[TIL] Confusion Matrix(혼동행렬)
회사에서 운영하고 있는 서비스가 점차 확대되어가면서 그동안 수동으로 모니터링을 하고 있었는데 이를 자동화로 바꾸자라는 의견이 나와 자동화 모니터링 시스템을 구축했다. 자동재생이 되지 않는 케이스들을 리스트업하고 그 조건에 부합하면 개발팀에게 이메일을 발송해 조취를 취하는 형식으로 구축하기로 했었다.
하지만 설정을 잘못 해놓은 바람에 무한 알람지옥에 빠지게 되었고, 이는 양치기 소년과 같이 너무 많은 메일로 인해 정작 정말로 필요한 정보를 놓치게 되는 문제점에 직면했다.
이 문제점을 개선하기 위해 고민하다가 혼동행렬에 대해 알게 되었는데 이는 모니터링 동작을 하는 데몬성 프로그램인 경우 이를 고려해봐야 하기에 기록해보고자 한다.
💡 데몬성 프로그램이란
멀티태스킹 운영 체제에서 데몬은 사용자가 직접적으로 제어하지 않고, 백그라운드에서 돌면서 여러 작업을 하는 프로그램을 말한다.
- 윈도우의 서비스 같은 개념
- 일반적으로 프로세스의 형식으로 실행되며 데몬이라는 표시를 위해 뒤에는 d가 붙는다.
ex) syslogd- 서버측면의 네트워크 서비스를 처리하는 프로그램
- 대개 관리자 권한으로 실행되어 네트워크 요청이나 하드웨어 동작 등 여러 기능을 담당하며 다양한 목적으로 사용
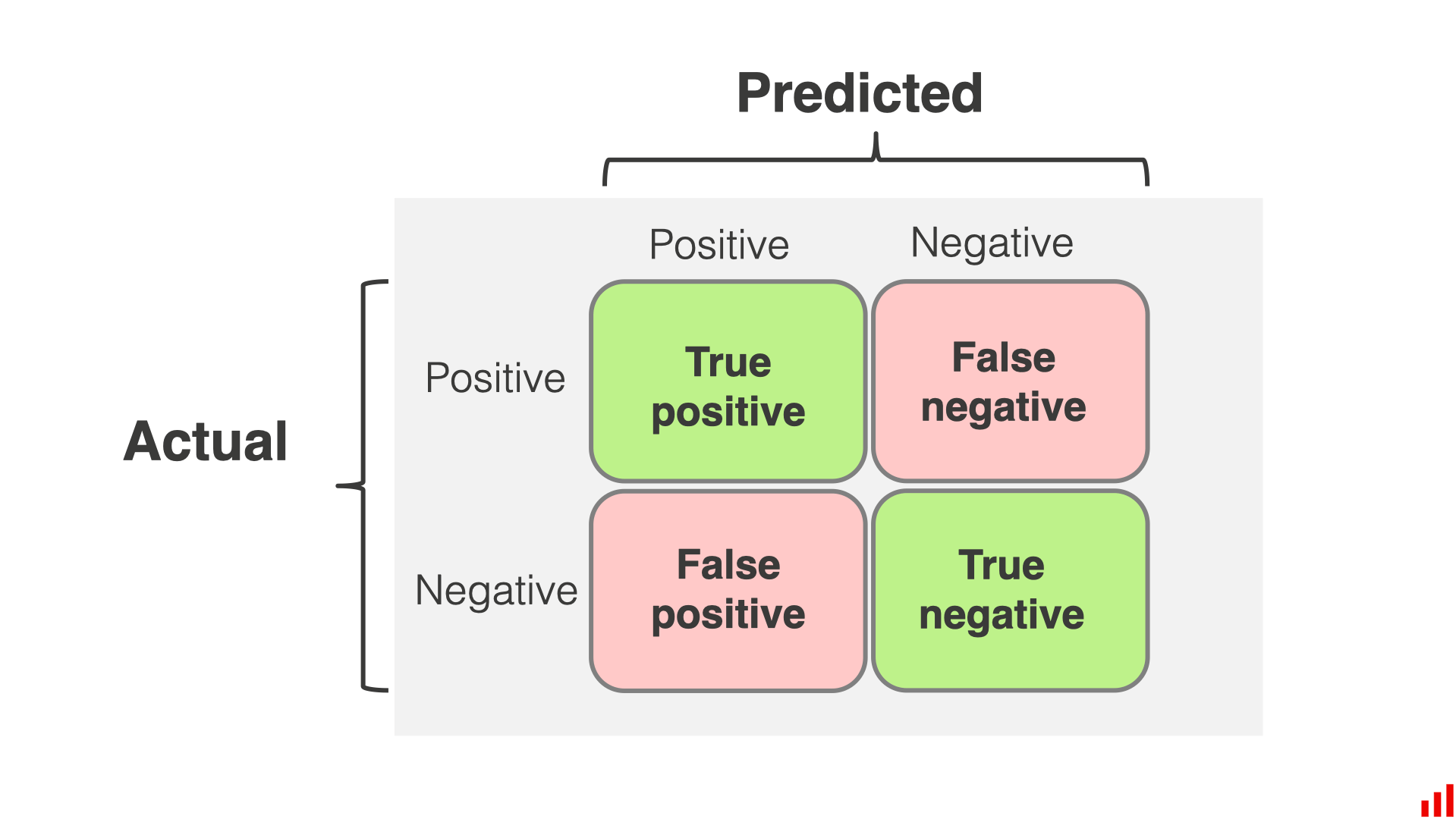
위 표와 같이 Confusion matrix(혼동 행렬)는 분류 모델의 예측 결과를 평가하는 데 사용되는 표 이다. 이는 정확도(accuracy) 외에도 모델의 성능을 다양한 측면에서 평가할 수 있도록 도와준다.
혼동 행렬은 일반적으로 이진 분류(binary classification)에 대해 설명된다. 이 경우, 분류 모델은 두 개의 클래스 중 하나에 속하는 샘플을 예측하려고 한다. 예를 들어, 암 진단 분류 모델은 종양이 악성(malignant)인지 양성(benign)인지 예측하려고 할 수 있다.
이진 분류의 혼동 행렬은 다음과 같이 4개의 항목으로 구성된다.
True Positive (TP): 실제 클래스가 양성이고, 모델이 양성으로 예측한 샘플 수
False Positive (FP): 실제 클래스가 음성이지만, 모델이 양성으로 예측한 샘플 수
False Negative (FN): 실제 클래스가 양성이지만, 모델이 음성으로 예측한 샘플 수
True Negative (TN): 실제 클래스가 음성이고, 모델이 음성으로 예측한 샘플 수
이러한 항목을 다음과 같이 표로 나타낼 수 있다.

각각의 항목은 모델의 예측 결과와 실제 레이블의 일치 여부에 따라 분류된다. 이를 바탕으로 다양한 성능 지표를 계산할 수 있으며, 이러한 지표를 통해 모델의 예측력을 평가할 수 있습니다. 아래 예시를 통하여 자세히 설명하고자 한다.
