- 군데 군데 chatGPT에서 가져온 내용들이 있습니다.
1. 구글 코랩
- 설치가 필요없는 클라우드에서 실행되는 무료 Jupyter 노트북 환경
- https://colab.research.google.com/
💻 설치 필요 없음
→ 로컬에 Python, 라이브러리 설치 안 해도 됨
📓 주피터 노트북(Jupyter Notebook) 기반
→ 코드 + 설명 + 결과를 한 화면에서 작성
☁ 구글 서버에서 실행
→ 내 PC 사양과 무관
🚀 GPU / TPU 지원 (머신러닝에 매우 유용)
🔗 Google Drive 연동
→ 파일 저장, 공유 쉬움
🤝 협업 가능
→ 여러 명이 같은 노트북을 동시에 수정
코멘트: 항상 그렇지만 새로운 것을 접하면 즐거운 마음이 된다. 코랩이라고 해서 한국과 관련이 있나 했는데 의외로 콜라보의 줄임말 이었다.
2. 형상관리기법
形狀管理, Configuration Management
- 소프트웨어나 문서의 변경 사항을 체계적으로 관리하는 방법
변경 이력 추적, 버전 관리, 협업 충돌 방지, 안정적인 품질 유지, 언제든 이전 상태로 복구 가능
관리 도구:
Git
GitHub / GitLab / Bitbucket
SVN (구버전)
공부를 위한 깃프로: https://git-scm.com
3. 파이썬 기본문법 + 알파
스타일 비교
C 언어 스타일의 문자열 포맷팅과 파이썬 스타일의 문자
name = "minsu"
score = 90
print("%s의 점수는 %d 점입니다." % (name, score))
-> (name, score)앞의 %는
% 는 "포맷 연산자"
왼쪽 문자열 안의 서식 지정자(placeholder)를 오른쪽 값으로 치환(substitute) 함
포맷 문자열에 2개의 서식 지정자가 있기때문에 튜플로 값 전달
- 서식 지정자 - %s = 문자열(string), %d = 정수(decimal integer), %f = 실수(float)
파이썬 3부터 지원하기 시작한 문자열 클래스의 포맷 메서드 사용 예
name = "minsu"
score = 90
print("{}의 점수는 {} 점입니다.".format(name,score))
파이썬 3.6부터 지원하는 f-string 사용 예
name = "minsu"
score = 90
print(f"{name}의 점수는 {score} 점입니다.")
f-string을 사용하는 이유
가독성이 압도적으로 좋음 (+ 등을 사용해서 연결하지 않아도 되므로)
코드가 짧고 실수가 줄어든다 (+연결, str() 변환, 순서 맞추기가 필요없음)
표현식을 바로 사용할 수 있음 (계산 함수 호출까지 문자열 안에서 처리 가능)
f"Next year: {age + 1}"
f"Upper: {name.upper()}"포맷팅이 직관적
성능이 좋음 (내부적으로 더 효율적, format() 이나 % 방식보다 빠른 편임)
간단 예시
f-string -> f"Hello {name}"
format -> "Hello {}".format(name)
% -> "Hello %s" % name
파이썬
특문 출력
두개를 적는다
data = 3
fmt = "{{ {} }}".format(data)
print(fmt)
data = 3
fmt = f"{{ {data} }}"
print(fmt)
자릿수채우기
a = 3
mtstr = f"{a:02d}"
print(mystr)
전체구조:
{value: [fill][align][sign][#][0][width][.precision][type]}02d는 이 중 일부를 사용한 것
0 0으로 채우기 (zero padding)
2 전체 폭(width)
d 정수(decimal) 타입
symbol = "BTCUSDT"
print(f"{symbol:<10}")print(f"{symbol:10}") 에서는 콜론 뒤에 스페이스가 허락되지 않는 이유
겉으로 보면 "공백 + 10 -> 폭 10" 처럼 보이지만 파이썬은 첫글자 ' '를 fill로 보고 다음글자 1을 align 으로 인식하려는데 align 문자가 아니므로 에러 발생
symbol = "BTCUSDT"
print(f"{symbol: 10}")
ValueError: Invalid format specifier규칙
fill 은 반드시 align 문자(< > ^ =)와 함께 2글자로 해석됨
align 이 없으면 → fill 자체가 존재할 수 없음
기본 fill 은 공백 ' '
기본 align 은 오른쪽 정렬 >
실수(float)
0.nf의 형식으로 소수점 자리 설정
a = 3.141592
mystr = f"{a: 6.2f}"
print(mystr)
3.14앞에 2개의 공백을 넣고 (전체가 6 width이므로) 두 자리의 소수점을 넣어 표시
' ' → fill
'6' → width (정상)
'.2' → precision
'f' → type
사용 예시
f"{symbol: >10}" # 오른쪽
f"{symbol: <10}" # 왼쪽
f"{symbol: ^10}" # 가운데
Immutable과 Mutable
Immutable => 수정 불가능: int, float, str, tuple
Mutable => 수정 가능: list, dict
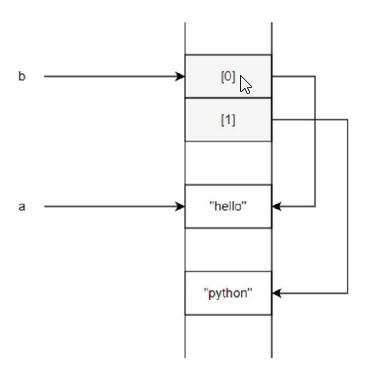
a = "hello"
b = ["hello", "python"]
print(id(a))
print(id(b))
print(id(b[0]))140704125497680
140703172790656
140704125497680
id(a)와 id(b[0])는 같은 객체를 바인딩하므로 같은 주소가 출력되나
리스트 자체 id(b)는 다른 주소가 나옴
파이썬의 리스트
a = "python2"
id(a)
a = "python3"
id(a)이 경우 python2라는 문자열 객체는 아무도 자신을 참조하지 않으므로 자동으로 메모리에서 소멸됩니다.
다른 언어에서는?
Python과 Java는 “도달 불가능하면 수거”,
C++는 “스코프를 벗어나면 파괴”,
C는 “개발자가 직접 해제”.
“python2 문자열 객체가 자동으로 소멸된다”는 거동은 Python과 Java에서는 개념적으로 맞지만, C와 C++에서는 동일하지 않다.
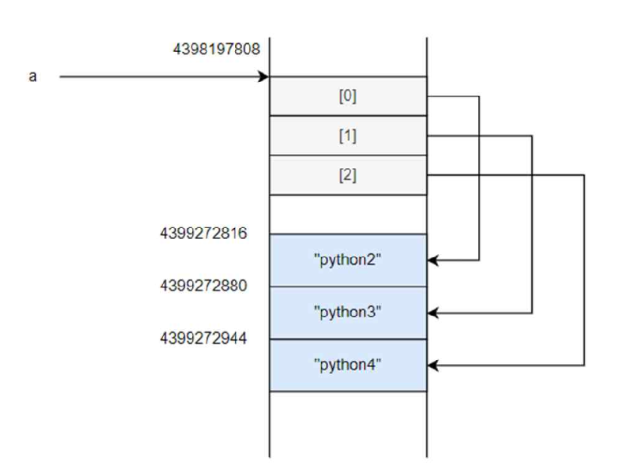
리스트의 수정
a = ["python2", "python3"]
print(id(a))
a.append("python4")
print(a)
print(id(a))리스트에 새로운 아이템을 추가해도 리스트 객체의 시작 주소값은 변하지 않음
비교연산자와 is 연산자
두 값을 비교할 때 ==
동일한 주소에 할당된 객체임을 비교하려면 is
a = 1000
b = 1000
print(id(a))
print(id(b))
print(a==b)a==b는 같은 값을 참조하므료 True 이지만 is 는 False
문자열 인터닝 (String Interning)
파이썬은 일부 문자열을 재사용:
문자열인 경우에는 같은 주소값을 가질 수 있음 (하지만 언제나 보장되지는 않음 - 구현 의존)
a = "1000"
b = "1000"
print(id(a))
print(id(b)is 사용 시 주의점
✔ 값 비교 → ==
✔ None 비교 → is
✔ 불변 객체 비교 → ==
✔ 캐싱 기대 금지
✔ is 결과에 로직 의존 ❌
정수의 경우
256까지에 대해서는 이미 해당 값이 존재하면 기존의 객체를 바인딩
a = 3
b = 3
print(id(a), id(b))
print(a==b)
print(a is b)11654440 11654440
True
True
리스트 컴프리핸션
- 리스트를 생성하는 간단한 표현
0~9까지 중에서 짝수를 출력하는 프로그램을 파이썬으로:
even_num = []
for i in range(10):
if i % 2 == 0:
even_num.append(i)
print(even_num)[0, 2, 4, 6, 8]
리스트 컴프리핸션을 사용하면:
even_num = [i for i in range(10) if i % 2 == 0]
print(even_num)컴프리핸션 구조:
[결과값 for 변수 in 반복가능객체 if 조건]
처음의 i는 결과값이므로 꼭 써야함
결과값에는 i 뿐만 아니라 다른 것(ii, i2, str(i) etc.) 도 가능
pow2_nums = [i*i for i in range(10)]튜플 - 패킹(packing)
리스트는 대괄호 [] 튜플은 소괄호 ()
패킹 - 여러 개의 독립된 값을 하나의 객체(튜플) 안에 “포장(pack)”
a = 1,2
b = (1, 2)
print(a, type(a))
print(b, type(b))(1, 2) <class 'tuple'>
(1, 2) <class 'tuple'>
파이썬에서 튜플을 만드는 진짜 표식은 괄호 ()가 아니라 “콤마 ,”이기 때문에 이 코드에서 a는 리스트가 아니라 튜플이 됨.
리스트로 만들기 위해서는 반드시 []가 필요.
튜플
1, 2 # tuple
(1, 2) # tuple
(1,) # tuple (1개짜리)
튜플 아님
(1) # int
a = (1) # int
b = (1,) # tuple패킹 예제:
변수에 할당
t = 10, 20
print(t) # (10, 20)
print(type(t)) # tuple함수 반환값
def calc():
return 1, 2, 3 # 튜플 패킹
result = calc()
print(result) # (1, 2, 3)여러 값 동시에 저장
data = "Alice", 30, True튜플 - 언패킹(unpacking)
| 개념 | 예시
| 패킹 | t = 1, 2, 3
| 언패킹 | a, b, c = t
scores = (1,2,3,4,5,6)
low, *others, high = scores
print(others)[2, 3, 4, 5]함수호출
함수에서 리턴할 때 패킹
def hap(num1, num2, num3, num4):
return num1+num2+num3+num4
scores = (1,2,3,4)
result = hap(scores[0], scores[1], scores[2], scores[3])
print(result)10
위의 함수 호출코드를 튜플 언패킹으로 간소화하면:
def hap(num1, num2, num3, num4):
return num1+num2+num3+num4
scores = (1,2,3,4)
result = hap(*scores)
print(result)zip 과 dictionary
zip
zip은 두 개의 리스트를 묶을 때 사용
name = ['merona', 'gugucon']
price = [500, 1000]
z = zip(name, price)
print(list(z))[('merona', 500), ('gugucon', 1000)]- list() - list(iterable)
파이썬 내장 타입이자 생성자(constructor)
전달받은 iterable을 리스트로 변환
만약 위에서 print(z)를 하면 결과: <zip object at 0x7ff8028f5700>
for 문을 사용할 때
name = ['merona', 'gugucon']
price = [500, 1000]
for n, p in zip(name, price):
print(n, p)merona 500
gugucon 1000dictionary
딕셔너리 생성
1) 보통 생성 방법
아이스크림1 = {"메로나": 500, "구구콘": 1000}
print(아이스크림1)
{'메로나': 500, '구구콘': 1000}2) 만약 키가 문자열인 경우:
아이스크림2 = dict(메로나=500, 구구콘=1000)
print(아이스크림2)
{'메로나': 500, '구구콘': 1000}3) 키와 값을 하나의 튜플로 저장하고 -> 튜플을 리스트로 저장 -> 이를 딕셔너리로
아이스크림3 = dict([('메로나', 500), ('구구콘', 1000)])
print(아이스크림3)
{'메로나': 500, '구구콘': 1000}* 이런 사용 방법을 하는 이유
1) 순서(order)를 유지하거나 제어하고 싶을 때
- 리스트 단계에서는 순서가 명확
중간에서:
정렬
필터링
우선순위 조정 가능
pairs = [
("b", 2),
("a", 1),
("c", 3)
]
d = dict(pairs)
2) 같은 키가 여러 번 등장할 수 있을 때 (중간 단계)
딕셔너리는 중복 키를 허용 하지 않음
리스트+튜플은 중복 키 허용
pairs = [
("a", 1),
("a", 2),
("b", 3)
]
3) 외부 데이터 포맷(JSON, CSV, DB)과의 호환
csv 예
key,value
lang,ko
count,3파일/네트워크 데이터는 행(row) 기반
(key, value) 튜플 리스트가 자연스러움
4) dict 생성자를 바로 쓰기 위한 표준 인터페이스
dict(iterable_of_pairs)파이션에서 dict()는 (key, value) 쌍의 iterable을 받음
dict(zip(keys, values))keys = ["a", "b"]
values = [1, 2]
pairs = list(zip(keys, values))5) 가공, 검증, 변환을 딕셔너리 이전 단계에서 하고 싶을 때
pairs = [
(k.lower(), int(v))
for k, v in raw_data
if v.isdigit()
]
6) 불편 구조가 필요할 때 (듀플의 장점)
키-값 쌍이 실수로 수정되는 것을 방지
pairs = tuple([
("a", 1),
("b", 2)
])
| 단계 | 역할 |
|---|---|
| 튜플 | 원자적 key-value 쌍 |
| 리스트 | 수집, 정렬, 필터, 중복 허용 |
| 딕셔너리 | 빠른 조회, 최종 구조 |
실제로 많이 쓰이는 곳:
dict(zip(keys, values))
API 응답 전처리
CSV → dict 변환
SQL 결과 → dict
설정 파일 파싱
로컬라이제이션 리소스 변환
dictionary 에서 zip의 활용법
두 개의 서로 다른 리스트에서 하나를 key로 하나를 value로 하여 딕셔너리를 표현하면 좋을 때가 있음
name = ['merona', 'gugucon']
price = [500, 1000]
icecream = dict(zip(name, price))
print(icecream)
{'merona': 500, 'gugucon': 1000}setdefault 메서드
딕셔너리에서 자주 사용하는 메서더에는 keys, values, items가 있음
setdefault는 딕셔너리에 key를 추가할 때 초기값을 설정 가능
data = {}
ret = data.setdefault('a', 0) # key로 a를 추가하고 value 0을 설정 setdefault는 현재 value 값 리턴
print(ret, data)
ret = data.setdefault('a', 1) # 이미 key가 있는 경우 setdefault는 현재 value 값 리턴
print(ret, data)
0 {'a': 0}
0 {'a': 0}dictionary 원소 개수
data = ["BTC", "BTC", "XRP", "ETH", "ETH", "ETH"]
for k in set(data):
count = data.count(k)
print(k, count)
ETH 3
BTC 2
XRP 1dictionary 컴프리헨션
zip으로 묶인 각 원소를 k, v로 바인딩한 후 그대로 key, value로 적어주기
name = ['merona', 'gugucon']
price = [500, 1000]
icecream = {k:v for k, v in zip(name, price)}
print(icecream)
{'merona': 500, 'gugucon': 1000}
dict(zip(name, price))가 더 간단하고 가독성도 좋으나 아이스크림 가격이 2배 오른 icecream2 딕셔너리를 생성해야 한다면 딕셔너리 컴프리핸션이 조금 더 간단할 수도 있음
name = ['merona', 'gugucon']
price = [500, 1000]
icecream2 = {k:v*2 for k, v in zip(name, price)}
print(icecream2)
{'merona': 1000, 'gugucon': 2000}조건문 추가하기
name = ['merona', 'gugucon', 'bibibig']
price = [500, 1000, 600]
icecream = {k:v for k, v in zip(name, price) if v < 1000}
print(icecream)
{'merona': 500, 'bibibig': 600}네임드 튜플(namedtuple)
튜플의 원소들이 어떤 것인지에 대한 정보를 포함할 수 있음
1) 클래스를 정해 프로퍼티를 추가하는 경우:
class Book:
def __init__(self, title, price):
self.title = title
self.price = price
mybook = Book("파이썬을 이용한 비트코인 자동매매", 27000)
print(mybook.title, mybook.price)
파이썬을 이용한 비트코인 자동매매 270002) 그냥 단순히 튜플을 사용하는 경우:
mybook2 = ("파이썬을 이용한 비트코인 자동매매", 27000)
print(mybook2[0], mybook2[1])
파이썬을 이용한 비트코인 자동매매 27000네임드튜플은 클래스처럼 객체 생성이 가능
튜플은 immutable 타입이기 때문에 변경할 필요없는 데이터에는 좋지만 딕셔너리와 비교하면 어떤 값에 대한 label 인지 알 수 없음. 1) 처럼 할 수도 있지만 클래스를 만들어야해서 번거로울 수 있음
- 네임드튜플을 통해 생성한 객체는 결국 튜플처럼 immutable -> 값 수정 불가능
mybook3.price = 25000에러 발생: AttributeError: can't set attribute
- 튜플 처럼 정수 값을 통해 인덱싱 가능
print(mybook3[0], mybook3[1])3) 네임트튜플을 사용하는 경우
from collections import namedtuple
Book = namedtuple('Book', ['title', 'price'])
mybook3 = Book("파이썬을 이용한 비트코인 자동매매", 27000)
print(mybook3.title, mybook3.price)
파이썬을 이용한 비트코인 자동매매 27000네임드튜플의 언팩킹
def print_book(title, price):
print(title, price)
print_book(*mybook3)
파이썬을 이용한 비트코인 자동매매 27000파일다루기 - 인코딩
ASCII - 0~127의 숫자를 영어 알파벳과 자주 사용하는 특수문자에 붙임
euc-kr - 완성형 - 한글에서 많이 사용하는 2350 글자에 번호 할당
cp949 - 완성형 - 마이크로소프트에서 사용한 인코딩. 11720 글자에 번호 할당, 윈도우 운영체제의 기본 한글 인코딩 방식
utf-8 - 조합형 - 모음과 자음에 번호를 할당하는 조합 방식, 웹페이지의 기본 인코딩 방식
