
1. 문제 설명
1.1 순위 검색
[본 문제는 정확성과 효율성 테스트 각각 점수가 있는 문제입니다.]
카카오는 하반기 경력 개발자 공개채용을 진행 중에 있으며 현재 지원서 접수와 코딩테스트가 종료되었습니다. 이번 채용에서 지원자는 지원서 작성 시 아래와 같이 4가지 항목을 반드시 선택하도록 하였습니다.
- 코딩테스트 참여 개발언어 항목에 cpp, java, python 중 하나를 선택해야 합니다.
- 지원 직군 항목에 backend와 frontend 중 하나를 선택해야 합니다.
- 지원 경력구분 항목에 junior와 senior 중 하나를 선택해야 합니다.
- 선호하는 소울푸드로 chicken과 pizza 중 하나를 선택해야 합니다.
인재영입팀에 근무하고 있는 니니즈는 코딩테스트 결과를 분석하여 채용에 참여한 개발팀들에 제공하기 위해 지원자들의 지원 조건을 선택하면 해당 조건에 맞는 지원자가 몇 명인 지 쉽게 알 수 있는 도구를 만들고 있습니다.
예를 들어, 개발팀에서 궁금해하는 문의사항은 다음과 같은 형태가 될 수 있습니다.
코딩테스트에 java로 참여했으며, backend 직군을 선택했고, junior 경력이면서, 소울푸드로 pizza를 선택한 사람 중 코딩테스트 점수를 50점 이상 받은 지원자는 몇 명인가?
물론 이 외에도 각 개발팀의 상황에 따라 아래와 같이 다양한 형태의 문의가 있을 수 있습니다.
- 코딩테스트에 python으로 참여했으며, frontend 직군을 선택했고, senior 경력이면서, 소울푸드로 chicken을 선택한 사람 중 코딩테스트 점수를 100점 이상 받은 사람은 모두 몇 명인가?
- 코딩테스트에 cpp로 참여했으며, senior 경력이면서, 소울푸드로 pizza를 선택한 사람 중 코딩테스트 점수를 100점 이상 받은 사람은 모두 몇 명인가?
- backend 직군을 선택했고, senior 경력이면서 코딩테스트 점수를 200점 이상 받은 사람은 모두 몇 명인가?
- 소울푸드로 chicken을 선택한 사람 중 코딩테스트 점수를 250점 이상 받은 사람은 모두 몇 명인가?
- 코딩테스트 점수를 150점 이상 받은 사람은 모두 몇 명인가?
즉, 개발팀에서 궁금해하는 내용은 다음과 같은 형태를 갖습니다.
* [조건]을 만족하는 사람 중 코딩테스트 점수를 X점 이상 받은 사람은 모두 몇 명인가?지원자가 지원서에 입력한 4가지의 정보와 획득한 코딩테스트 점수를 하나의 문자열로 구성한 값의 배열 info, 개발팀이 궁금해하는 문의조건이 문자열 형태로 담긴 배열 query가 매개변수로 주어질 때,
각 문의조건에 해당하는 사람들의 숫자를 순서대로 배열에 담아 return 하도록 solution 함수를 완성해 주세요.
1.2 제한 조건
- info 배열의 크기는 1 이상 50,000 이하입니다.
- info 배열 각 원소의 값은 지원자가 지원서에 입력한 4가지 값과 코딩테스트 점수를 합친 "개발언어 직군 경력 소울푸드 점수" 형식입니다.
- 개발언어는 cpp, java, python 중 하나입니다.
- 직군은 backend, frontend 중 하나입니다.
- 경력은 junior, senior 중 하나입니다.
- 소울푸드는 chicken, pizza 중 하나입니다.
- 점수는 코딩테스트 점수를 의미하며, 1 이상 100,000 이하인 자연수입니다.
- 각 단어는 공백문자(스페이스 바) 하나로 구분되어 있습니다.
- query 배열의 크기는 1 이상 100,000 이하입니다.
- query의 각 문자열은 "[조건] X" 형식입니다.
- [조건]은 "개발언어 and 직군 and 경력 and 소울푸드" 형식의 문자열입니다.
- 언어는 cpp, java, python, - 중 하나입니다.
- 직군은 backend, frontend, - 중 하나입니다.
- 경력은 junior, senior, - 중 하나입니다.
- 소울푸드는 chicken, pizza, - 중 하나입니다.
- '-' 표시는 해당 조건을 고려하지 않겠다는 의미입니다.
- X는 코딩테스트 점수를 의미하며 조건을 만족하는 사람 중 X점 이상 받은 사람은 모두 몇 명인 지를 의미합니다.
- 각 단어는 공백문자(스페이스 바) 하나로 구분되어 있습니다.
- 예를 들면, "cpp and - and senior and pizza 500"은 "cpp로 코딩테스트를 봤으며, 경력은 senior 이면서 소울푸드로 pizza를 선택한 지원자 중 코딩테스트 점수를 500점 이상 받은 사람은 모두 몇 명인가?"를 의미합니다.
1.3 입출력 예시
| info | query | result |
|---|---|---|
["java backend junior pizza 150","python frontend senior chicken 210","python frontend senior chicken 150","cpp backend senior pizza 260","java backend junior chicken 80","python backend senior chicken 50"] | ["java and backend and junior and pizza 100","python and frontend and senior and chicken 200","cpp and - and senior and pizza 250","- and backend and senior and - 150","- and - and - and chicken 100","- and - and - and - 150"] | [1,1,1,1,2,4] |
2. 풀이 과정
문제를 보자마자 SQL이 떠올랐던 문제였다. 문제 자체는 어렵지 않아서 완전 탐색으로 구현하면 정확성 테스트에서 통과할 수 있는 문제지만, 효율성 테스트까지 고려한다면 조금 난도가 있는 편이었다.
실제로 문제의 정답률을 확인해 봤더니 정확성 44.07%, 효율성 4.49%로 효율성이 핵심인 문제였다.
2.1 교집합 활용 : 실패😂
query의 배열 크기와 코딩 테스트 점수의 제한 조건이 10만 이하여서 O(nlogn) 이하로 풀어야겠다고 생각했다. 그래서 생각한 완전 탐색이 아닌 첫 번째 방법은 교집합을 활용하는 것이었다.
각 아이템(key)에 해당하는 사용자(value)를 사전에 저장하고, 쿼리 조건에 해당하는 아이템들의 교집합을 구한 후 주어진 점수 이상인 사용자의 수를 세는 방식이다.
이론상으로는 문제가 없는 줄 알았는데 실제 실행 결과를 보니 테스트 케이스에서만 동작하고 채점 케이스 모두에서는 실패하는 것을 볼 수 있었다. 거기다 시간 초과까지... 추가로 검토해서 문제를 해결할 수도 있었지만 일단 시간 초과가 나는 것을 보아 수정해도 효율성 테스트를 통과하지 못할 것 같아서 다른 방식으로 넘어가게 되었다.
- 전체 코드 (Python)
from collections import defaultdict
def solution(info, query):
group_info = defaultdict(set)
for i, user_info in enumerate(info):
user_info = user_info.split()
score = int(user_info[-1])
for item in user_info[:-1]:
group_info[item].add((i, score))
group_info["all"].add((i, score))
answer = []
for q in query:
q = q.split()
score = int(q[-1])
flag = True
filter_info = {}
for item in q[:-1]:
if item == "and" or item == "-": continue
if flag and not filter_info:
filter_info = group_info[item]
flag = False
else:
filter_info &= group_info[item]
if not filter_info and q.count("-") == 4:
filter_info = group_info["all"]
count = 0
for i, s in filter_info:
if s >= score: count += 1
answer.append(count)
return answer- 실행 결과
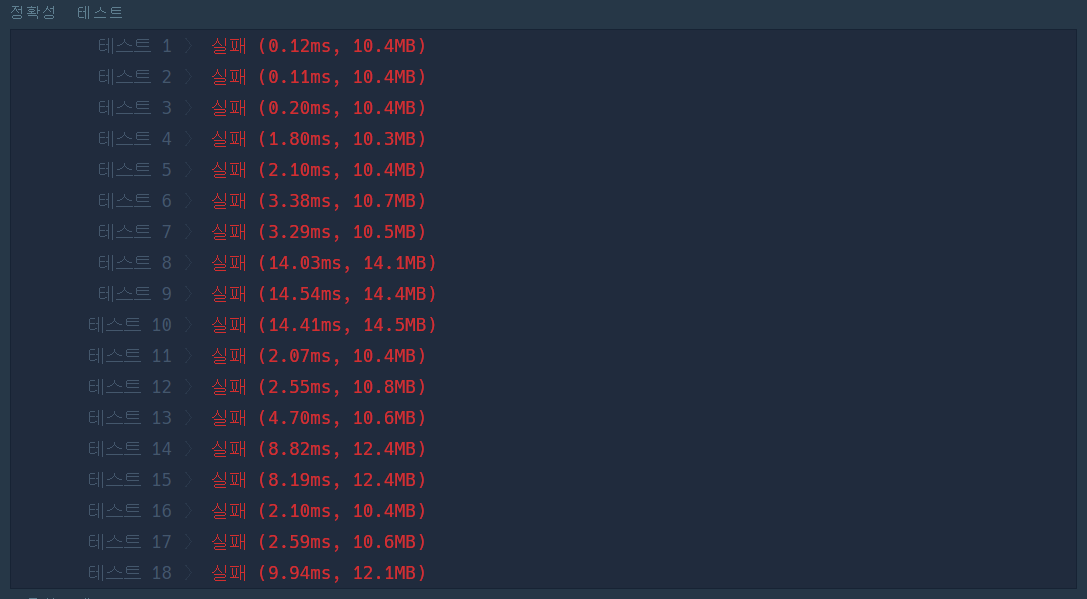
2.2 경우의 수 : 실패😂
두 번째 방법은 경우의 수를 고려하는 것이었다. 첫 번째 방식과 유사하게 사전을 활용한 방식이다.
| 언어 (유 or 무) | 직군 (유 or 무) | 경력 (유 or 무) | 소울 푸드 (유 or 무) |
|---|---|---|---|
| - | - | - | (chicken or pizza) |
| - | - | (junior or senior) | - |
| - | (backend or frontend) | - | - |
| (cpp or java or python) | - | - | - |
| ...(생략) | |||
| (cpp or java or python) | (backend or frontend) | (junior or senior) | - |
| (cpp or java or python) | (backend or frontend) | (junior or senior) | (chicken or pizza) |
query에서는 언어, 직군, 경력, 소울 푸드에 대해서 필터링을 하거나 하지 않거나(-) 2가지의 경우가 있다. 이 부분에 집중해서info를 순회할 때 미리 위의 모든 경우(2^4 = 16)에 대해서 사전에 저장해 둔 뒤qeury를 순회할 때 주어진 조건에 해당하는key를 찾아서 그 중 주어진 점수보다 높은 점수를 받는 지원자의 수를 세는 방식으로 구현해보았다.
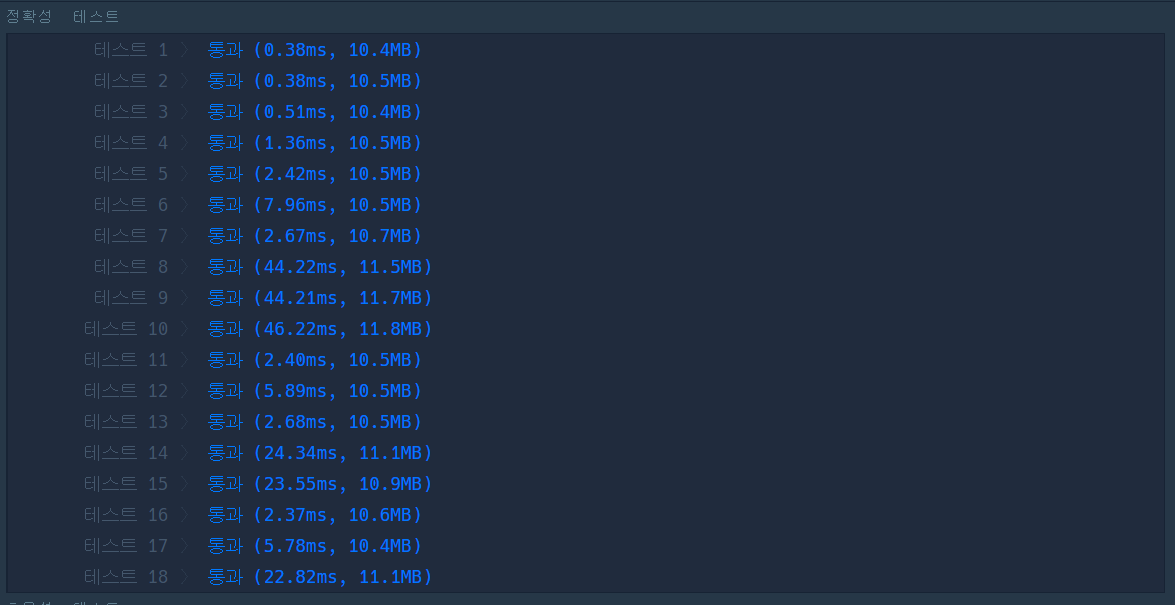
하지만 이렇게 하는 방식의 경우도 시간 초과가 났었다. 아마 제한 조건이 10만 이상인 query 안에서 반복문을 돌리는 과정이 시간 초과의 원인이지 않을까 생각해보았다.
- 전체 코드 (Python)
from collections import defaultdict
def solution(info, query):
group_info = defaultdict(list)
for i, user_info in enumerate(info):
lang, task, exp, food, score = user_info.split()
score = int(score)
case_list = []
for a in range(2): # 16가지 경우의 수에 대해서 모두 저장
for b in range(2):
for c in range(2):
for d in range(2):
temp_lang = "-" if a == 0 else lang
temp_task = "-" if b == 0 else task
temp_exp = "-" if c == 0 else exp
temp_food = "-" if d == 0 else food
group_info[(temp_lang, temp_task, temp_exp, temp_food)].append(score)
# score 이상인 사람을 찾기 편하도록 미리 정렬
for key in group_info.keys():
group_info[key] = sorted(group_info[key])
answer = []
for q in query:
lang, _, task, _, exp, _, food, score = q.split()
score = int(score)
temp = group_info[(lang, task, exp, food)] # 조건에 해당하는 값 찾기
count = 0
for t in temp: # score 이하인 사람 세기
if t >= score:
break
count += 1
answer.append(len(temp) - count) # score 이상인 사람
return answer- 실행 결과
2.3 경우의 수 + 이진 탐색 : 성공😋
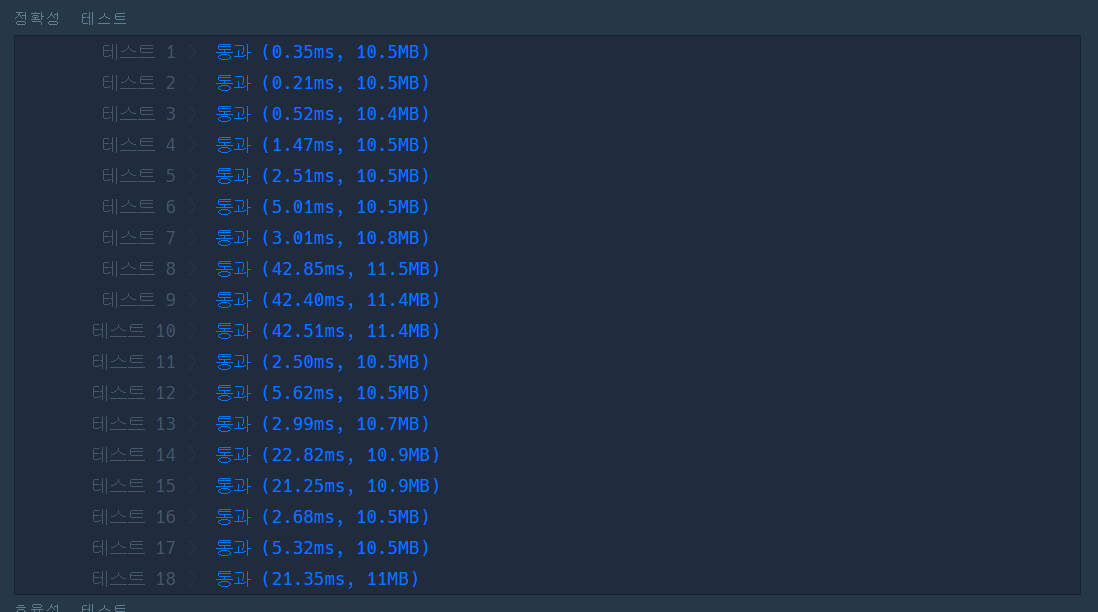
두 번째 방법까지 시도 후, 어떻게 해야 시간 효율에서 통과할 수 있을지 생각하는 것이 어려웠다. 그래서 힌트를 얻고자 질문하기를 뒤적거리던 중 이진 탐색을 활용하면 된다는 것을 알게 되어서 위의 코드에서 query 안의 반복문을 이진 탐색으로 변경해보았다.
그랬더니 효율성 테스트에서도 성공하는 것을 볼 수 있었다. n의 수가 작을 때는 별 차이가 없지만 n이 커질수록 이진 탐색을 할 경우 시간이 확연하게 줄어든다는 것을 알 수 있었다.
2.3.1 1차 코드 구현
- 전체 코드 (Python)
from collections import defaultdict
def solution(info, query):
group_info = defaultdict(list)
for i, user_info in enumerate(info):
lang, task, exp, food, score = user_info.split()
score = int(score)
case_list = []
for a in range(2):
for b in range(2):
for c in range(2):
for d in range(2):
temp_lang = "-" if a == 0 else lang
temp_task = "-" if b == 0 else task
temp_exp = "-" if c == 0 else exp
temp_food = "-" if d == 0 else food
group_info[(temp_lang, temp_task, temp_exp, temp_food)].append(score)
for key in group_info:
group_info[key].sort()
answer = []
for q in query:
lang, _, task, _, exp, _, food, score = q.split()
score = int(score)
temp = group_info[(lang, task, exp, food)]
# 이진 탐색
start, end = 0, len(temp) - 1
while start <= end:
mid = (start + end) // 2
if temp[mid] < score:
start = mid + 1
else:
end = mid - 1
answer.append(len(temp) - start)
return answer- 실행 결과

2.3.2 2차 코드 구현 (반복문 개선)
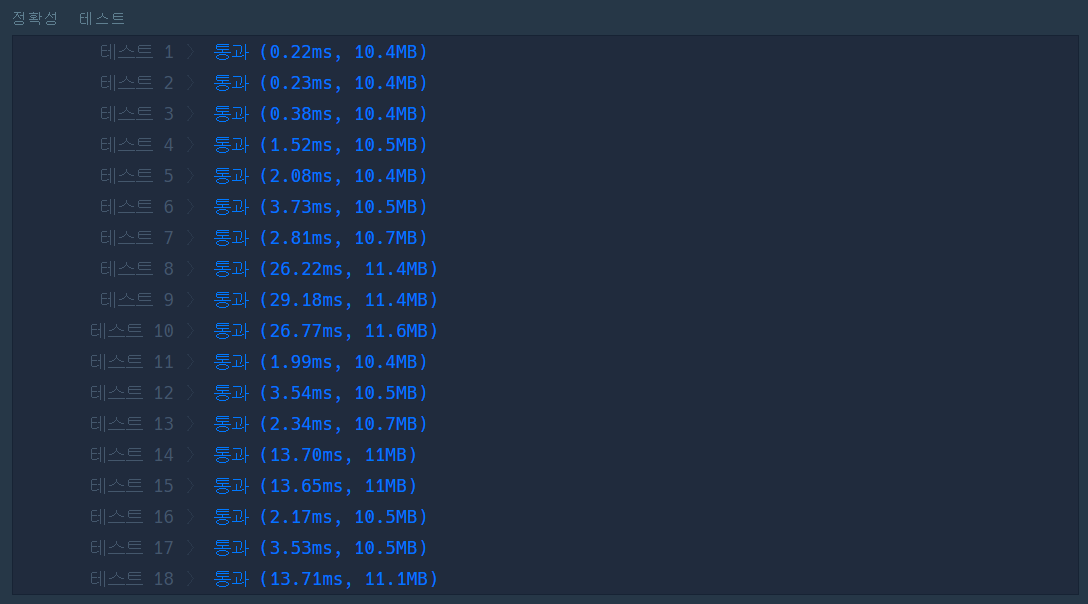
효율성을 통과하고 나니 코드를 조금만 더 개선해보면 좋지 않을까 해서 다른 사람들의 풀이를 보던 중 좋은 팁을 발견했다. 이전에 코드에서는 16가지의 경우의 수를 구현하는 데 있어서 for a in range(2)와 같은 형식으로 반복문을 구현 후 최종 반복문 안에서 if문으로 조건을 걸어주는 방식으로 구현했었다.
그런데 이렇게 구현하는 대신 애초에 for a in ["-", lang]와 같은 방식으로 구현할 수도 있다는 것을 알아서 바로 적용해보았다. 코드 적인 개선일 뿐이라 생각해서 시간 차이는 크지 않으리라 생각했는데 중첩되는 반복문 안에서 반복적으로 수행해야 했던 if문이 빠지게 되니 생각보다 많은 차이가 있었다.
- 전체 코드 (Python)
from collections import defaultdict
def solution(info, query):
group_info = defaultdict(list)
for i, user_info in enumerate(info):
lang, task, exp, food, score = user_info.split()
score = int(score)
case_list = []
for a in ["-", lang]: # 코드 개선 부분
for b in ["-", task]:
for c in ["-", exp]:
for d in ["-", food]:
group_info[(a, b, c, d)].append(score) # if 문 삭제됨.
for key in group_info:
group_info[key].sort()
answer = []
for q in query:
lang, _, task, _, exp, _, food, score = q.split()
score = int(score)
temp = group_info[(lang, task, exp, food)]
start, end = 0, len(temp) - 1
while start <= end:
mid = (start + end) // 2
if temp[mid] < score:
start = mid + 1
else:
end = mid - 1
answer.append(len(temp) - start)
return answer- 실행 결과

3. 핵심 정리
3.1 🔥 최종 풀이 🔥
가장 시간 효율이 좋은 마지막 풀이를 최종 풀이로 하였다.
from collections import defaultdict
def solution(info, query):
group_info = defaultdict(list)
for i, user_info in enumerate(info):
lang, task, exp, food, score = user_info.split()
score = int(score)
case_list = []
for a in ["-", lang]:
for b in ["-", task]:
for c in ["-", exp]:
for d in ["-", food]:
group_info[(a, b, c, d)].append(score)
for key in group_info:
group_info[key].sort()
answer = []
for q in query:
lang, _, task, _, exp, _, food, score = q.split()
score = int(score)
temp = group_info[(lang, task, exp, food)]
start, end = 0, len(temp) - 1
while start <= end:
mid = (start + end) // 2
if temp[mid] < score:
start = mid + 1
else:
end = mid - 1
answer.append(len(temp) - start)
return answer3.2 핵심 포인트
- 시간 복잡도 고려
- 완전 탐색 =>
이진 탐색
3.3 주요 라이브러리
3.4 참고 링크
