🔎 주제
HashSet의 내부 동작 방식과 중복 제거 메커니즘을 설명하고, HashSet이 효율적인 중복 체크를 할 수 있는 이유를 설명해주세요.
이 글에서는 HashSet에 요소를 삽입하는 원리를 살펴본다.
HashSet
import java.util.HashSet;
HashSet<Integer> set = new HashSet<>();HashSet의 특징
- 중복을 허용하지 않고, 고유한 값만 저장한다.
- null 값을 허용한다.
- 요소의 순서가 유지되지 않는다.
- Java Collectios Framework 중 Set 인터페이스를 구현한다.
- 해시 테이블 구조를 따른다.
⚙️ 내부 동작 방식
HashSet은 HashMap으로 구현된다
HashSet 클래스를 들여다보면 생성자에서 HashMap을 생성하고 있다.
HashSet.java
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable {
...
public HashSet() {
map = new HashMap<>();
}
...
}HashSet은 이 HashMap 객체와 메소드를 이용해 구현된다.
Set에 요소를 더하는 add() 메소드에서는 HashMap의 put() 메소드를 호출하는 방식이다.
HashSet의 삽입하는 값(e)은 맵 객체의 key 역할을 하며, value에는 상수를 대입한다.(-> 모든 요소의 value 값이 같다.)
HashSet.java
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}HashMap에서 key는 중복 불가능한 고유 식별자이다.
HashMap의 put(key, value) 메소드는
- 이미 key가 있다면 이전 value 값을 반환한다.
- key가 없었다면, null을 반환한다.
public class Main {
public static void main(String[] args) {
Map<Integer, Integer> map = new HashMap<>();
System.out.println(map.put(1,1));
System.out.println(map.put(1,2));
}
}
-------------------------------
출력 결과
null
1HashSet의 add()에서는 HashMap의 put() 메소드의 반환값이 null이면 참을, null이 아니면 거짓을 반환하므로 HashSet의 add()는 다음과 같이 동작한다.
- 삽입 성공 -> HashMap의
put()에서 null 반환 -> HashSet의add()에서 true 반환 - 삽입 실패 -> HashMap의
put()에서 이전 value 반환 -> HashSet의add()에서 false 반환
⚙️ 중복 제거 방식
HashMap에서 중복을 제거한다
즉, HashSet에서 중복을 제거하는 것은 HashMap에서 처리한다는 뜻이다.
그렇다면 HashMap에서는 어떻게 중복인지 구별할까?
이때 hashCode()와 equals() 두 메소드를 활용한다.
hashCode()
HashMap.java
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}hashCode() 메소드로 객체를 정수 형태로 변환한다. 이 과정을 해싱이라고 한다.
해시 알고리즘은 임의 길이의 메세지를 일정한 고정 길이의 해시 값으로 변환시킨다. 이때 해시 값을 구하는 함수를 해시 함수라고 한다. Java에서 hashCode()는 각 객체의 주소값을 변환하여 객체마다 고유한 값을 얻는다.
같은 객체의 해시 코드는 언제나 동일하다.
그러나 역은 성립하지 않는다. 해시 함수에 따라 다른 입력값이어도 같은 출력값이 나올 수 있기 때문이다. 해시 코드가 같다고 반드시 같은 객체는 아니다.
equals()
HashMap.java
public final boolean equals(Object o) {
if (o == this)
return true;
return o instanceof Map.Entry<?, ?> e
&& Objects.equals(key, e.getKey())
&& Objects.equals(value, e.getValue());
}이 메소드는 두 객체가 같은지 아닌지를 확인하여 boolean으로 반환한다.
코드를 보면 HashMap의 equals() 메소드에서는 두 가지 방식으로 객체를 비교한다.
- == 연산자: 두 객체의 메모리 주소값을 비교한다. 메모리 주소값이 같으면 두 객체는 당연히 같은 존재이다.
equals()와 &&: 오브젝트가 Map.Entry이고, 두 객체의 key가 같고, 두 객체의 value가 같은지 확인한다. 즉 두 객체의 내용이 같은지 본다.
equals()는 두 객체의 논리적 동등성을 확인한다.
두 객체의 내용이 같으면 주소가 달라도 같은 객체로 본다.
예시를 보자. equals()는 문자열을 비교할 때 많이 써봤을 것이다.
Main.java
public static void main(String[] args) {
String str1 = new String("Hello World");
String str2 = new String("Hello World");
String str3 = new String("hello world");
System.out.println(str1==str2); // str1과 str2의 메모리 주소는 다름
System.out.println(str1.equals(str2)); // 그러나 내용은 같음
System.out.println(str1.equals(str3)); // str1과 str3는 주소와 내용 모두 다름
}
---------------------
출력 결과
false
true
falsestr1과 str2의 메모리 주소는 다르므로 "==" 연산자로 비교하면 다른 객체로 본다.
그러나 equals()로 비교하면 true이다.
String.java
public boolean equals(Object anObject) {
if (this == anObject) {
return true;
}
return (anObject instanceof String aString)
&& (!COMPACT_STRINGS || this.coder == aString.coder)
&& StringLatin1.equals(value, aString.value);
}String 클래스에서는 값을 비교할 때 value 즉 저장된 문자열을 확인하기 때문이다.
이처럼 HashMap에서는 한 엔트리에서 key와 value의 내용이 같은지 비교하고, HashSet에서는 value는 상수로 모두 같으므로 key, HashSet의 요소들이 내용이 같은지 확인하여 중복을 피한다.
equals()와 hashCode()의 관계
equals()로 객체가 같은지 비교할 수 있고, hashCode()로 각 객체마다 고유한 값을 줄 수 있다면 왜 두 메소드 중 하나만 쓰지 않고, 함께 쓸까?
HashSet, HashMap이 해시 테이블 구조를 기반으로 구현된 클래스이기 때문이다.
결론을 먼저 말하자면, hashCode로 다른 객체인지 아닌지는 빨리 알 수 있지만, 해시 충돌이 일어난 경우에는 equals로 정말로 같은 객체인지 확인한다.
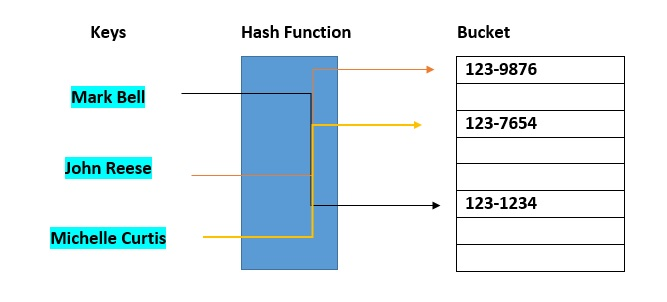
해시 테이블 구조에서 각 키(HashMap의 키, HashSet의 요소)는 해시코드를 부여 받는 해싱 프로세스를 거쳐 값(value)을 테이블의 어느 인덱스에 저장될지 결정된다. 여기서 실제로 값이 저장되는 장소를 버킷이라고 부른다.
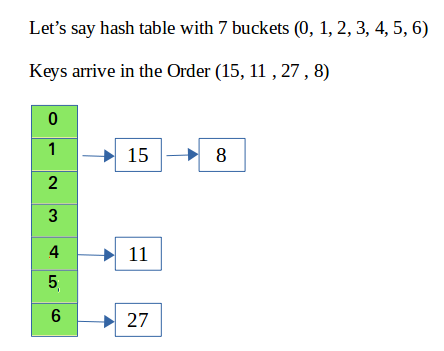
당연히 하나의 버킷에 하나의 데이터만 저장되는 것은 아니다.
버킷의 개수는 유한하고 만약 다른 두 객체의 해시 함수 출력값이 동일하다면, 해시 테이블의 같은 인덱스 즉, 같은 버킷에 저장된다.
위 그림에서는 '15'와 '8'이 같은 해시 값을 가지고 있어(해시 충돌) 같은 버킷에 저장되었다. (같은 버킷 내에서는 서로 연결되는데 이것을 체이닝이라 한다.) 같은 객체는 반드시 같은 해시 값을 가지지만, 같은 해시 값을 가진다고 같은 객체라고 볼 수는 없다.
경우 1
만약 이 테이블에서 '11'과 '15'가 같은지 비교하고자 한다면
각자의 버킷으로 가서 내용을 직접 확인하기도 전에 해시 코드가 다르므로
결과는 false이다.
경우 2
만약 이 테이블에서 '15'와 '8'을 비교하고자 하면
두 객체는 해시 값이 1로 같다. 이제는 내용을 비교해봐야 한다.
버킷 1로 가서 '15'와 '8'이 같은 내용인지 equals를 확인한다.
결과는 false이다.
이처럼 해시 구조에서 두 객체를 비교할 때는
테이블의 모든 객체와 일일이 비교하지 않고 hashCode()로 버킷을 찾아 데이터를 탐색하고,
같은 버킷에 여러 객체가 있는 경우에는 equals()로 실제로 동등한 객체가 있는지 확인한다.
Java에서 해시 구조에서의 탐색 규칙은 다음과 같다.
- equals()가 true라면 hashCode()는 반드시 같고, 두 객체는 같다.
- equals()가 false라면 hashCode()는 같을 수도, 다를 수도 있다. 객체는 서로 다르다.
✅ 효율적인 해시 테이블 구조
왜 해시 구조를 사용할까?
해시 값을 사용하여 데이터가 저장된 버킷을 빠르게 찾기 때문이다.
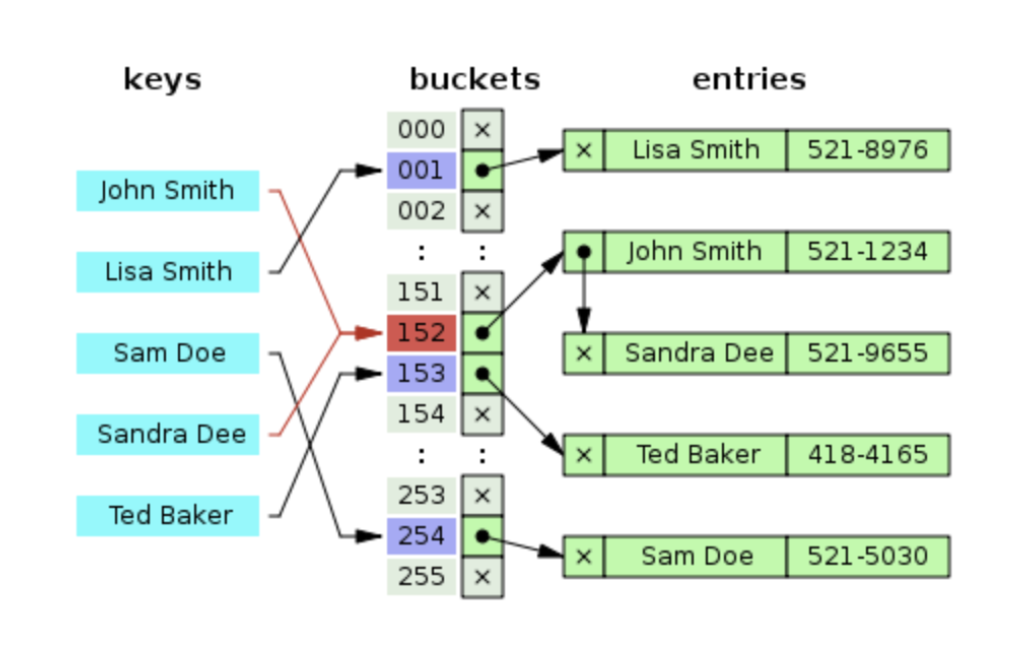
만약 Sam Doe를 검색하고 싶다면 해시 코드를 계산하고 그 버킷에 접근한다.
버킷 254에는 객체가 Sam Doe 하나만 있으므로 바로 찾았다.
만약 Sandra Dee를 검색하고 싶다면 버킷 152에 접근한다.
버킷에서 객체들이 링크드 리스트로 연결되어 있는데 Sandra Dee는 루트 노드가 아니다. Sandra Dee가 나올 때까지 다음 노드를 순회한다.
평균적으로, 해시 코드가 겹치지 않는다면 객체를 바로 찾을 수 있으므로 O(1)에 찾을 수 있다. 워스트 케이스에는 한 버킷에 객체가 여럿 있고, 찾으려는 객체가 링크드 리스트의 마지막에 있는 경우로 O(n)이다.
해시 함수를 잘 정의한다면 대부분의 경우에 O(1)로 객체를 바로 찾을 수 있으므로
효율적으로 중복을 체크할 수 있다.
🔑 한 줄 요약
HashSet은 내부적으로 HashMap으로 동작하고,
해시 구조에서 hashCode()와 equals()로 객체를 빠르게 찾고 비교하여
중복을 효율적으로 체크할 수 있다!
📋 참고자료
추천 ✅
Internal working of Set/HashSet in Java
Java HashSet
HashSet In Java: Features, Hierarchy, Constructors, Methods, and More
[JAVA] HashSet이란? & 사용법 정리
Hashing in Data Structure
자바에서 equals()와 ==의 차이
