이벤트 스토밍을 하게 되면 BC가 도출이 된다.
Command가 API 후보가 된다.
Aggregate라는 데이터 요소가 나온다.
Domain Event가 나온다.
비즈니스 로직을 설계하기 위한 이거에 대한 Input 요소들이 이벤트 스토밍 과정을 통해서
도출이 된다.
이러한 이벤트 스토밍을 통해서 나타낸 데이터를 통해서 실질적인 MSA 및 비즈니스 로직을 설계하는 데 필요한 전략이 전술적 설계이다.
✅ 트랜젝션 스크립트 패턴
< 엔터프라이즈 아키텍처 패턴 , 마틴 파울러 >
- 간단한 비지니스 로직 구현의 경우
- 절차 지향 스크립트로 구현 , 데이터베이스 직접 접근도 가능
- 각 작업은 성공하거나 실패할 수 있지만 유효하지 않은 상태를 만들면 안된다.

MSA 내의 비즈니스 로직들을 어떻게 구성할 것인가 그런것들이 어떻게 보면 Pattern 화 되어 있다.
-
서비스 내부에 Class가 있다면, 그 Class가 트랜잭션 단위로 CURD 방법으로 구현
- 유저의 방문 기록을 남기는 비즈니스 로직
- 유저의 최근 방문 날짜는 Update, 방문 로그를 insert 하는 모습
-
트랜잭션 단위로 table을 건드려서 처리하는 것
-
데이터 베이스에 종속된 방식이다.
-
비즈니스 로직은 Java 언어만 있어야 하지만 SQL문이 종속된다.
- 굉장히 기술적인곳에 종속된다.
-
저장소가 다양하게 변경될 수 있다.
- 기술에 종석적인 SQL 을 쓰게 되니깐 유연하게 되지 못하는 단점이 있다.
-
흔히 CRUD라는 방식 , 비즈니스 로직이 단순한 경우는 이해하기 쉽고 인지하기 쉽다.
-
하지만 비즈니스 로직이 복잡할 수록 트랜잭션간 비즈니스 로직이 중복되기가 쉽고 결과적으로 중복된 코드가 동기화 되지 않는 일관성 없는 동작이 발생된다.
(유지보수가 안되는 거대한 진흑 덩어리가 될 가능성이 있다.)
그래서 이러한 방식에는 핵심(Core)부분에는 사용하지 않는 것이 좋다.
✅ Active Record (엑티브 레코드 패턴)

-
객체가 가지는 속성을 행위를 통해서 표현한다.
-
따라서, 액티브는 행위에 getter, setter, save 정도의 메서드만 있다.
-
행위가 비즈니스 로직을 표현해야 하는데, 액티비 레코드 기준에서는 조금 부족하다. (행위적 측면)
-
응용 서비스에서는 도메인 모델에게 책임을 위임함으로써 메시지를 전송하는 방식이다.
-
액티브 레코드는 객체 모델을 만들긴 하는데 행위가 빈약하다. (Getter, Setter 정도만 존재) ⇒ 빈약한 도메인 모델이라고 불린다.
비즈니스 로직을 얼마나 풍부하게 다루냐에 따라서 액티브 레코드와 도메인 모델 패턴하고 분리된다.
✅ 도메인 모델 패턴
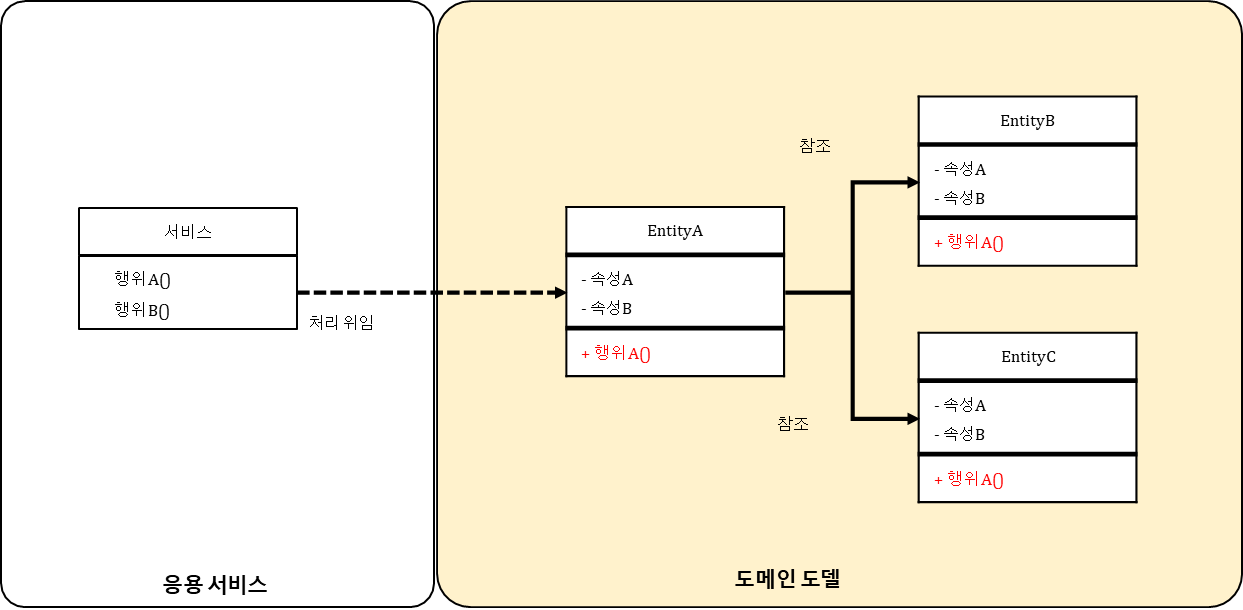
<엔터프라이즈 아키텍처 패턴 , 마틴 파울러>
-
에반스는 전술적 도메인 주도 설계(tactical domain-driven design) 패턴이라 언급
-
도메인 모델은 행위(behavior) + 자료구조(data)를 통해 비지니스 로직 구현
-
POJO 로 구성 : 이미 본질적으로 복잡하므로 인프라, 기술적 관심사를 피해야 함.
-
응용서비스에서는 대부분 업무 흐름 제어만 하며 주요 비지니스 로직은 도메인 모델에 위임하여 처리
-
비즈니스 메서드를 구현하도록 표현한 패턴이다.
-
복잡한 비즈니스 로직은 도메인 모델 패턴을 사용해라
-
마틴 파울러가 말하는 도메인 모델 패턴은 넓은 의미에서의 패턴이고
애릭 에반스가 말하는 Aggregate 패턴은 Domain 모델 패턴을 다시 구체적 설명 -
도메인 모델 패턴에 사용되는 도메인은 진흙 덩어리 될 가능성이 있다. (연관 관계가 커지는 경우)
-
도메인 모델이 복잡해지면, 객체를 조회하는데 한꺼번에 모두 조회
-
메모리에 로딩된 객체가 많아질 가능성이 커진다.
-
적당히 BC에 따라 쪼개야 한다는 것은 애릭 에반스가 말하는 Aggregate 수준으로 쪼개야 한다.
✅ 도메인 주도 설계의 Aggregate 패턴
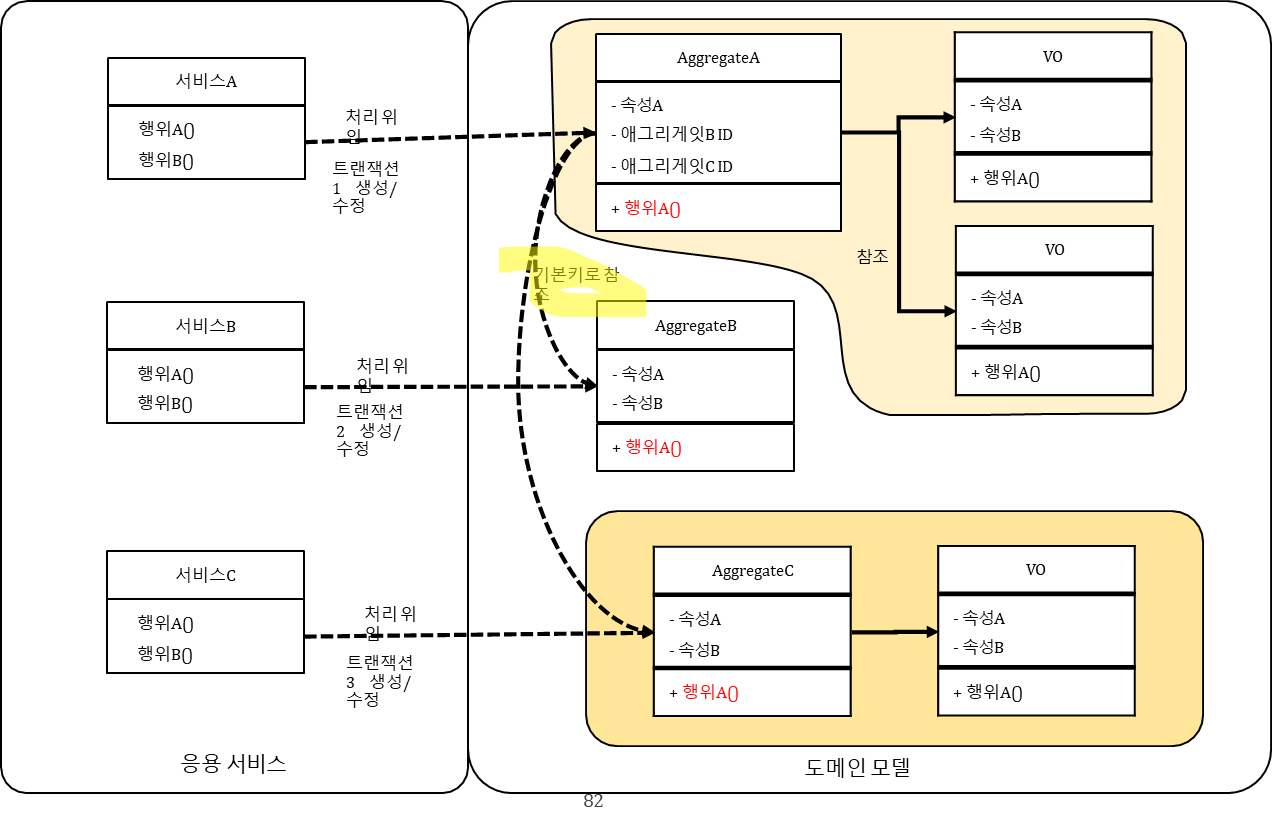
BC 내부적으로는 Class를 통해 직접 참조
BC 간의 참조는 ID 값을 통해 간접 참조
-
앞전의 도메인 모델 패턴 적용 시 도메인 모델이 점점 복잡하고 비대해짐(Big ball of mud)
-
이에 그 복잡성을 관리할 단위를 구분해 냄 (도메인 주도의 Aggregate)
-
하나의 BC 안에 하나의 Aggregate가 존재하며 그 구성은 대부분 한개의 Entity 와 여러 개의 VO 구성
-
거대한 도메인 모델을 Aggregate 수준으로 나눈게 애릭 에반스의 Aggregate 패턴이다.
-
Entity를 통해서 객체 모델을 만든다.
-
여기서 말하는 Entity는 논리 모델에서의 Entity이다.
식별자를 가지고 있는 요소이다. -
데이터 모델(JPA의 Entity)과 다른 점은 데이터 모델은 속성만 있다.
- 객체 모델은 행위까지 있다.
-
Entity 중심으로 묶여져 있다.
-
상위 Entity를 Aggregate Root라고 한다.
-
상위 Aggregate Entity를 표현할때 VO를 통해서 Aggregate 내부를 모델링할 수 있다.
✔️ VO (Value Object)

-
개념적으로 완전한 하나를 표현
-
고유의 식별자를 가지지 않음
-
명료성 향상, 의도를 명확히 전달, 유효성 검사, 비지니스 로직 표현, 유비쿼터스 언어 사용시 비지니스 도메인 개념 표현
-
도메인 주도 설계에서 말하는 VO는 Dto가 아니라 도메인 모델을 표현하는 유형중 하나이다.
-
원시타입 string을 사용하게 되면, 어떤 값이든 들어갈 수 있다.
- 그래서 유효성 검사를 하기가 쉽지 않다.
-
그래서 VO를 통해서 유효성 검사를 해라.
- 원시 속성을 객체로 표현한다.
-
구조체 선언하는 듯 하는게 VO이다.
- VO는 이런 유효성 검사를 하는데 좋다.
-
상태를 변경할 수 없는(불변: immutable) 단순히 값만을 갖는 객체
-
객체를 변경할 때는 객체 자체를 완전히 교체하는 것을 의미
-
읽기 전용 객체
- 분산되기 쉬운 비즈 로직을 한데 묶어줄 뿐 아니라 안전한 코드를 작성할 수 있음.
-
가능한 모든 경우에 사용 , 다른 객체(엔티티, 다른 VO)의 속성을 표현하는 요소로 사용
-
Ex) ID, 이름, 전화번호, 이메일 , 받는 사람(Receiver), 주소(Address), 화폐(Money)
의미가 잘 드러나도록 식별자를 Vo로 표현 -
DTO와 헷갈리지 말 것 , DTO는 프레젠테이션 계층과 도메인 계층에서 사용되는 구조체 개념
✔️ Entity (엔티티)

-
모든 도메인의 필수 구성요소
-
도메인의 고유 개념 표현
-
다른 객체와 구별할 수 있는 식별자(고유 식별자)를 갖는 객체
-
주문에서 배송지 정보가 변경되어도 주문번호는 변경되지 않음.
-
자신의 생명주기를 가짐
-
예시: 주문, 회원, 상품 DB Entity 와의 차이 : 데이터와 함께 기능을 제공
-
Entity는 VO 구조체와 달리 식별자를 가지고 있다.
-
생성, 수정, 삭제를 할 수 있는 요소이다. (생명 주기가 있다)
-
객체의 논리적 Entity는 기능을 제공한다 → 행위를 제공한다. (메서드)
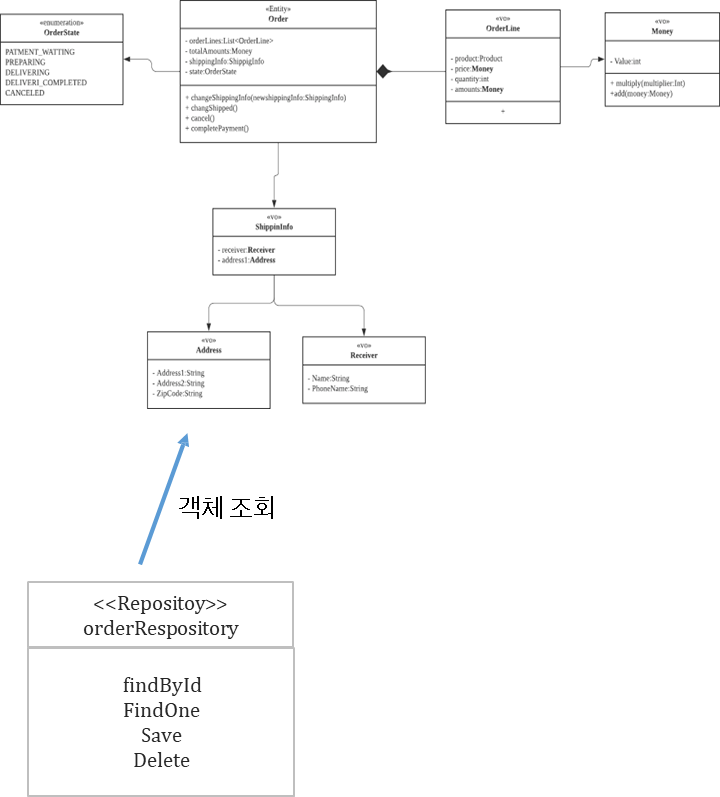
✔️ 도메인 모델 예시
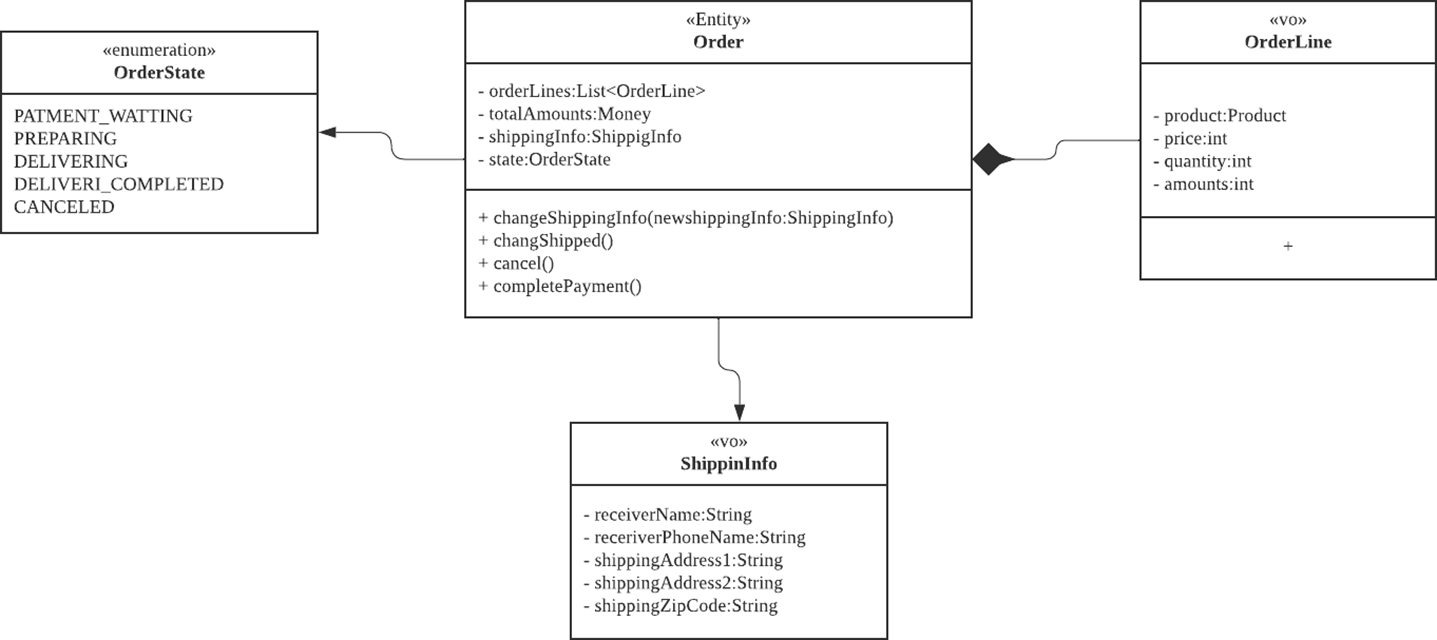
- Entity : Order
- VO : orderLine, ShippingInfo
- Enumeration
- VO 안에서도 또 다른 VO를 활용해서 목적별로 사용할 수 있다.

VO 추가 식별을 통해, VO 분리
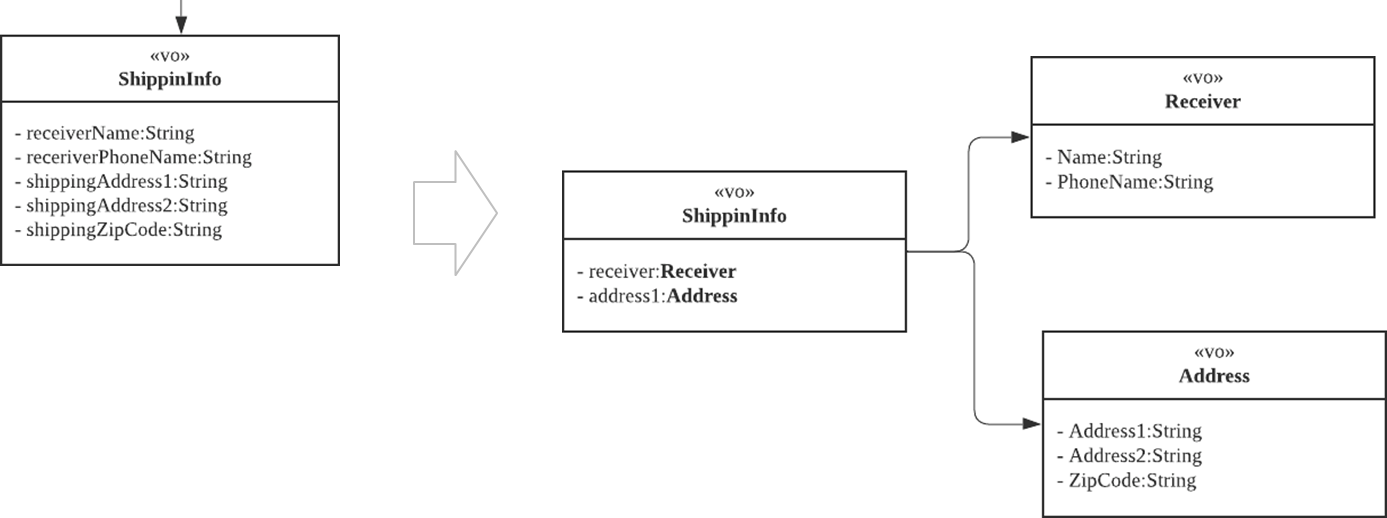
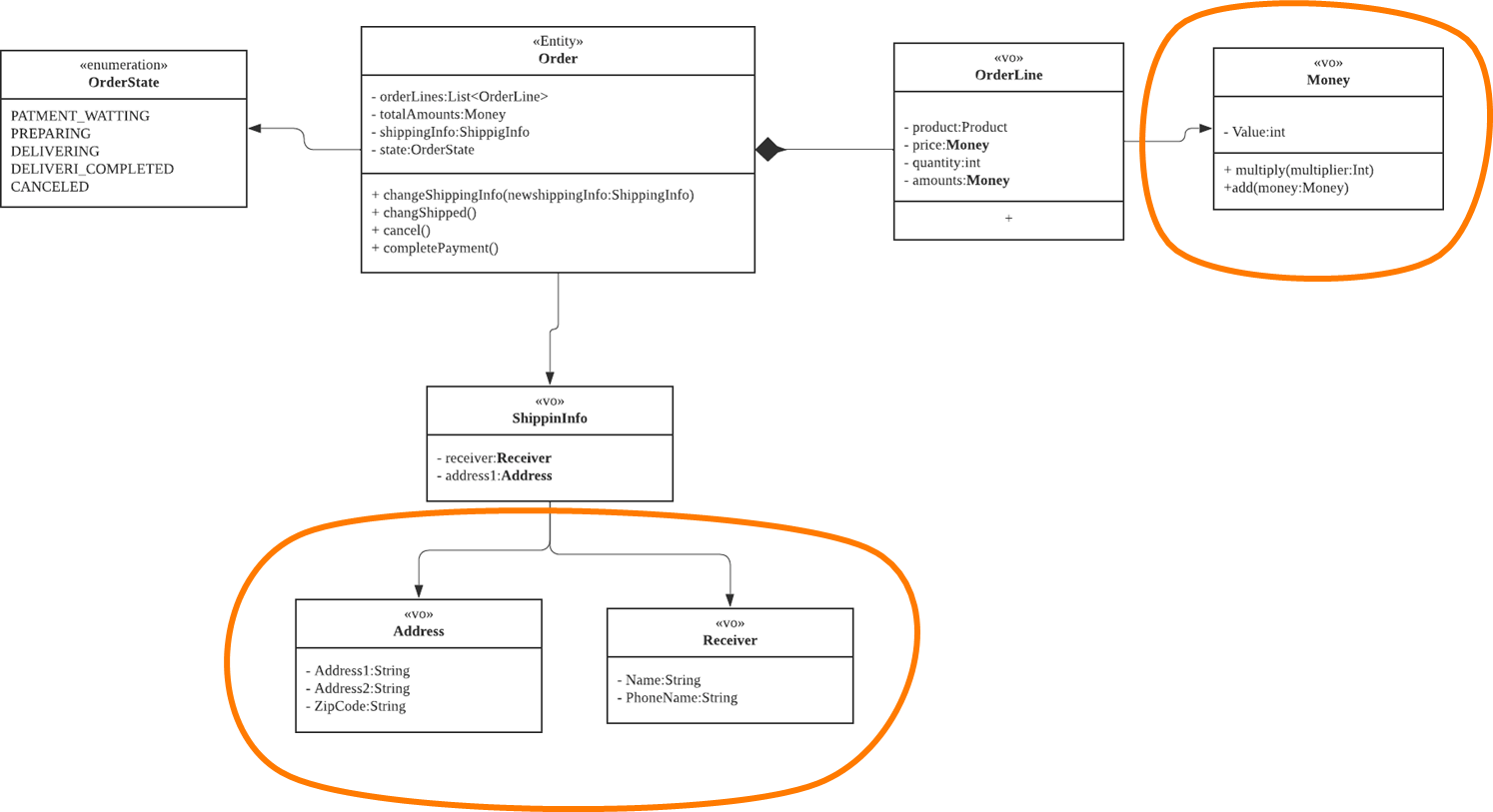
- 가독성 있는 로직을 구현할 수 있다.
- Order 메서드 안에서는 하위 VO 객체에게 메시지를 보낸다.
- 이 큰 덩어리가 Aggregate가 된다.
- Order가 Aggregate Root가 된다.
- Entity이자 Aggregate Root가 된다.
- 하위 VO들은 Aggregate Root와 생명주기가 같다.
✔️ Aggregate
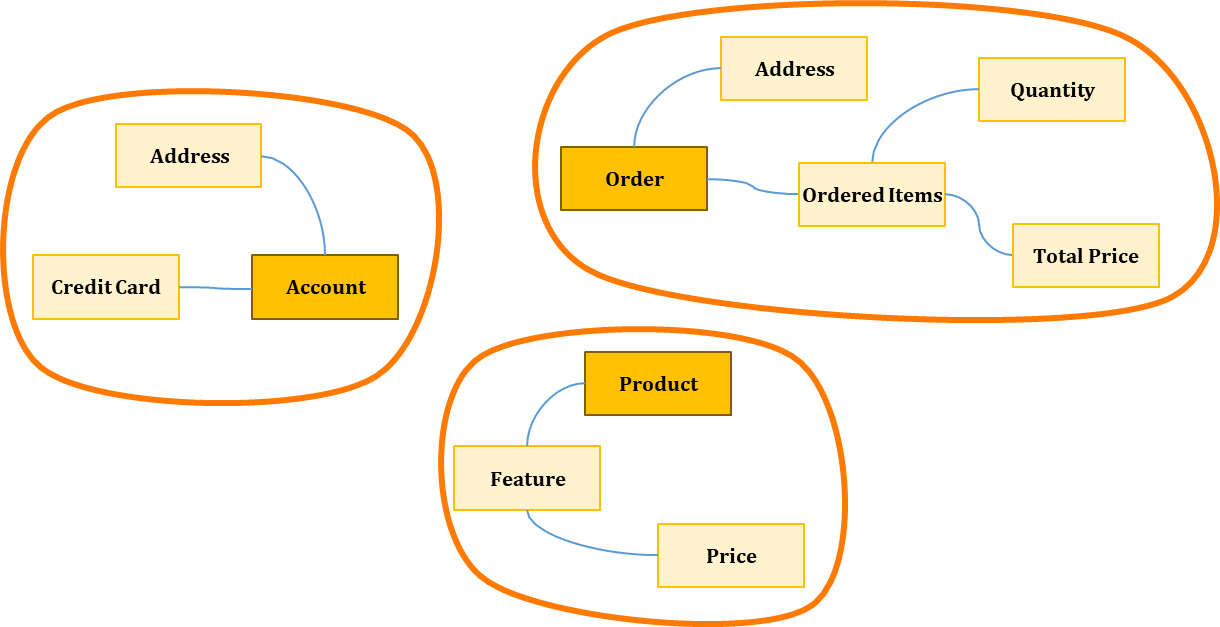
- 관련 객체를 하나로 묶은 군집
- Aggregate는 Entity, 목적은 데이터 일관성을 보호, 데이터 변경 시 Aggregate 단위로 처리
- Aggregate Root를 통해 Aggregate 내의 다른 Entity 및 VO 접근
- 데이터 변경의 단위, 트랜잭션 단위가 되는 연관된 객체 묶음
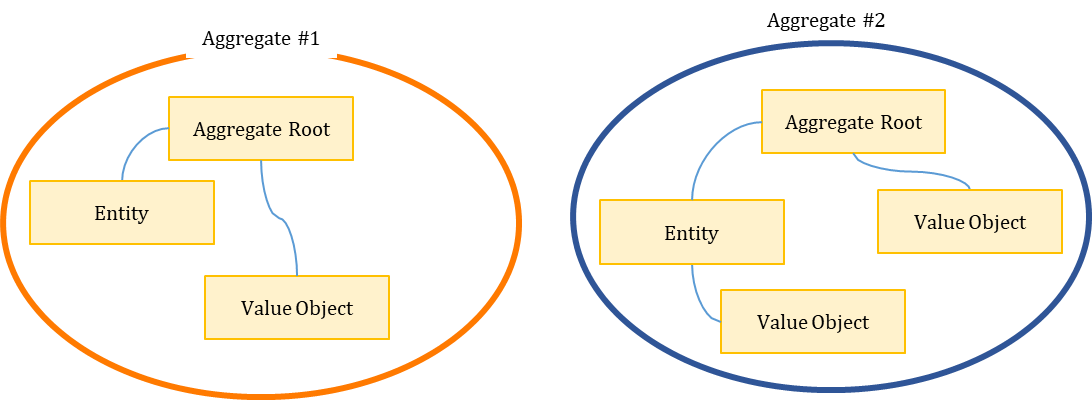
설계 고려사항 #1
- 하나의 Transaction에서는 하나의 Aggregate만 수정함
- Transaction 일관성과 성공을 보장하도록 Aggregate 구성요소들을 설계해야 함
특징
- 각 Aggregate 은 일관성 있는 Transaction 경계를 형성함
- 즉, Transaction 제어가 DB에 Commit 될 때, 한 Aggregate 내의 모든 구성요소들은 비즈니스 규칙을 따르면서 일관성 있게 처리되어야 함
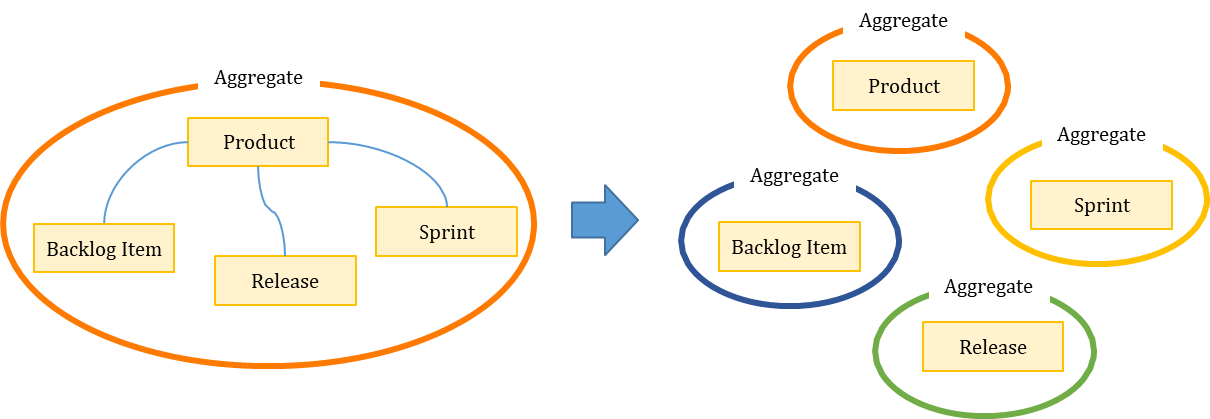
설계 고려사항 #2
-
하나의 일을 잘 수행할 수 있도록 작게 설계해야 함
-
작게 설계할 수록 성능이 좋고 확장에 용이함, 변경사항 Commit할 때 문제도 거의 발생되지 않음
-
큰 Aggregate의 문제점
- 시간이 지날 수록 하위의 객체의 인스턴스의 증가가 결국 엄청난 크기로 불어날 수 있음
-
따라서 하나의 일을 잘 수행할 수 있는 작은 Aggregate로 분리해야 함
-
Entity 가 여러 개로 구성된 Aggregate는 바람직하지 않다.
Aggregate 안에 Entity가 하나일지라도 잘게 쪼개는게 의미가 있다.
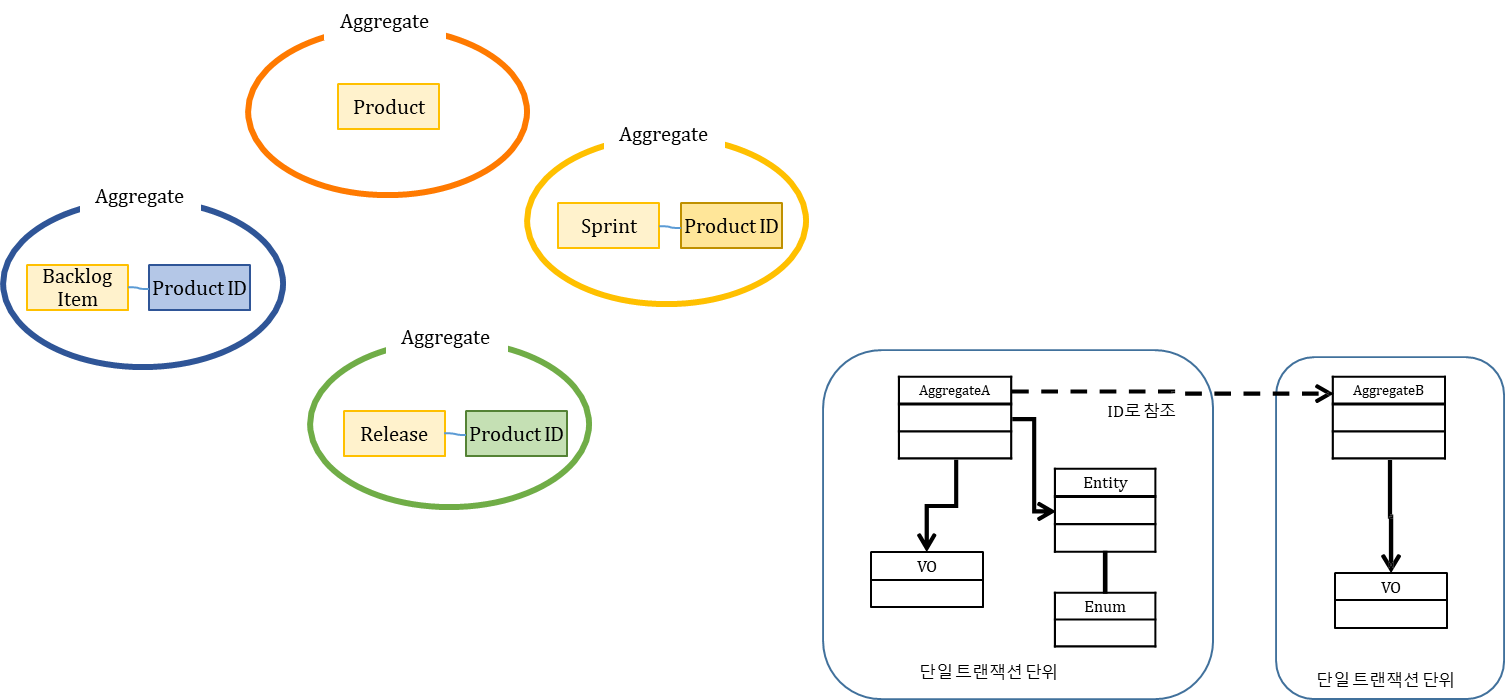
설계 고려사항 #3
- 한 Aggregate 에서 다른 Aggregate 의 참조는 식별자(ID)를 통해서만 참조해야 함
- 하나의 Transaction 내에서 여러 개의 Aggregate 이 수정되는 것을 방지할 수 있음
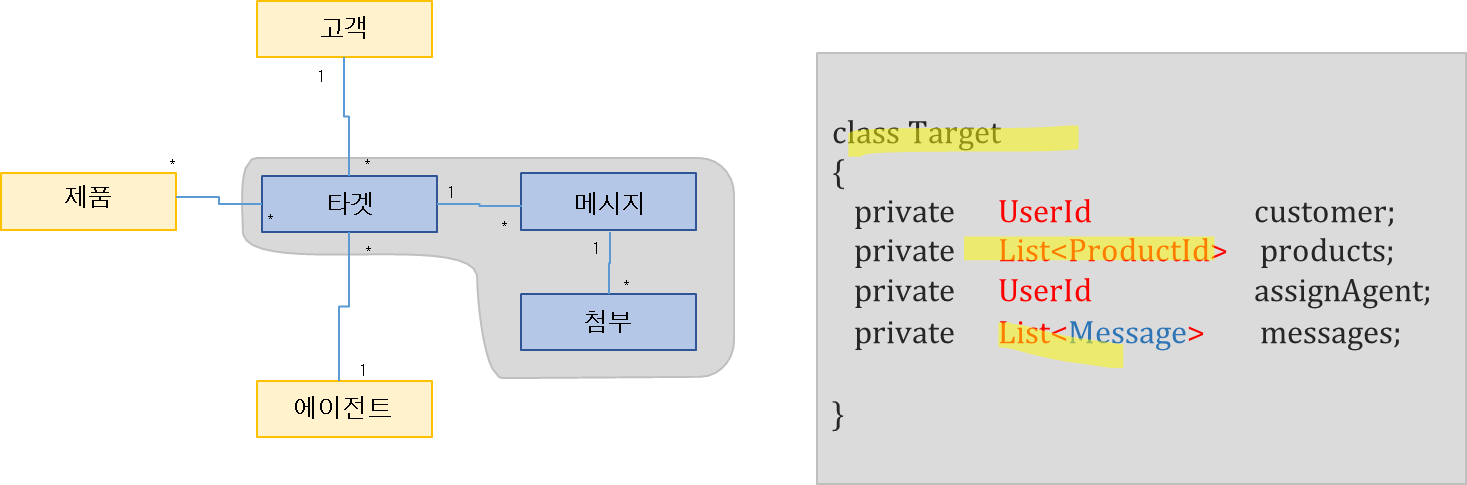
- 타겟 , 메시지, 첨부 가 아래와 같이 같은 Aggregate로 묶여 있음.
- 타겟 이 고객 , 제품 , 에이전트 를 모두 직접 참조하지 않고 식별자를 통해서 참조, 식별자는 VO로 작성됨
- 같은 Aggregate내에 있는 메시지 만 직접 참조하고 있음.
- Target, Message는 같은 Aggregate 안에 있기에 직접 Class 참조
- Target ↔ 고객, 제품, 에이전트는 ID를 통해서 간접 참조를 하고 있다
(다른 Aggregate랑)
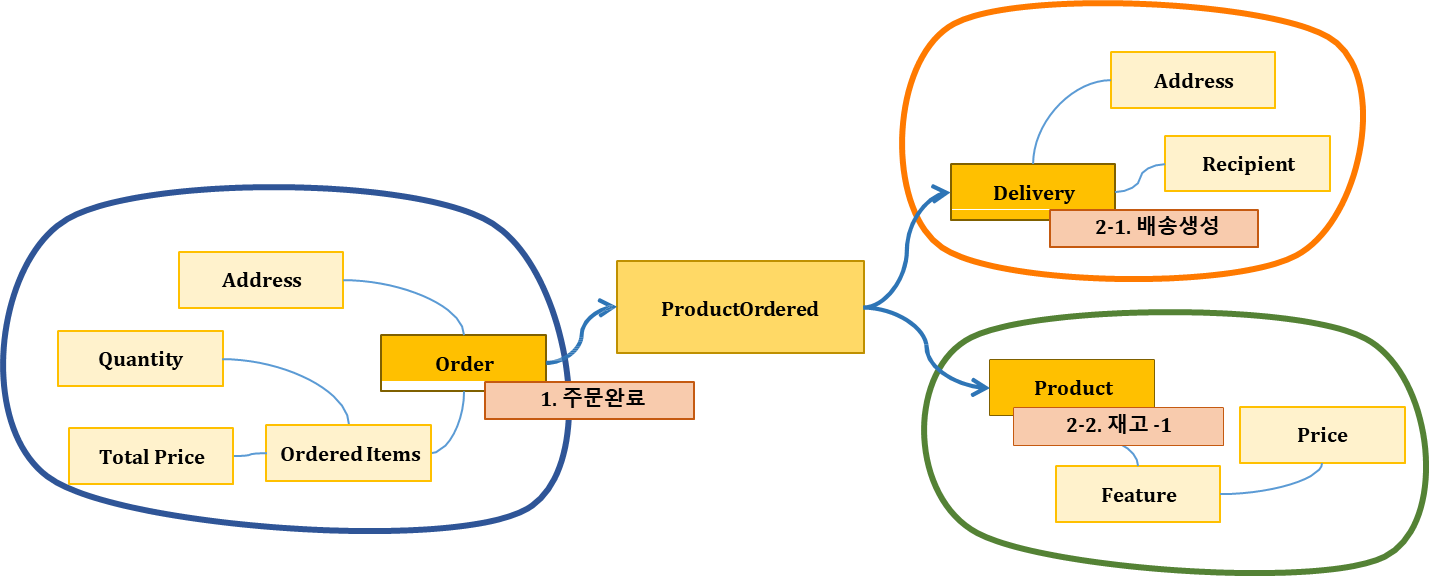
설계 고려사항 #4
- 하나의 Transaction에서 여러 개의 Aggregate이 갱신되어야 하는 경우,
- 다른 Aggregate 의 갱신은 비동기 통신을 활용해서 결과적 일관성을 맞춰야 함
※ 결과적 일관성‘
-
일관성을 유지시켜야 하는 데이터가 일정시간 다른 데이터와 일치 하지 않을 수도 있지만 어느 시점이 되면 결국 일치하게 된다.
-
BC 간의 일관성을 맞추는데도 Domain Event를 사용하고
-
BC 안의 Aggregate 안에서도 일관성을 맞추는데 Domain Event를 사용한다.
-
BC 단위가 MicroService 단위가 될수도 있고 Aggregate 단위가 Micro Service단위가 될 수 있다.
- ACID 처럼 즉시 일관이 아니더라도, 결국에는 일관성이 일치해진다.
(결과적 일관성)
- ACID 처럼 즉시 일관이 아니더라도, 결국에는 일관성이 일치해진다.
✔️ Domain Event
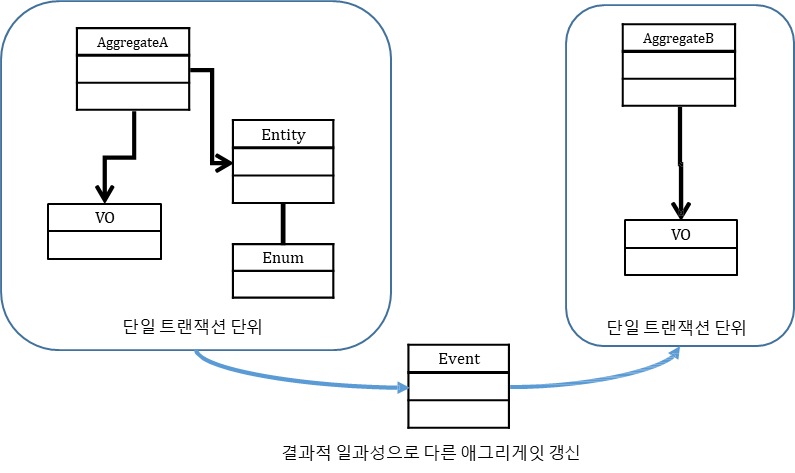
-
비지니스 도메인에서 일어난 중요한 이벤트를 설명하는 메시지
-
‘과거형'으로 명명
-
Aggregate의 퍼블릭 인터페이스의 일부, Aggregate 는 자신의 Domain Event 를 발행
-
Aggregate Entity, VO, Domain Event 개념을 통해서 도메인 모델을 표현할 수 있다.
-
각각의 일관성을 맞추는데 Domain Event는 각각의 일관성 위해 과거형으로 한다.
✔️ Domain Service
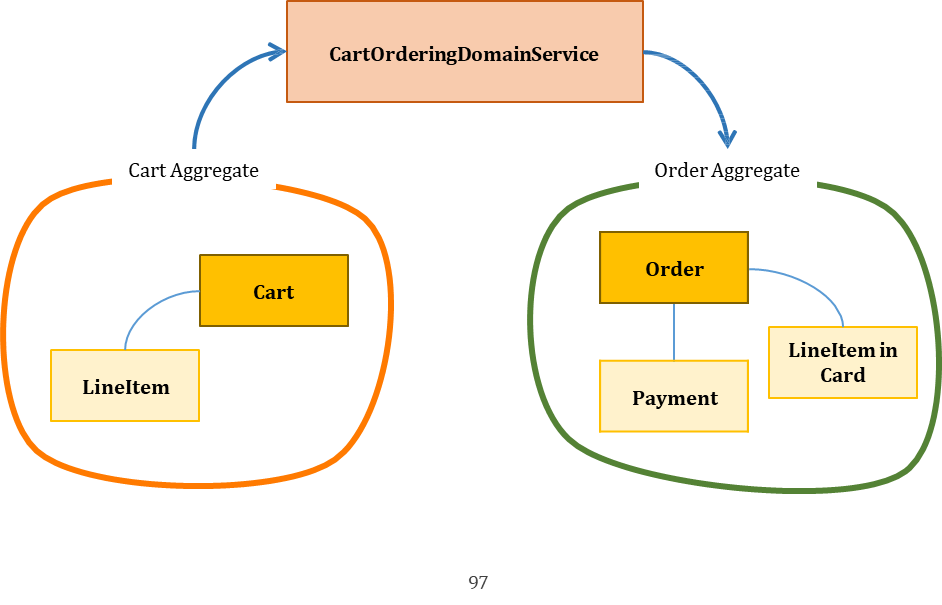
- 특정 Entities/Value Objects에 속하지 않는 도메인 로직 또는 복수의 Aggregate 에 관련된 비지니스 로직 제공
- 어떤 계산이나 분석을 위해 다양한 시스템 구성요소의 호출을 조율
특징
-
상태가 없는 객체(stateless object)
-
비즈니스 처리를 위해 다수의 Aggregate 이 포함되어야 하는 경우 Service 객체를 만들어서 처리함
-
여러 Aggregate의 데이터를 읽는 것이 필요한 계산 로직 구현을 도와줌
-
여러 개의 Aggregate를 통해서 다뤄야 할때 Service를 이용한다
-
여러 Aggregate의 상태 값을 가지고 비즈니스 로직을 풀어야 할 때 사용한다.
(트랜잭션 처리 같은 로직이 들어가지 않는다)
- 추후에 다루지만, 트랜잭션 처리는 응용 서비스에서 책임을 갖는다.
✔️ Repository
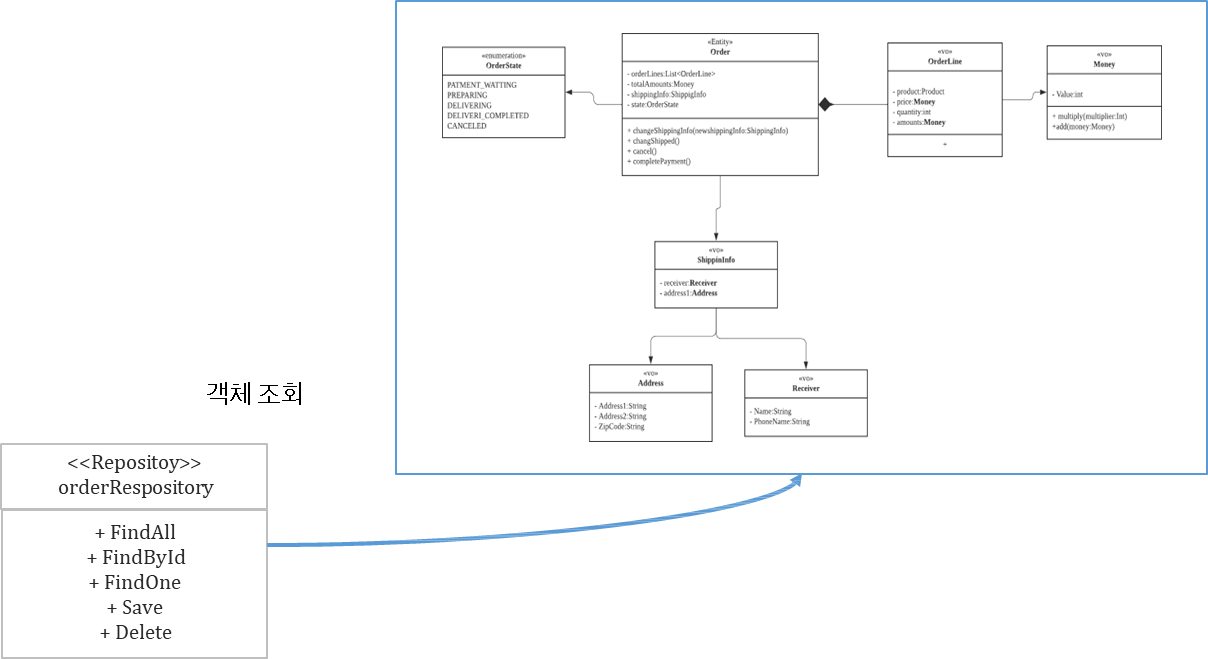
- 정의 : 도메인 모델의 영속성를 처리
- 도메인 모델을 사용하기 위해서 Repository를 통해 도메인 객체(Aggregate Root)를 조회 한 후 도메인 객체의 기능을 실행
- 도메인 객체(Aggregate)에 대한 생명주기, 즉 영속성 관리 (등록, 조회, 수정, 삭제 시 Aggregate의 일관성 유지)
- Spring Data JPA의 Repository 인터페이스
✔️ Factory
정의 : 복잡한 Entity 또는 Aggregate 생성을 전담하는 객체
특징
- 객체의 생성 과정과 관련된 지식이 정리된 객체로, 특정 정보를 Factory에 보내면 결과로 Entity 또는 Aggregate 을 생성함
- 복잡한 생성 로직을 숨겨, 개발자들이 내부의 복잡함에 신경 쓰지 않아도 됨
✔️ 응용 서비스
- 도메인 모델에 속하지 않음.
- Repository 와 밀접한 연관
- 트랜잭션 처리
- 응용 계층
- Aggregate 를 저장하는 메소드, Aggregate Root 식별자로 Aggregate를 조회하는 Method 제공
✔️ 도메인 모델을 사용하는 비지니스 로직 처리 매커니즘
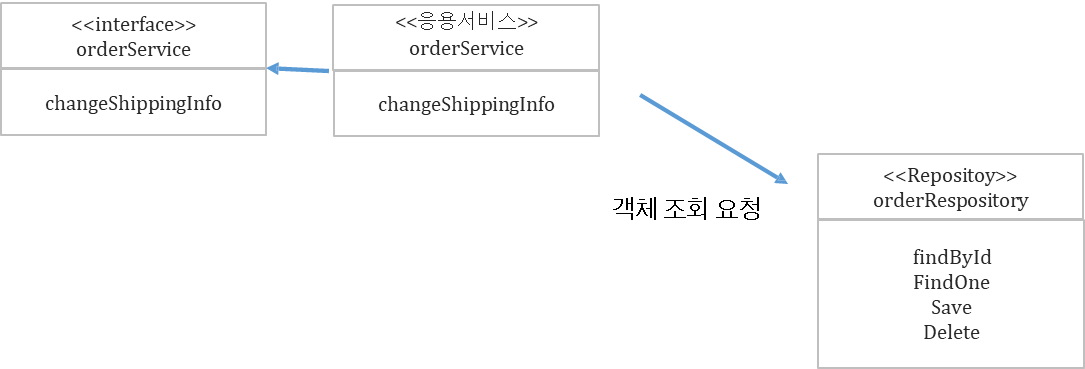
- 응용 서비스에서 1차적으로 객체 조회 요청을 진행한다.
- Repository 에서는 Aggregate Root를 조회한다.
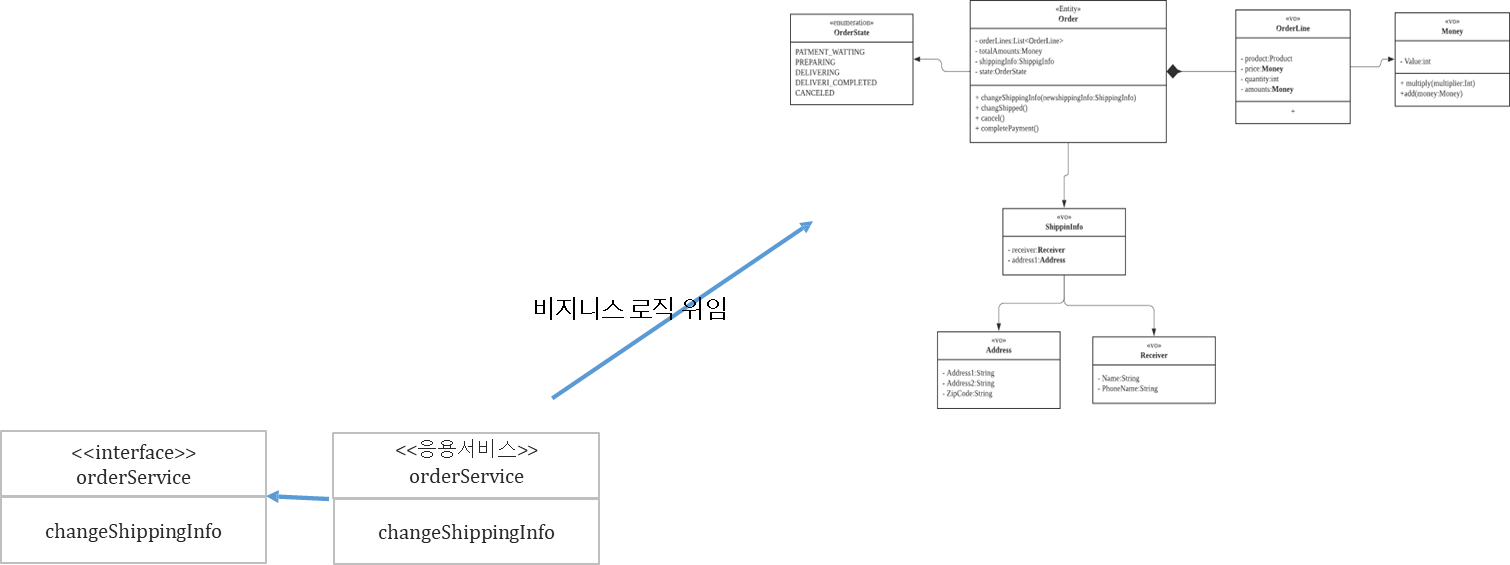
- 조회 된 Aggregate Root로 비지니스 로직을 위임한다. (메시지 전송)
참고
