Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
위 논문을 리뷰하고 관련된 개념들을 수집하여 종합적인 개념을 정리해보려 한다.
Abstract
- Deep Neural Network 를 학습시킬 때 이전 레이어의 파라미터가 변함에 따라 각각의 레이어에 들어오는 input의 분포가 변하기 때문에 복잡하다.
- 이는 더 낮은 lr 을 필요로 함으로써 학습을 더 느리게 하고 파라미터 값 초기화에 더 민감하게 만든다. (파라미터를 초기에 넣을 때 조심히 넣어야 하고 값에 따라 결과차이가 꽤 난다는 의미) -> 학습이 어려움
- 이러한 현상을 'internal covariate shift'라고 정의하며 이런 ICS 문제를 layer input을 정규화함으로써 해결한다.
- BN 방법은 모델 아키텍쳐의 일부분을 정규화하는 것에 강점이 있고 각 트레이닝 미니 배치마다 정규화한다.
- 이것이 주는 효과는 더 높은 lr을 사용할 수 있게 하고 파라미터 초기화에 덜 조심해도 된다. 그리고 regularizer의 역할도 해서 Dropout을 어떨때는 안써도 된다.
아래 두 개념은 해당 글을 참고했습니다.
❗Covariate Shift (공변량 변화)
- 독립변수들인 공변량 분포의 변화로, Dataset shift의 모든 징후중 하나. Dataset shift는 아래 그림 처럼 training set과 test set의 분포가 달라 학습 결과에 차이가 있는 것을 의미한다.
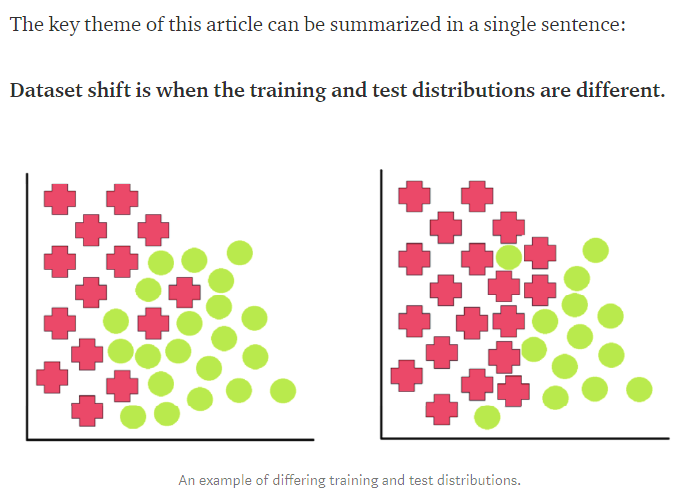
- Dataset shift 는 표준 용어는 아님. 때때로
- concept drift
- concept shift
- changes of classification
- changing environments
- contrast mining in classification learning
- fracture points and fractures between data 로 언급됨.
- Dataset shift 의 다양한 이상 징후
- Concept shift
- Covariate shift
- Prior probability shift
- Internal covariate shift (an important subtype of covariate shift)
- 즉 Covariate shift는 Dataset shift의 한 양상이며, 아래의 예시로 나타나는 현상을 의미한다.
- 얼굴 인식 알고리즘은 대게 나이 먹은 얼굴보다는 젊은 얼굴로 학습을 시킨다.
- 이미지를 고양이나 개로 분류하고 테스트 세트에서 볼 수 있는 훈련 세트에서 특정 종은 제외한다.
- 다시 말해, data의 input 과 output의 관계를 알아내는 것에는 변화가 없지만(regression line 은 여전히 같다), 관계의 일부는 data-sparse, omitted, 하거나 misrepresented된 경우에 test set이 그러한 training set의 분포를 반영하지 않는다는 현상이다.
❗Internal Covariate Shift
- Covariate shift 가 Deep Neural Network의 hidden layer에서 '내부적으로(internal)' 발생함.
- hidden layer으로부터 주어진 output의 activation의 분포 변화가 다음 레이어의 input으로 사용되기 때문에 network 레이어가 학습 도중 covariate shift 문제를 겪는다는 것.
Introduction
-
SGD, Adagrad등 optimizer 는 네트워크 파라미터를 최적화하는 역할을 하여 loss 를 최소화 한다.
-
SGD에서는 각 미니배치 step 마다 loss funtion의 gradient 를 근사하도록 한다.
-
mini-batch를 사용하는 이유는
- 1. loss 의 gradient 가 전체 training set 의 gradient 의 추정치이다. 그리고 그 퀄리티는 배치사이즈가 커짐에 따라 향상한다.- 배치 단위로 계산하는게 각각 example을 계산하는 것보다 훨씬 효율적이다.
-
SGD는 간단하고 효율적이지만 model hyper-parameter를 튜닝이 필요하다. 특히 lr 이 optimization에 필요하며 initial values들이 모델 파라미터에 필요하다.
-
그래서 train 하는게 까다로운데, 그 이유는 각각의 layer가 모든 연속적인 레이어의 파라미터에 의해 영향을 받고 작은 network parameter의 변화가 네트워크가 깊어질수록 증폭되기 때문이다.
-
layer들의 input의 분포 변화가 또 문제가 된다. 왜냐면 하나의 layer가 계속적으로 새로운 분포를 만들어낸다. 학습할 때 input 분포가 변하게 되면 covariate shift 를 겪는다. 근데 이런 현상이 전체적으로 학습할 때 퍼지게 된다. 네트워크가 계산될 때 그 다음 network layer 에 이전 layer 분포를 전달하는 방식이기 때문이다.
-
예를 들어 아래 식과 같이 gradient descent step 이 진행되고(batchsize = m, lr = a)
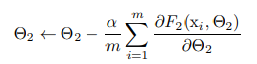
아래 처럼 network computing 이 진행된다.
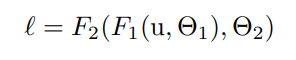
-
sub-network 에 들어가는 input의 분포를 고치게 되면 output 도 잘나온다.
-
sigmoid activation 을 생각해보자. z = g(Wu + b)에서 g(x) = 1/
1+exp(−x)이고 |x| 가 증가함에 따라 g'(x)는 0으로 수렴한다. -
이는 작은 절대값을 제외하고 모든 차원에 대해 u를 향헤 가는 gradient 가 사라질 것이고 모델은 천천히 학습될 거라는걸 의미한다.
-
그러나 x가 W와 이전 layer의 파라미터들에 영향받기 때문에 학습하는 동안 파라미터의 변화가 많은 차원의 x가 the saturated regime of the nonlinearity and slow down the convergence 로 이동할 것이다.
-
saturation 문제와 gradient 가 사라지는 결과는 결국 ReLU 를 사용함으로써 해결될 수 있다.
-
그러나 만약 우리가 nonlinearity input의 분포가 더 안정적이라고 확신할 수 있다면 optimizer가 덜 get stuck in the saturated regime 그리고 학습은 더 잘될 것이다.
