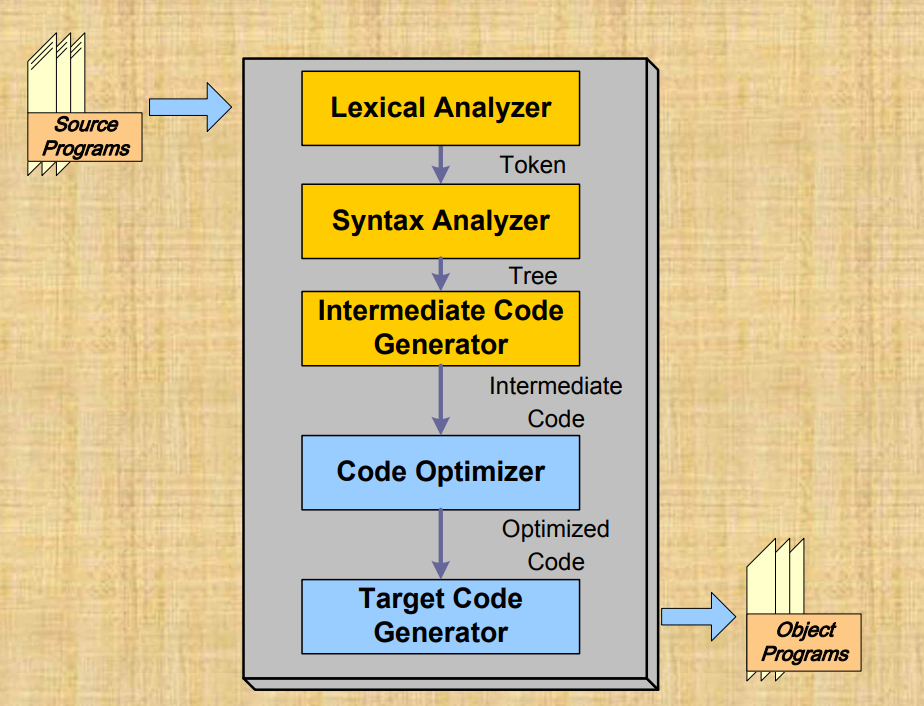
컴파일러의 Front-end와 back-end를 좀더 깊게 보자.
1. Lexical Analyzer

- 어휘 분석기
입력자료 (문자들)이 무슨 의미인지 파악해야 한다.
'+' 문자가 사칙연산의 더하기 를 실행함을 알아야한다.
문자를 읽어서 숫자, 사칙연산 등의 의미를 가짐을 저장.
즉, 입력 단위에서 의미 단위로 분석해야 한다.
그렇게 분석된 의미단위를 Token으로 처리하게 되고 각 token을 token number로 바꿔어서 컴퓨터가 처리하기 쉽게 바꾼다. 이때 Token number 만으로는 존재할수있는 모든 token 을 처리하기 힘들다. 왜냐하면 숫자token도 그 각각을 token number로 mapping 하려고 하면 무한개의 token number 정보가 필요하다.
따라서 token number와 token value를 같이 가져간다.
input : src
ouput : Token (의미단위로 분석됨)
2. Syntax Analyzer
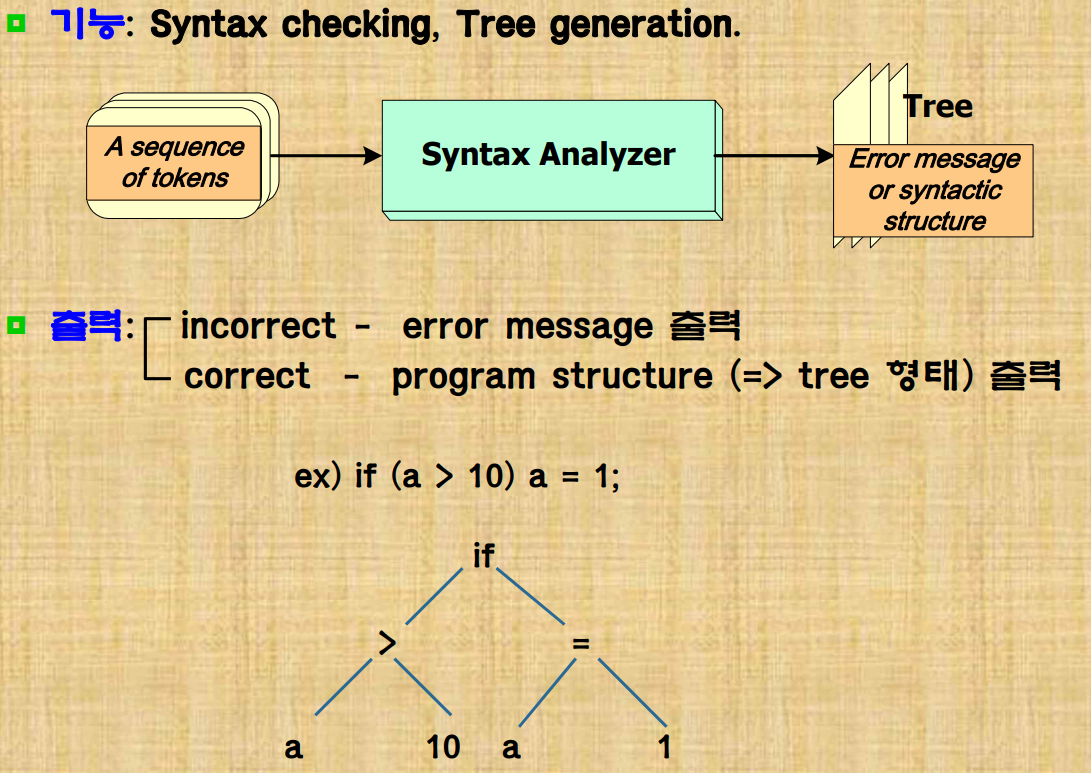
- 문법 분석기
그렇게 들어온 token 정보를 문법에 맞게 parseTree 형태로 만든다. 어떻게 표현하느냐에 따라 구현방식이 달라지기에 정확한 규격을 표현하여 트리형태로 구현한다. 문법체계가 필요하다.
syntax checking, Tree generation 을 통해 syntactic structure를 만들어 낸다.
예를 들어 if (condition) state 같은 token들이 들어오면 if token 을 기준으로 condition token 과 state token이 자식노드로 들어가는 파스트리가 만들어진다.
3. Intermediate Code Generator
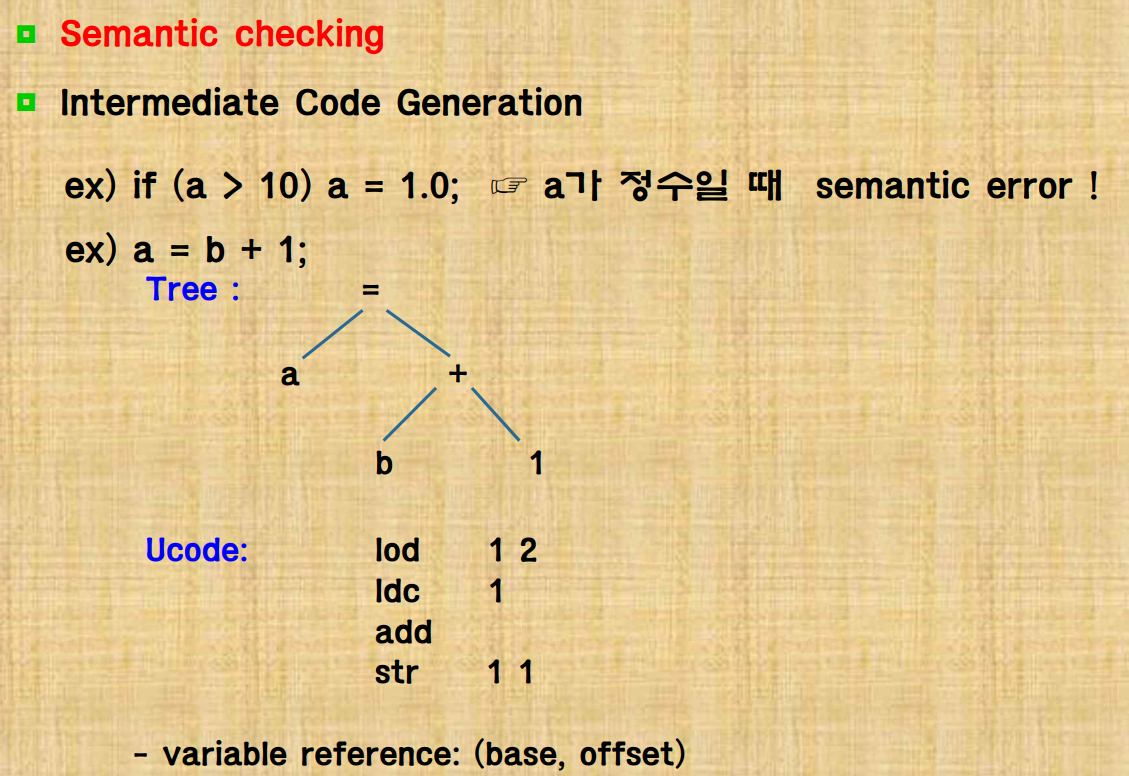
-
의미분석기
front-end 를 구분짓는 중간코드를 만드는데 이때 sementic 체크를 한다. 대표적은 type 변환등을 확인한다. 변수, 함수이름, constant 같은 identifier 정보가 symbol table에 적혀 의미를 분석해낼수있다.
operation이 실행될때 그 결과로 stack machine에 정보가 남는다. 첫 node부터 traverse하면서 stack형태로 돌아다닌다.4.Code optimizer

-
코드 최적화
컴파일러는 최대한 빨리 실행해줘야한다. 그래서 코드를 한번 정리를 해줘야 하는데 특히 register에 데이터를 저장하는 부분에서 많은 최적화가 이루어지면 시간이 단축된다. 그중에서 메모리 접근을 최소화하는것이 시간이 절약된다.

그래서 반복되는 부분을 지우고 안쓰는 변수도 지우고 등의 방법을 쓰는데 local과 global하게 optimization을 할수있다.
local
- constant folding : 코드내에 상수로 바로 계산되면 실행시간 이전에 미리 계산해놓는다.
- eliminating redundant load, store instructions : 시간이 가장 오래 걸리는 load, store 명령어를 최소화 시킨다.
- algebraic simplification : 곱셉 보다는 덧셈이 간단하기 때문에 그런 연산 부분들을 최적화 시킨다.
- strength reduction : 중복된 코드를 제거하며 코드 수를 줄인다.
global
loop 부분에서 영향을 주지 않는 부분은 밖으로 꺼낸다.5. Target Code Generator
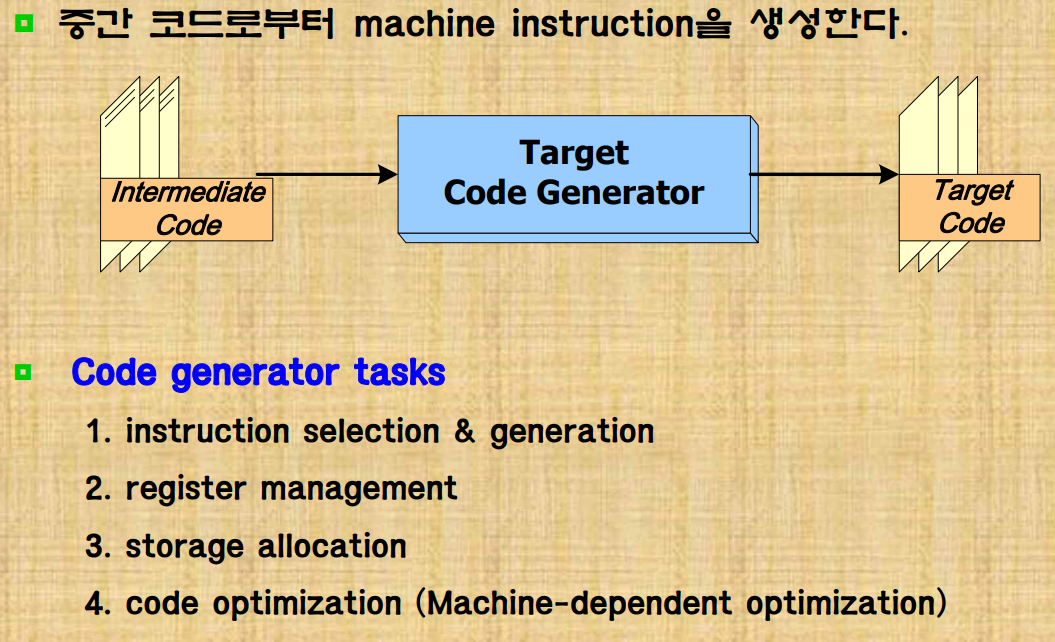
- 타켓 코드 생성
target machine에 영향을 받는다.
특히 한정된 register의 활용이 굉장히 중요하다. 또한 동적 메모리 관리를 하는 코드도 신경써야한다.
6. Error Recovery

마지막으로 에러를 처리하는 부분도 있다.
- error recovery : error가 다른 문장에 영향을 미치지 않게 그 파장범위를 최소화하여 에러가 난 부분만 잘 처리한다. 뒤에도 코드가 많기에 해당 문장을 패스하던지의 처리를 한다.
- error repair : 에러난 부분 자체를 아예 수정을 해버린다.
컴파일러 자동화 도구

unix : Lex, yacc // gcc: flex, bison
Lex
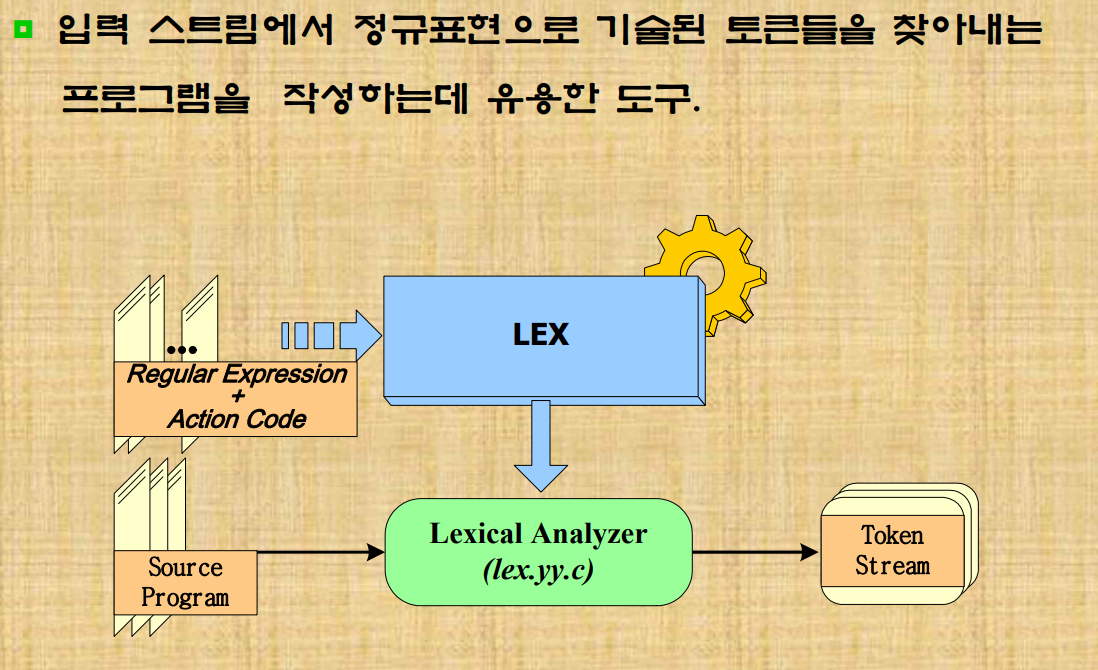
어휘분석기를 쉽게 작성할 수 있게 도와준다. unix에서 lex 명령어가 삽입되어있다.
어휘정의는 정규표현으로 정의한다.
Parser Generator(PGS)
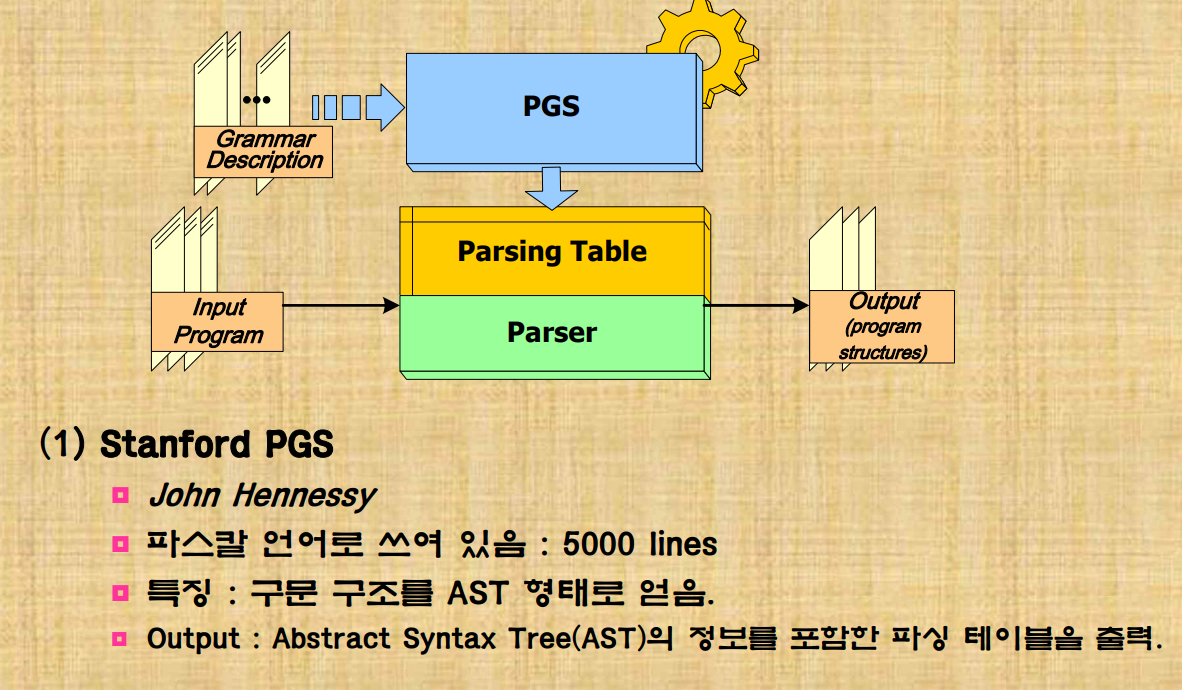
src의 언어를 알려주면 parsing table을 drive하면서 처리해준다.
YACC
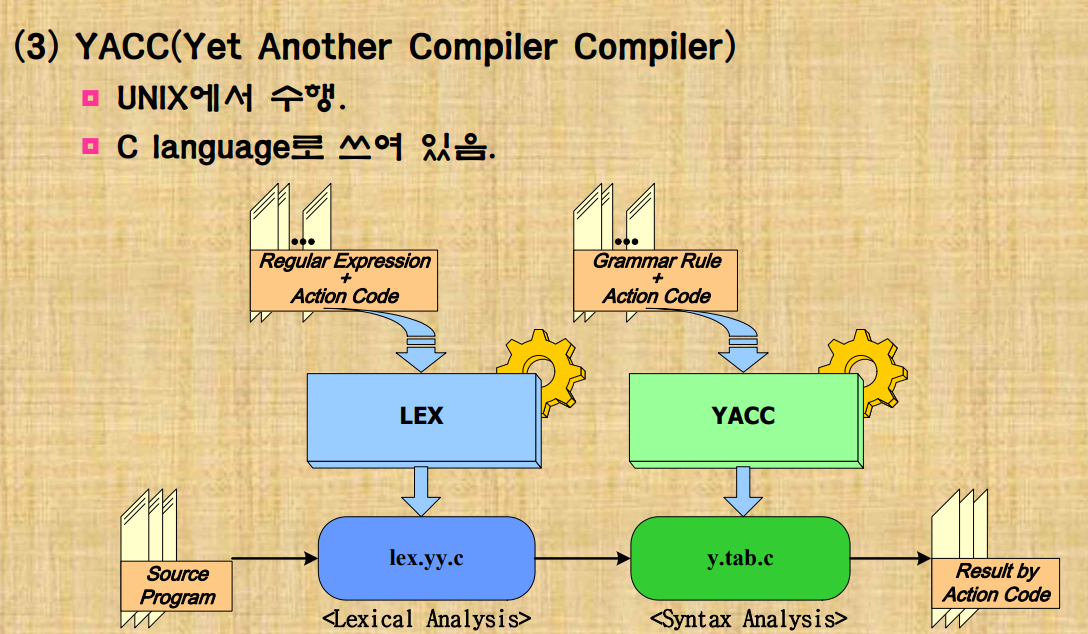
lex 부분과 yacc이 따로 순서대로 처리되기 보다는 구문분석기에 포함되어 어휘가 필요할때마다 구문분석기가 lex를 호출하는 식으로 동작한다.
