Kaleidoscope 언어를 통하여 LLVM의 컴포넌트를 활용하여 언어의 프론트앤드를 직접 구현해보자.
https://llvm.org/docs/tutorial/index.html
1~10장으로 구성되어 있다.

- 소스 코드를 tokenize 하는 Lexer 구현
- paser 구현 -> token stream을 AST로 변환
- AST 기반으로 IR 코드 생성
- JIT complier (Just-In-Time) 기능 추가
5. if/then/else/for loop 등의 제어 흐름 구조를 추가
6. 연산자 우선순위 지정 등 새로운 연산자를 정의할 수 있도록 언어 확장
- 변수 선언, 대입연산자 추가
- 실제 오브젝트 코드로 컴파일
- 디버깅을 위한 정보를 IR에 추가하는 방법 -> break point, 변수값 출력 등
- 추가적인 주제들
1~4장까지
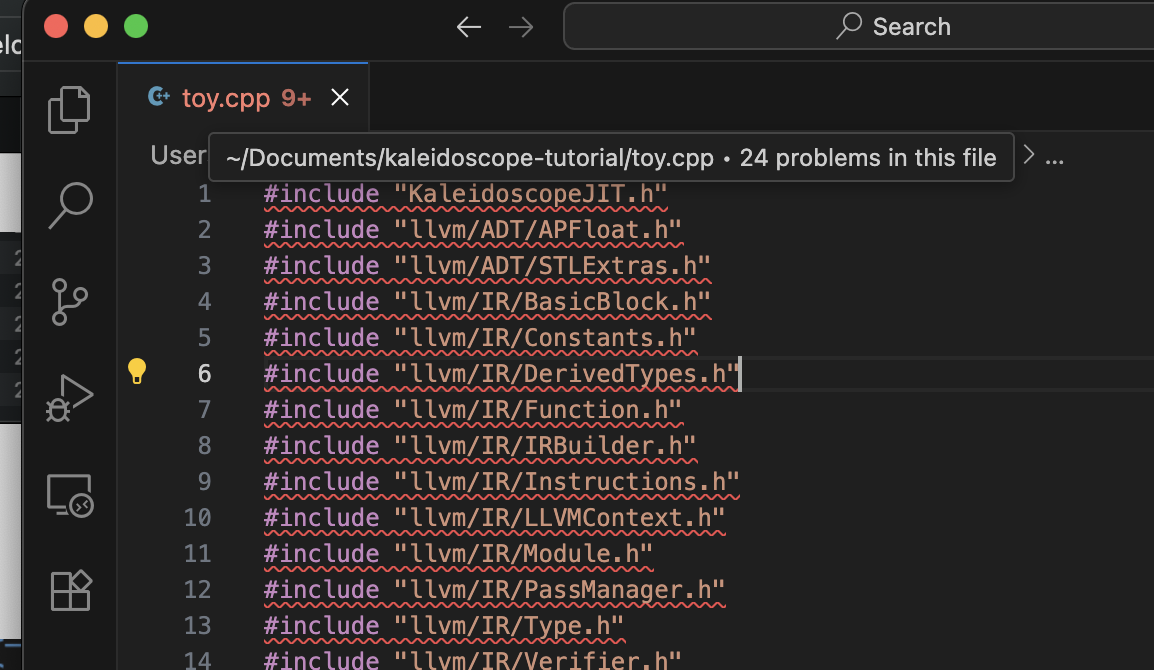
파일 경로 수정
주의해야 할 점으로, SelfExecutorProcessControl.h 헤더파일이 존재하지 않는것을 확인할 수 있다.
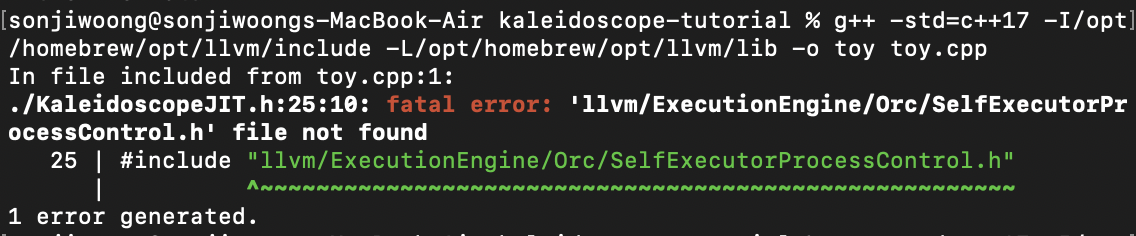
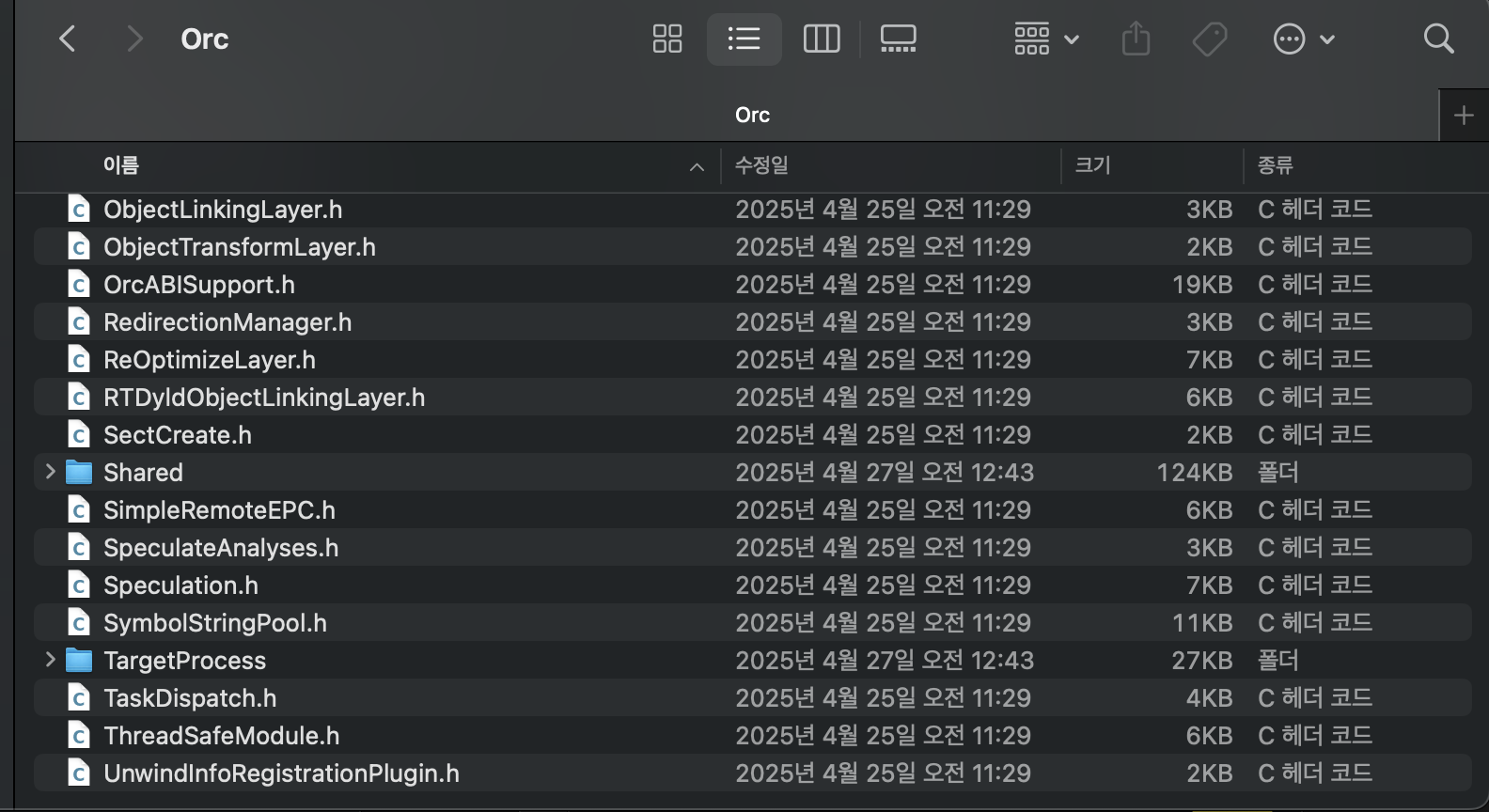
버전 13 이상의 LLVM에서는 SelfExecutorProcessControl.h가 별도의 파일이 아니라,
llvm/ExecutionEngine/Orc/ExecutorProcessControl.h 파일 안에 정의되어 있다고 한다.
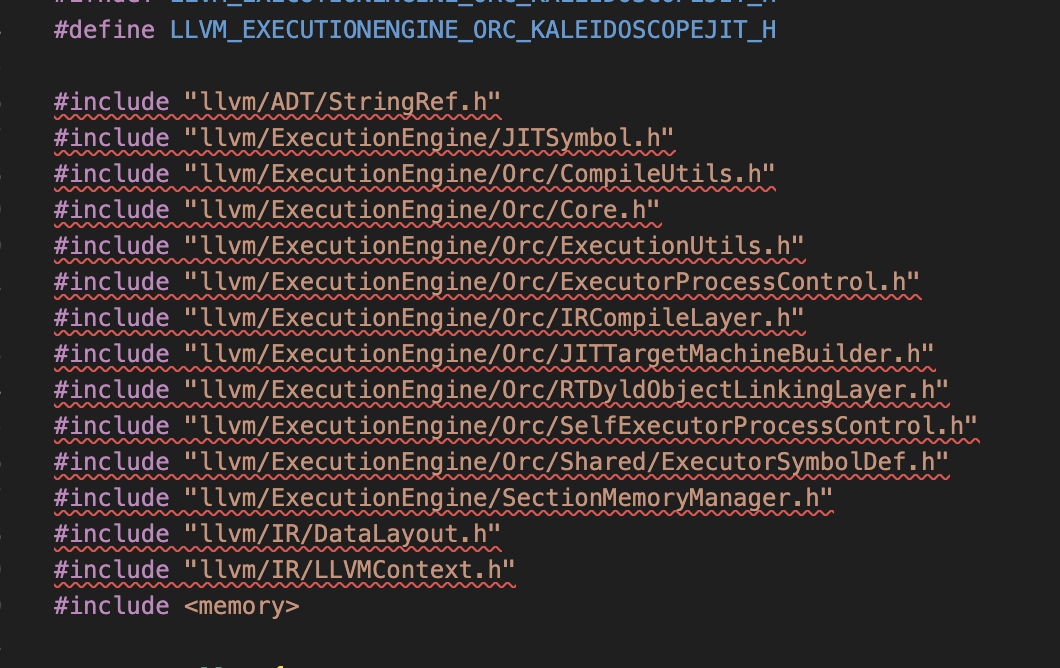
따라서 KaleidoscopeJIT.h 파일의 25번째 줄에서 Self를 빼주면 된다.
추가적으로 KaleidoscopeJIT.h 파일에서
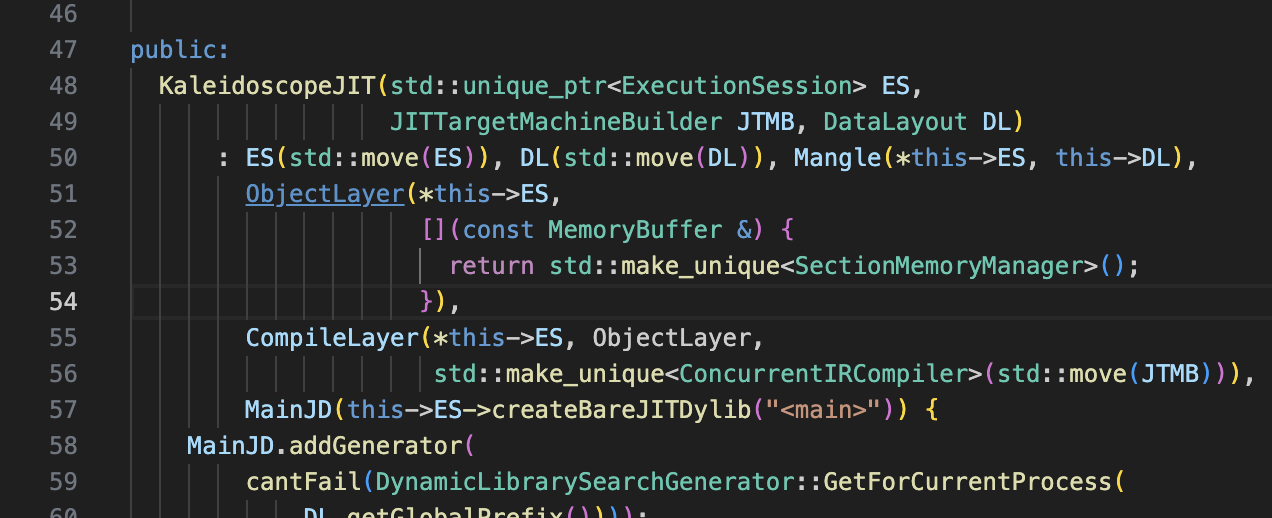

해당 부분을 위와 같이 매개변수가 없는 람다로 변경해야 한다. 최신 LLVM(특히 13 이상)에서는 RTDyldObjectLinkingLayer의 두 번째 인자(메모리 매니저 생성 함수)는 매개변수가 없는 함수 객체여야 하기 때문이다.

컴파일이 잘 된 모습이다.
1~4장까지의 내용에서는 kaledoscope 언어의 구현 과정에 대해 다루었다. LLVM IR, 최적화, JIT ,,
하지만 앞선 코드를 보면 call, return 즉 함수 호출과 리턴 외에는 제어 흐름이 전혀 없다. 해당 장에서 conditional branch를 구현해보자.
5,6장에서는 조금 더 자세한 설명을 통하여 LLVM에 대한 이해를 높여보자.
Kaleidoscope: Extending the Language: Control Flow
if, then, else
def fib(x)
if x < 3 then
1
else
fib(x-1) + fib(x-2);해당 기능을 구현하기 위하여, 앞선 장에서 구현했던 기능들의 확장이 필요하다.
1. Lexer: 새로운 keyword if,then,else 등을 인식하여야 한다.
2. paser: 새로운 구문 해석하여 AST 노드를 만들어야 한다.
3. AST: 새로운 노드 클래스를 추가
4. LLVM 코드 생성: LLVM IR 코드를 생성하여야 한다.
kaleidoscope는, statement가 없다. (함수형 언어)
따라서 조건을 평가 한 뒤 결과에 따라 then, else 부분의 값을 반환해야 한다. 이는 C언어의 삼항 연산자 '?:'
와 비슷하다. 조건은 boolean 값으로 해석한다. 즉
- 0이면 false
- 이외의 모든 값들은 true
주의해야 할 점은 side effect를 허용하므로 어떤 부분이 실행되는지 명확히 정의해야 한다.
Lexer Extension: if, then, else
// control
tok_if = -6,
tok_then = -7,
tok_else = -8,먼저 새로운 토큰을 정의한다. if, then, else를 키위드로 인식하여 고유한 토큰으로 처리되도록 한다.
if (IdentifierStr == "def")
return tok_def;
if (IdentifierStr == "extern")
return tok_extern;
if (IdentifierStr == "if")
return tok_if;
if (IdentifierStr == "then")
return tok_then;
if (IdentifierStr == "else")
return tok_else;
return tok_identifier;이후, input stream에서 식별자를 인식할 때, if/then/else 중 하나이면 해당 토큰을 반환하고 아니라면 일반 식별자 토큰을 반환하게끔 한다.
AST Extension: if, then, else
새로운 AST를 추가하여야 한다.
/// IfExprAST - if/then/else 표현식을 위한 AST 클래스
class IfExprAST : public ExprAST {
std::unique_ptr<ExprAST> Cond, Then, Else;
public:
IfExprAST(std::unique_ptr<ExprAST> Cond, std::unique_ptr<ExprAST> Then,
std::unique_ptr<ExprAST> Else)
: Cond(std::move(Cond)), Then(std::move(Then)), Else(std::move(Else)) {}
Value *codegen() override;
};if/then/else 구문 전체를 하나의 표현식으로 간주한다.
Paser Extension: if, then, else
lexer에서 토큰을 받아 파서에서 해당 구문을 parsing하는 함수를 작성해보자.
/// ifexpr ::= 'if' expression 'then' expression 'else' expression
static std::unique_ptr<ExprAST> ParseIfExpr() {
getNextToken(); // 'if' 토큰을 소비
// 조건식 파싱
auto Cond = ParseExpression();
if (!Cond)
return nullptr;
// 'then' 토큰 확인 및 소비
if (CurTok != tok_then)
return LogError("expected then");
getNextToken();
// then 부분 파싱
auto Then = ParseExpression();
if (!Then)
return nullptr;
// 'else' 토큰 확인 및 소비
if (CurTok != tok_else)
return LogError("expected else");
getNextToken();
// else 부분 파싱
auto Else = ParseExpression();
if (!Else)
return nullptr;
// IfExprAST 노드 생성
return std::make_unique<IfExprAST>(std::move(Cond), std::move(Then), std::move(Else));
}그리고 파서에서 if 토큰을 인식하면, ParseIfExpr()을 호출하기 위하여
static std::unique_ptr<ExprAST> ParsePrimary() {
switch (CurTok) {
default:
return LogError("unknown token when expecting an expression");
case tok_identifier:
return ParseIdentifierExpr();
case tok_number:
return ParseNumberExpr();
case '(':
return ParseParenExpr();
case tok_if:
return ParseIfExpr();
}
}LLVM IR Extension: if, then, else
이제 중간 표현 코드를 생성하여야 한다.
먼저 예시를 통하여 이해해보면
//def baz(x) if x then foo() else bar(); 변환
declare double @foo()
declare double @bar()
define double @baz(double %x) {
entry:
%ifcond = fcmp one double %x, 0.000000e+00
br i1 %ifcond, label %then, label %else
then: ; preds = %entry
%calltmp = call double @foo()
br label %ifcont
else: ; preds = %entry
%calltmp1 = call double @bar()
br label %ifcont
ifcont: ; preds = %else, %then
%iftmp = phi double [ %calltmp, %then ], [ %calltmp1, %else ]
ret double %iftmp
}
코드 생성의 핵심 개념
• 조건 분기(Branch):
fcmp one 명령으로 조건을 평가하고, br 명령으로 then/else 블록으로 분기
• then/else 블록:
각각의 블록에서 필요한 연산(여기서는 함수 호출)을 수행한 후, 공통 블록(ifcont)으로 이동
• PHI 노드:
ifcont 블록에서는 PHI 노드를 사용해, 어떤 경로에서 왔는지에 따라 값을 선택하여 반환. SSA(Static Single Assignment)
C++ 코드로의 매핑 (핵심 로직)
IfExprAST::codegen()
1. 조건식 코드 생성:
조건식을 평가하여 Value*를 얻고, fcmp 명령을 사용해 0.0과 비교(불리언 변환)
2. 분기 생성:
LLVM IR에서 CreateCondBr를 이용해 then/else 블록으로 분기하는 명령을 추가
3. then/else 코드 생성
각각의 블록에서 AST 하위 노드의 codegen을 호출하여 값을 생성합
4. PHI 노드 생성
두 블록의 결과 값을 PHI 노드로 결합하여 if/then/else 전체의 결과로 반환
해당 과정을 control flow graph로 시각화해보면
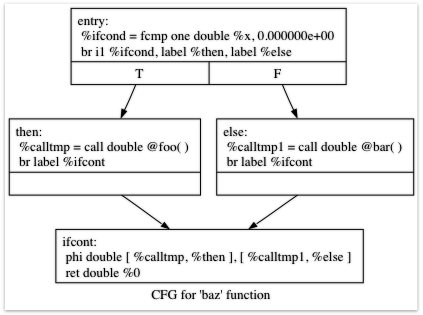
Phi 노드의 역할
• 두 분기(then/else)에서 각각 다른 값을 계산한 뒤, 마지막에 어떤 값을 반환할지 결정해야 하는데, 이때 사용하는 것이 SSA(Static Single Assignment)의 핵심 연산인 Phi 노드
Phi 노드란?
• Phi 노드는 여러 제어 흐름 경로가 합쳐질 때, “어떤 경로에서 왔는가”에 따라 값을 선택
• 예시:
• then 블록에서 온 경우: calltmp 값을 선택
• else 블록에서 온 경우: calltmp1 값을 선택
• IR 예시: %iftmp = phi double [ %calltmp, %then ], [ %calltmp1, %else ]
Code Generation Extension: if, then, else
해당 구문에 대한 코드를 생성하기 위하여, ifExprAST codegen 메서드를 구현하여 보자.
Value *CondV = Cond->codegen();
if (!CondV)
return nullptr;
// 0.0과 같지 않은지 비교하여 조건을 bool로 변환합니다.
CondV = Builder->CreateFCmpONE(
CondV, ConstantFP::get(*TheContext, APFloat(0.0)), "ifcond");
Function *TheFunction = Builder->GetInsertBlock()->getParent();
// then과 else 케이스를 위한 블록을 생성합니다. 'then' 블록은 함수 끝에 삽입합니다.
BasicBlock *ThenBB =
BasicBlock::Create(*TheContext, "then", TheFunction);
BasicBlock *ElseBB = BasicBlock::Create(*TheContext, "else");
BasicBlock *MergeBB = BasicBlock::Create(*TheContext, "ifcont");
Builder->CreateCondBr(CondV, ThenBB, ElseBB);빌드 중인 function 객체를 가져와서, 현재의 BasicBlock을 얻고 해당 블록의 parent(현재 포함된 함수) 를 요청하여 얻는다.
이후 세 개의 블록을 생성하여 then블록 생성자에 Thefunction을 전달한다 : 새 블록을 지정된 함수의 끝에 자동으로 삽입하게 만듦
// then 값 생성
Builder->SetInsertPoint(ThenBB);
Value *ThenV = Then->codegen();
if (!ThenV)
return nullptr;
Builder->CreateBr(MergeBB);
// 'Then'의 codegen이 현재 블록을 바꿀 수 있으므로, PHI를 위해 ThenBB를 업데이트
ThenBB = Builder->GetInsertBlock();조건 분기 명령어가 삽입된 후 빌더를 then 블록에 맞추어 코드를 삽입한다. 즉 지정된 블록의 끝에 삽입 위치를 이동시킨다.
처음에는 then 블록이 비어있으므로, 블록의 시작점부터 삽입된다.
삽입 위치가 정해지면 then 표현식을 재귀적으로 생성.
then 블록을 마무리하기 위해 merge 블록으로 무조건분기하는 명령.
IR의 특징 : 모든 기본 블록이 return이나 branch같은 제어 흐름 명령으로 무조건 종료되어야 한다,, 무든 흐름을 명시적으로 작성하여야 한다. 아닐 경우 verifier 오류를 발생시킨다.
ThenBB = Builder->GetInsertBlock();
merge블록에서 PHI 노드를 생성할 떄, PHI가 어떻게 동작할지 블록/값 쌍 설정.
// else 블록 생성
TheFunction->insert(TheFunction->end(), ElseBB);
Builder->SetInsertPoint(ElseBB);
Value *ElseV = Else->codegen();
if (!ElseV)
return nullptr;
Builder->CreateBr(MergeBB);
// 'Else'의 codegen이 현재 블록을 바꿀 수 있으므로, PHI를 위해 ElseBB를 업데이트
ElseBB = Builder->GetInsertBlock();
// merge 블록 생성
TheFunction->insert(TheFunction->end(), MergeBB);
Builder->SetInsertPoint(MergeBB);
PHINode *PN =
Builder->CreatePHI(Type::getDoubleTy(*TheContext), 2, "iftmp");
PN->addIncoming(ThenV, ThenBB);
PN->addIncoming(ElseV, ElseBB);
return PN;
else 블록의 코드 생성 또한 then 블록과 똑같다. 차이점으로 else 블록을 함수에 추가한다는 것
최종적으로 merge 코드를 마무리할 수 있다.
- merge 블록을 function 객체에 추가
- 삽입 위치를 merge 블록으로
- PHI노드 생성, 블록/값 설정
- Codegen 함수 : phi 노드 반환
for loop
extern putchard(char);
def printstar(n)
for i = 1, i < n, 1.0 in
putchard(42); # ascii 42 = '*'
# print 100 '*' characters
printstar(100);
if문보다 조금 더 강력한 제어 구조인 for 반복문에 대해서도 확장해보자. 위의 예시 코드처럼 * 100개를 출력하는 예제이다.
if문과 마찬가지의 시퀸스를 통하여 구조를 확장해보자.
Lexer Extension: for
먼저 enum Token에 새로운 값 추가, for과 in을 각기 고유한 토큰으로 처리할 수 있게끔 만든다.
이후, gettok 함수에서 식별자를 읽어들일 때 아래와 같이 새로운 키워드를 인식하도록 if문을 추가한다.
// control
tok_if = -6, tok_then = -7, tok_else = -8,
tok_for = -9, tok_in = -10
if (IdentifierStr == "def")
return tok_def;
if (IdentifierStr == "extern")
return tok_extern;
if (IdentifierStr == "if")
return tok_if;
if (IdentifierStr == "then")
return tok_then;
if (IdentifierStr == "else")
return tok_else;
if (IdentifierStr == "for")
return tok_for;
if (IdentifierStr == "in")
return tok_in;
return tok_identifier;AST Extension: for
/// ForExprAST - for/in 표현식을 위한 AST 클래스
class ForExprAST : public ExprAST {
std::string VarName; // 루프 변수 이름
std::unique_ptr<ExprAST> Start, End, Step, Body; // 각 부분 표현식
public:
ForExprAST(const std::string &VarName, std::unique_ptr<ExprAST> Start,
std::unique_ptr<ExprAST> End, std::unique_ptr<ExprAST> Step,
std::unique_ptr<ExprAST> Body)
: VarName(VarName), Start(std::move(Start)), End(std::move(End)),
Step(std::move(Step)), Body(std::move(Body)) {}
Value *codegen() override; // LLVM IR 코드 생성 함수
};
이후 for 루프를 표현하기 위해, AST를 위와 같이 정의할 수 있다.
루프 변수 이름과 for루프 각 부분의 표현식을 저장한다.
- VarName: for 루프에서 사용할 변수의 이름 (예:
for i = ...의i) - Start: 루프 변수의 시작 값 (초기화 표현식)
- End: 루프 종료 조건 표현식
- Step: 루프 변수의 증가(혹은 감소) 값 (스텝 표현식, 생략 가능)
- Body: 루프 본문(반복해서 실행할 표현식)
이렇게 각 부분이 다른 EXprAST로 저장되어, recursive한 구조도 표현할 수 있게 된다.
std::unique_ptr를 사용해 자동으로 메모리 관리를 할 수 있고, 위에서 보았든 codegen() 함수는 LLVM IR 코드로 변환할 때 호출된다.
Paser Extension: for
static std::unique_ptr<ExprAST> ParseForExpr() {
getNextToken(); // 'for' 토큰 소비
if (CurTok != tok_identifier)
return LogError("expected identifier after for");
std::string IdName = IdentifierStr;
getNextToken(); // 변수명 소비
if (CurTok != '=')
return LogError("expected '=' after for");
getNextToken(); // '=' 소비
auto Start = ParseExpression();
if (!Start)
return nullptr;
if (CurTok != ',')
return LogError("expected ',' after for start value");
getNextToken(); // ',' 소비
auto End = ParseExpression();
if (!End)
return nullptr;
// 스텝 값은 선택적(optional)
std::unique_ptr<ExprAST> Step;
if (CurTok == ',') {
getNextToken();
Step = ParseExpression();
if (!Step)
return nullptr;
}
if (CurTok != tok_in)
return LogError("expected 'in' after for");
getNextToken(); // 'in' 소비
auto Body = ParseExpression();
if (!Body)
return nullptr;
return std::make_unique<ForExprAST>(IdName, std::move(Start),
std::move(End), std::move(Step),
std::move(Body));
}
위의 예시처럼, for / 변수명/ =/ 시작값/ , / 종료조건을 parsing한다. 모든 정보가 모이면 For ExprAST노드를 생성하여 return하게 된다.
static std::unique_ptr<ExprAST> ParsePrimary() {
switch (CurTok) {
default:
return LogError("unknown token when expecting an expression");
case tok_identifier:
return ParseIdentifierExpr();
case tok_number:
return ParseNumberExpr();
case '(':
return ParseParenExpr();
case tok_if:
return ParseIfExpr();
case tok_for:
return ParseForExpr();
}
}for 토큰을 만나면, ParseForExpr()을 호출하여 for 루프 구문을 파싱한다. 이를 통하여 for 루프또한 하나의 expression으로 파싱될수 있다.
LLVM IR Extension: for
llvm 코드 예시를 보자.
declare double @putchard(double)
define double @printstar(double %n) {
entry:
; 초기값 = 1.0 (phi 노드에 직접 대입)
br label %loop
loop: ; preds = %loop, %entry
%i = phi double [ 1.000000e+00, %entry ], [ %nextvar, %loop ]
; 루프 본문
%calltmp = call double @putchard(double 4.200000e+01)
; 증가
%nextvar = fadd double %i, 1.000000e+00
; 종료 조건 검사
%cmptmp = fcmp ult double %i, %n
%booltmp = uitofp i1 %cmptmp to double
%loopcond = fcmp one double %booltmp, 0.000000e+00
br i1 %loopcond, label %loop, label %afterloop
afterloop: ; preds = %loop
; 루프는 항상 0.0을 반환
ret double 0.000000e+00
}- entry 블록
• 루프의 시작점.
• 바로loop블록으로 분기 (br label %loop). - loop 블록
• phi 노드로 루프 변수 i 초기화 및 갱신
•%i = phi double 1.0, %entry , %nextvar, %loop
• 첫 진입 시:%i = 1.0(초기값)
• 반복 시:%i = %nextvar(이전 반복에서 계산된 값)
• 루프 본문 실행
•@putchard(42)호출로 ‘*’ 출력
• 루프 변수 증가
•%nextvar = fadd double %i, 1.0
(i에 1.0을 더해 다음 반복값 생성)
• 종료 조건 검사
•%cmptmp = fcmp ult double %i, %n
(i < n비교, 결과는 i1 타입)
•%booltmp = uitofp i1%cmptmp to double
(불리언을 double로 변환)
•%loopcond = fcmp one double %booltmp, 0.0
(0.0과 다르면 참, 같으면 거짓)
• 분기
•br i1%loopcond, label %loop, label %afterloop
• 조건이 참이면 다시 loop 블록으로,
• 조건이 거짓이면 afterloop 블록으로 이동 - afterloop 블록
• 루프 종료 후 항상0.0을 반환
(ret double 0.0)
Code Generation Extension: for
1. 루프 시작값 코드 생성
Value *StartVal = Start->codegen();
if (!StartVal)
return nullptr;루프 변수의 시작값을 먼저 계산한다. 아직 변수 i가 스코프에 등록되지 않은 상태이다.
2. 루프 헤더 블록 생성
Function *TheFunction = Builder->GetInsertBlock()->getParent();
BasicBlock *PreheaderBB = Builder->GetInsertBlock();
BasicBlock *LoopBB = BasicBlock::Create(*TheContext, "loop", TheFunction);
Builder->CreateBr(LoopBB);현재 함수와 블록을 저장하고, 반복이 시작될 때, 루프 블록 BB를 생성한다. 그리고 현재 블록에서 LoopBB로 무조건분기하는 명령을 추가한다.
3. 루프 본문 코드 생성 준비
Builder->SetInsertPoint(LoopBB);
PHINode *Variable = Builder->CreatePHI(Type::getDoubleTy(*TheContext), 2, VarName);
Variable->addIncoming(StartVal, PreheaderBB);코드 생성 위치를 LoopBB로 이동 -> phi 노드를 생성하여 루프변수 i 값 관리.
첫 진입 시에는 시작값을 사용한다.
4. 변수 테이블 관리
Value *OldVal = NamedValues[VarName];
NamedValues[VarName] = Variable;루프변수를 심볼테이블에 등록, shadowing 지원
5. 루프 본문 코드 생성
if (!Body->codegen())
return nullptr;루프 본문을 재귀적으로 생성
6. step 값 계산
Value *StepVal = nullptr;
if (Step) {
StepVal = Step->codegen();
if (!StepVal)
return nullptr;
} else {
StepVal = ConstantFP::get(*TheContext, APFloat(1.0));
}
Value *NextVar = Builder->CreateFAdd(Variable, StepVal, "ne_텍스트_xtvar");
스텝 값이 없다면 1.0 사용, 현재 루프변수에 스텝을 더하여 다음 루프변수를 계산
7. 종료 조건 계산
Value *EndCond = End->codegen();
if (!EndCond)
return nullptr;
EndCond = Builder->CreateFCmpONE(
EndCond, ConstantFP::get(*TheContext, APFloat(0.0)), "loopcond");0.0과 비교하여 true 즉 0.0 (false)라면 다시 루프를 돎
8. 루프 종료 블록 생성 및 분기
BasicBlock *LoopEndBB = Builder->GetInsertBlock();
BasicBlock *AfterBB = BasicBlock::Create(*TheContext, "afterloop", TheFunction);
Builder->CreateCondBr(EndCond, LoopBB, AfterBB);
Builder->SetInsertPoint(AfterBB);루프가 끝나면 이동할 afterloop 블록 생성, 조건에 따라 루프를 반복할지 종료할지,,
이후 생성되는 코드는 afterloop 블록에 삽입된다.
9. phi 노드에 backedge 반복 값 추가
Variable->addIncoming(NextVar, LoopEndBB);phi 노드에 반복 경로에서 온 값을 추가, 새로운 i값을 업데이트(phi노드에 연결)
10. 변수 스코프 복구 및 반환
if (OldVal)
NamedValues[VarName] = OldVal;
else
NamedValues.erase(VarName);
return Constant::getNullValue(Type::getDoubleTy(*TheContext));
쉐도잉 기능을 지원하므로, 쉐도잉된 변수가 있으면 복원, 없으면 삭제한다. 항상 0.0을 반환.
시작값 계산 → phi 노드로 변수 관리 → 본문 코드 생성 → 스텝 계산 → 종료 조건 검사 → 분기 → phi 노드 갱신 순서로 진행
Kaleidoscope: Extending the Language: User-defined Operators
5장까지, 여러가지 조건분기와 함수를 구현할 수 있었다.
하지만 해당 언어에는 나눗셈, 논리부정, less-than을 제외하고는 연산자들이 거의 없다.
6장에서는 사용자 정의 연산자를 추가해보도록 하자.
Idea
# Logical unary not.
def unary!(v)
if v then
0
else
1;
# Define > with the same precedence as <.
def binary> 10 (LHS RHS)
RHS < LHS;
# Binary "logical or", (note that it does not "short circuit")
def binary| 5 (LHS RHS)
if LHS then
1
else if RHS then
1
else
0;
# Define = with slightly lower precedence than relationals.
def binary= 9 (LHS RHS)
!(LHS < RHS | LHS > RHS);사용자가 임의로 새로운 연산자를 만들고, 우선순위까지 지정할 수 있다.
왜??
- 표준 라이브러리의 상당 부분을 언어 자체로 구현할 수 있다.
- 파서의 강력함 체험,,실습
- Kaleidoscope의 parser는 재귀 하강 파싱과, 연산자 우선순위 파싱을 결합하여 사용한다. 따라서 런타임 중에도 문법을 동적으로 확장할 수 있다.
아래에서
사용자 정의 이항/단한 연산자를 직접 구현해보자.
User-defined Binary Operators
Lexer 확장
enum Token {
...
tok_binary = -11,
tok_unary = -12
};
if (IdentifierStr == "binary")
return tok_binary;
if (IdentifierStr == "unary")
return tok_unary;AST 구조의 일반화
기존의 AST에서는 이항 연산자를 아스키 코드를 표현한다. 따라서 새로운 연산자도 아스키 코드로 처리하자
별도의 확장 없이 binary@ 등을 함수 이름으로 사용할 수 있다.
PrototypeAST 확장
class PrototypeAST {
std::string Name;
std::vector<std::string> Args;
bool IsOperator;
unsigned Precedence; // 이항 연산자 우선순위
// 생성자 및 기타 메서드...
bool isUnaryOp() const { return IsOperator && Args.size() == 1; }
bool isBinaryOp() const { return IsOperator && Args.size() == 2; }
char getOperatorName() const { ... }
unsigned getBinaryPrecedence() const { ... }
};연산자 정의를 함수 프로토타입으로 표현할 수 있도록, 프로토타입AST에 연산자 정보와 우선순위 필드를 추가하면 위와 같다.
연산자 프로토타입 파싱
prototype ::= id '(' id* ')'
::= binary LETTER number? (id, id)def binary| 5 (LHS RHS) 와 같이 연산자 이름과 우선순위를 지정할 수 있다.
파서에서 연산자 이름(binary@ 등)과 우선순위를 PrototypeAST에 저장
코드 생성 로직
기존 이항 연산자 노드에 내장 연산자가 아니면 사용자 정의 연산자를 함수 호출로 처리한다.
Value *BinaryExprAST::codegen() {
Value *L = LHS->codegen();
Value *R = RHS->codegen();
if (!L || !R)
return nullptr;
switch (Op) {
// 내장 연산자 처리...
default:
break;
}
// 사용자 정의 연산자: "binary" + Op로 함수 이름을 만들어 호출
Function *F = getFunction(std::string("binary") + Op);
Value *Ops[2] = { L, R };
return Builder->CreateCall(F, Ops, "binop");
}이후 연산자 우선순위 등록하여, 파서가 새로운 연산자와 우선순위를 인삭하고 기존 연산자와 동일하게 처리할 수 있게끔 한다.
User-defined Unary Operators
하나의 피연산자만 가짐
AST Node 정의
/// UnaryExprAST - 단항 연산자를 위한 AST 클래스
class UnaryExprAST : public ExprAST {
char Opcode; // 연산자 문자 (예: '!')
std::unique_ptr<ExprAST> Operand; // 피연산자
public:
UnaryExprAST(char Opcode, std::unique_ptr<ExprAST> Operand)
: Opcode(Opcode), Operand(std::move(Operand)) {}
Value *codegen() override;
};파싱 로직 추가
/// unary
/// ::= primary
/// ::= '!' unary
static std::unique_ptr<ExprAST> ParseUnary() {
// 현재 토큰이 연산자가 아니면 primary로 처리
if (!isascii(CurTok) || CurTok == '(' || CurTok == ',')
return ParsePrimary();
// 단항 연산자라면, 연산자 기호를 저장하고 다음 토큰으로 이동
int Opc = CurTok;
getNextToken();
if (auto Operand = ParseUnary())
return std::make_unique<UnaryExprAST>(Opc, std::move(Operand));
return nullptr;
}연속된 단한 연산자도 재귀적으로 파싱이 가능함. 그리고 순방향으로 계산이 진행되므로, 우선순위 정보가 필요 없다.
Parser의 호출 구조 변경
// 이항 연산자 우변 파싱
auto RHS = ParseUnary();
// 최상위 표현식 파싱
auto LHS = ParseUnary();
return ParseBinOpRHS(0, std::move(LHS));
프로토타입 파싱 확장
함수나 연산자의 이름과 매개변수 등 형태와 interface만 미리 선언해놓은것
/// prototyp` /// ::= id '(' id* ')' /// ::= binary LETTER number? (id, id) /// ::= unary LETTER (id) static std::unique_ptr<PrototypeAST> ParsePrototype() { ... case tok_unary: getNextToken(); if (!isascii(CurTok)) return LogErrorP("Expected unary operator"); FnName = "unary"; FnName += (char)CurTok; Kind = 1; getNextToken(); break; ... }
함수 이름은 unary!으로 저장
### 코드 생성
```cpp
Value *UnaryExprAST::codegen() {
Value *OperandV = Operand->codegen();
if (!OperandV)
return nullptr;
Function *F = getFunction(std::string("unary") + Opcode);
if (!F)
return LogErrorV("Unknown unary operator");
return Builder->CreateCall(F, OperandV, "unop");
}피연산자에 대해 먼저 코드를 생성한 뒤, unary + 연산자 기호 로 해당 함수ㅡ 즉 연산자 정의를 찾을 수 있다.
Test
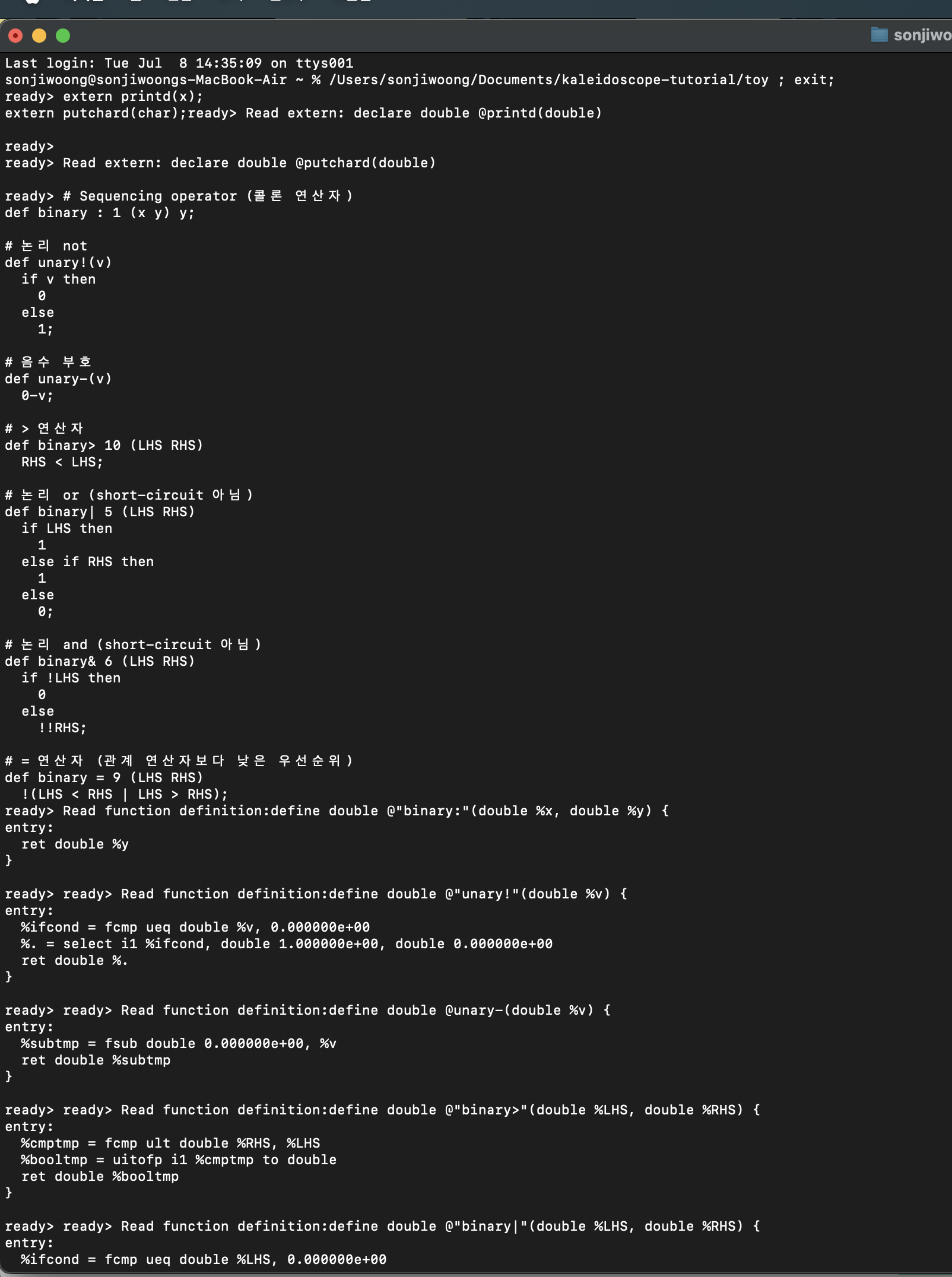
외부 함수 선언 및 연산자, 기본함수 정의
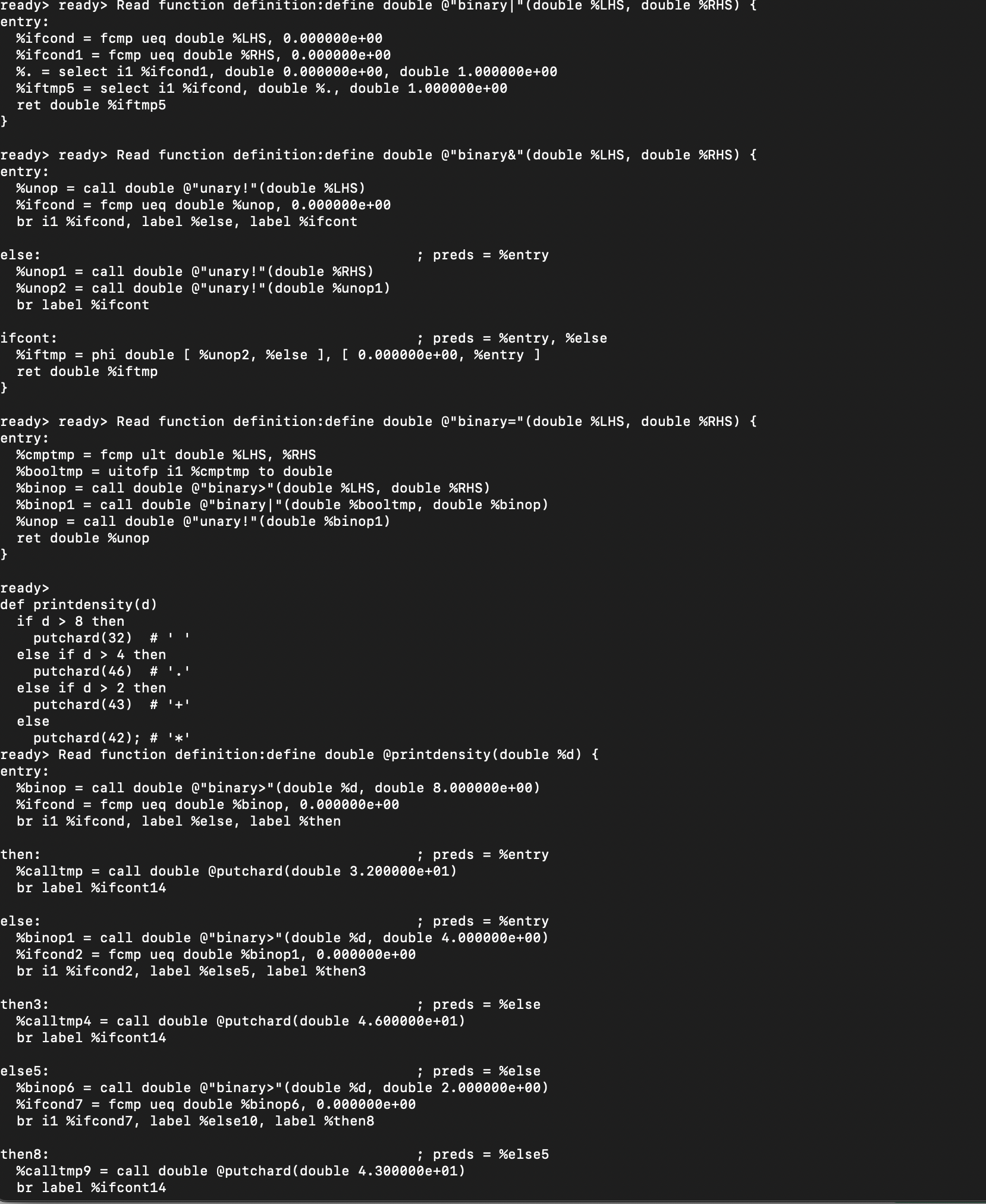
멀도에 따라 문자 출력 함수
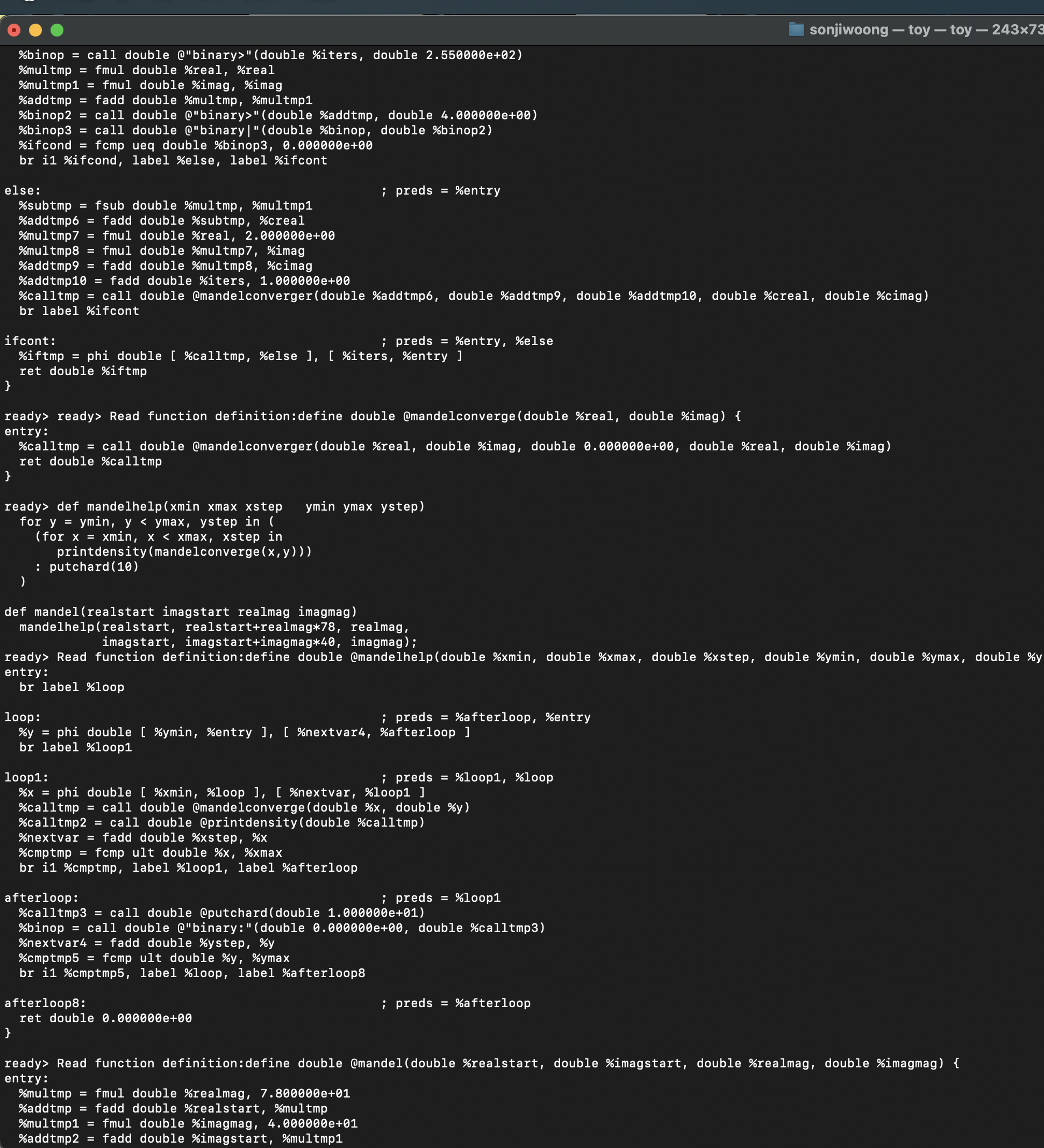
Mandelbrot 계산 함수, Mandelbrot 세트 그리기 함수
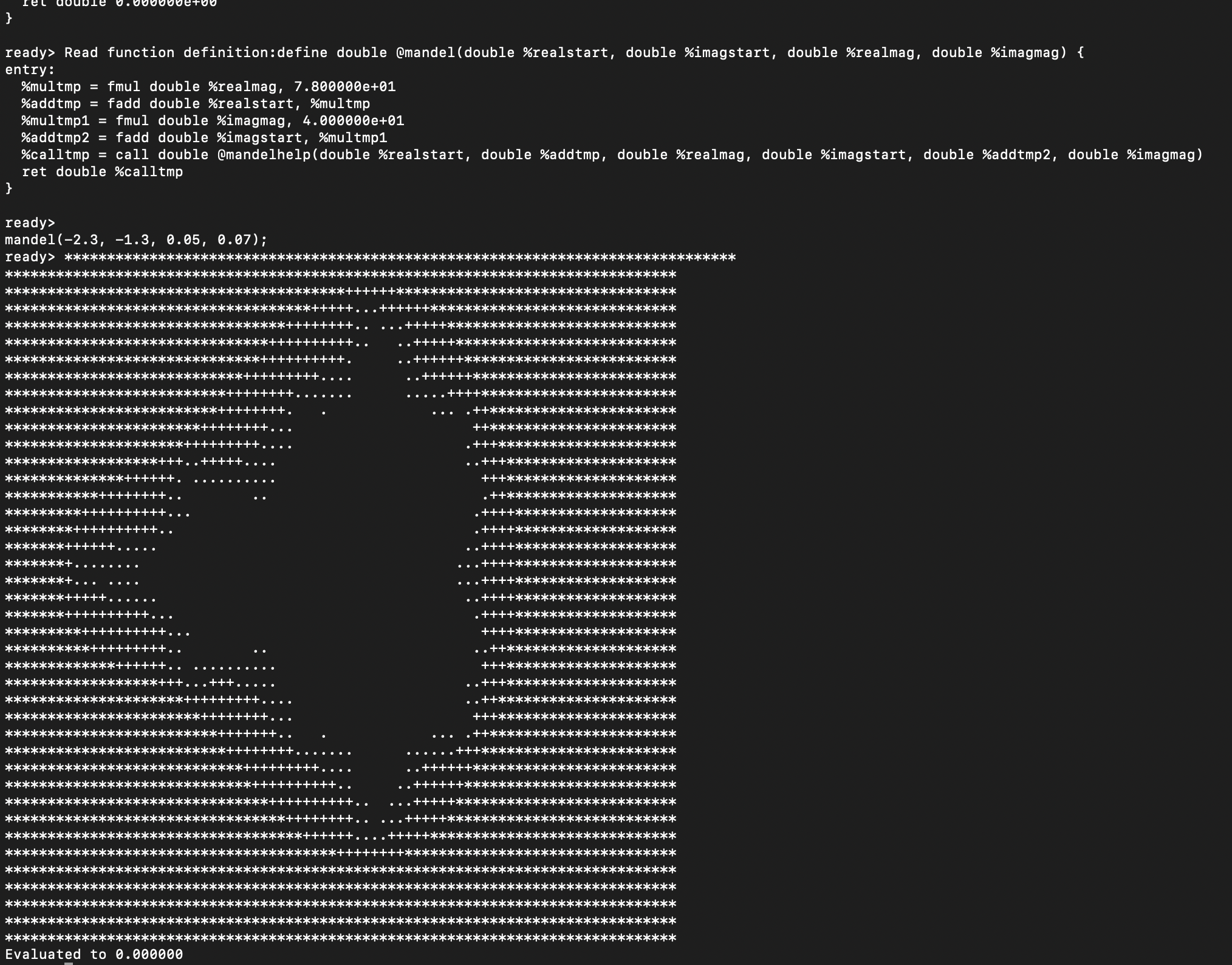
출력
