
✏️ PANDAS (jupyter)
💡 Series ()
- Pandas Series 공식
- 첫 글자는 대문자로 입력하기!!!
- Index & Value 로 구성
- 1가지 데이터 타입만 가질 수 있음 ex) int+str 함께 x, 출력시 str로 전체 인식
- 데이터형을 구성하는 기본
- coulmn 한줄 한줄
- pandas.Series(data=None, index=None, dtype=None, name=None, copy=None, fastpath=False)
- dtype : int / float / object(=str) / datetime64[ns] / timedelta64[ns]
- pandas.Series(Index : value)
#1.
import pandas as pd
pd.Series()
#------out-----
Series([], dtype: object)
#2.
import pandas as pd
pd.Series([1,2,3,4])
#------out-----
0 1
1 2
2 3
3 4
dtype: int64
#3.
import pandas as pd
pd.Series([1,2,3,4],dtype = float54) # 에러 뜸
pd.Series([1,2,3,4],dtype = np.float54)
0 1.0
1 2.0
2 3.0
3 4.0
dtype: float64
#------out-----💡 date_range ("날짜", periods=기간 )
- 날짜 및 시간 출력
import pandas as pd
dates = pd.date_range("20130101",periods=6)
dates
#------out-----
DatetimeIndex(['2013-01-01','2013-01-02','2013-01-03','2013-01-04','2013-01-05','2013-01-06'],dtype='datetime64[ns]',freq='D')💡 DataFrame ()
- Index & Value & colunm 로 구성
- pandas.DataFrame (data,index,columns)
dates = pd.date_range("20210101", periods=6 )
data = np.random.randn(6,4) #6행4열
df = pd.DataFrame (data,index=dates,columns=['A','B','C','D'])
df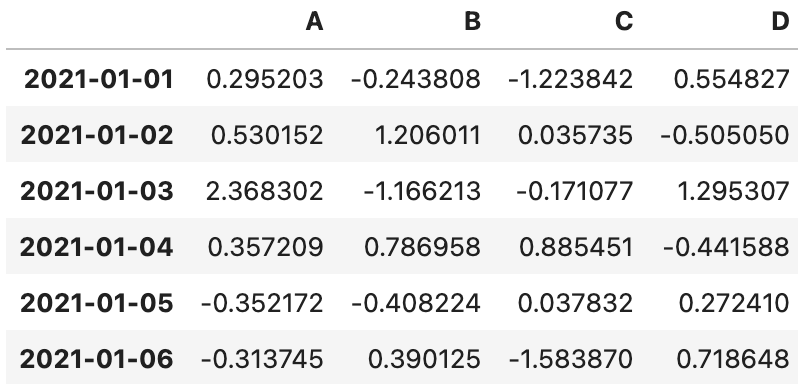
💡 DataFrame 정보 탐색
1_head ( )
- 인덱스 앞 5개만 호출
df.head ( )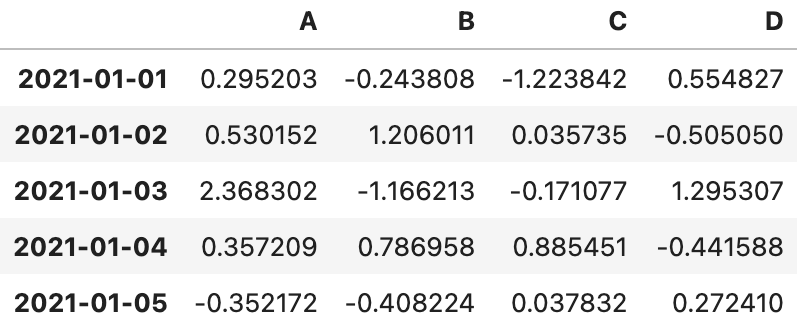
2_tail ( )
- 인덱스 뒷 5개만 호출
df.tail ( )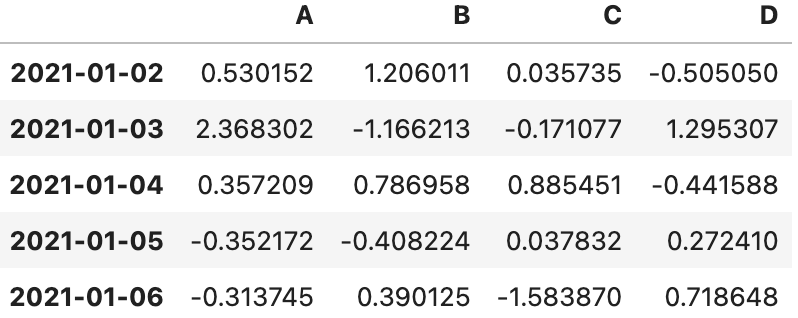
3_index, values, columns
- index, values, columns라는 변수에 들어간거라 괄호가 필요 없음
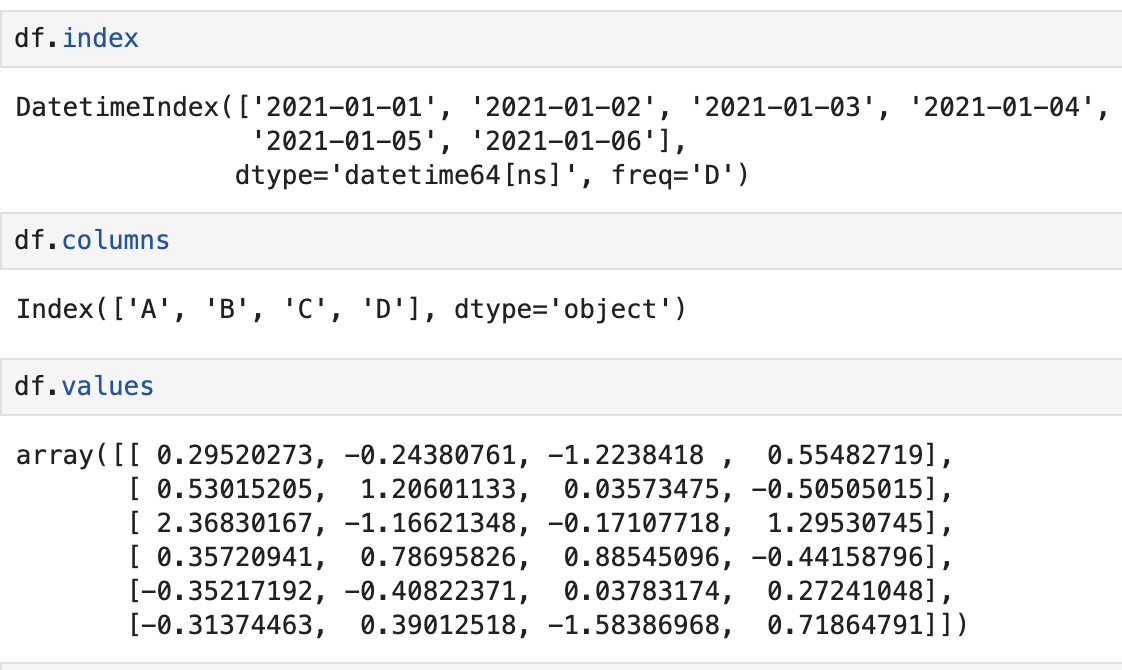
💡 slice
- [n:m] : 인덱스값 n ~ (m-1)
- 인덱스나 컬럼 이름으로 할 경우, 끝을 포함

- loc
- location의 약자
- 특정 인덱스 행과 컬럼 열 이름으로 로딩
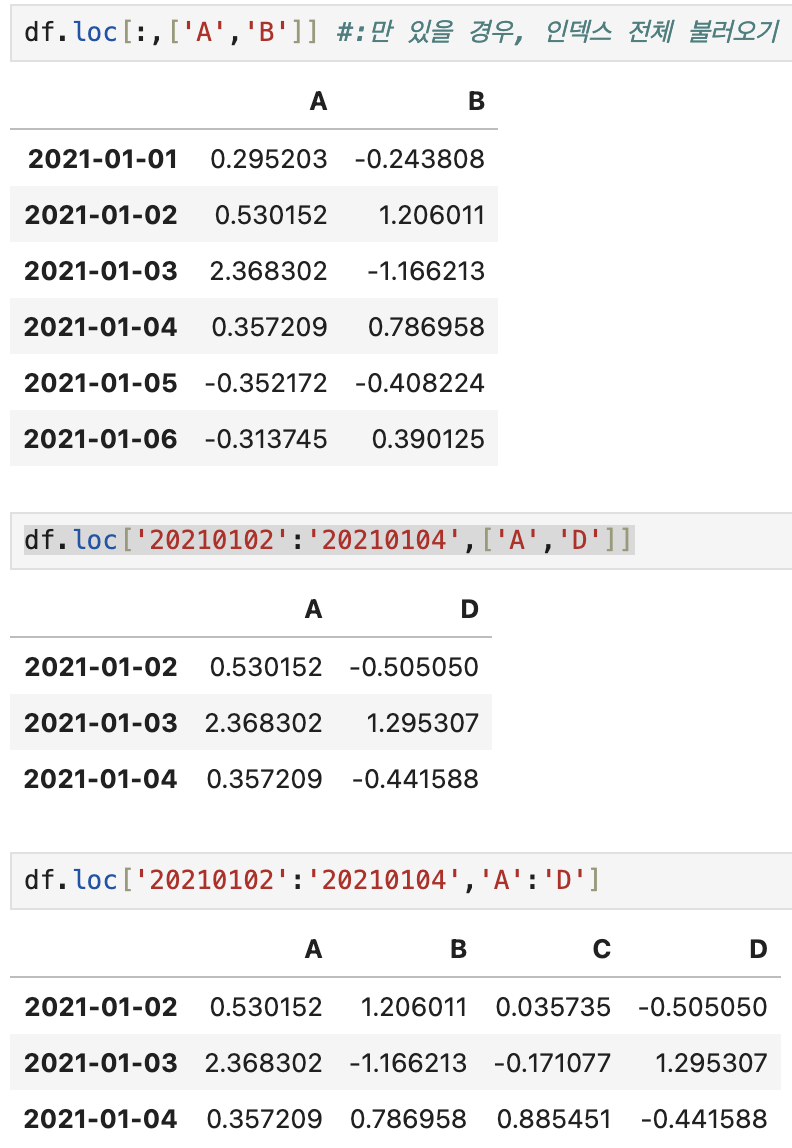
- iloc
- 컴퓨터가 인식하는 인덱스 값으로 선택

- 컴퓨터가 인식하는 인덱스 값으로 선택
💡 condition
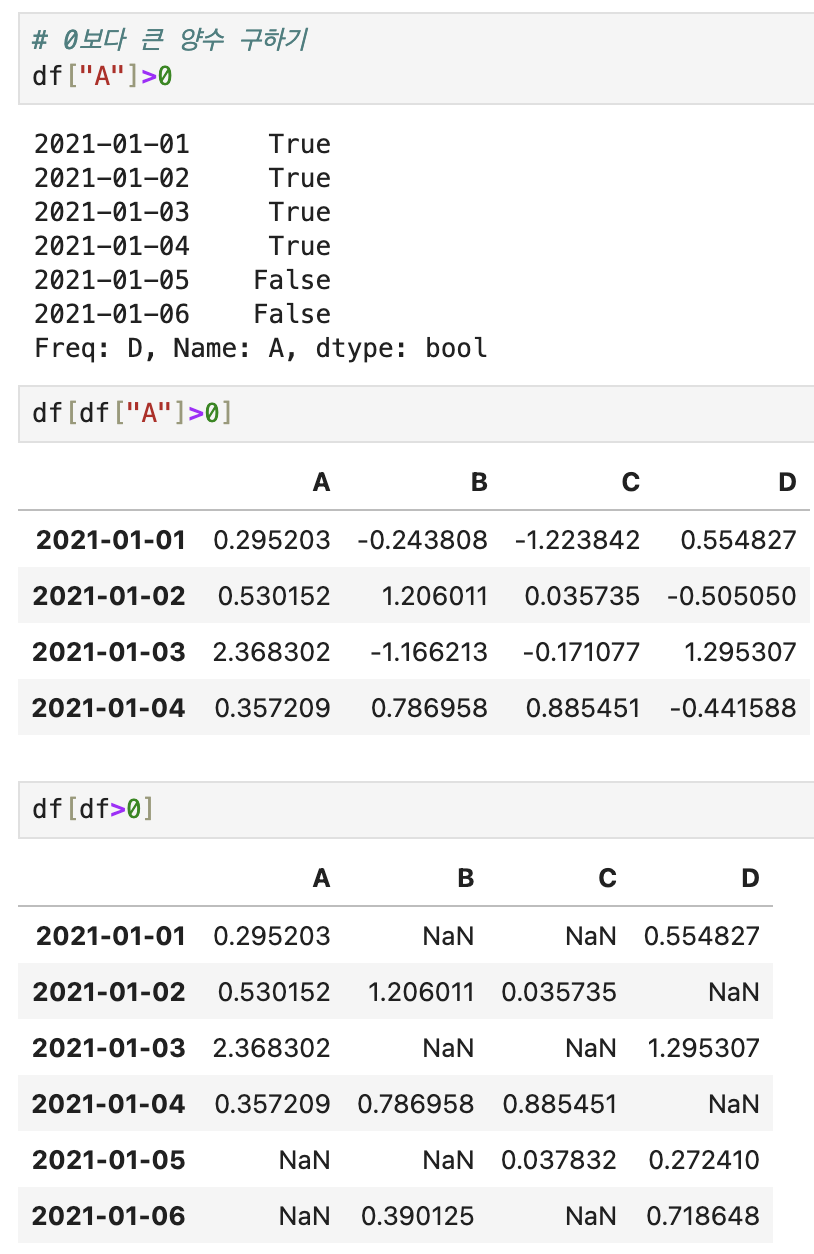
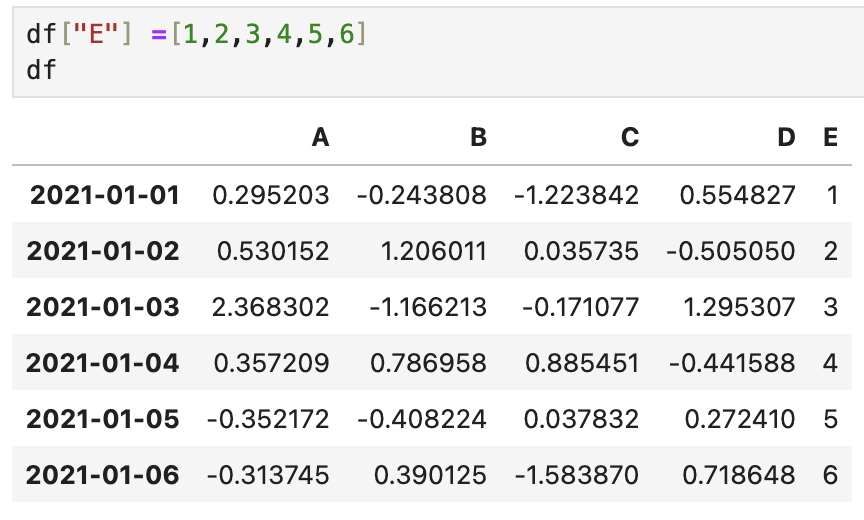
💡 컬럼 추가
- 기존 데이터가 없으면 추가, 있으면 수정
💡 컬럼 제거
1_del
- del은 원본 저장 따로 필요없이 바로 원본까지 수정됨
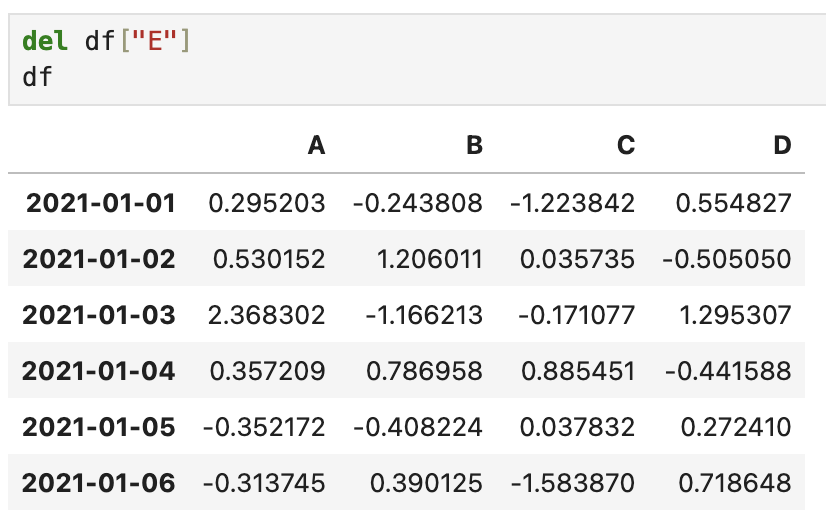
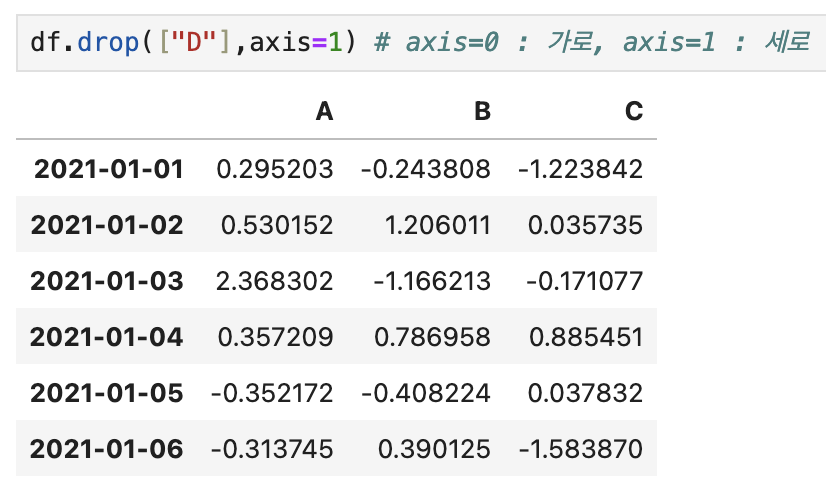
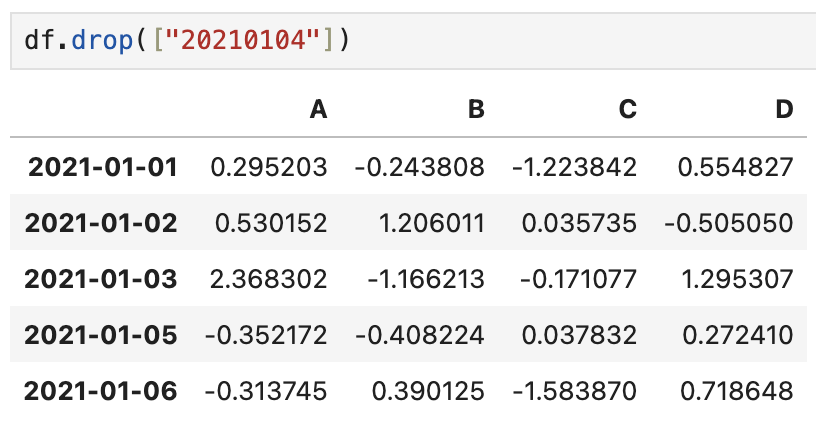
2_drop
- 컬럼에 사용시 axis 필요 (인덱스 이름으로 삭제시, 불필요)
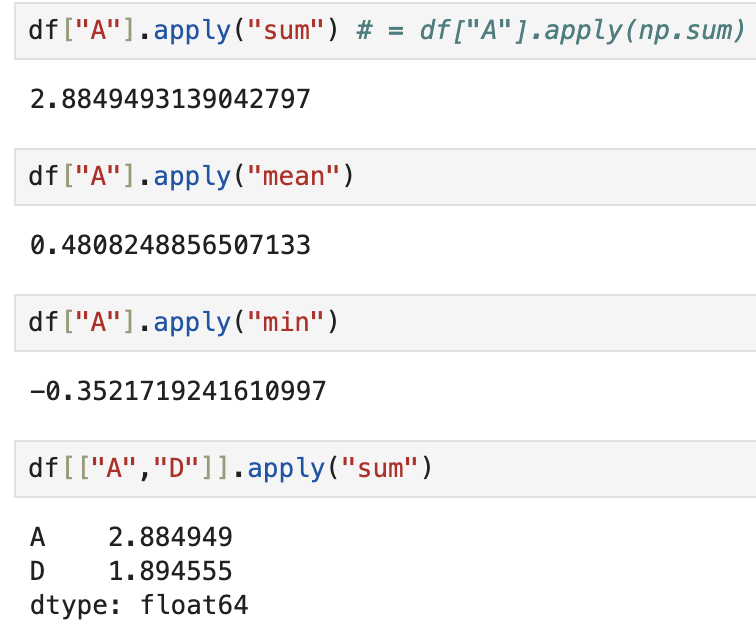
💡 apply()
- apply ("sum") : 덧셈
- apply ("mean") : 평균
- apply ("min") : 최솟값
- apply ("max") : 최댓값
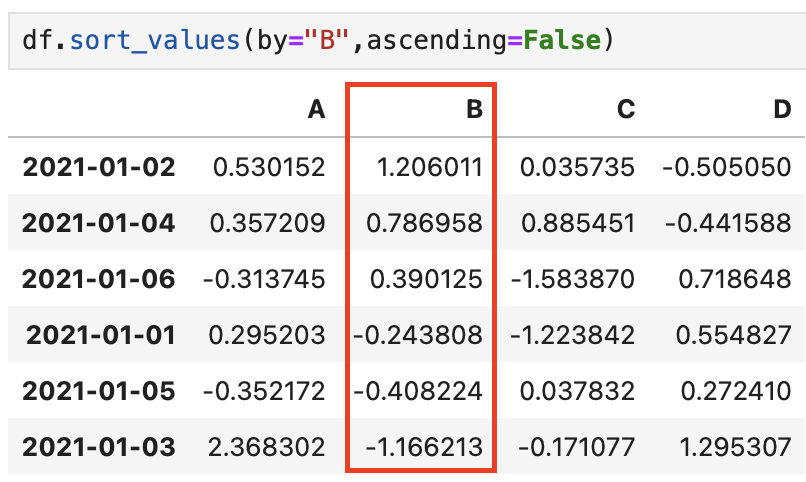
💡 sort_values()
- (by=" ")을 통해 특정 컬럼/열을 기준으로 데이터 정렬
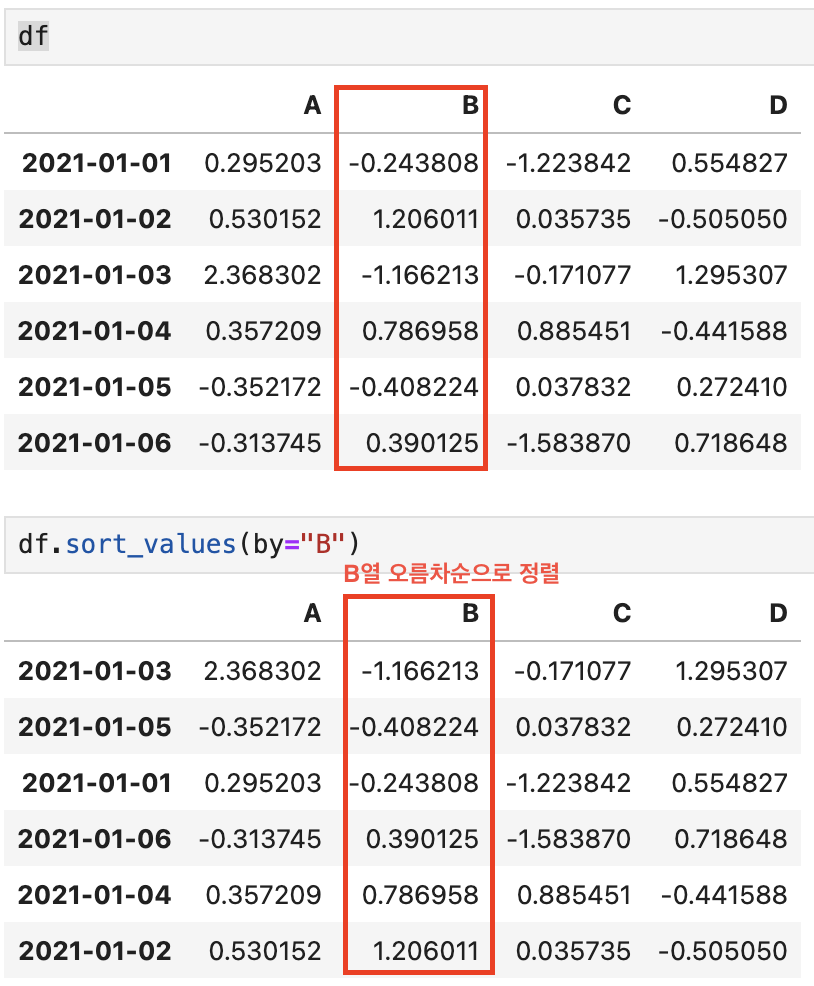
- ascending=False : 내림차순으로 정렬
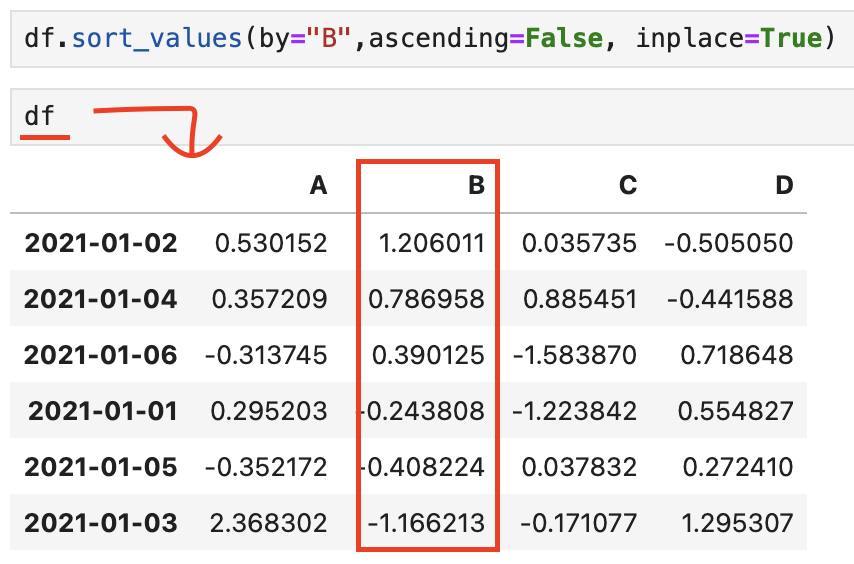
- inplace=True : 원본 데이터에 저장
원본 데이터인 df를 호출해도 명령 그대로 적용돼서 출력됨
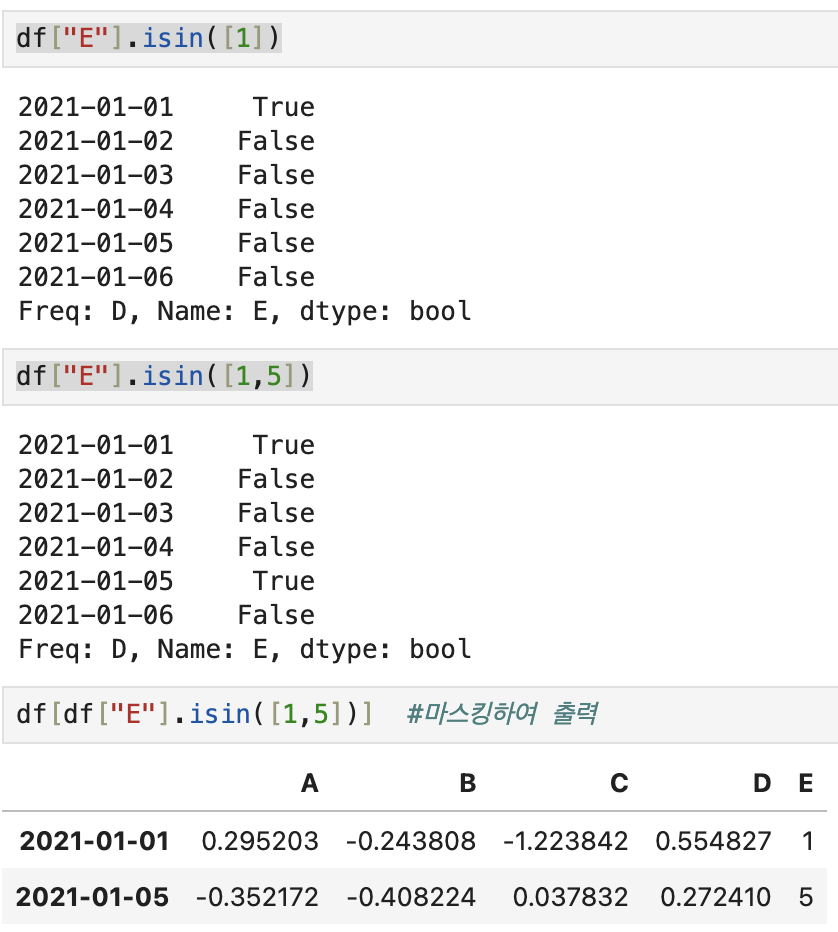
💡 .isin([ ])
- 특정요소가 있는지 확인
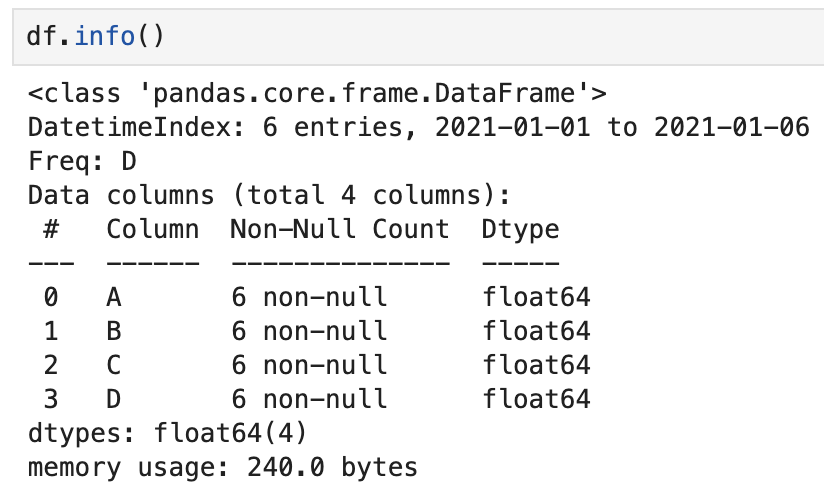
💡 데이터의 정보(속성) 탐색
1_info()
- 데이터의 기본 정보를 탐색할 때 사용
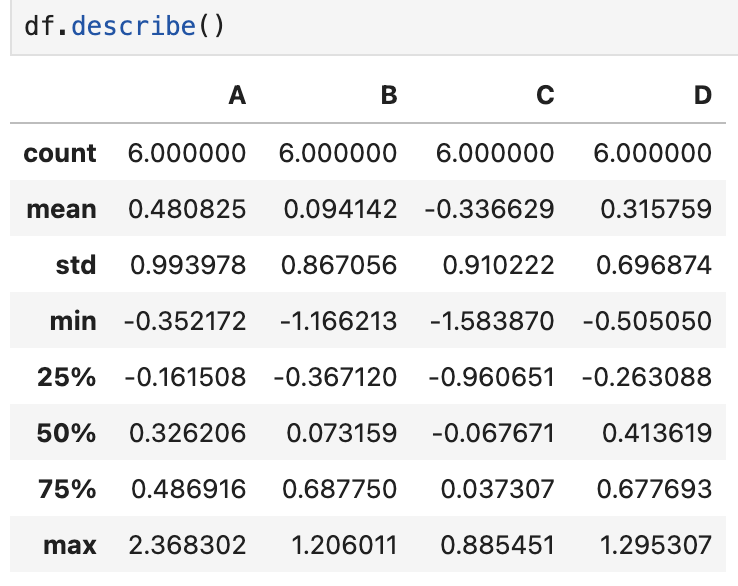
2_describe()
- 데이터 프레임의 기술통계 정보 확인
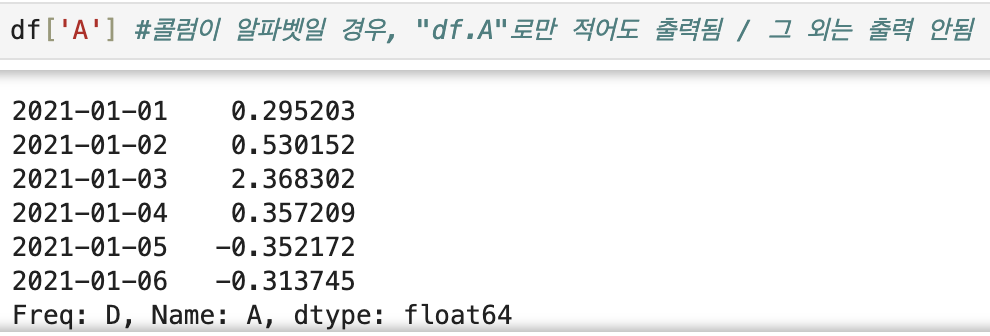
💡 열(columns) 선택
1_1개의 column 선택
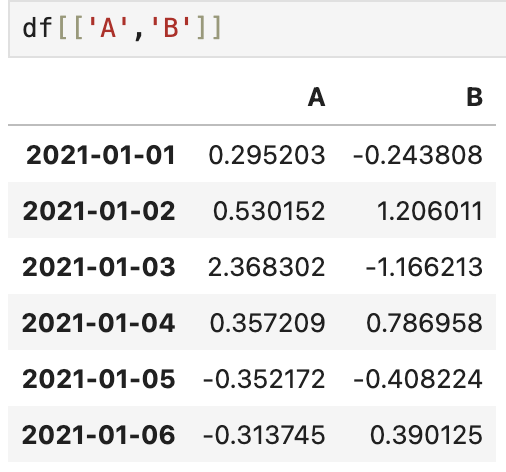
 #### 2_다수 column 선택 : 리스트 형식
#### 2_다수 column 선택 : 리스트 형식
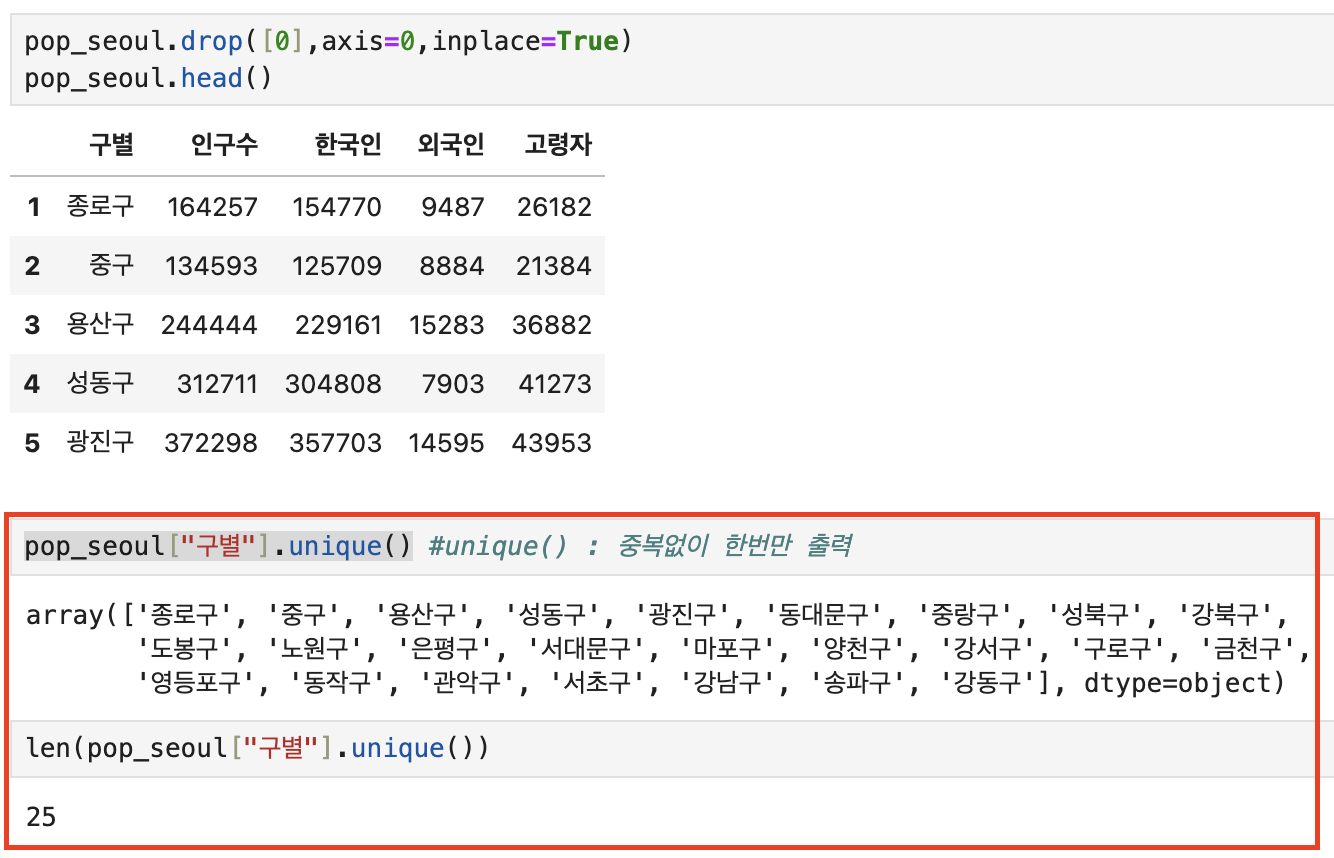
💡 unique()
터미널 - [conda activate ds_study] 입력 - [cd 저장 경로] 입력- [jupyter notebook] 입력
VS code에서 파일을 만들 때, 반드시 확장자명도 함께 써야함 , ipynb가 주피터를 불러오는 확장자
차이 확인하기 : 도트(.) 유뮤, 소괄호를 쓰거나 대괄호를 쓰거나

데린이인데요 ໒꒰ྀ ˶ • ༝ •˶ ꒱ྀིა (잘못 된 부분은 너그러이 알려주세요.)