
들어가며
안녕하세요 ! 저는 현재 스프링과 MySQL을 사용하고 있는 마켓 골라라는 이커머스 프로젝트를 진행하고 있습니다.
이 글은 제가 프로젝트를 진행하다 만난 문제를 해결해나가는 과정을 기록한 글입니다. 최대한 자세히 풀어 설명할테니 편안하게 읽어주세요 ~!
발생한 문제
저희 프로젝트에는 주문하기 기능이 있습니다. 만약 여러 사용자가 동시에 같은 상품에 대해 주문할 경우 동시에 같은 수량의 재고를 읽어 -1 한 후 같은 값을 업데이트하는 과정에서 재고가 정확히 차감이 안되는 문제가 있을 수 있습니다.
이 문제를 해결하는 방법에는 여러가지 방법이 있지만 저는 낙관적 락을 이용하였고, 동시성 문제를 테스트하기 위해서 쓰레드 100개를 생성해 주문하기 로직을 호출하였습니다.
그런데 테스트용 H2 Embedded DB의 MySQL Mode에서는 정상적으로 테스트가 성공하였으나 실제 MySQL DB를 연결해서 테스트 할 때는 테스트가 끝나지 않고 무한 루프에 빠져 버리는 문제가 있었습니다… !
문제가 발생한 코드
OrderService.java
@Transactional
public long createOrder(long userId, CreateOrderRequestDto request) {
Order order = request.toOrder(userId);
List<OrderProduct> orderProducts = request.toOrderProducts();
stockSubtractionStrategy.subtractStock(orderProducts); // 주입 받은 재고 감소 전략으로 재고 감소시키기
... 주문 insert하기
... 주문 상품 insert하기
}OptimisticStockSubtractionStrategy.java
@Override
public void subtractStock(List<OrderProduct> orderProducts) {
for (OrderProduct orderProduct : orderProducts) { // 모든 주문 상품에 대해 재고 감소
subtractStockUntilSuccess(orderProduct.getProduct().getId(), orderProduct.getCount());
}
}
private void subtractStockUntilSuccess(long productId, int count) {
int updatedCount = 0;
while (updatedCount == 0) {
Product findProduct = productMapper.findById(productId)
.orElseThrow(NoSuchProductException::new);
checkStock(count, findProduct); // 재고가 남아 있는지 체크
findProduct.subtractStock(count); // 재고 감소
updatedCount = productMapper.updateStockOptimistic(findProduct); // 재고 감소 업데이트
waitIfFailed(updatedCount); // 재고 감소에 실패할 경우 50ms 기다리기
}
}
private void checkStock(int count, Product findProduct) {
…
}
private void waitIfFailed(int updatedCount) {
…
}
OrderServiceTest.java
@DisplayName("동시에 주문을 하더라도 주문 수량과 차감된 재고가 정확히 일치한다.")
@Test
void createOrder_concurrent_order_ok() throws InterruptedException {
//given
... 재고 100개를 갖는 테스트용 상품 insert하기
CreateOrderRequestDto orderRequest = … //주문 요청 생성
//then
List<Thread> threads = new ArrayList<>();
for (int i = 0; i < 100; i++) {
Thread thread = new Thread(() -> orderService.createOrder(user.getId(), orderRequest)); // 주문을 생성하는 코드를 실행하는 쓰레드 100개 생성
threads.add(thread);
thread.start(); //쓰레드 시작
}
for (Thread thread : threads) {
thread.join(); // 쓰레드 100개가 끝날 때까지 기다리기
}
int stock = productRepository.findById(product.getId()).get().getStock();
assertThat(stock).isZero();
}원인 파악
먼저 각 쓰레드들이 찍어내는 로그를 자세히 살펴 보았는데, 특이한 점을 발견할 수 있었습니다.
그것은 모든 쓰레드가 무한히 SELECT를 통해 상품의 재고를 읽어올 때마다 99개의 재고가 찍혀있다는 것입니다. 왜 100개도 아니고 98개도 아니고 99개일까.. 어쨌뜬 1개의 주문은 성공했다는 의미인데.. 음.. 이런 생각을 거듭하다 문득 DB 공부할 때 배웠던 Isolation Level에 REPEATABLE READ가 떠올랐습니다.
'REPEATABLE READ Isolation Level에서는 하나의 트랜잭션 안에서 진행되는 SELECT 쿼리는 몇 번을 실행해도 처음 읽었던 값을 그대로 읽게 된다'
...
'그리고 MySQL에서는 REPEATABLE READ가 기본 Isolation Level이다'
...
'주문하기 메소드에서 재고감소 로직은 같은 트랜잭션 안에 포함되어 있고, 업데이트 실패 후 재시도를 하는 로직 또한 마찬가지이다'
...
여기까지 생각이 닿자 Isolation Level로 인한 문제가 맞다는 확신이 들기 시작했고, 실제 MySQL DB의 Isolation Level을 READ COMMITTED로 바꿔 본후 테스트를 다시 진행하였습니다.
결과는 성공 ..!
상황 정리
문제의 원인을 정확히 파악해냈다는 생각에 기분이 매우 좋아졌습니다. 들뜬 마음을 뒤로 하고 상황을 정리해보았습니다. MySQL의 Isolation Level이 REPEATABLE READ일 때는 테스트 과정에서 정확히 무슨 일이 일어났길래 무한 루프에 빠지게 된 것일까요?
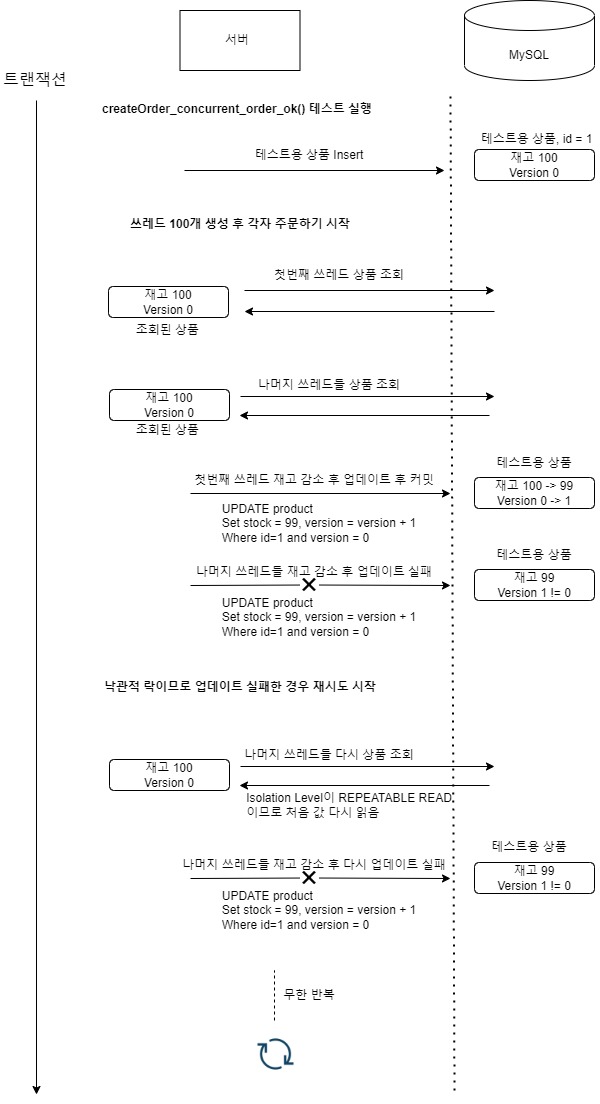
요약하자면, 다른 스레드가 업데이트한 값을 읽어야 재시도가 실패하지 않는데, 처음 읽은 값을 계속 읽게 되기 때문에 처음 업데이트에 성공한 쓰레드를 제외하면 다른 모든 쓰레드는 무한히 처음 읽었던 값을 읽게 되고 version이 달라 업데이트에 실패하게 되는 것입니다.
왜 테스트용 DB에서는 정상 작동할까?
테스트 DB로 H2 Embedded DB를 MySQL Mode를 사용하고 있습니다. 왠지 H2 DB의 Isolation Level은 MySQL MODE에서도 READ COMMITTED가 기본으로 설정되어 있을 것 같아 공식 문서를 찾아보았습니다. 하지만 그에 관한 내용은 나와 있지 않았고, 직접 실험을 해본 결과 예상대로 READ COMMITTED가 기본 Isolation Level로 사용되고 있었습니다.
실험 코드
@SpringBootTest
public class IsolationLevelTest {
@Autowired
DataSource dataSource;
@Test
public void is_isolation_level_read_committed() throws SQLException {
Connection connection = dataSource.getConnection();
int isolationLevel = connection.getTransactionIsolation();
assertThat(isolationLevel).isEqualTo(Connection.TRANSACTION_READ_COMMITTED);
}
}application.yml
spring:
datasource:
url: jdbc:h2:mem:testdb;DB_CLOSE_DELAY=-1;MODE=MYSQL;
driverClassName: org.h2.Driver
username: sa
password: ''해결 방법
만약 단순 재고만 감소하는 메소드였다면 메소드에 @Transactional을 떼주는 것만으로 간단히 해결 가능합니다. 재고를 읽는 트랜잭션과 재고를 업데이트하는 트랜잭션이 분리되고, 재시도하는 과정에서 재고를 읽는 작업은 항상 새로운 트랜잭션 안에서 읽기 때문이죠.
하지만 저의 경우 재고를 감소하고, 주문을 주문 테이블에 집어 넣고, 주문 상품을 주문 상품 테이블에 집어넣고.. 등등에 과정이 하나의 트랜잭션에서 이루어져야 하기 때문에 위와 같은 방법으로 해결할 수가 없었고, 다음과 같은 2가지 방식을 추가적으로 떠올렸습니다.
Isolation Level 변경
첫번째 방법은 말 그대로 Isolation Level을 변경하는 방법입니다. Spring에서는 원하는 메소드에 @Transactional 어노테이션을 붙여주는 것만으로 트랜잭션을 열 수 있으며 @Transactional(isolation = Isolation.READ_COMMITTED)로 바꾸면 해당하는 트랜잭션의 Isolation Level을 손쉽게 변경할 수가 있습니다.
트랜잭션 분리
두번째 방법은 트랜잭션을 분리하는 방법입니다. 상품을 읽는 로직만 따로 분리한 후 트랜잭션 전파 레벨을 조절하여 새로운 트랜잭션을 생성하고 읽기 작업이 끝나면 먼저 Commit을 해버리는 방법입니다. 상품을 읽는 로직은 계속 새로운 트랜잭션에서 진행되므로 업데이트된 재고와 버전을 읽게 되고 무한 루프에 빠지지 않습니다.
상품 SELECT 로직 분리 전
private void subtractStockUntilSuccess(long productId, int count) {
int updatedCount = 0;
while (updatedCount == 0) {
Product findProduct = productMapper.findById(productId) // ----- 변경할 부분
.orElseThrow(NoSuchProductException::new);
checkStock(count, findProduct);
findProduct.subtractStock(count);
updatedCount = productMapper.updateStockOptimistic(findProduct);
waitIfFailed(updatedCount);
}
}
상품 SELECT 로직 분리 후
private void subtractStockUntilSuccess(long productId, int count) {
int updatedCount = 0;
while (updatedCount == 0) {
Product findProduct = findById(productId); // ------ 변경된 부분
checkStock(count, findProduct);
findProduct.subtractStock(count);
updatedCount = productMapper.updateStockOptimistic(findProduct);
waitIfFailed(updatedCount);
}
}
@Transactional(propagation = Propagation.REQUIRES_NEW)
public Product findById(long productId) {
return productMapper.findById(productId)
.orElseThrow(NoSuchProductException::new);
}트랜잭션 전파 레벨 - REQUIRES_NEW
트랜잭션 전파 레벨을 REQUIRES_NEW로 설정할 경우 부모 트랜잭션과 별개로 트랜잭션을 생성하고 자신의 작업이 끝나면 부모 트랜잭션과 상관없이 커밋한다.
내가 선택한 방법
두번째 방법의 경우 Self-Invocation 문제가 있어 새로운 트랜잭션이 제대로 생성되지 않았습니다. Self-Invocation 문제를 해결하기 위한 여러가지 방법이 있지만 현재 상황에서는 번거로운 작업들이 많이 존재했습니다. 게다가 새로운 트랜잭션이 생성되는 만큼 더많은 커넥션이 필요하게 되고 기존의 최적으로 구성해놓은 커넥션 풀 size를 수정해주어야 할 수 있습니다.
저의 경우 재고 읽는 로직(findById메소드)을 외부 클래스로 분리하여 Self-Invocation 문제를 해결한 후, 쓰레드 100개를 이용해 테스트해본 결과 Spring의 기본 Connection Pool Size로는 데드락 문제으로 인한 Timeout으로 테스트가 실패했으며 Size를 110개까지 늘려놓아서야 겨우 테스트를 통과하였습니다.
따라서 저는 구현이 간편하고 추가적인 작업이 필요 없는 첫번째 방법을 사용하여 문제를 해결하였습니다.
Isolation Level을 READ COMMITTED로 변경하는 경우 REPEATABLE READ가 되지 않는 현상과 PHANTOM READ 현상이 발생할 수 있지만, 현재 상황에서는 위와 같은 현상으로 인해 발생할 수 있는 문제가 딱히 없다고 판단되었습니다.
Self-Invocation 문제란?
스프링은 프록시 방식의 AOP를 사용한다. 즉 AOP가 적용되려면 프록시 객체를 통해 메소드를 호출해야 한다. 그러나 어떤 메소드가 자신과 같은 객체에 있는 메소드에 의해 호출될 경우 프록시 객체를 통하는 것이 아니라 실제 객체에 의해 바로 호출되기 때문에 AOP가 적용 되지 않는다. 이것을 Self-Invocation 문제라고 한다.
마무리
이 문제를 해결하면서 저는 기본 CS 지식의 중요성을 느꼈습니다. Isolation Level에 대한 개념이 없었다면 이 문제를 해결하기 위해 꽤 많은 시간을 투자해야 하지 않았을까? 라는 생각이 들었습니다.
또한 아무리 MySQL 모드라도 실제 MySQL과는 다른 점이 꽤 있으므로 테스트용 DB를 너무 믿으면 안 되고 꼭 실제 DB를 연결해서 테스트를 해야겠다는 생각이 들었습니다 ^^
긴 글 읽어주셔서 감사합니다 ~!


좋은 정보 감사합니다!