
함수형 프로그래밍이란?
함수형 프로그래밍이란 성공적인 프로그래밍을 위해 부수 효과를 미워하고 조합성을 강조 하는 프로그래밍 패러다임이다.
함수형 프로그래밍의 목적은 4단계에 걸쳐 말하고 있다.
- 부수 효과를 미워한다. => 순수 함수를 만든다.
- 조합성을 강조한다. => 모듈화 수준을 높인다.
- 순수 함수 => 오류를 줄이고 안정성을 높인다.
- 모듈화 수준이 높다. => 생산성을 높인다.
여기서 말하는 조합성이란 단어는 모듈의 독립성으로도 대체 할 수 있을거 같다.
결국 모듈의 수준을 높이기 위해 모듈의 독립성과 응집력을 높입니다. 모듈화 수준이 높아지면 얻을 수 있는 효과로는 기획 변경의 대응력을 높이고, 오류를 줄이고 다른 모듈에 영향이 가지 않도록 하여 생산성과 안정성을 확보 할 수 있다.
Pure Function?
리덕스(Redux)가 함수형 프로그래밍(functional programming)의 “순수 함수(pure function)“에 의존한다고 알고 있을 것이다. 이것이 실제로 의미하는 바는 무엇일까?
순수함수를 한마디로 정의해보자면 동일한 인자가 주어졌을 때 항상 동일한 결과를 반환해야 하며 외부의 상태를 변경하지 않는 함수이다. 쉽게 말하면 함수 내 변수 외에 외부의 값을 참조, 의존하거나 변경하지 않아야 한다.
let obj = { val: 20 };
//non pure function
const notPureFn = (obj, b) => {
obj.val += b;
};
//pure function
const pureFn = (obj, b) => {
return { val: obj.val + b };
};
//pure function
const add = (a, b) => a + b;notPureFn 는 순수함수는 아니지만 pureFn은 순수함수이다.
notPureFn(obj,10)을 호출하게된다면, 바깥의 변수은 obj는 영향을 받게 되고 obj.val의 값은 30이 될 것이다.
마찬가지로 pureFn(obj,10)을 호출하게 된다면, 리턴값은 {val:30}일 것이고, obj.val의 값은 변하지 않고 20일 것이다.
순수함수라는 것은 알겠는데, 왜 redux와 연관이 있는걸까?
redux의 변경감지 정책
React의 state는 불변성을 유지해야 됩니다. 이는 redux의 state에서도 마찬가지인데 불변하다는 것은 수정되면 안된다는 말이다.
counter 리듀서를 예로 들어보자.
const initState = {
value: 0,
};
const counter = (state = initState, action) => {
switch (action.type) {
case INCREMENT:
return { ...state, value: action.payload };
case DECREMENT:
return { ...state, value: action.payload };
default:
return state;
}
};리듀서는 기존 state와 발생한 action을 인자로 받아 해당 액션의 type을 감지하여 변화를 일으키는 함수인데,
state의 값을 변경할 때는 Spread Operator(...)로 기존의 state의 값들을 복사한 뒤 value라는 키의 값만 변경하여 state를 반환한다.
그 외에 default case에서는 state를 수정할 필요가 없기 때문에 그대로 state를 반환한다.
이렇게 reducer를 구현할 때 인자로 들어온 state를 직접 수정하지 않고
복사본을 만들어 수정하는 이유는 redux의 변경 감지 알고리즘 때문이다.
객체의 속성으로 비교하는 것은 깊은 비교(deep-compare)라고 한다. 이는 개발자에게 더 편리할 수 있다. 하지만 state 객채에 모든 속성에 대해 변화를 감지하기 위해선 복잡하고 무거운 알고리즘이 필요하다.
아래 두 함수는 각각 주소를 통한 비교화 속성을 통한 비교를 하는 알고리즘의 예제이다.
// 객체의 주소 비교
const compareReference = (object1, object2) => object1 === object2;
// 객체의 속성 비교
const compareProps = (object1, object2) => {
const object1Keys = Object.keys(object1);
const object2Keys = Object.keys(object2);
if (object1Keys.length !== object2Keys.length) {
return false;
}
for (const key of object1Keys) {
if (typeof object1[key] === 'object' && typeof object2[key] === 'object') {
return compareProps(object1[key], object2[key]);
} else if (object1[key] !== object2[key]) {
return false;
}
}
return true;
};물론 실제로는 훨씬 더 복잡한 알고리즘이 필요하겠지만 지금 상태로도 충분히 속성비교 알고리즘이 복잡하다는것을 알 수 있다. 그렇다면 두 알고리즘의 성능은 얼마나 차이가 날까?
아래 예제는 위에서 구현된 두 알고리즘의 성능을 측정하기 위해 작성한 테스트코드이다. 100만개의 속성을 가진 object를 생성하고 두 알고리즘의 수행시간을 측정해보았다.
describe('change detection', () => {
const object = {};
for (let n = 0; n < 1000000; n++) {
object['prop' + n] = '123';
}
it('compare reference', () => {
const object2 = object;
const object3 = { ...object, prop2: 1234 };
expect(compareReference(object, object2)).toBeTruthy();
expect(compareReference(object, object3)).toBeFalsy();
});
it('compare properties', () => {
const object2 = object;
const object3 = { ...object, prop2: 1234 };
expect(compareProps(object, object2)).toBeTruthy();
expect(compareProps(object, object3)).toBeFalsy();
});
});
/*
테스트 결과
√ compare reference (1956ms)
√ compare properties (4011ms)
*/결과는 생각보다 큰 차이는 나지 않았지만 2배정도 차이를 보였다. 물론 state에 속성을 100만개씩이나 저장할 일이 극히 드물긴 하겠지만 속성의 개수가 적더라도 Redux를 사용하며 state가 비교되는 횟수를 감안하면 유의미한 측정결과라고 생각된다.
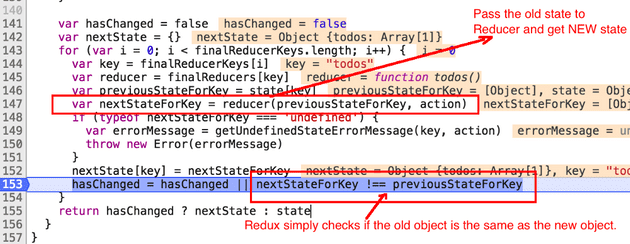
리덕스는 주어진 상태(객체)를 가져와서 loop의 각 리듀서로 전달한다.
그리고 변경사항이 있는 경우 리듀서의 새로운 객체를 리턴하고, 변경사항이 없으면 이전 객체를 리턴한다.
리덕스는 두 객체(prevState,newState)의 메모리 위치를 비교하여 이전 객체가 새 객체와
동일한지 여부를 단순 체크한다. 만약 리듀서 내부에서 이전 객체의 속성을 변경(mutate)하면 새 상태 와 이전 상태가 모두 동일한 객체를 가리킨다. 그렇게 되면 리덕스는 아무것도 변경되지 않았다고 판단하여 동작하지 않는다.
redux는 왜 이렇게 설계되었나?
그렇다면 바뀐 속성만 비교하면 되지 왜 주소를 비교하는 걸까? 라는 의문이 생긴다.
두 개의 자바스크립트 객체가 동일한 속성이 있는지를 아는 단 한 가지 방법은 이 둘을 깊이 비교(deep-compare)하는 것뿐이다. 그러나 이것은 일반적으로 큰 객체 이거나 비교해야 하는 횟수가 많다면 실제 앱에서는 매우 무거운(expensive) 작업이 된다.
따라서 이것의 해결 방법으로는 변경 사항이 있을 때마다 개발자에게
새 객체를 만들어서 프레임 워크로 보내도록 하는 정책을 만드는 것이다. 그리고 변경 사항이 없다면이전 객체를 그대로 되돌려 보내면 된다. 다시 말하면,새로운 객체는새로운 상태를 나타낸다.
이제 이러한 정책을 적용하면 객체의 각 속성 비교없이 ! ==를 사용하여 두 객체의 메모리 위치를 비교할 수 있다. 두 객체가 같지 않으면 객체의 상태가 변경된 것이라고 할 수 있다 (즉, 자바스크립트 객체의 속성이 변경됨). 그것이 리덕스가 사용하는 전략이다.
그 이유는 성능과 복잡도에 영향을 미치기 때문이다. 위의 예제와는 다르게 덩치가 큰 객체를 비교해야 되는 상황이면 객체의 주소 비교라면 O(1) 만큼 비교를 하면 되지만, 속성을 비교하게 된다면 O(n)만큼 비교를 해야되기 때문에 시간이 오래 걸린다.
이것이 리덕스의 “리듀서”가 순수 함수여야만 하는 이유이다!
다음의 글을 참고하였습니다.
