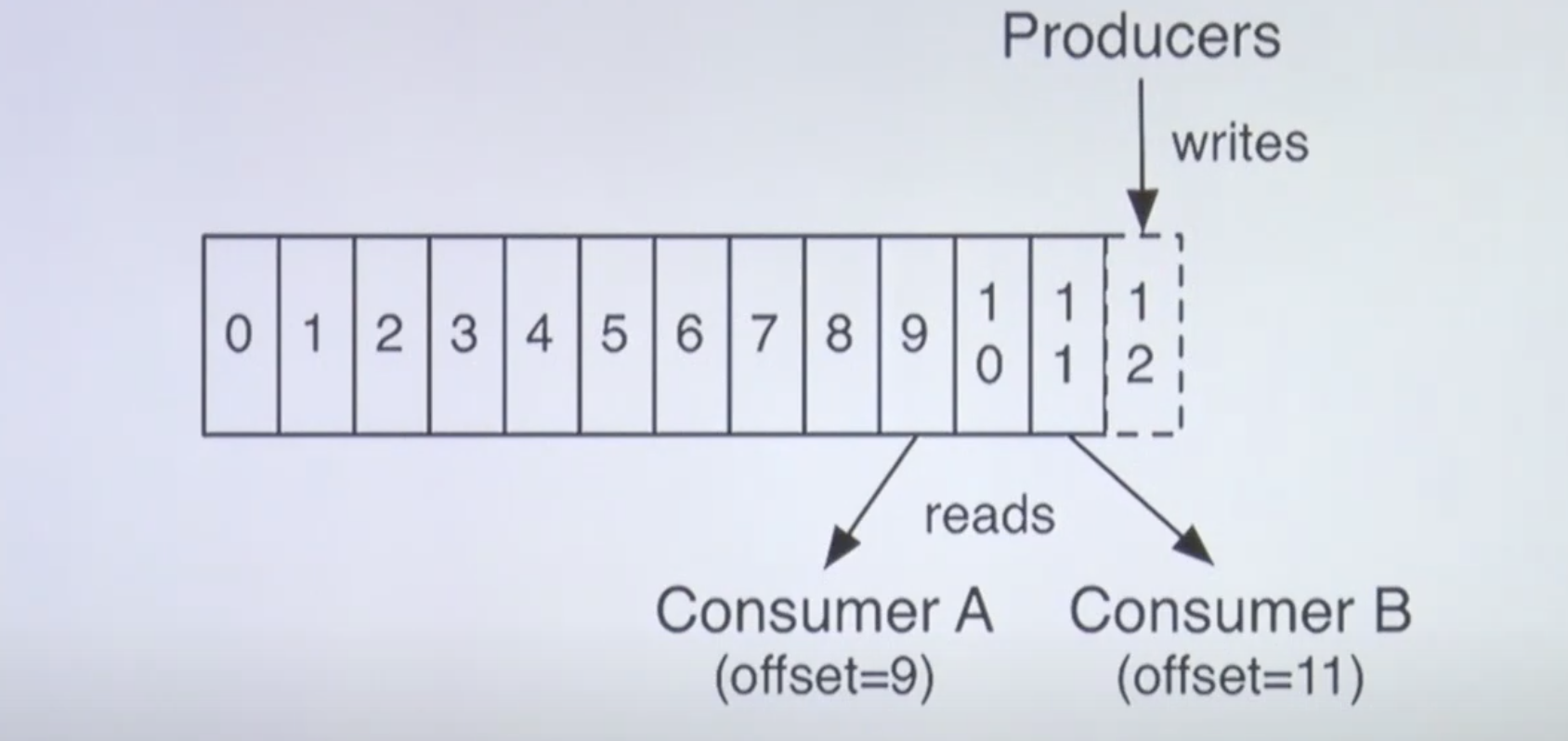
Consumer B가 11번을 가져갔다는 말은 이미 0~10번을 가져갔다는 말이다.
- 프로듀서는 레코드를 생성하여 브로커로 전송
- 전송된 레코드는 파티션에 신규 오프셋이 지정된 레코드로 저장
- 컨슈머는 브로커로부터 레코드를 요청하여 가져감(polling)
브로커가 컨슈머로 보내는게 아니다!
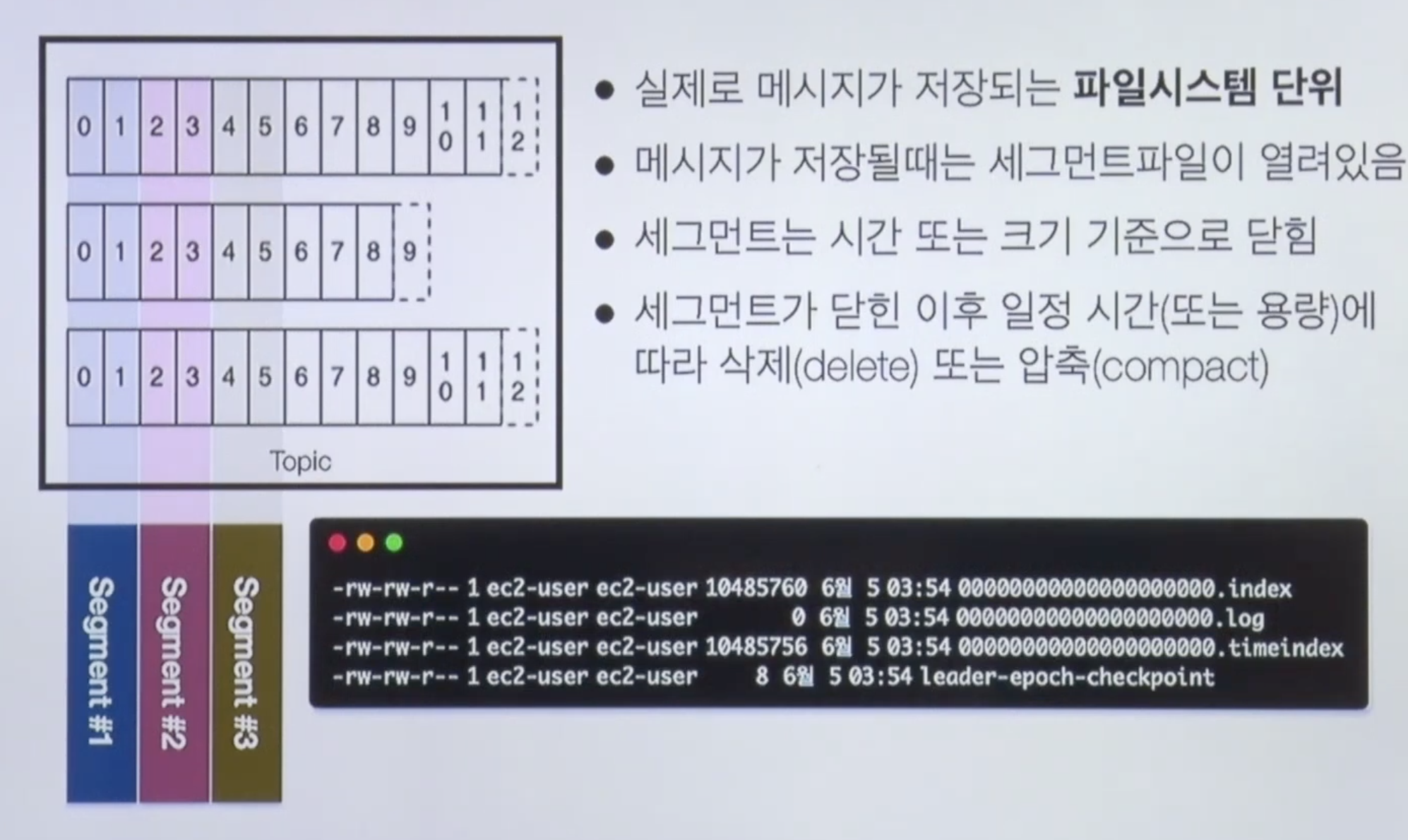
Kafka log and segment
이렇게 보낸 레코드가 파일시스템 단위로 저장된다. (DB에 저장이 아님!)
메시지가 저장 될 때는 세그먼트파일이라고 하는 ~.index/~.log/~.timeindex로 저장이 된다.
이 파일은 시간 또는 크기 기준으로 닫히게 되는데 닫힌 이후에는 브로커나 토픽에 설정된 시간 또는 크기에 따라 삭제 또는 압축이 된다.
즉, 이 시그먼트로 적재된 레코드들이 일정 시간이나 용량으로 삭제가 되면 이 레코드를 다시 사용할 수 없다.
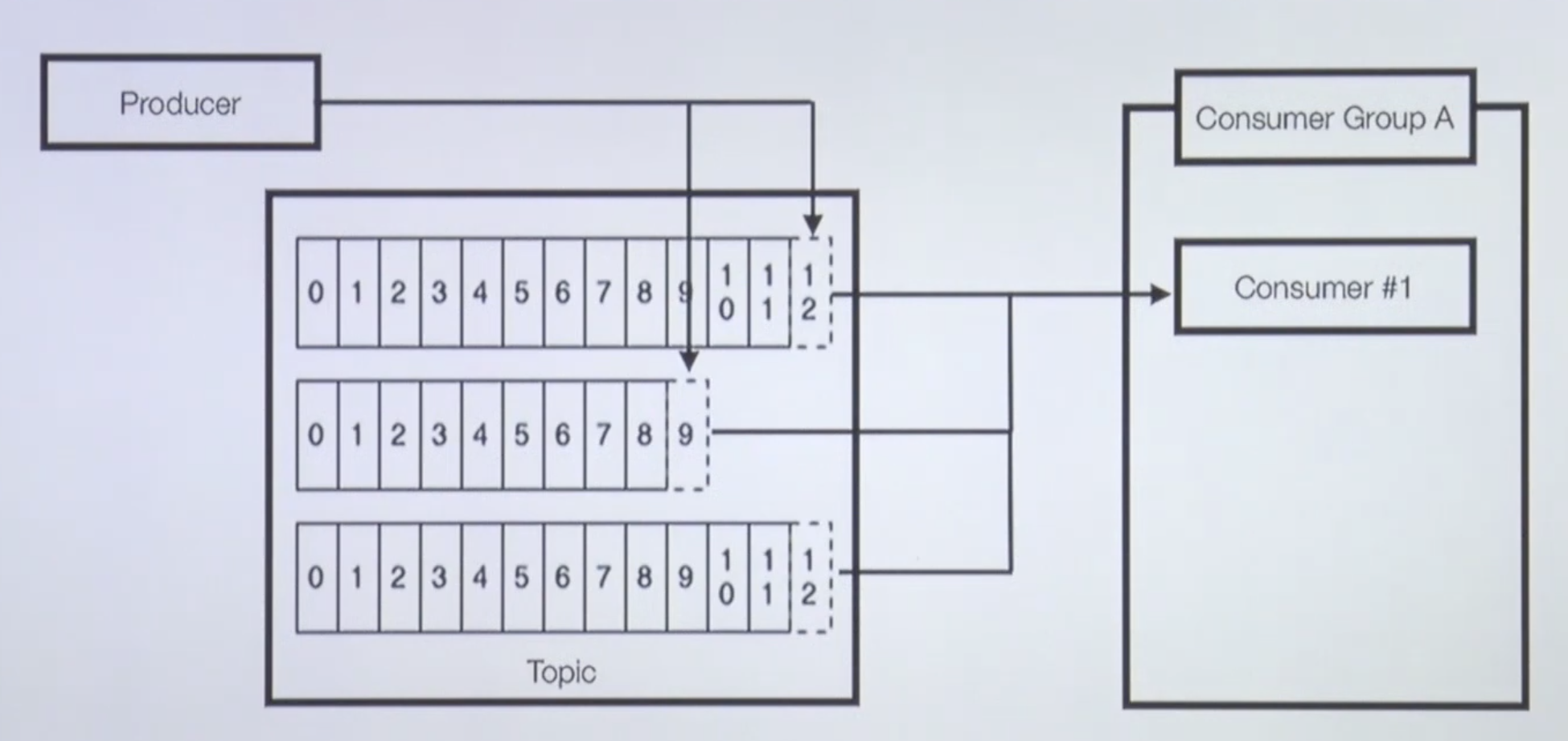
Topic, Partition, Consumer
Partition이 3개인 Topic과 Consumer 1대
아래는 토픽에 파티션 3개가 있는 상황이다.
프로듀서 한개가 3개의 파티션에 데이터를 보내고있다.
컨수머 한개가 파티션 세개에 할당 되어있다.
그러면 컨수머는 파티션으로부터 파티션 0번,1번,2번에 할당되어서 파티션 세개의 데이터를 계속해서 polling해 갑니다.
Partition이 3개인 Topic과 Consumer 3대
아래 처럼 컨수머가 3개인 경우에는 토픽이 세개고 컨수머가 세개일 때는 각각의 파티션이 각각의 컨수머에 할당 되어 1:1 매칭이 된다.
이렇게해서 컨수머는 각 파이션의 데이터를 가져가게 되는 것이다.
그러면서 토픽에 있는 모든 파티션이 할당 되고 컨수머는 같이 일을 하게 된다.
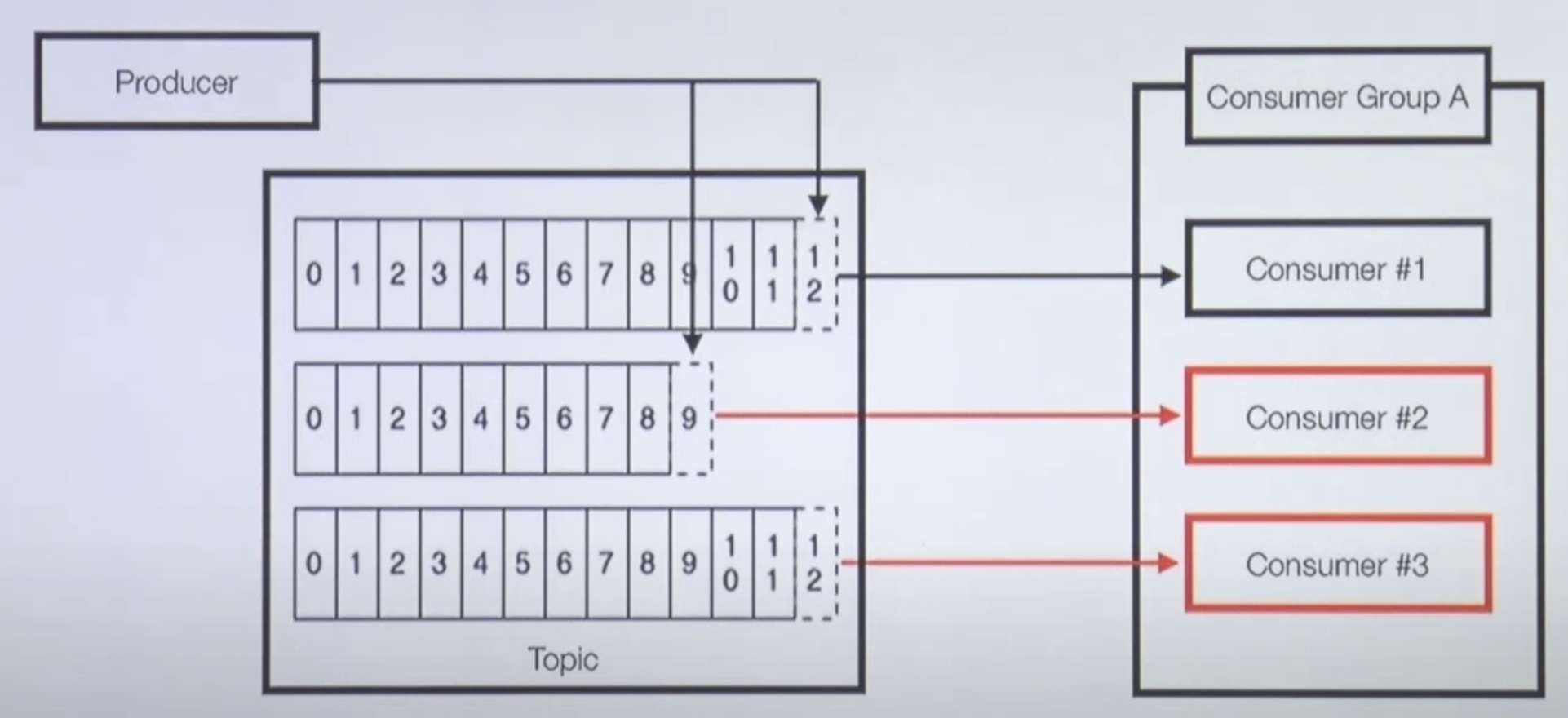
컨수머는 결국에는 파일에 저장한다던가 S3에 저장할 텐데, 컨수머 한대당 처리하는 프로세스 시간이 한정적인데 컨수머를 여러개 두고 병렬처리하면 각 파티션의 데이터를 각각의 쓰레드 혹은 프로세스가 실행하면 더욱 빠른속도로 처리할 수 있다.
- 파티션이 3개인 토픽
- 1개의 프로듀서가 토픽에 레코드를 보내는 중
- 1개의 컨슈머가 3개의 partition으로 부터 polling 중
Partition이 3개인 Topic과 Consumer 4대
불가능한 경우
컨슈머가 4대가 되면, 파티션이 더이상 컨슈머에 할당이 되지 못하고 컨슈머 한대가 놀게된다. 따라서 컨슈머 개수는 파티션 개수보다 같거나 작게 만들어야 한다.
단, 각각의 네개의 컨수머들이 같은 그룹 안에 있는 컨수머들일 때 불가능하다는 말이다.

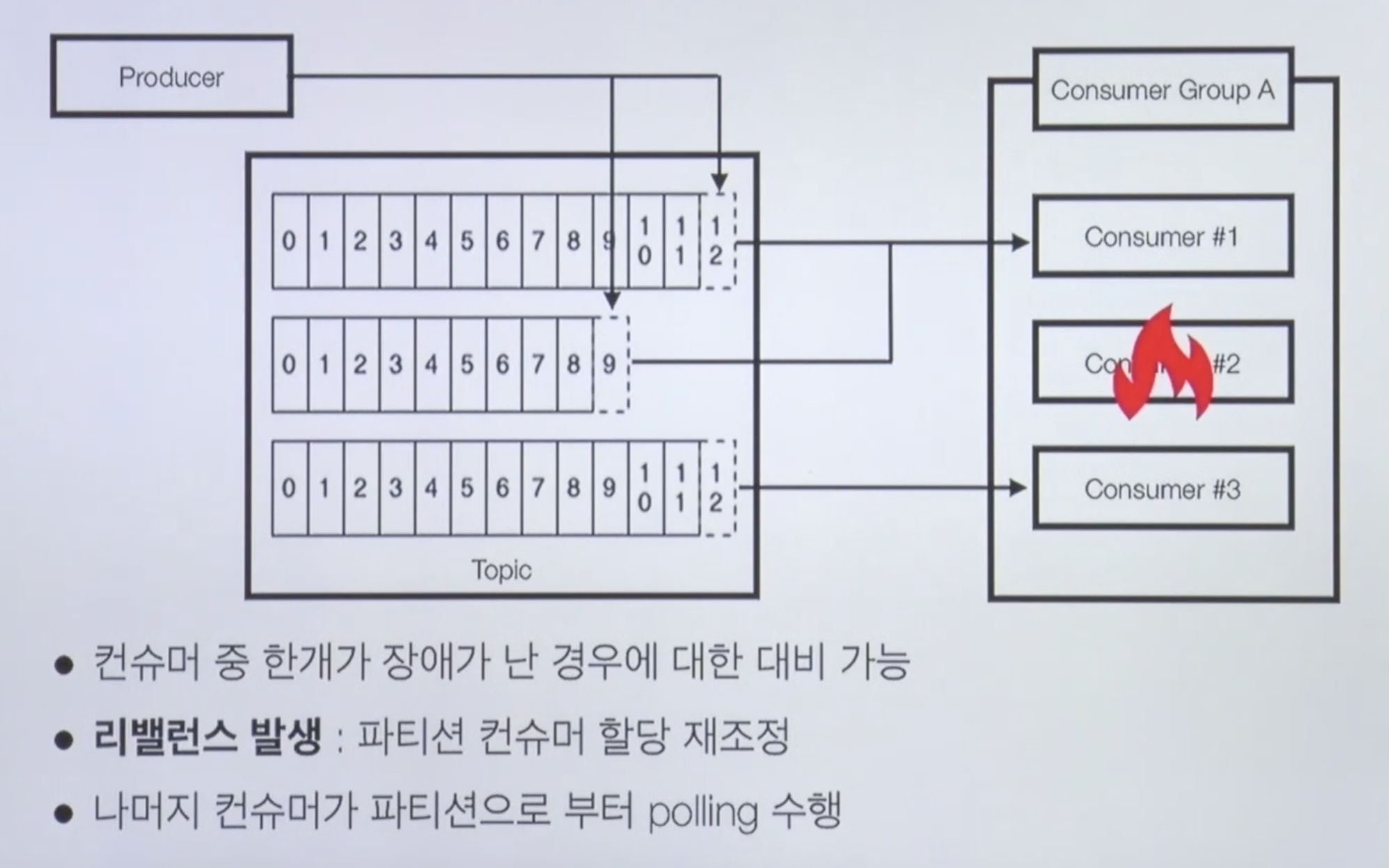
Consumer 3대 중 1대 장애 발생
만약에 컨수머 2번이 장애가 났을 때(쓰레드가 종료되거나, 프로세스, 서버가 종료되었을 때) 컨수머 1번이 두개의 파티션에 할당이 된다.
모든 파티션이 끝까지 데이터를 처리할 수 있도록 재할당 == 리밸런스
참고로 리밸런스가 발생되면 할당되는 과정에 중단이 일어나게 된다.
(어느 컨슈머에 할당이 되어야하는지 찾는 중-)
나중에 리밸런스리스너 등과 같이 기록을 해서 운영할 때 리밸런스할 때 얼마나 놓쳤는지 확인할 수 있다.
2개 이상의 Consumer Group
컨슈머 그룹 A는 컨슈머 한개, 컨슈머 그룹 B도 컨슈머 하나를 가지고 있다.
그러면 토픽안에 있는 파티션의 데이터들을 각각, 따로따로 목적에 따라 컨슈머 그룹을 분리해서 처리할 수도 있다.
컨슈머 A의 컨슈머 1번이 파티션 0의 12번 오프셋 레코드를 처리해도 컨슈머 B는 A와 상관없이 파티션 0의 12번을 처리할 수 있다.
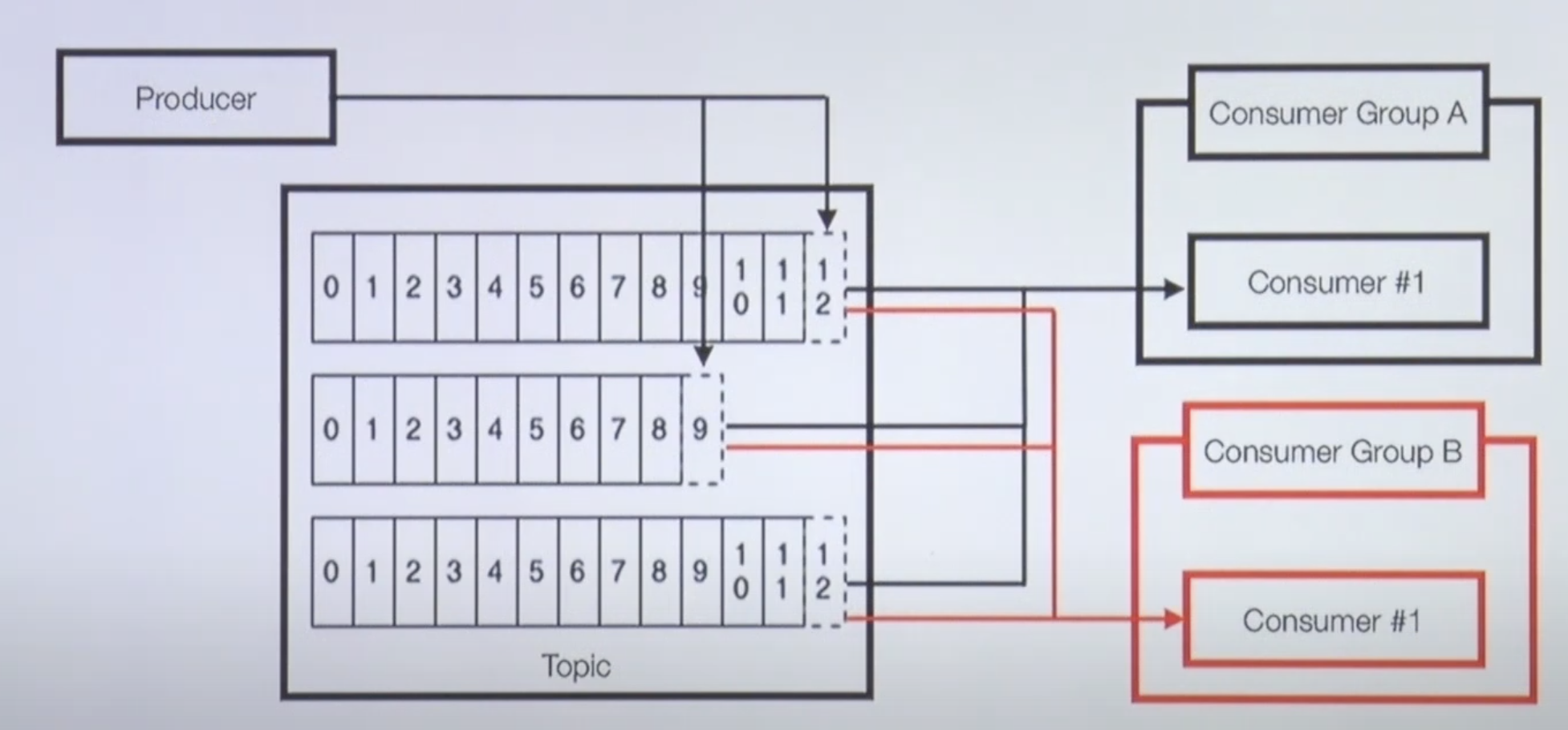
- 목적에 따른 컨슈머 그룹을 분리할 수 있다.
참고 💁🏻♀️
위에 처럼 목적에 따라할 수도 있지만, 장애에 대응하기 위해 재입수(또는 재처리) 목적으로 임시 신규 컨슈머 그룹을 생성하여 사용하기도 한다.왜냐하면 이미 처리중이고 스트리밍 처리중인(실제 라이브중인) 컨슈머 그룹은 그대로 처리하도록 하고 어떤 중간의 데이터가 재처리 되어야 한다면 새로운 컨슈머 그룹을 만들어서 다시 중간부터 재처리한다.
Application log 적재용 Consumer Group 2개
어플리케이션 로그를 적재한다고 가정했을 때 엘라스틱서치/하둡을 통해 적재 가능하다.
실시간으로 검색을 통해서 원하는 로그를 볼 땐 Kibana를 통해서 엘라스틱서치로 통해 보는게 좋다.
그러나 데이터 양이 많아지고 1개월, 6개월, 1년 단위로 적재되면 테라바이트가 넘어갈텐데, 이건 하둡을 통해서 적재하는 방법도 있다.
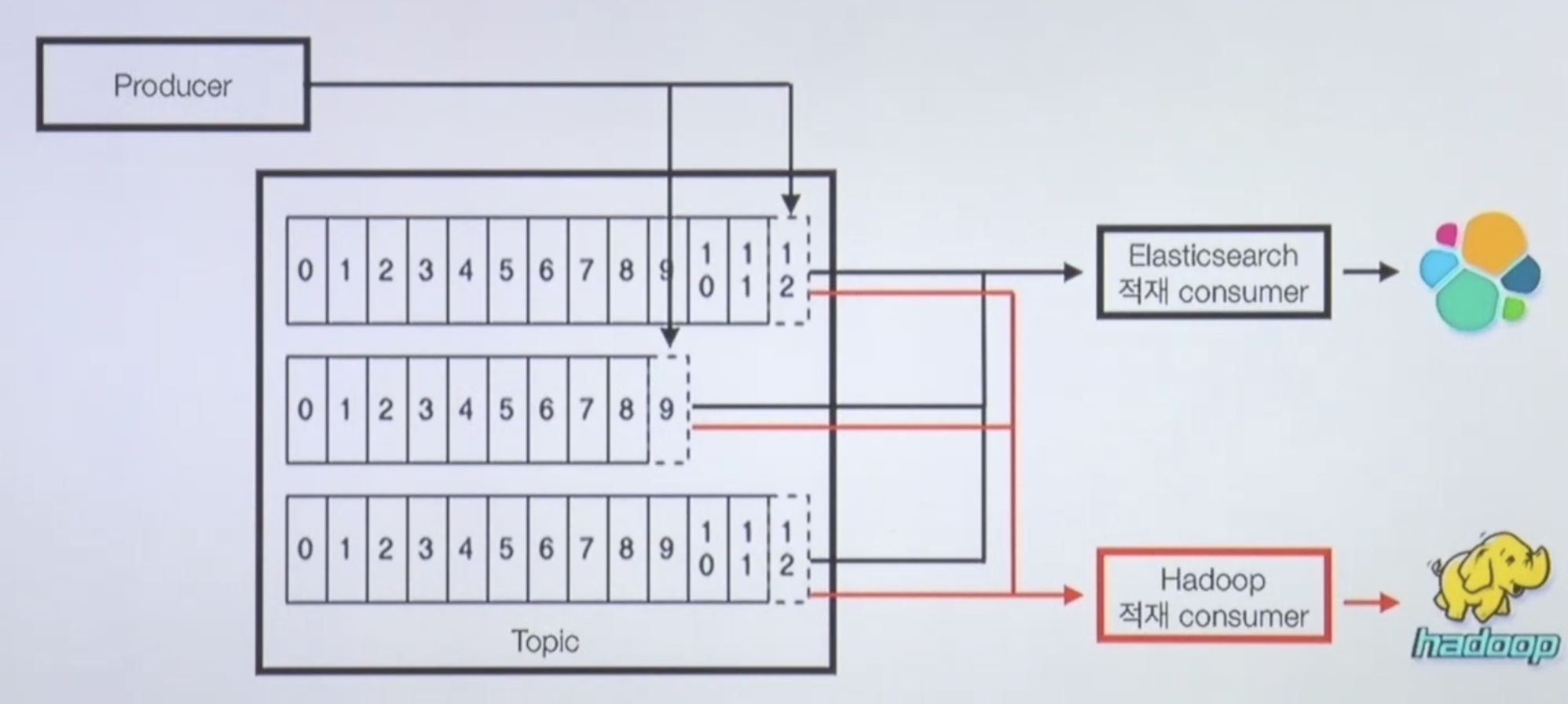
- Application log 적재 상황 Example
- 엘라스틱서치 : 로그 실시간 확인용. 시간순 정렬
- 하둡 : 대용량 데이터 적재. 이전 데이터 확인용
Consumer Group 장애에 격리되는 다른 Consumer Group
그래서 목적에 따라 동시에 적재한다면 아주 좋다!
각 컨슈머 그룹은 장애에 격리가 되는데 하둡이 장애가 나서 하둡 적재 컨수머가 하둡에 적재를 못할 때 엘라스틱 서치도 장애가 나면 안될것이다. 하둡이 복구되는 것과는 무관하게 엘라스틱 서치에는 적재할 수 있다. 따라서 간섭을 줄일 수 있고 엘라스틱은 그대로 볼 수 있고 하둡은 적재 중단 이후부터 다시 적재할 수 있다.
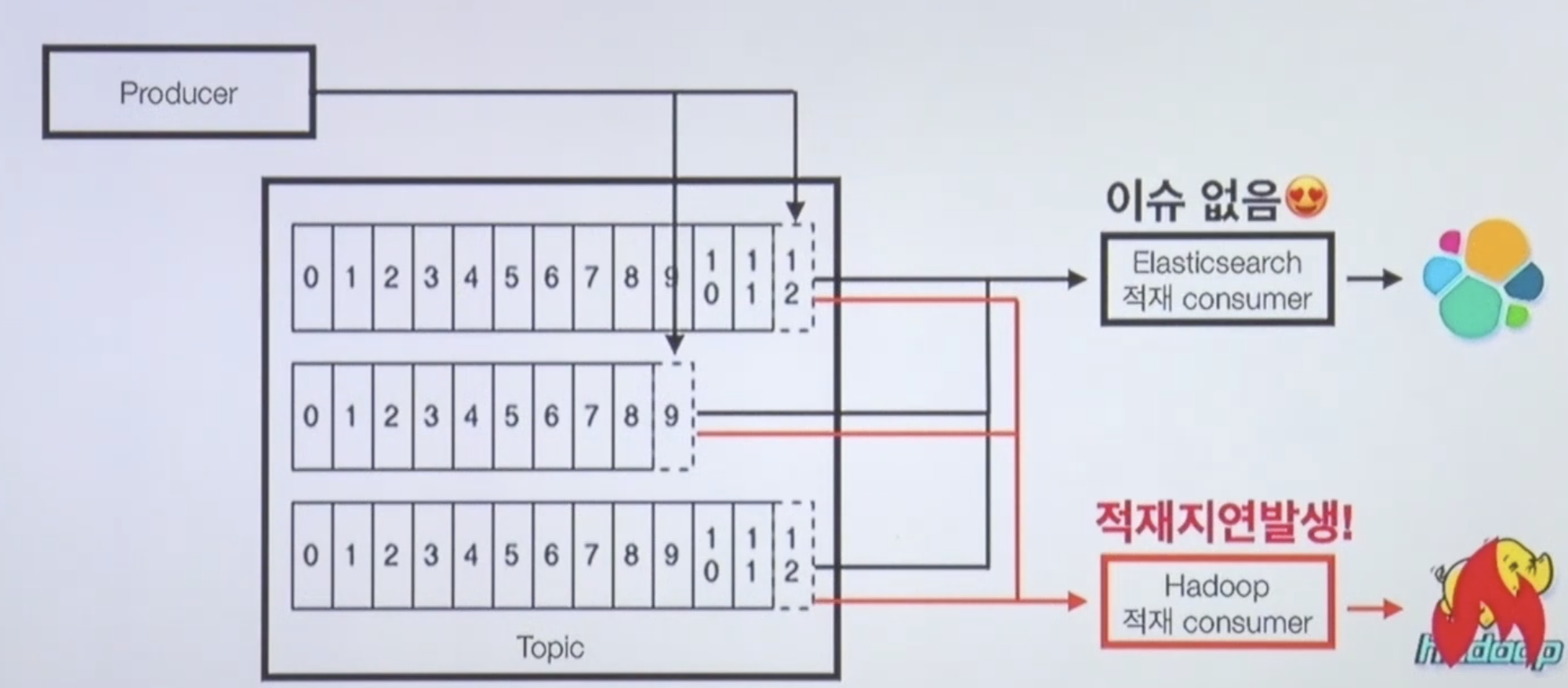
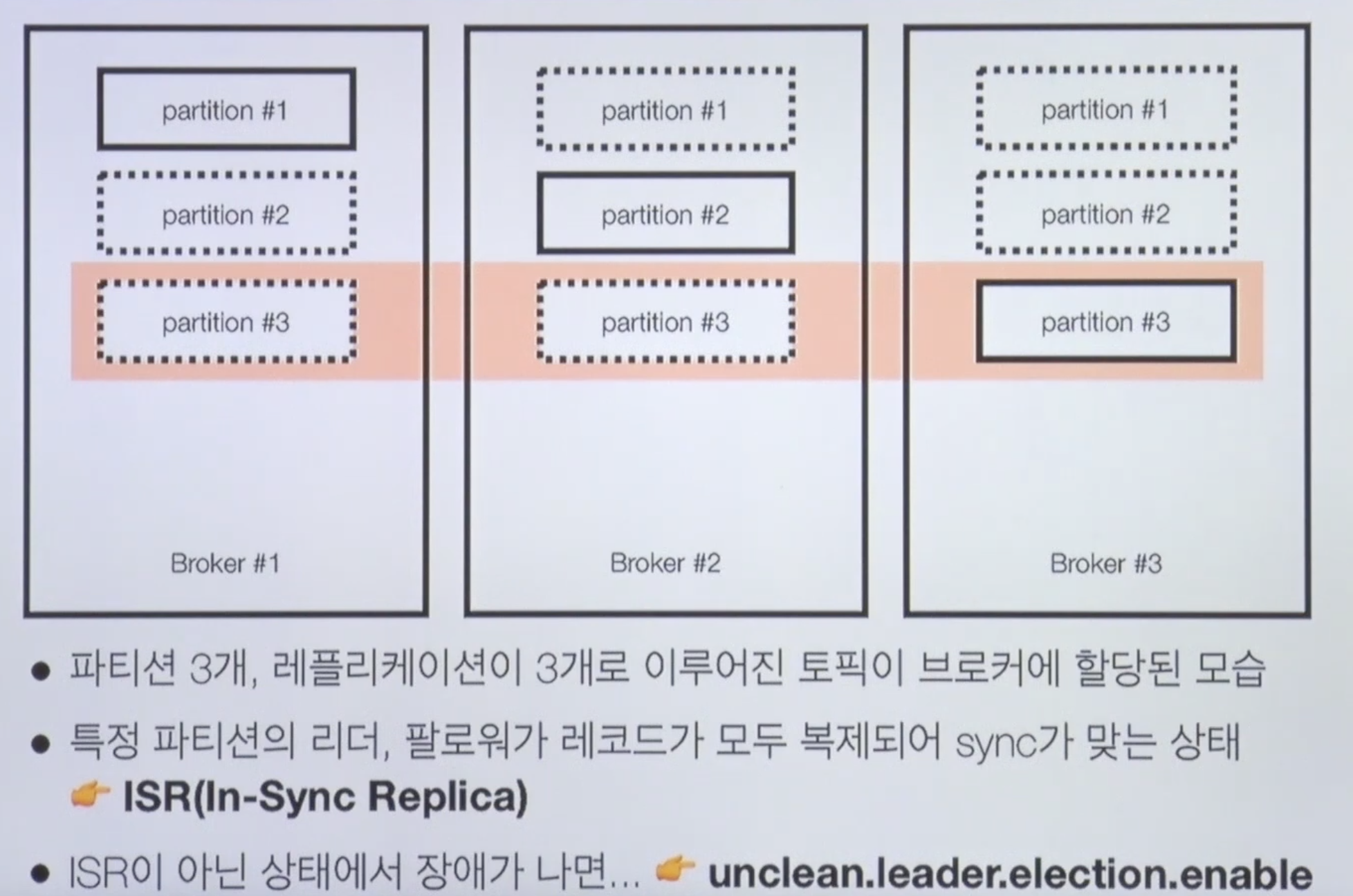
Broker partition replication
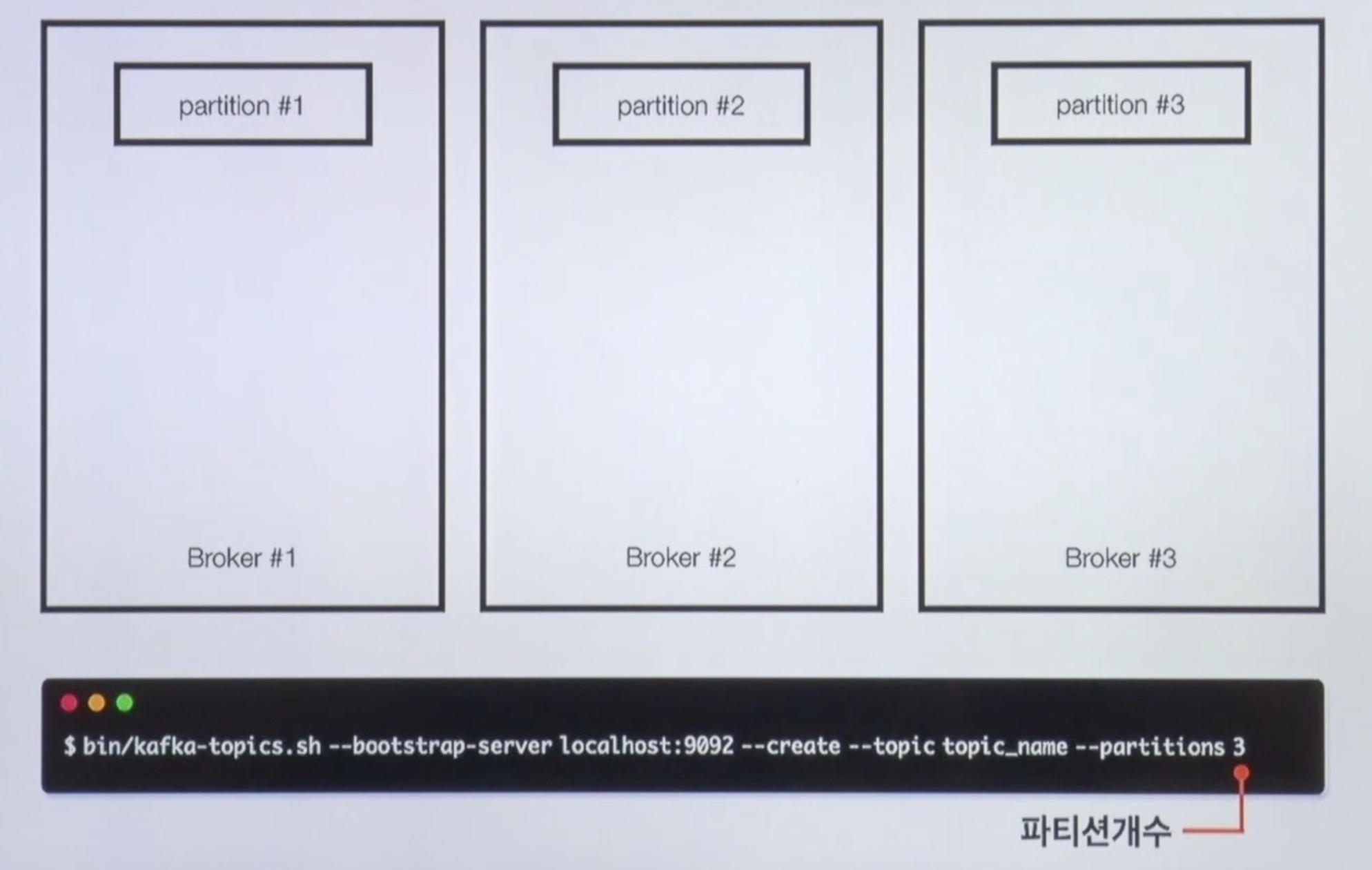
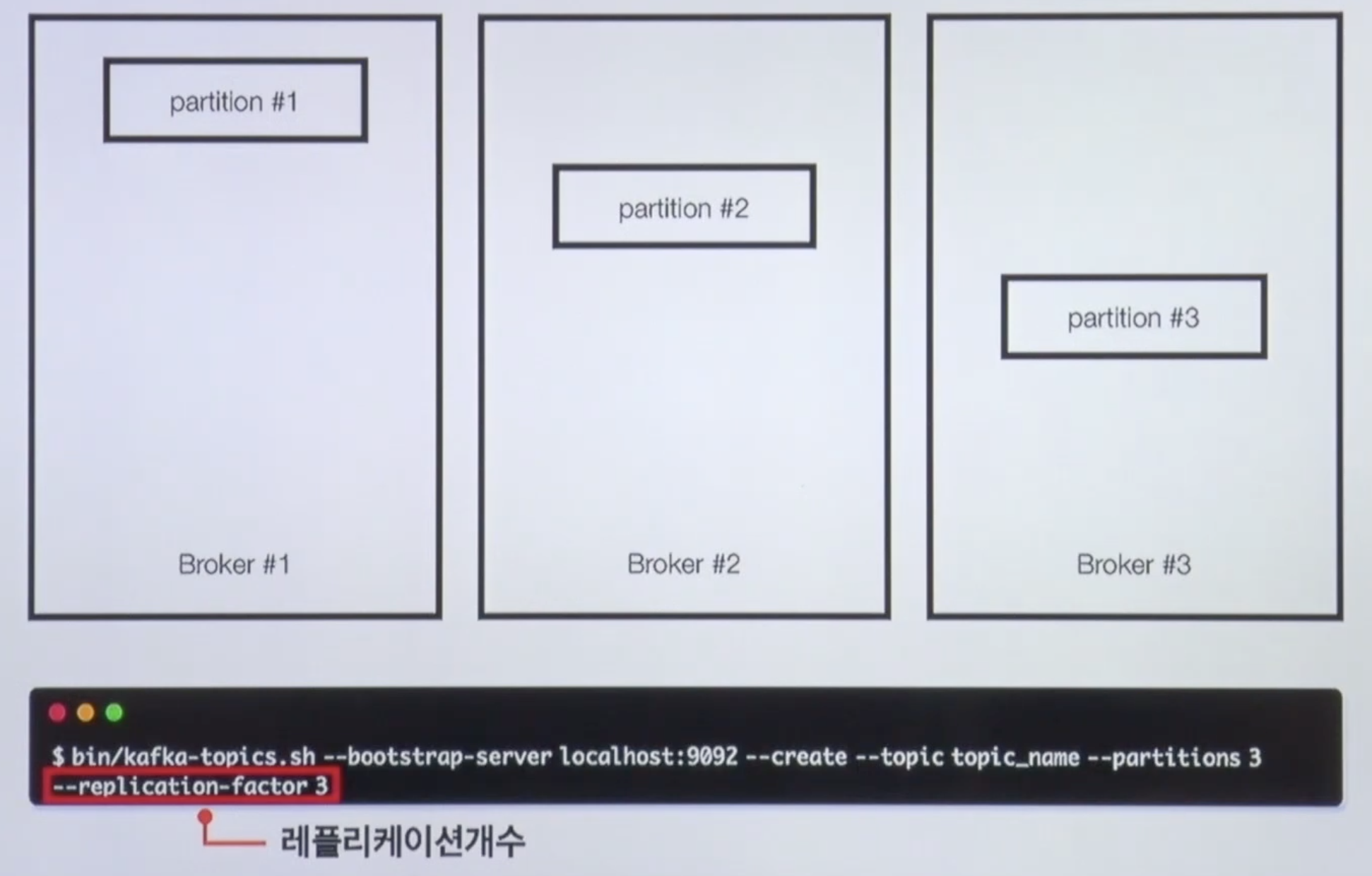
터미널 명령어는 카프카 토픽을 생성하는 명령어다
kafka-topics.sh: 카프카 토픽스 쉘 스크립트이다.- 카프카의 토픽을 생성하거나, 리스트를 보거나 혹은 수정할 수 있다.
--bootstrap-server localhost:9092: 로컬호스트의 9092, 즉 내 로컬 컴퓨터의 떠져있는 카프카 브로커에 명령을 내린다는 뜻--create --topic topic_name --partitions 3: 토픽을 만들겠다. 토픽네임, 파티션 개수 지정
이렇게 옵션을 주고 만들게 되면 브로커 세개일때는 파티션이 균등하게 1,2,3이 만들어진다.
Kafka Broker Issue 🧨
만약 브로커 1번에 장애가 생겼을 때 파티션 1번 사용이 불가능한데,
Q) 그렇다면 카프카 브로커 이슈에 대응하기 위한 방법은 뭘까?
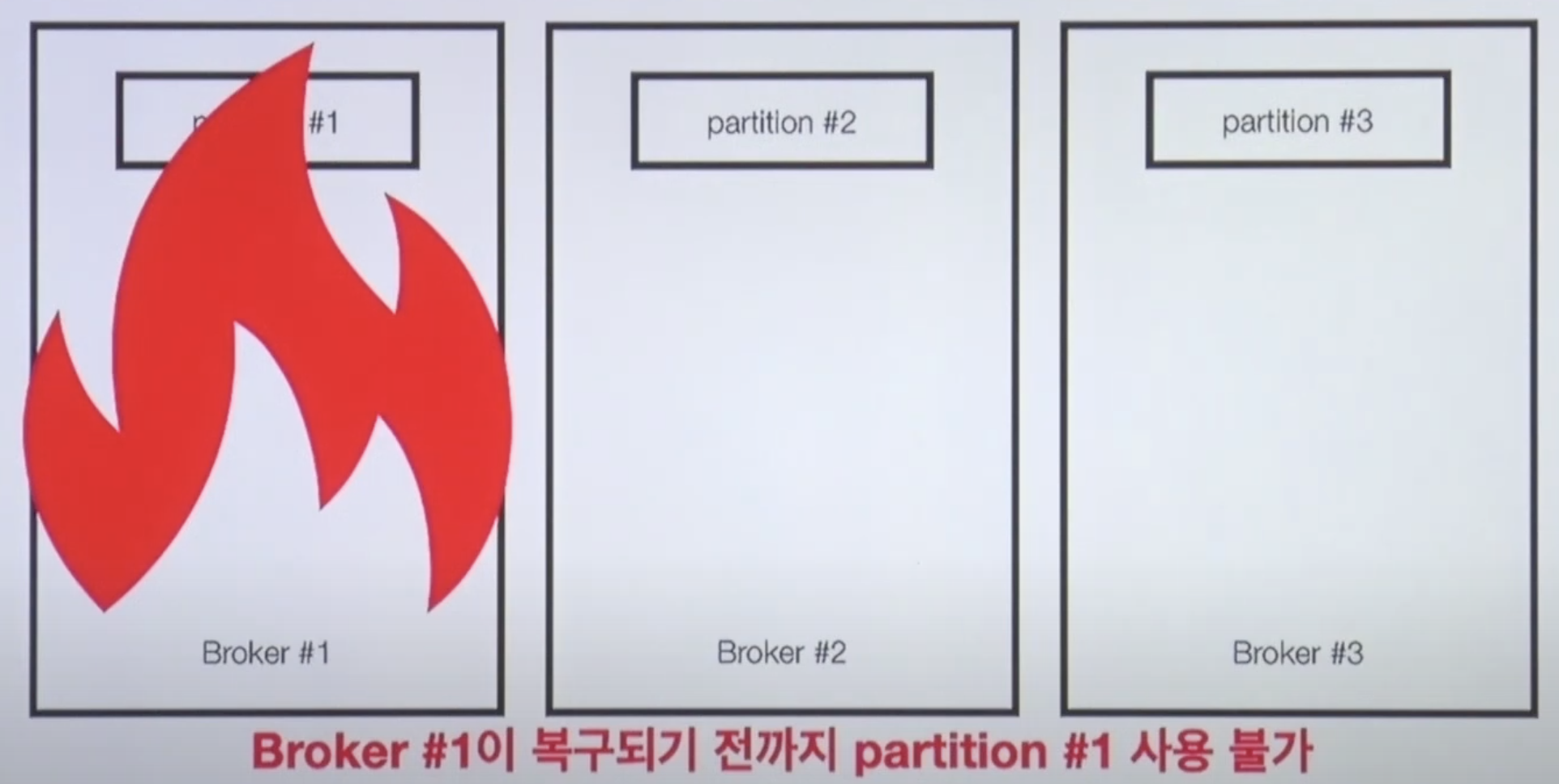
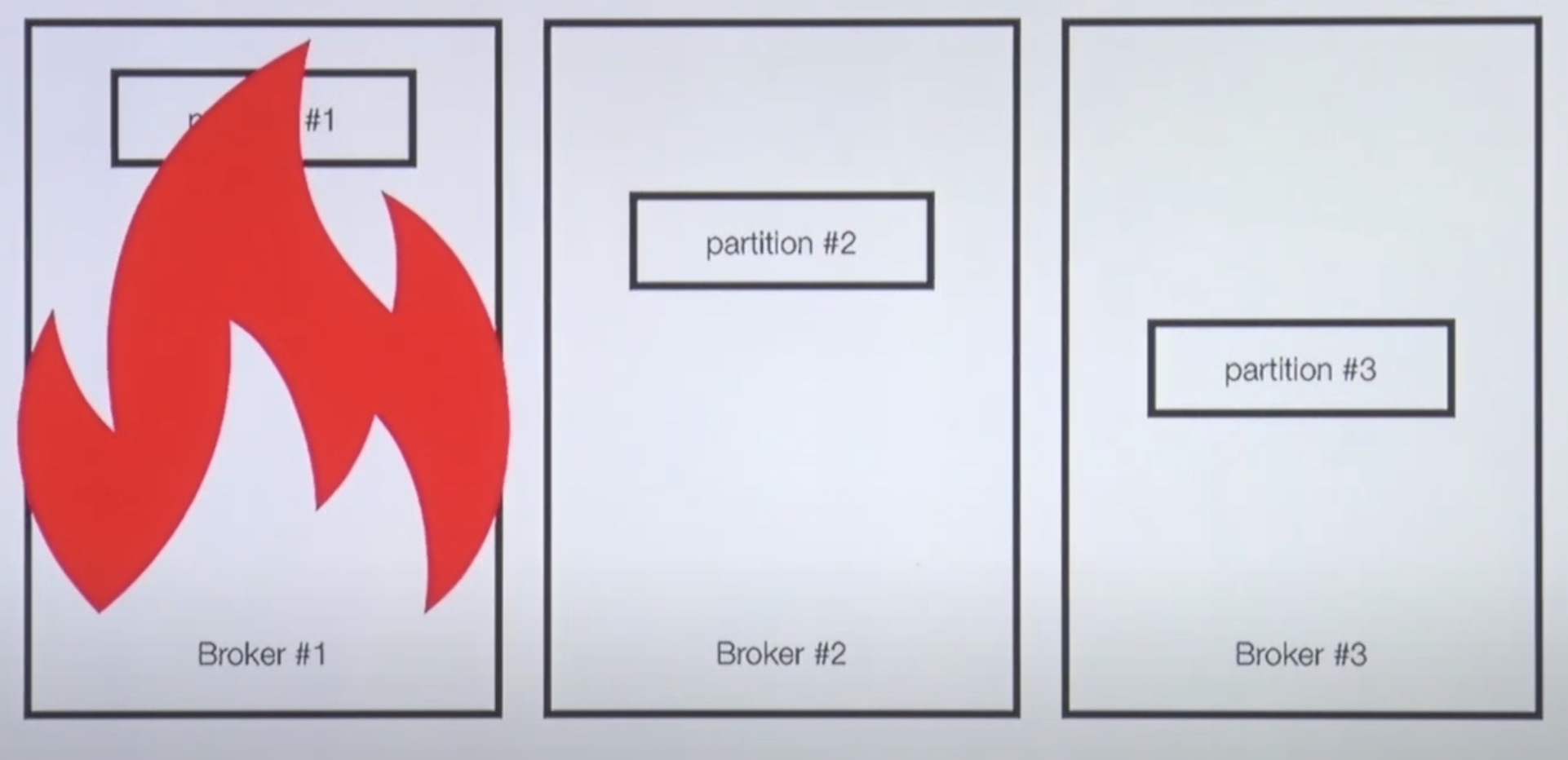
A) Partition을 다른 Broker에 복제하여 이슈에 대응한다.
1번 Broker에 이슈가 생기면 다른 Broker에 복제된 데이터를 사용한다.
Broker Partition replication 설정 in kafka-topics
고가용성을 위한 복제
파티션 1번이 브로커 2번, 브로커 3번에 복제가된 걸 볼 수 있다.
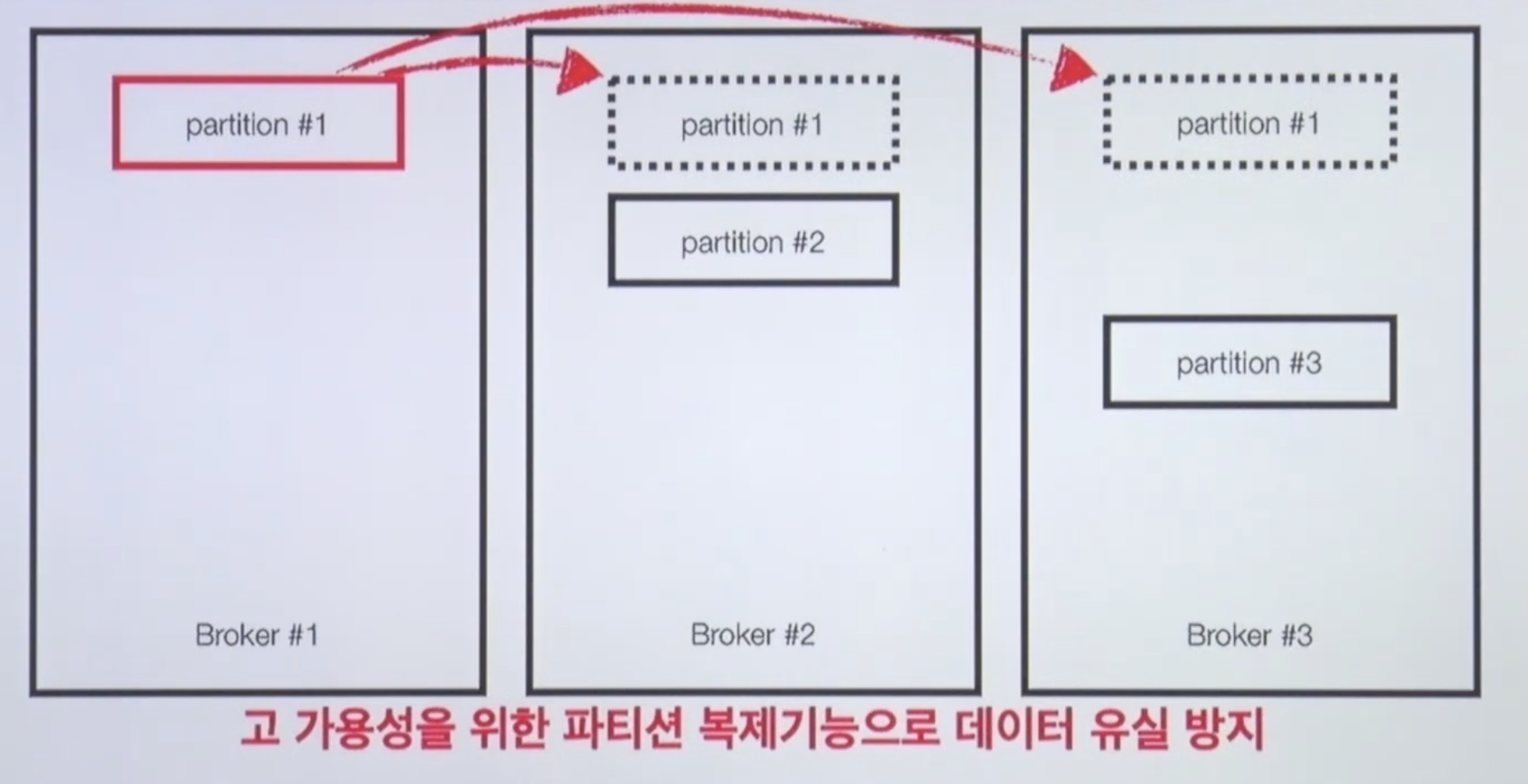
리더 파티션, 팔로워 파티션
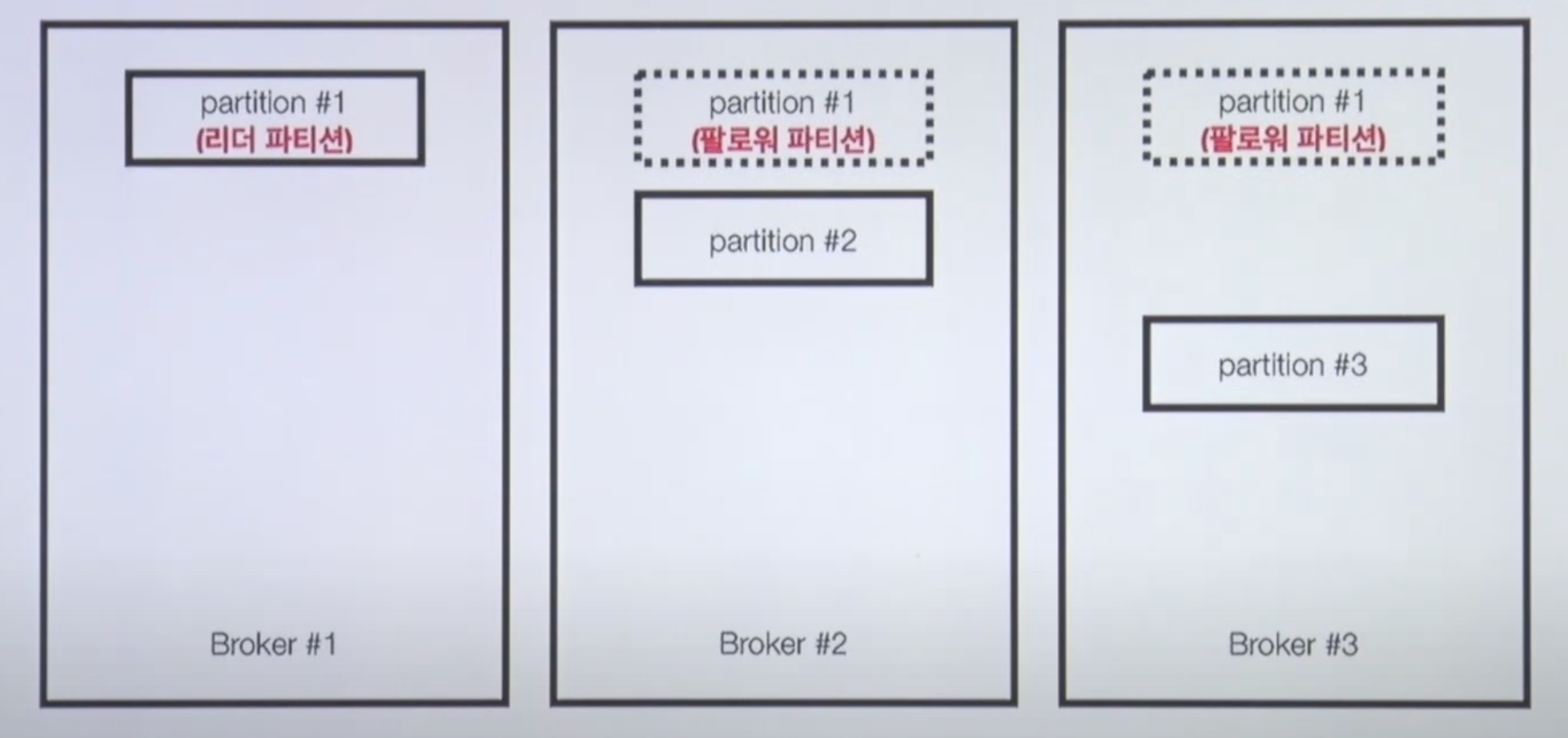
- 리더 파티션 : Kafka 클라이언트와 데이터를 주고 받는 역할
- 팔로워 파티션 : 리더 파티션으로 부터 레코드를 지속 복제(복제하는데 시간은 걸림).
리더 파티션의 동작이 불가능할 경우 나머지 팔로워 중 1개가 리더로 선출됨- 리더 파티션의 데이터가 늘어나면 오프셋이 계속해서 늘어날텐데 팔로워 파티션이 이걸 캐치해서 리더 파티셋을 복제하는 것이다.
리더 파티션의 오프셋이 0부터 100까지 있을 때 나머지 팔로워 파티션도 0부터 100까지 완벽하게 복제가 되어있다면 ISR 상태.
고가용성에 아주 중요하다.