
시작하며
이 글은 JVM을 간단히 살펴보고,
자바 프로그램이 JVM에서 실행되는 과정을 통해 JVM의 전체적인 이해를 돕기 위한 글입니다.
JVM은 왜 나왔을까?
1990년대 초 TV, 팩스 머신, PDA 등 수많은 기기들이 네트워크로 연결되기 시작했습니다.
새롭게 변화되는 횐경에서 기존 언어들의 '이식성'과 '보안'이라는 문제가 부각되었습니다.
이식성
자바 이전의 유행하던 언어들은 대부분 하드웨어와 OS에 종속적이었습니다. 쉽게 말해서 인텔(x86)과 윈도우 운영체제에서 컴파일된 프로그램은 Arm과 리눅스로 구성된 컴퓨터에서 실행되지 않습니다. 왜냐하면 인텔(x86)과 Arm이 서로 다른 명령어 집합을 가졌을 뿐만 아니라 윈도우와 리눅스도 각 OS에 특화된 라이브러리가 있어서 이러한 라이브러리를 사용한 코드는 다른 OS에서 지원하는 라이브러리에 맞게 바꾸어주어야 하기 때문입니다.
즉 ‘이식성’이란 어떠한 프로그램을 만들었을 때 하드웨어와 OS에 상관없이 어떠한 플랫폼에서도 잘 동작하는가?에 관련된 문제라고 할 수 있겠습니다.
보안
네트워크로 연결되지 않은 기기는 그 기기의 프로그램을 설치하려면 직접 기기에 설치하는 수밖에 없습니다.
이 과정에서는 바이러스나 악의적인 프로그램이 끼여들 여지가 적죠.
하지만 네트워크에는 수많은 위험이 존재합니다. 프로그램을 쉽게 다운받을 수 있는 만큼 악의적인 프로그램도 쉽게 침입할 수 있습니다. 이러한 프로그램은 중요한 정보를 훔치거나 삭제시킬 수 있기 때문에 어떠한 프로그램이 네트워크를 통해 다운받아지면 매우 신중하게 안전성에 대한 체크가 필요했습니다.
이러한 상황에서 제임스 고슬링은 자바라는 언어를 만들었고, JVM은 위와 같은 문제를 해결하는데 중추적인 역할을 하게 되었습니다.
JVM이란?
JVM(Java Virtual Machine)은 자바 바이트코드를 실행할 수 있는 가상의 컴퓨터입니다.
JVM은 일반적인 CPU처럼 자신만의 명령어 집합을 가지고 있습니다. 자바 프로그램은 이 명령어 집합에 맞게 컴파일이 되고, 이렇게 JVM의 명령어 집합에 맞게 컴파일된 코드를 자바 바이트코드라고 부릅니다. JVM은 바이트코드를 해석하여 현재 CPU에 맞는 머신 코드로 변환시키고 이 머신 코드는 실제 CPU에 의해서 실행이 됩니다.
JVM의 이러한 특성이 자바를 ‘이식성’이 강한 언어로 만들어 줍니다.
“하나의 자바 프로그램을 실행하는 것”이 JVM의 가장 중요한 역할입니다. 자바 프로그램이 실행하면 JVM도 실행되며 자바 프로그램이 종료되면 JVM도 종료됩니다. 만약 3개의 자바 프로그램을 동시에 실행하면 3개의 JVM 프로세스가 생성되어 각각의 JVM 안에서 동작할 것입니다.
JVM 구조
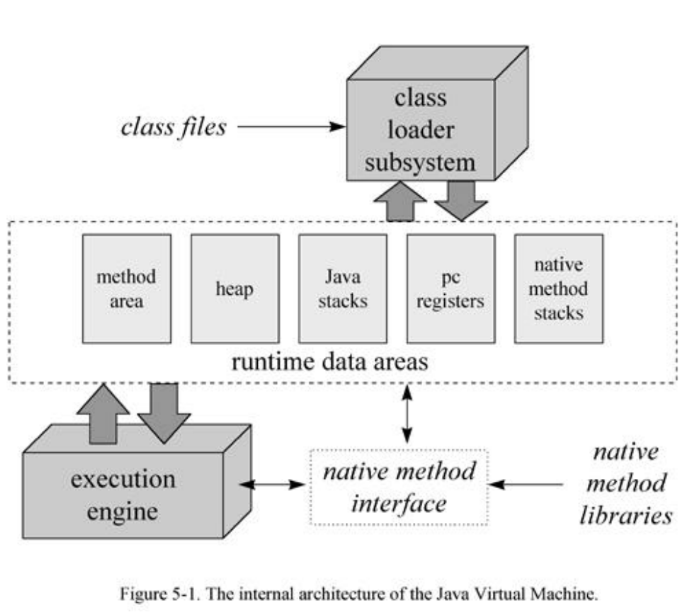
ClassLoader Subsystem
ClassLoder란?
ClassLoader는 Class가 JVM에 의해 실행될 수 있도록 준비시켜주는 놈이라고 할 수 있습니다.
ClassLoading 과정
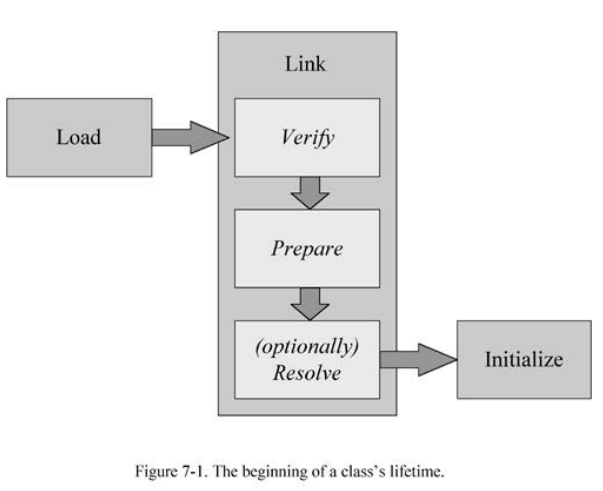
ClassLoader는 다음의 3가지 과정을 통해 Class를 준비시킵니다.
-
Loading
ClassLoader는 Class를 찾고 Stream을 열어 바이트코드를 JVM 안으로 들여옵니다.
이후 method area에 클래스 정보들을 저장합니다.
최종 결과로 이 클래스에 대한 정보를 얻을 수 있는 객체인 java.lang.Class의 인스턴스를 힙 영역에 생성합니다. -
Linking
2-1 Verification
클래스 파일이 구조적으로 잘 구성되었는지, 허용되지 않은 작업을 하려고하는 것은 아닌지에 대해서 파악합니다.
2-2 Preparation
정적 변수들을 타입에 맞는 기본값으로 초기화합니다. 예를 들어 int라면 0으로 초기화합니다.
2-3 Resoulution
Runtime Constant Pool에 존재하는 Symbolic Reference들을 실제 주소로 변환해주는 작업을 진행합니다.
이 과정은 Preparation 과정 후 바로 진행될 수도(static resolution) 혹은 나중에 클래스가 처음 사용되는 순간에 진행될수도(lazy resolution) 있습니다. -
Initialization
Preparation 과정에서 default값이 할당되어 있던 static 변수들을 초기화하고 static 초기화 블록 등을 실행합니다.
Initialization는 클래스가 처음 사용되어질 때 이루어집니다. Initialization되는 클래스가 부모 클래스를 갖고 있다면 부모 클래스가 먼저 초기화됩니다.
Runtime Data Areas
Runtime Data Areas는 자바 프로그램이 실행되는 동안 여러가지 데이터들이 저장되는 영역입니다.
Method Area
각 클래스 별로 존재하는 영역으로 로딩된 클래스에 대한 정보와 전역 변수가 이 method area에 저장됩니다.
클래스에 대한 정보로는 다음과 같은 것들이 있습니다.
-
Constant Pool
Constant Pool은 클래스에서 사용되는 상수들과 symbolic reference들을 포함하는 집합입니다. symbolic reference는 클래스에서 사용하는 field나 method, class, interface 등을 지칭하기 위해 임시적으로 사용되는 이름과 같은 기호를 의미합니다. 이 기호들은 ClassLoader의 Resolution 과정에서 실제 위치하는 주소 값으로 바뀌게 됩니다. -
Field Information
Field의 이름, 타입, 제어자가 저장됩니다. -
Method Information
Method의 바이트 코드와 Method의 이름, 리턴 타입, 파라미터의 숫자와 타입, 제어자를 저장합니다. -
Static variables, ClassLoader, Class
정적 변수, 이 클래스를 로딩한 ClassLoader 객체에 대한 참조, ClassLoader의 Loading 과정에서 생성된 java.lang.Class 객체에 대한 참조가 저장됩니다.
Heap
클래스의 인스턴스나 배열이 생성될 때 이 오브젝트들은 힙 영역에 저장됩니다.
더 이상 어떠한 객체도 참조하지 않는 객체를 가비지라고 부르는데 가비지 컬렉터라는 놈이 힙 영역에 있는 가비지를 제거해 줍니다.
개발자는 이 가비지 컬렉터로 인해 직접적으로 메모리 주소를 다룰 일이 없습니다. 이로 인해 메모리 주소를 잘못만져서 접근해서는 안되는 메모리 영역에 접근하는 memory corruption과 같은 문제도 사라졌습니다. 이 부분은 JVM이 제공해주는 여러 '보안' 기능 중 하나라고도 할 수 있습니다.
참고로 이 힙은 자료구조에서 배우는 힙과는 상관이 없습니다.
Java stacks
쓰레드마다 하나씩 존재하며 쓰레드가 생성될 때 생성됩니다. 쓰레드가 여는 중괄호('{')를 만날 때마다 Stack에 하나의 프레임이 생성됩니다. 그 프레임 안에서 다른 메소드 호출시 이 프레임 위에 또 하나의 프레임이 쌓이고, if문과 같은 블록이 실행되면 프레임 안에 중첩해서 프레임이 생깁니다. 쓰레드가 닫는 중괄호('}')를 만난다면 스택에서 스택 프레임이 제거됩니다.
스택 프레임은 다음과 같이 구성되어 있습니다.
-
Local Variable Array
말 그대로 지역 변수가 저장되는 배열입니다.
호출된 메소드에서 사용하는 지역변수들이 저장됩니다.
인스턴스 메소드의 경우 인스턴스 자신을 가르키는 this가 변수에 포함되는데, 이 this는 지역 변수 배열의 가장 첫번째 인자로 등록됩니다. -
Operand Stack
JVM은 스택 기반 머신입니다.
스택 기반 머신은 스택에 피연산자들을 push하고 pop해가며 연산을 수행합니다.
Operand Stack은 이 피연산자가 저장되는 스택입니다.
참고로 Java stack과 스택 프레임 안에 Operand stack은 자료구조에서 배우는 그 스택 구조가 맞습니다.
PC registers
쓰레드가 메소드를 실행할 때 PC(Program Counter) register는 현재 명령어의 주소를 담고 있습니다.
스택과 마찬가지로 쓰레드마다 하나씩 존재하며 쓰레드가 생성될 때 생성됩니다.
Native Method Stacks
네이티브 메소드란 자바가 아닌 다른 언어로 쓰여진 메소드를 말합니다.
Native Method Stack이란 Native Method를 호출하는 코드를 수행하기 위한 스택입니다.
Execution Engine
Interpreter
Interpreter는 PC register에 위치한 명령어를 해석하여 CPU 머신 코드로 변환합니다.
해석하는 과정에는 시간이 많이 듭니다.
이러한 문제를 해결하기 위해 JIT(Just In Compiler)가 등장했습니다.
JIT
JIT는 실행 시에 작동하는 컴파일러를 의미합니다.
JIT는 JVM이 바이트코드에서 자주 실행되는 HOT한 영역을 찾아서 미리 머신 코드로 변환한 후 code cache에 보관해놨다가 해석할 필요 없이 필요할 때 바로 사용할 수 있게 해주는 기능입니다.
예를 들어 반복문 안에 코드는 여러 번 반복됩니다. JIT는 이 코드를 미리 컴파일하여 저장해둡니다.
자바 프로그램의 실행 과정
이제 하나의 자바 프로그램이 실행되기까지 어떠한 과정을 거치는지 알아보도록 하겠습니다.
예제 코드
class Lava{
private int speed = 5;
}
public class Volcano{
public static void main(String[] args){
Lava lava = new Lava();
}
}프로그램 실행 과정
-
Volcano 어플리케이션을 실행시키기 위해서 ClassLoader는 Volcano.class 파일을 찾은 후 Volcano 클래스에 대한 정보를 method area에 위치시킵니다.
-
PC register는 Volcano 클래스의 method area에 존재하는 main method의 바이트 코드가 저장되어 있는 주소를 저장합니다.
-
JVM의 Interpreter는 PC register가 가리키는 maint method의 첫 instruction인 Lava lava = new Lava();를 해석하여 CPU에게 전달하고 CPU는 이를 실행합니다.
3-1. JVM은 Volcano의 constant pool에서 Lava class에 대한 symbolic reference인 "Lava"를 찾고 이 symbolic reference를 이용해 Lava 클래스의 정보가 method area에 로딩되어 있는지 확인합니다.
3-2. JVM이 "Lava"라는 이름의 클래스가 아직 로딩되어 있지 않은 것을 발견하면 Lava.class 파일을 로딩하고 method area에 Lava class에 대한 정보를 저장합니다.
3-3. JVM은 Volcano의 constant pool에 있는 "Lava"라는 symbolic reference를 실제 Lava class의 데이터들이 저장되어 있는 method area를 가르키는 포인터(주소)로 교체합니다. 이러한 과정을 constant pool resolution이라고 부르기도 하며 늦게 resolution이 이루어졌다고 하여 lazy resolution이라고도 합니다.
3-4. 모든 준비가 완료되었고 JVM은 Lava의 인스턴스를 위한 메모리를 힙에 할당합니다.
참고 자료
Bill Evans, Inside the Java Virtual Machine, McGraw-Hill Education, chapter(1,5,7), 2000
https://docs.oracle.com/javase/specs/jvms/se18/html/index.html
이상민, 자바 성능 튜닝 이야기, 초판 4쇄, 인사이트, 314p, 2019
김종민, 스프링 입문을 위한 자바 객체지향의 원리와 이해, 초판 4쇄, 위키북스, 45p,2020
