연관관계
@OneToMany + @JoinColumn = 포린키로 참여할 컬럼을 지정할 수 있다.
그 포린키에 해당하는 멤버변수가 있고, 그 컬럼이 있다고 했을 때, 그 컬럼을 테이블이 생성된다고 했을 때 그 컬럼이 누구를 참조하자면 B를 has-a로 B테이블의 프라이머리키를 포린키로 자동 참조하게 된다.
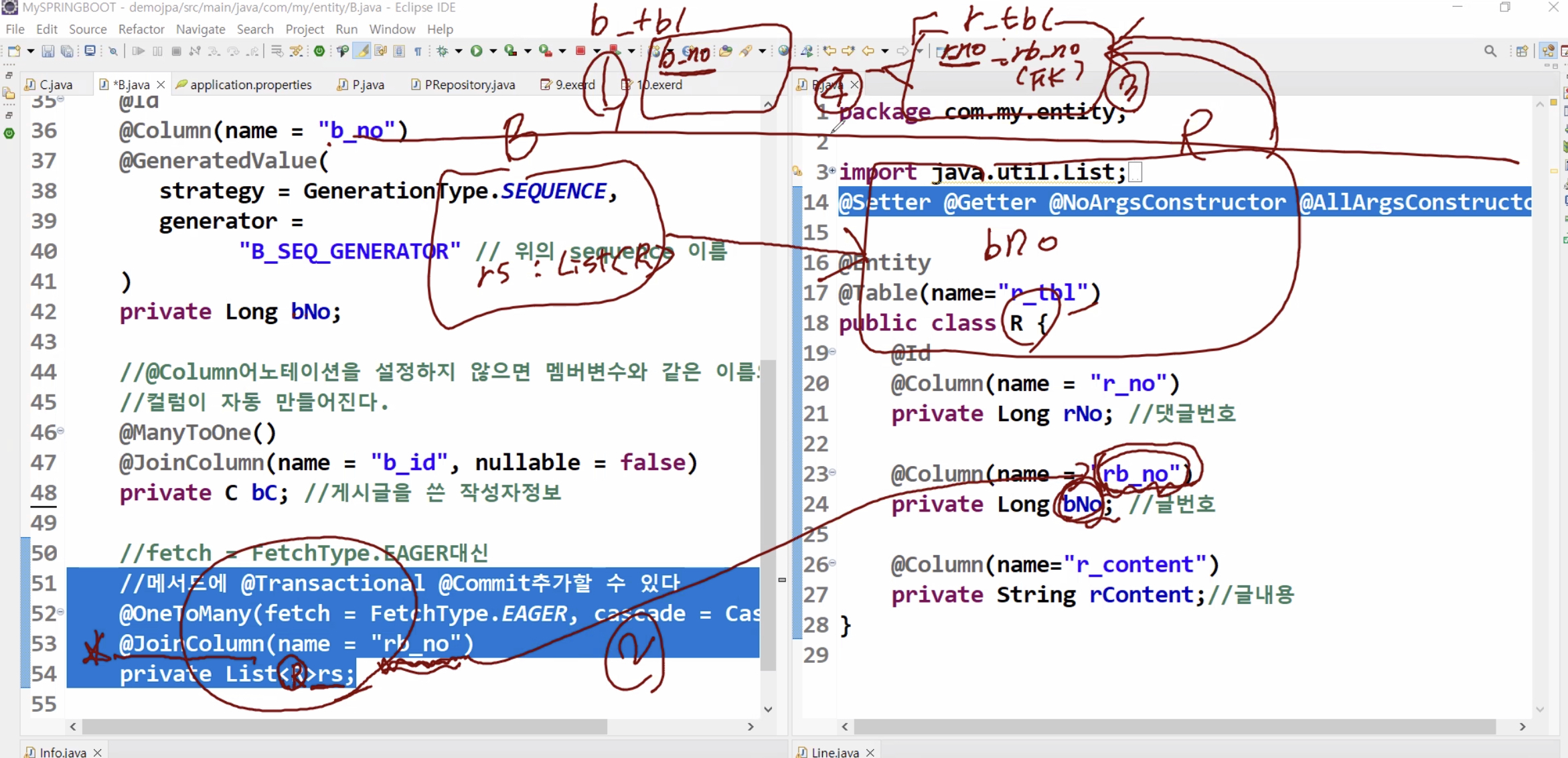
1. 비 테이블 생성
2. 관계선 따라가서 R 테이블 생성 rb_no 컬럼 찾아가서 테이블 생성할 때 포린키로 생성한다.
부모인 게시글을 삭제하려고할 때,
br.deleteById()를 썼을 때, delete SQL 구문이 만들어지는데 이 delete SQL 구문이 부모쪽에서 만들어져 수행되려고한다.
근데 이때 constraint를 맞추기 위해 Null값을 넣으려고한다.
이 오류를 그대로 두고 싶으면 그대로 @JoinColumn을 쓰면 된다.
그런데 우리는 JoinColumn을 안하고 같이 지워지게 하고 싶으면 cascade = 를 지정해준다.
info와 line의 관계
@OneToMany에서 @JoinColumn을 안씀.
mappedBy로 양방향으로 정의하고 cascade씀. 이때 delete()를 하면 쌍인 line들에 Null값이 들어가지 않고 같이 지워진다.
고객의 회계에 매우 중요한 히스토리이기 때문에 절대 이 데이터는 망가지면 안된다.
= 포린키 안쓰겠다. mappedBy 쓴다고 포린키가 만들어지는게 아니라 묶여있다는 것이다.
부모를 마음대로 삭제할 수 없고, 부모를 삭제할 때 자식도 같이 삭제하겠다!
그래서 mappedBy는 부모쪽에만 쓰이고, @OneToMany에서만 쓰인다.
mappedBy쓴다고 포린키가 자동연결되는 것이 아니니, 그 연결 고리로 info 멤버변수를 매핑하겠다.
포린키 연결을 위해서는 자식쪽에서 해줘야한다. @ManyToOne + @JoinColumn!
매니투원은 자식쪽에서 부모를 참조하기 위한 것.
자료가 먼저 저장되는곳이 부모, 나중에 저장되는 곳이 자식
자식입장에서 부모 피키를 포린키로 하겠다고 할 때는 매니투원..
원투매니는 부모쪽에서 자식을 참조하기위해.
자식쪽의 포린키를 설정하려면 조인컬럼
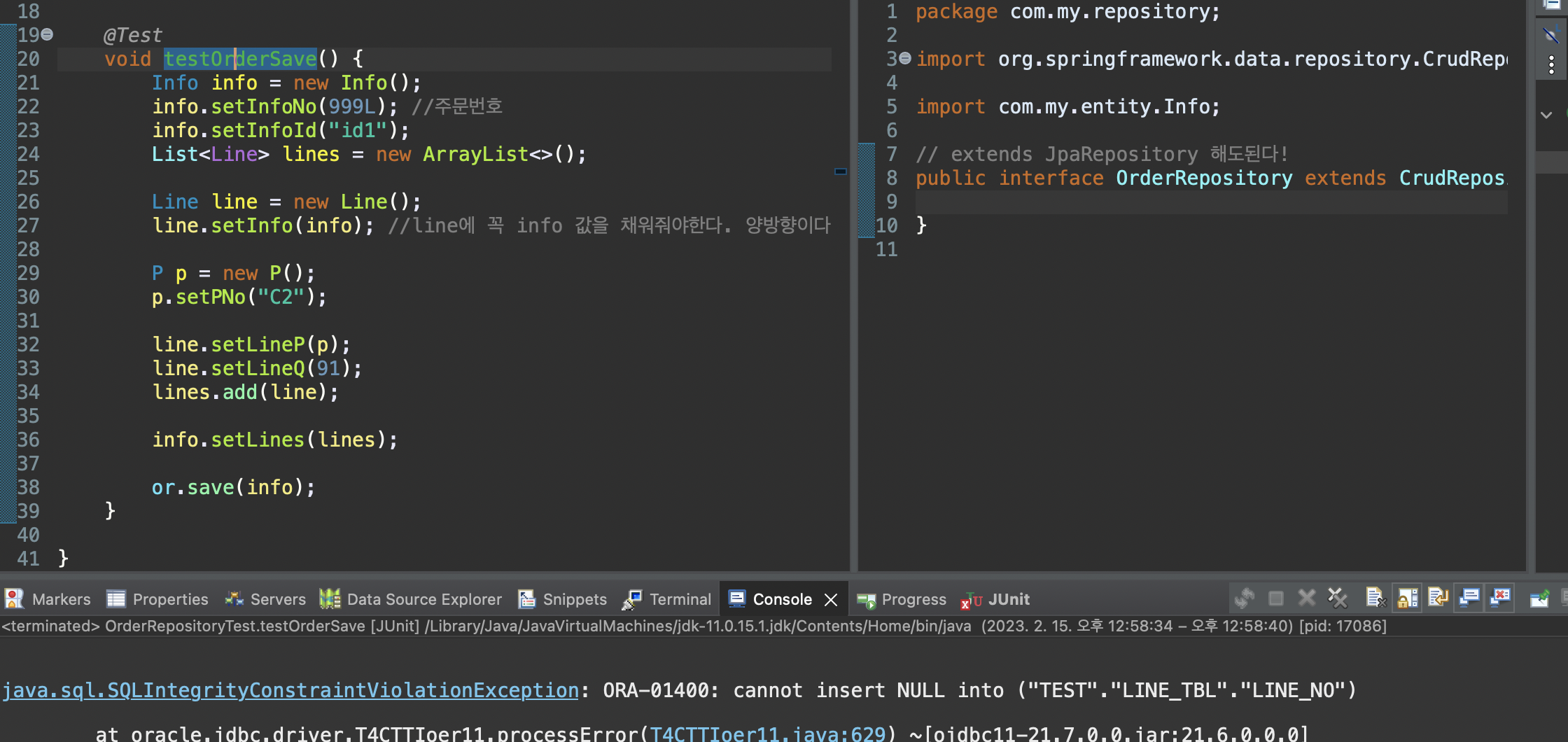
OrderRepo 하나만드는게 좋은지?
아니면 OrderInfoRepo 따로, OrderLineRepo 따로?
음 고민해봐야한다. 게시판과는 다르게 같이 움직이는 애들이므로 OrderRepo 하나만 만들어도된다.
lines를 삭제하고싶으면 info를 통해 지움