벡터와 스칼라
스칼라(scalar): 길이, 넓이, 질량, 온도 - 크기가만 주어지지만 완전히 표시되는 양
벡터(vector): 속도, 위치이동, 힘 - 크기뿐만 아니라 방향까지 지정하지 않으면 완전히 표현할 수 없는 양
벡터는 크기와 방향을 갖는 유향선분 - 2차원, 3차원 공간의 벡터는 화살표로 표현 가능
벡터
- 시작점과 끝점이 같아서 크기가 0인 벡터 => 영벡터 (크기가 0이므로 방향은 임의의 방향)
- 크기와 방향이 같은 벡터는 모두 같은 벡터이며, 만일 벡터의 시작점을 원점으로 한다면 그 벡터는 끝점의 좌표로 유일하게 나타낼 수 있다.
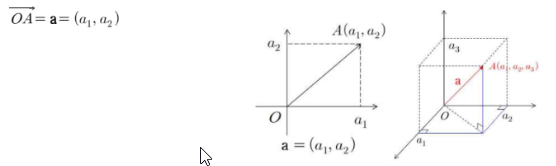
n개의 실수의 순서조를 n차원 벡터(n-dimensional vector)라 하고

로 나타낸다. 이 때 실수 () 괄호안의 x들을 x의 성분이라 한다.
1차원 벡터 -> (한 개의 숫자, 한 방향), v=(x)
2차원 벡터 (평면) -> 예) 서로 수직인 독립 방향이 2개, (두 개의 숫자, 두 개의 독립 방향), v=(x,y)
3차원 벡터 (공간) -> 세 개의 숫자, 세 개의 독립 방향, v=(x,y,z)
n차원 벡터 - 기저가 n개인 공간의 벡터
벡터의 상등 (Equality)
벡터의 성분이 모두 같으면 두 벡터는 같다.
n차원 공간
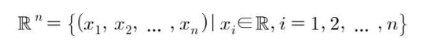
벡터의 연산법칙
Rn의 벡터 x, y, z 와 스칼라 h, k에 대하여 다음이 성립한다.

sagemath 실습
a = vector([1, 2, -3, 4])
b = vector([-2, 4, 1, 0])
print("a = ",a)
print("b = ",b)
print()
print( "a+b=", a+b)
print( "a-b=", a-b)
print( "-2*a=", -2*a)
a = (1, 2, -3, 4)
b = (-2, 4, 1, 0)
a+b= (-1, 6, -2, 4)
a-b= (3, -2, -4, 4)
-2*a= (-2, -4, 6, -8)노름(norm), 벡터의 크기, 길이

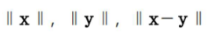
차례대로 x의 노름 (0에서부터의 거리), y의 노름, x에서 y를 뺀 것의 길이 (둘 사이의 거리)
4차원 벡터는 어떻게 생겼나?
1차원 → 선
2차원 → 평면
3차원 → 공간
4차원 → ? (직접 볼 수 없음)
기하학적으로는 4차원 벡터는 서로 직교하는 4개의 방향 성분을 가진 이동
서로 직교한다고 하는 이유는 그렇지 않으면
- 좌표가 서로 섞여버림
- 길이 계산이 복잡해짐
- 피타고라스 법칙이 깨짐
때문에 서로 직교하는 벡터로 정의한다.
(하지만 꼭 직교할 필요는 없다, 그저 계산하기 쉽도록 직교로 가정하는 것일 뿐)
sagemath 실습
a = vector([2, -1, 3, 2])
b = vector([3, 2, 1, -4])
print(a.norm())
print(b.norm())
print( (a-b).norm() )
3*sqrt(2)
sqrt(30)
5*sqrt(2)데이터의 유사도
주어진 데이터가 각 범주와 얼마나 가까운지 (혹은 유사한지) 판단하는 척도로 벡터의 노름은 데이터의 유사도를 판단하는 하나의 기준이 됨.
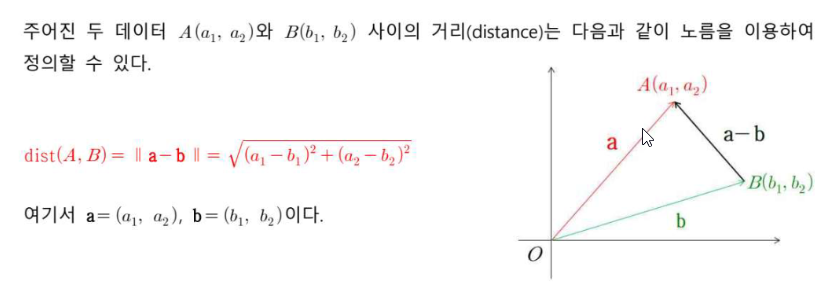
- 거리 (distance)를 활용한 데이터의 유사도
주어진 두 데이터에 대하여, 거리가 가까우면 두 데이터는 유사하고, 거리가 멀면 두 데이터는 관계없다고 판단할 수 있다. 또한 데이터와 어떤 범주와의 거리가 가까우면, 이 데이터는 범주에 속해 있다고 판단할 수 있다.
노름의 특징

세 개의 데이터 A, B, C에 대하여 B는 A와 C 중 어느 데이터에 더 가까운지 판단하시오.
sagemath 실습
a = vector([0, 1, -7, 1])
b = vector([5, 2, -1, 3])
c = vector([-2, 0, -4, 6])
distAB = (a-b).norm()
distBC = (b-c).norm()
print("distAB: ", distAB)
print("distBC: ", distBC)
bool(distAB < distBC)
Share
distAB: sqrt(66)
distBC: sqrt(71)
TrueB는 A와 더 가깝다
벡터의 내적

내적의 성질

- 두 벡터의 거리와, 내적은 다른 것이지만, 두 벡터 x,y 사이의 거리 = 차이 벡터의 노름
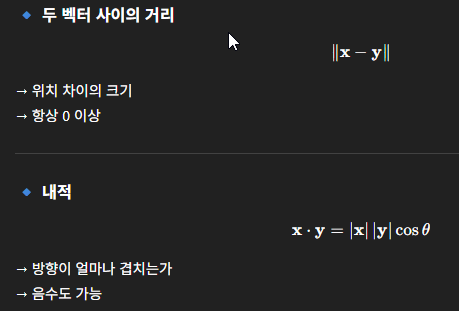
만약 내적이 17인 두 벡터와 14인 두 벡터가 있을 때 17인 벡터 둘이 더 방향이 같다고 할 수 있나
내적은 "방향 + 벡터 길이"가 함께 들어간 값이기 때문에 그렇다고 할 수 없다.

각도(세타)를 보면 14인 벡터가 30도로 더 방향이 비슷하다고 할 수 있다.
그렇기 때문에 데이터 분석에서는 코사인 유사도를 이용한다.
사잇각을 활용한 데이터의 유사도
데이터를 분석하는 사람이 단지 데이터의 패턴(방향)에만 관심이 있는 경우에는 앞서 학습한 (거리) 척도는 데이터의 유사도 분석에 적합하지 않다. 예를 들어, 아래 그림과 같이 주어진 두 데이터 a = (a1, a2)와 b=(b1, b2)의 경우에는 패턴(방향)은 유사하지만 거리는 매우 큰 값을 갖게 되어 거리 척도로는 두 데이터가 유사하지 않은 것으로 판단할 수 있다.
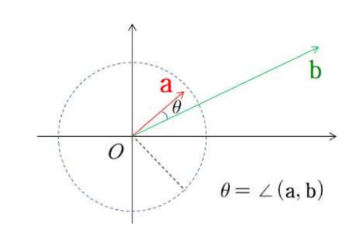
2차원 벡터 x, y의 사잇각 (θ)
- 90 보다 작을 때: 방향이 비슷, 같은 패턴을 가짐, 내적이 양수
- 90 일 때: 내적이 0이므로 유사도가 없음
- 90 보다 클 때: 반대 방향 성향, 한쪽이 크면 다른 쪽은 작음 (역상관), 내적이 음수
내적(dot product)와 사잇각(θ)과 코사인 유사도는 다른 것

코사인 세타를 이용하는 이유
코사인 세타는 얼마나 큰가를 제거(normalization)하고 "얼마나 같은 방향인가"만 측정하기 위해 사용된다.
벡터의 내적과 관련한 "코시-슈바르츠 부등식"

sagemath 실습
a=vector([0, 1, -7, 1])
b=vector([5,2,1,3])
c=vector([-2,0,-4,6])
cos_simAB = a.inner_product(b)/(a.norm()*b.norm()) # 코사인 유사도
cos_simBC = b.inner_product(c)/(b.norm()*c.norm())
print("cos_sim(A,B) = ", cos_simAB.n(digits = 3))
print("cos_sim(B,C) = ", cos_simBC.n(digits = 3))
bool(cos_simAB < cos_simBC)
cos_sim(A,B) = -0.0448
cos_sim(B,C) = 0.0856
True정사영(Projection)

w는 y에서 x 부분을 없앤 것이기 때문에 w=y-p 그러므로 y=p+w, w는 y의 벡터성분


sagemath 실습
x = vector([2, -1, 3])
y = vector([4, -1, 2])
yx = y.inner_product(x) # 벡터 x와 y의 내적 구하기
xx = x.inner_product(x) # 벡터 x와 x의 내적 구하기
p = yx/xx*x # 벡터의 정사영 구하기
w = y-p
print("x=", x)
print("y=", y)
print("yx=", yx)
print("xx=", xx)
print("p=", p)
print("w=", w)
x= (2, -1, 3)
y= (4, -1, 2)
yx= 15
xx= 14
p= (15/7, -15/14, 45/14)
w= (13/7, 1/14, -17/14)평면의 방정식: 법선벡터와 한 점
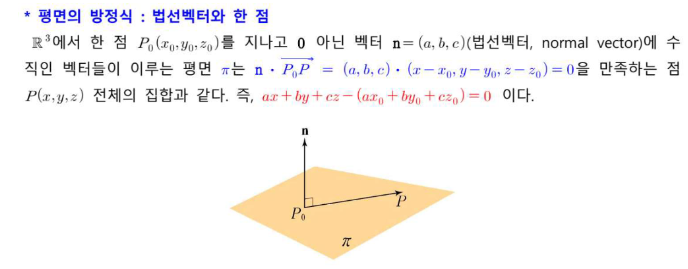
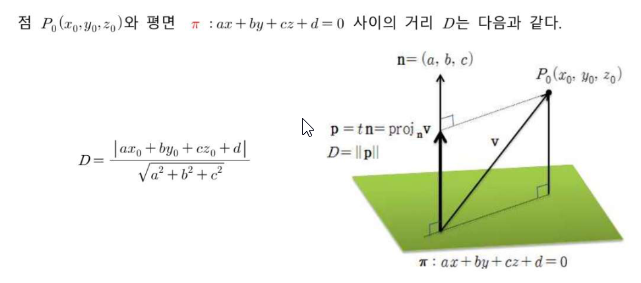
평면과 (그 평면에 없는) 한 점 사이의 거리 D를 구할 대는 평면의 방정식을 ax+by+cz+d=의 형태로 바꾸어 놓고 사용해야 한다.
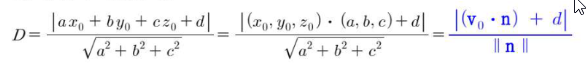
sagemath 실습
- P(3, -1, 2)에서 평면 x+3y-2z-6=0에 이르는 거리 D를 구하여라.
v=vector([3, -1, 2])
n=vector([1, 3, -2])
d=-6
vn=v.inner_product(n) # 벡터 v와 n의 내적 구하기
nn=n.norm() # 벡터 n의 노름 구하기
Dist = abs(vn + d)/nn # abs() 입력된 숫자나 수식의 결과값에서 부호를 제거하고 절대값(0으로부터의 거리)만을 반환하는 수학 및 프로그래밍 함수
print("P=", v)
print("n=", n)
print(Dist)
P= (3, -1, 2)
n= (1, 3, -2)
5/7*sqrt(14)데이터 분석에서...
거리나 코사인 유사도를 사용하여 유사도를 볼 수 있으나:
- 거리가 가까워도 방향은 다를 수 있다.
- 코사인 유사도가 높아도 거리가 가깝다고 보장할 수 없다.
1. 거리 기반
사용 예
- k-means
- kNN
- clustering
측정
∣∣x−y∣∣
의미
실제 위치가 가까운가
2. 코사인 유사도
사용 예
- 문장 임베딩
- LLM 검색
- 추천 시스템
측정
cosθ
의미
방향(패턴)이 비슷한가
