
안녕하세요~🙌 오늘은 프로젝트 중 기술적으로 도전했던 내용을 주제로 여러분께 소개하려고 합니다.
안 읽은 메시지가 있다고 알려주는 것은 실시간 채팅 서비스를 개발하는 데 있어 기술적인 도전이었습니다.
우리 서비스의 사용자는 자신의 안 읽은 메시지가 어느 커뮤니티, 채널에 있는지 알 수 있고 어디서부터 읽지 않았는지 알 수 있습니다. 이 기능을 구현하기 위해 어떤 고민 과정이 있었는지 얘기해 보려고 합니다.

서비스의 메시지 저장 방식
메시지 저장에 사용되는 DB는 MongoDB를 활용하였습니다.
🤔 왜 메시지를 MongoDB에 저장하는가요?
다음과 같은 장점이 있어 MongoDB를 메시지 저장에 사용하게 되었습니다.
- 스키마 변경에 있어 유연하다.
메시지를 저장할 때 넣는 정보를 추가할 때 용이하다.
- 확장성에 좋다.
메시지를 작성할 때마다 DB에 데이터를 저장하므로 용량이 많아질 것으로 예상하였다. 그래서 확장성이 좋은 MongoDB를 사용하게 되었다.
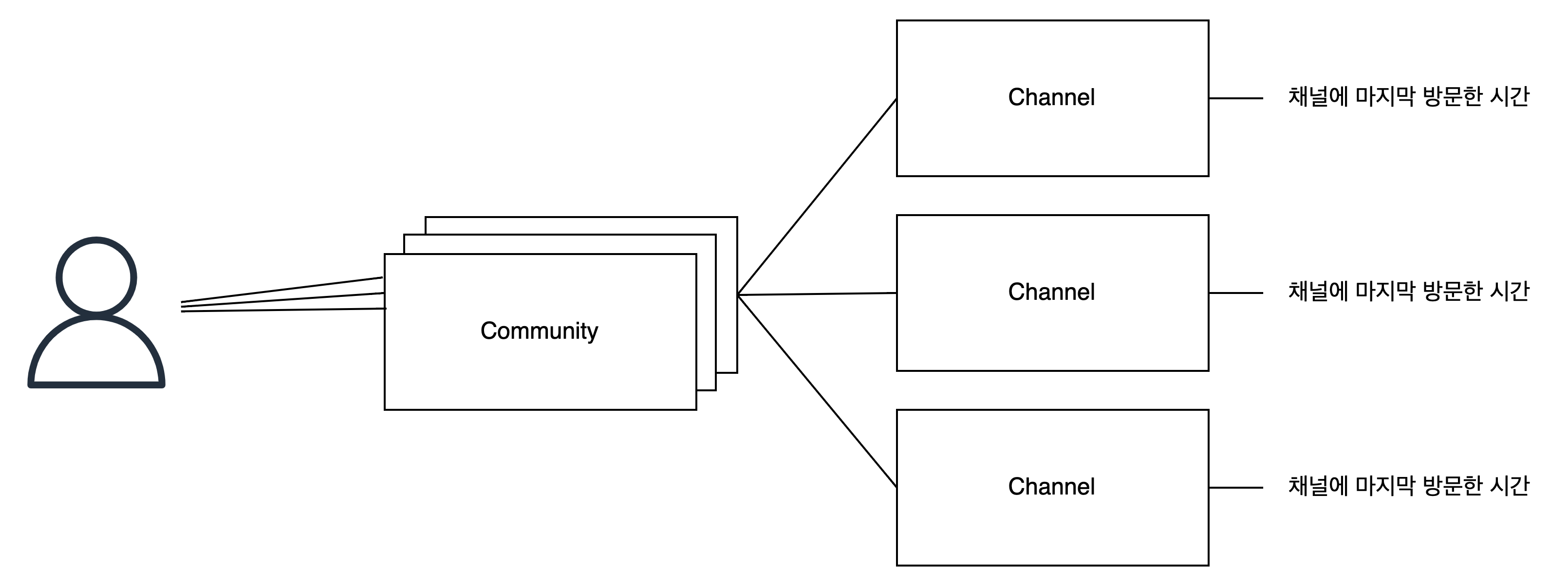
안 읽은 메시지를 저장하기 위해 어떤 정보를 DB에 저장하는지 설명하겠습니다.
- Chat의
createdAt(메시지 생성 시간)- 메시지 생성 시간과 비교하여 안 읽은 메시지의 위치를 알 수 있다.
- User의
lastRead(채널 마지막 방문 시간)-
사용자마다 자기가 속한 채널의 마지막 방문 시간 정보를 가지고 있다.
-
그러면 이제 안 읽은 메시지 위치를 찾는 로직에 대해 설명하겠습니다.
💬 안 읽은 메시지 위치 찾는 로직 (개선 전)
안 읽은 메시지를 찾는 로직은 복잡하지 않았습니다. 메시지의 생성 시간과 채널의 마지막 방문 시간을 비교하는 것이었습니다.
안 읽은 메시지 로직은 다음과 같은 사용자 스토리로 나누어집니다.
1. 서비스에 접속했을 때 커뮤니티, 채널에 안 읽은 메시지가 있는지 알 수 있다.
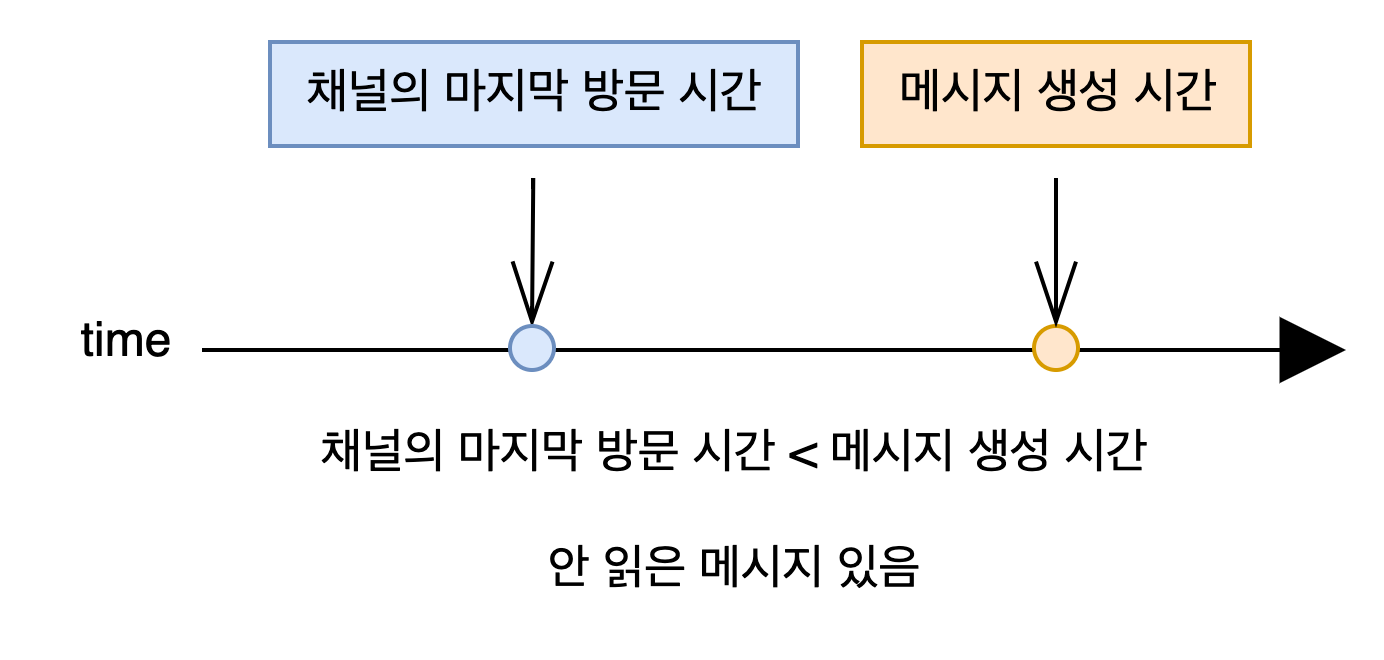
사용자가 서비스에 접속했을 때, 사용자가 속한 커뮤니티, 채널에 안 읽은 메시지가 있는지 알려줍니다. 이때 각 채널의 마지막 메시지의 생성 시간만 채널의 마지막 방문 시간하고 비교해주면 됩니다.
사용자가 참여한 채널의 개수가 K 개라고 하면, 총 K 번의 탐색이 발생합니다.
2. 채널에 접속했을 때 어디서부터 읽지 않았는지 알 수 있다.

채널에 접속했을 때는 어디서부터 읽지 않은 메시지가 있는지 알려면 최신 메시지부터 읽은 메시지가 나올 때까지 순차적으로 메시지 생성 시간과 채널의 마지막 방문 시간을 비교하면 됩니다.
읽지 않은 메시지가 M 개 있다고 하면, 채널에 방문했을 때 총 M 번의 탐색이 발생합니다.
이렇게 순차적으로 전부 비교하는 방식은 비효율적입니다. 그리고 자주 사용되는 API여서 성능상 개선하면 시스템 전체적으로 성능이 올라갈 것으로 생각하여 효율적인 방식을 찾기 위해 고민을 하였습니다.
💬 안 읽은 메시지 찾는 로직 개선 (M → M/100 + M%100)
메시지를 100개씩 ChatList에 저장한다.
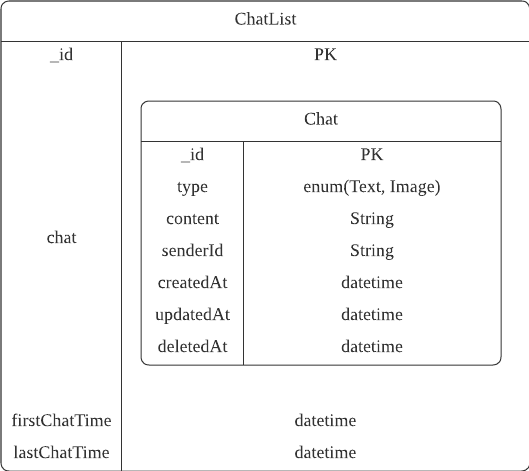
메시지 100개를 하나의 ChatList로 저장하고 FirstChatTime과 사용자의 채널 마지막 방문 시간을 비교합니다.
채널 마지막 방문 시간이 FirstChatTime보다 최신이면, 해당 ChatList 안에 안 읽은 메시지가 있다는 것입니다.
이렇게 구현하면 탐색 횟수가, 번 에서 번으로 단축됩니다.
예를 들어, 읽지 않은 메시지 개수 M을 1530이라고 가정하고 계산해 보자.
- 채널의 마지막 방문 시간과 FirstChatTime 비교 (채널의 마지막 방문 시간 < FirstChatTime ⇒ 다음번째 chatList에 존재) 15번 반복 [탐색 횟수: 15]
- 채널의 마지막 방문 시간과 FirstChatTime 비교 (채널의 마지막 방문 시간 > FirstChatTime ⇒ 이번 chatList에 존재) [탐색 횟수: 1]
- 내부에서 메시지 탐색 [탐색 횟수: 30]
이렇게 구현하면, 1530번 탐색할 것을 46번에 할 수 있습니다.
여기서 더 개선할 수 있는 방법에 대해 생각해 보았습니다. 메시지의 생성 시간이 오름차순으로 저장되기에 이진 탐색을 활용하기로 하였습니다.
💬 안 읽은 메시지 찾는 로직 개선 (M/100 + M%100 → M/100 + 6)
이진 탐색을 적용해 보자!
읽지 않은 첫 번째 메시지의 위치가 있는 ChatList를 찾았으면, ChatList 안의 메시지 100개를 전부 확인합니다.
이 부분을 이진 탐색을 활용하면, 최대 6번()의 탐색을 거쳐 안 읽은 메시지 위치를 찾을 수 있습니다. 그러면 탐색 횟수는 은 으로 줄어듭니다.
100 → 6 으로 줄어드는 것이 그렇게 효율적일까 생각을 할 수 있습니다. 하지만 실시간 채팅 서비스 특성상 위 로직은 자주 발생할 것이어서 이 정도 개선도 효과적이라고 생각했습니다.
🧑🔬 예를 들어, 읽지 않은 메시지 개수 M을 1530이라고 가정하고 계산해보자.
- 채널의 마지막 방문 시간과 FirstChatTime 비교 (채널의 마지막 방문 시간 < FirstChatTime ⇒ 다음번째 chatList에 존재) 15번 반복 [탐색 횟수: 15]
- 채널의 마지막 방문 시간과 FirstChatTime 비교 (채널의 마지막 방문 시간 > FirstChatTime ⇒ 이번 chatList에 존재) [탐색 횟수: 1]
- 내부에서 메시지 탐색 [탐색 횟수: 6]
이렇게 구현하면, 1530번 탐색할 것을 22번에 할 수 있습니다.
🤔 그러면 chatList도 순차적으로 찾는 것이 아니라 이진 탐색을 사용하면 되지 않을까?
chatList를 사용하지 않고 메시지를 전부 이진 탐색으로 찾을 경우, 의 시간 복잡도로 찾을 수 있습니다.
필자도 처음에 이렇게 생각을 하였으나, 서비스 특성상 안 읽은 메시지가 최신 메시지와 가까이 있을 가능성이 높아 chatList는 최신 메시지부터 뒤로 순차적으로 탐색하도록 구현하였습니다.
