1. CPU Scheduling
스케줄러(Scheduler)는 언제, 어떤 프로세스를 선택해서 CPU에서 실행시키는지 선택하는 모듈(Module)이다. 멀티프로그래밍의 목적이 CPU 효율 극대화이므로 적절한 스케줄링이 필요하다.
기본적으로 프로세스는 CPU만 사용하는 단계(CPU burst)와 I/O 작업만 하는 단계(I/O burst)의 반복으로 구성된 사이클의 형태로 수행된다
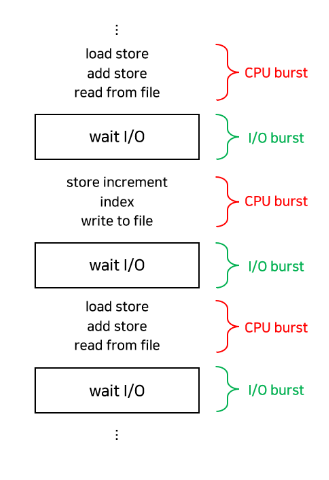
CPU burst time의 분포에 따라 프로그램의 특성을 나타낼 수 있는데, 짧고 많은 CPU burst가 존재하는 프로그램을 I/O-bound Job, 길고 적은 CPU burst가 존재하는 프로그램을 CPU-bound Job이라고 부른다. I/O-bound Job은 CPU를 잡고 계산하는 시간보다 I/O에 많은 시간이 필요한 Job이다. 반면 CPU-bound Job은 계산 위주의 Job이다.
그래프로 표현하면 아래와 같다.
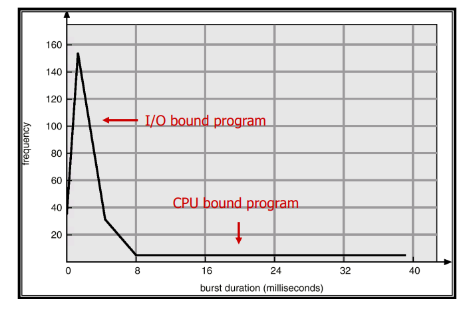
이러한 여러 Job이 섞여있기 때문에 CPU 스케줄링이 필요하다.
CPU Scheduler는 메모리에서 Ready 상태의 프로세스 중 어떤 프로세스를 CPU에 할당해줄지 선택한다.
CPU 스케줄링으로 인해 변경되는 프로세스의 상태는 다음과 같다.
1) Running → Waiting(Blocked) : I/O 요청이나 자식의 종료를 위해 wait( ) 함수 호출한 경우
2) Running → Ready : 인터럽트가 발생한 경우
3) Waiting → Ready : I/O 작업이 끝난 경우
4) Terminate
여기서 1)과 4)는 Non-preemptive (비선점) 방식이고, 그 외의 모든 과정은 preemptive(선점) 방식이다.
Preemptive 방식은 운영체제가 강제로 프로세스의 사용권을 통제하는 방식이고, Non-preemptive 방식은 프로세스가 스스로 다음 프로세스에게 자리를 넘겨주는 방식이다.
Preemptive 스케줄링은 여러 프로세스가 데이터를 공유하고 있는 경우, 경쟁 상태(Race condition)의 문제점을 낳을 수 있다. 만약 한 프로세스가 데이터를 수정하고 있는 동안에 다른 프로세스의 수행을 위해 preempted 된다면, 다른 프로세스는 일관성이 없는 상태의 데이터를 읽게 된다.
2.Dispatcher
component of CPU scheduling function
Dispatcher는 CPU의 제어권을 CPU 스케줄러에 의해 선택된 프로세스에게 넘겨주는 모듈이다.( dispatcher는 스케쥴링 알고리즘에 의해 선택된 프로세스를 CPU에 올리는 역할 )
- Context switching
- 커널 모드에서 유저 모드로 스위칭하는 작업
- PCB의 program counter를 읽어서 프로그램의 어느 부분부터 수행할지를 결정해준다(jumping to the proper location in the user program to restart that program) -> 프로세스가 다시 시작할 때 pc값에 기반해서 사용자 프로그램에서 제대로 된 위치를 찾아주는 역할
한 프로세스를 멈추고 다른 프로세스를 실행하는 데까지 걸리는 시간을 Dispatch latency라고 부른다.
3. Scheduling Criteria
CPU 스케줄링 알고리즘은 여러 종류가 있는데, 각 알고리즘의 성능을 평가하는 기준(Performance measure, 성능 척도)이 있다.
1. 시스템 입장에서의 성능 척도
-
CPU 이용률 (CPU Utilization) : 전체 시간 중 CPU가 쉬지 않고 일한 시간
-
처리량 (Throughput) : 단위 시간당 수행 완료한 프로세스의 수
2. 프로그램 입장에서의 성능 척도
-
소요 시간 (Turnaround Time) : 프로세스가 Ready queue에서 대기한 시간부터 작업을 완료하는데 걸리는 시간 sum of the periods spent waiting in the ready queue, executing on the CPU, and doing
I/O. -
대기 시간 (Waiting Time) : 프로세스가 Ready queue에서 대기한 시간
-
응답 시간 (Response Time) : 프로세스가 처음으로 CPU를 할당받기까지 걸린 시간 the first response is produced, not output
프로그램 입장에선 소요, 대기, 응답 시간이 모두 최소가 될수록 좋고, 시스템 입장에선 CPU 이용률과 처리량이 모두 최대가 될수록 좋다.
-
In most cases, CPU scheduler needs to
Maximize CPU utilization and throughput.
Minimize turnaround time, waiting time and response time. -
average value 가 보통 가장 최적화된 상태
-
However, under some circumstances, optimizing the minimum and maximum values is preferred.
-
For interactive systems, it is more important to minimize the variance(변동성) in the response time than to minimize the average response time
4. Scheduling Algorithm
이제 여러 스케줄링 알고리즘에 대해 알아보자. 처음엔, 다음과 같은 조건이 주어져 있다고 가정하자.
1) 모든 작업은 동일한 시간만큼 수행된다.
2) 모든 작업은 동일한 시간에 도착한다.
3) 모든 작업은 오직 CPU만 사용한다. (no I/O)
4) 각각의 작업이 수행될 시간을 이미 알고 있다.
- First-Come, First-Served (FCFS) Scheduling
- Shortest-Job-First (SJF) Scheduling
- Priority Scheduling
- Round-Robin (RR) Scheduling
- Multilevel Queue Scheduling
- Multilevel Feedback Queue Scheduling
1. FCFS Scheduling
FCFS 스케줄링은 First Come First Served의 약자로 CPU에 먼저 도착하는 순서대로 프로세스를 할당해주는 방식이다.
각 작업이 종료될 때까지 CPU를 빼앗지 않으므로 Non-Premptive 방식이며, FIFO 방식의 큐(Queue)와 동일하다.
구현하기 쉬워 간단한 시스템에 자주 사용된다.
Average waiting time is often quite long.
Particularly troublesome for time-sharing systems.
- example
모든 작업들의 수행 시간과 도착 시간이 동일하므로 어떤 식으로 스케줄링을 하더라도 동일한 성능을 갖는다.
하지만 만약 "1) 모든 작업은 동일한 시간만큼 수행된다" 라는 조건이 제거되면 어떨까?

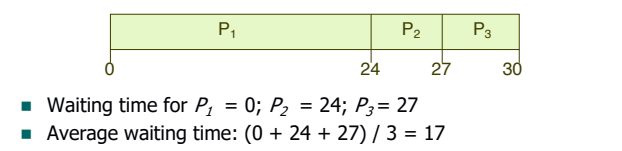
각 작업별로 수행 시간이 다를 때 FCFS 스케줄링 방식이 효율적일까?
-> 아니다.
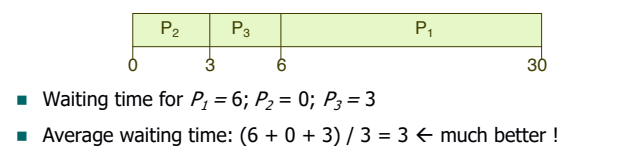
하나의 긴 프로세스로 인해 나머지 프로세스가 오래 기다리게 되어 CPU 효율성이 낮아지는 문제점을 Convoy Effect라고 한다. Convoy Effect가 발생하면 CPU와 I/O 둘 중 하나는 아무것도 하지 않을 수도 있다.
예시처럼 짧은 프로세스를 먼저 수행하는 방식을 Shortest Job First 스케줄링이라고 한다.
2. Shortest-Job-First (SJF) Scheduling
SJF(Shortest Job First) 스케줄링은 Convoy Effect를 해결하기 위한 방식이다. 프로세스의 수행 시간이 짧은 순서대로 CPU에 할당한다. SJF 스케줄링은 항상 주어진 프로세스에 대해 최소의 평균 대기 시간을 보장한다. 즉, 항상 최적(Optimal) 임이 보장된다.
하지만, 수행시간이 긴 프로세스는 계속 뒤로 밀려나는 기아(Starvation) 현상이 발생할 수 있다.
또, 각 프로세스가 얼마나 CPU를 사용할지 모르는 경우 사용하기가 어렵다. 단지 추정만 가능한데, 과거의 CPU burst time을 이용하여 예측하는 지수 평활법(exponential averaging)을 사용한다. 최근 가중치를 더 많이 반영하는 방식이다.
SJF 방식은 Non-preemptive와 Preemptive 두 방식이 존재한다.
1) Non-preemptive SJF
프로세스가 한번 CPU를 잡으면 이번 CPU burst 시간이 만료될 때까지 CPU를 뺏기지 않는다.
하지만 만약 "2) 모든 작업은 동일한 시간에 도착한다"의 조건을 만족하지 않는다면 어떻게 될까?
- example

프로세스들이 모두 다른 시간에 도착한다고 가정하자. 현재 도착한 프로세스 중 시간이 가장 짧은 프로세스에 CPU를 할당하고, 한번 실행을 시작하면 완료될 때까지 CPU를 빼앗기지 않는다면 위처럼 평균 대기 시간은 4가 된다.
이 값이 과연 최적일까? -> 아니다
2) Preemptive SJF

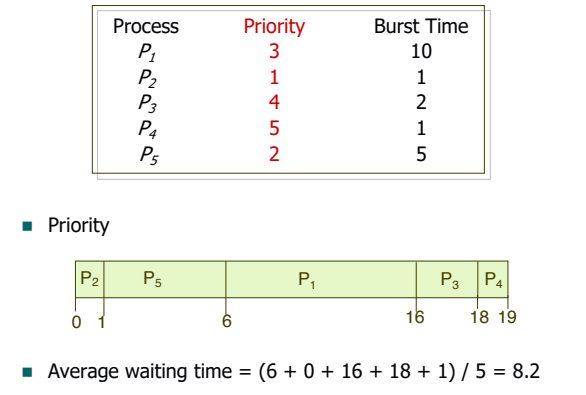
3. Priority Scheduling
우선순위 스케줄링은 특정 기준으로 프로세스에게 우선순위를 부여해 우선순위가 제일 높은 프로세스에게 CPU를 할당하는 방식이다. 일반적으로 숫자가 작으면 우선순위가 높은 것을 의미하며, SJF도 일종의 우선순위 스케줄링이다.
다만 이 방식 또한 우선순위가 낮은 프로세스가 계속해서 수행되지 않는 기아 현상(Starvation)이 발생할 수 있는데, 이를 에이징(Aging) 기법을 통해 해결한다. 에이징 기법은 시간이 지날수록 오래 대기한 프로세스의 우선순위를 높이는 방식이다.
다른 스케줄링 알고리즘과 결합해서 사용할 수 있어 선점, 비선점 모두 가능하다.
SJF is a priority scheduling where priority is the predicted next CPU burst time.
- example
4. Round Robin (RR) Scheduling
때때로, 작업이 언제 끝나는지보다 언제 시작되는지가 더 중요할 수도 있다.
Round Robin 스케줄링은 각 프로세스가 주로 10 ~ 100ms의 동일한 크기의 할당 시간(Time quantum)을 갖는다. 할당 시간이 끝나면 프로세스는 자동으로 선점(Preempted)당하고, Ready queue의 제일 뒤에 가서 다시 줄을 선다.
n개의 프로세스가 Ready queue에 존재하고, 할당 시간(Time quantum)이 q라면 어떤 프로세스도 (n-1)q 이상 기다리지 않으므로 기아 현상이 발생하지 않는다. 따라서 응답 시간이 빠르다는 장점이 있다.
다만, 일반적으로 SJF보다 평균 소요 시간(Average Turnaround Time)은 길다.
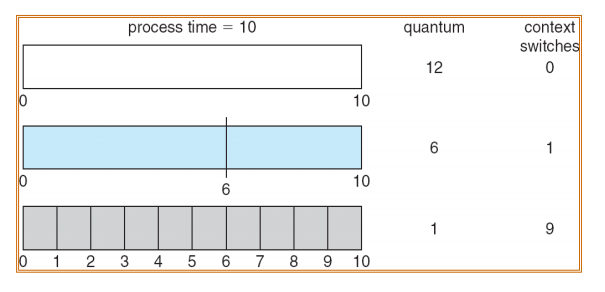
평균 소요 시간은 할당 시간이 커진다고 해서 반드시 증가하는 것은 아니다. 할당 시간 q가 클수록 FCFS의 방식과 유사하고, q가 작을수록 Context switch의 오버헤드가 커지기 때문에 적절한 할당 시간을 배정하는 것이 중요하다.
->If q is extremely small, it is called processor sharing – each of n processes has its own processor running at 1/n the speed of the real processor.
- example
RR with Time Quantum = 20
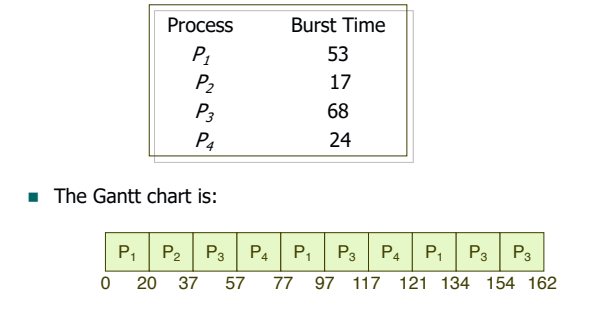
- Typically, higher average turnaround than SJF, but better response.
Time Quantum vs Context Switch Time
Time Quantum vs Turnaround Time
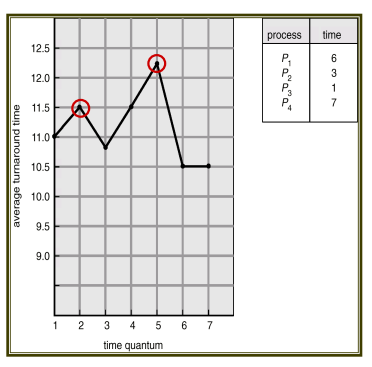
- Average turnaround time does not necessarily improve as the timequantum size increases.
- If time quantum is too large, RR scheduling becomes FCFS policy.
- 80 percent of the CPU bursts(CPU 명령을 실행하는 것) should be shorter than the time quantum.
I/O burst: I/O를 요청한다음 기다리는 시간
5. Multilevel Queue Scheduling
Multi-Level Queue는 Ready Queue를 여러 개로 분할한 것이다. 각 큐는 독립적인 스케줄링 알고리즘을 가진다.
Foreground task 같은 Interactive 프로그램은 응답 시간이 중요하기 때문에 Round Robin 스케줄링으로, Background Task 같은 Batch 프로그램은 소요시간이 중요하기 때문에 FCFS 스케줄링을 사용한다.
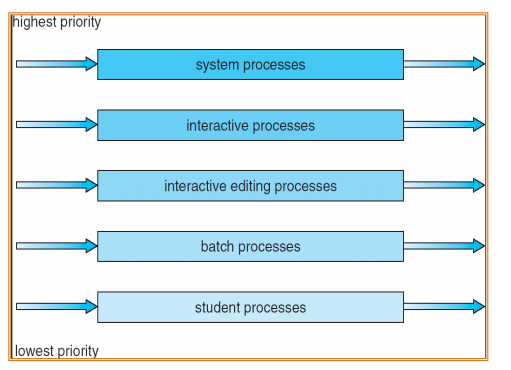
큐 사이에서도 스케줄링이 필요한데, Foreground 작업을 먼저 다 수행한 후, Background 작업을 수행하는 고정된 우선순위 스케줄링을 이용할 수 있다. 따라서 이 방식은 기아 현상이 발생할 수 있다.
또는, 각 큐에 CPU Time을 적절한 비율로 할당하는 Time slice 방식을 사용할 수도 있다. 예를 들어 80%는 Foreground에, 20%는 Background에 사용한다.
6. Multilevel Feedback Queue
MLFQ는 여러 개의 큐로 구성되며, 각각 다른 우선순위(Priority level)가 배정된다. 실행 준비가 된 프로세스는 이 중 하나의 큐에 존재한다. MLFQ는 실행할 프로세스를 결정하기 위하여 우선순위를 사용한다. 높은 우선순위를 가진 작업, 즉 높은 우선순위 큐에 존재하는 작업이 선택된다.
우선순위를 부여해서 에이징(aging) 기법을 통해 구현될 수 있다. 우선순위는 프로세스들의 과거 CPU burst time을 이용하여 미래의 행동을 예상하여 부여한다. 이를 이용하여 기아 현상을 해결할 수 있다.
MLFQ 스케줄링의 핵심은 우선순위를 정하는 방식이다. MLFQ는 각 작업에 고정된 우선순위를 부여하는 것이 아니라 각 작업의 특성에 따라 동적으로 우선순위를 부여한다.
예를 들어, 어떤 작업이 키보드 입력을 기다리며 반복적으로 CPU를 양보하면 MLFQ는 해당 작업의 우선순위를 높게 유지한다. 이러한 패턴은 대화형 프로세스가 나타내는 패턴과 같다. 대신에 한 작업이 긴 시간 동안 CPU를 집중적으로 사용하면 MLFQ는 해당 작업의 우선순위를 낮춘다. 이렇게 MLFQ는 작업이 진행되는 동안 해당 작업의 정보를 얻고, 이 정보를 이용하여 미래 행동을 예측한다.
MLFQ 스케줄러를 정의하는 변수(Parameter)들은 다음과 같다.
-
Queue의 개수
-
각 Queue를 위한 스케줄링 알고리즘
-
프로세스를 상위/하위 Queue로 보내는 기준
-
프로세스를 강등하고 업그레이드 를 결정하는 기준
-
프로세스가 CPU 서비스를 받으려 할 때 들어갈 Queue를 결정하는 기준
- example

새로운 작업이 Q0에 들어간다. CPU를 할당받아 8ms만큼 작업을 수행하고, 작업을 다 못 끝내면 Q1로 내려간다. 그리고 Q1에서 기다리다가 CPU를 할당받아 16ms만큼 작업을 수행한다. 또 작업을 다 못 끝내면 FCFS으로 내려가서 오직 Q0과 Q1이 비어있을 때 작업을 이어나간다.
MLFQ의 규칙
규칙 1 : 우선순위(A) > 우선순위(B) 이면 A실행. B는 실행되지 않음
규칙 2 : 우선순위(A) = 우선순위(B) 이면 A, B를 RR로 실행
규칙 3 : 작업이 도착하면 가장 높은 우선순위에서 시작
규칙 4 : 작업이 지정된 단계에서 배정받은 시간을 소진하면 (CPU 포기 횟수 무관) 우선순위 감소 (한단계 아래 큐로 이동)
규칙 5 : 일정 주기 S 마다 모든 작업을 가장 높은 우선순위 큐로 이동
