프로젝트 설명
카메라로 하노이탑의 고리 위치를 인식하고 유전알고리즘을 활용하여 문제 해결을 도출하는 프로그램이다.
대학교 2학년 2학기에 동아리에서 전시를 위해 약 2달간 진행한 프로젝트이다.

개인 작품으로 진행하였고 언어는 C++을 사용하였다.
개발 동기
당시에 머신러닝에 관심이 많아 유전알고리즘을 사용하고 싶었다.
유전알고리즘을 사용해보고 싶다고 결정하고 프로젝트를 정한거라 유전알고리즘을 하노이탑에 적용하는 이유는 딱히 없었다. 하노이탑을 주제로 정한 이유는 유전알고리즘 특징인 교차, 변이를 적용하기에 적합하다고 생각해서이다.
시스템 아키텍처
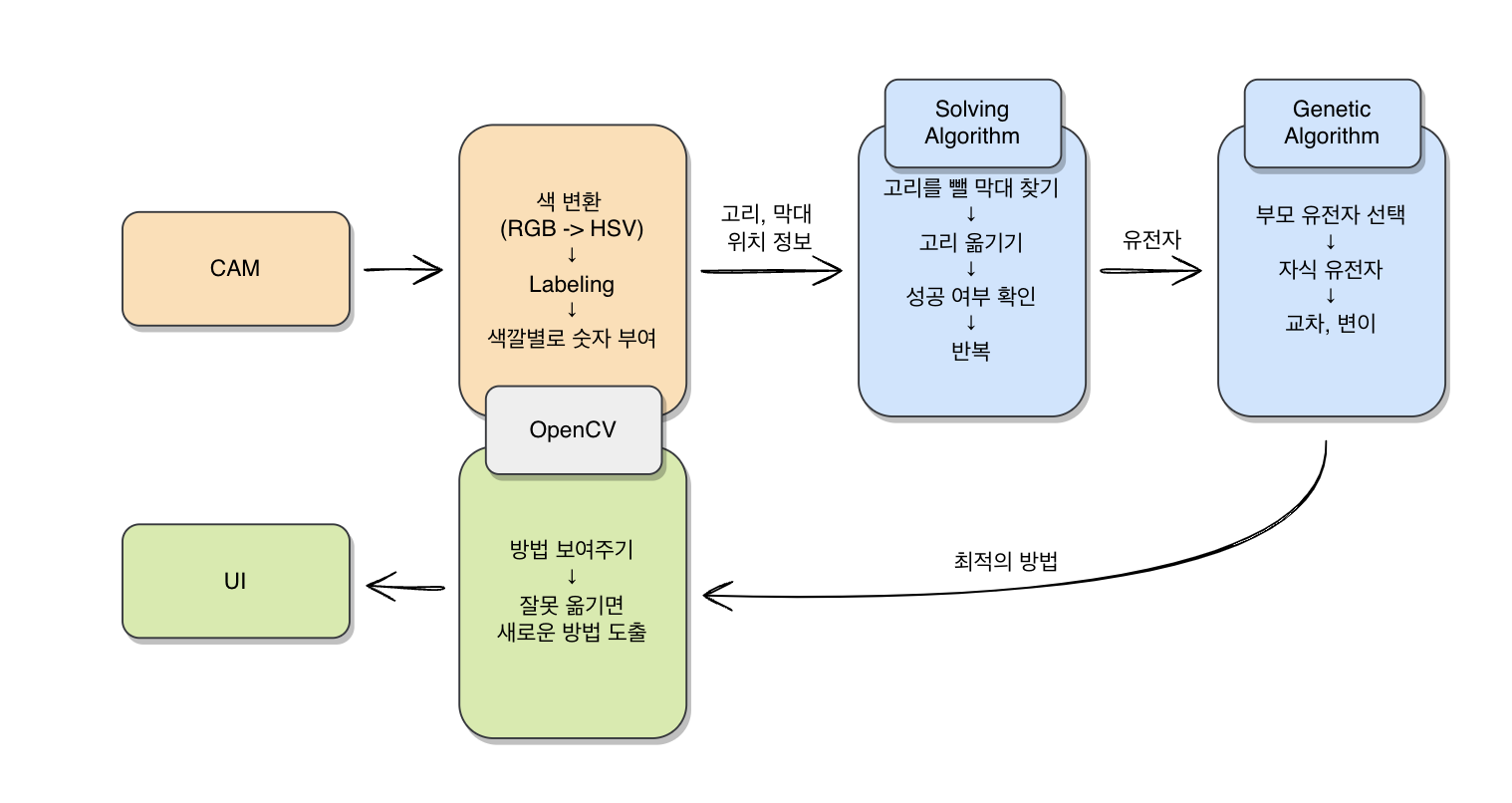
프로젝트 구현 과정
1. 기본 알고리즘 구현
하노이탑의 규칙을 이용한 알고리즘이다.
규칙
- 고리는 한번에 하나씩 옮길 수 있다.
- 막대의 가장 위에 있는 고리만 옮길 수 있다.
- 고리가 큰 것이 작은 것 위에 올라갈 수 없다.
[1] 고리가 있는 막대 찾기
고리가 없는 막대를 선택하여 고리를 옮기게 되면 오류가 나므로 어느 막대에 고리가 있는지 알아야 한다.
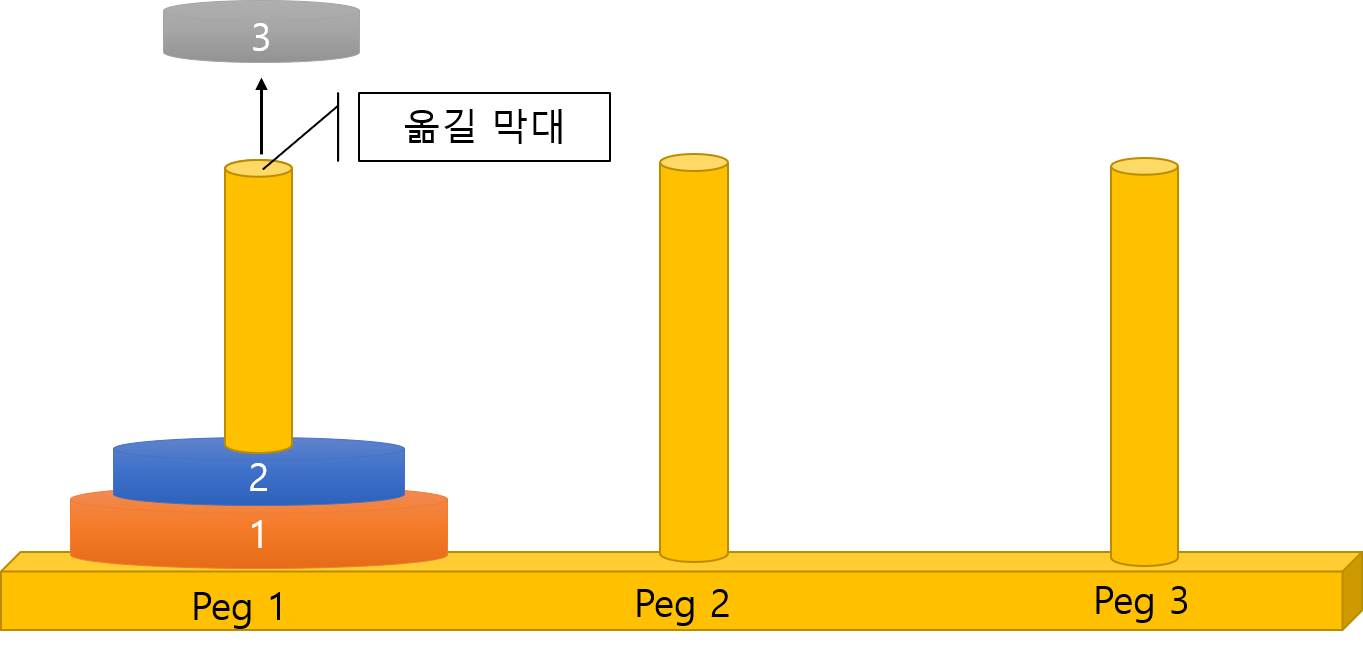
[2] 고리를 넣을 막대 찾기
고리를 넣을 막대를 랜덤으로 선택한다. 만약 바로 직전에 옮겼던 고리인 경우, 옮기기 전 막대로 돌아가는 경우는 제한시켰다.(이전에 옮겨왔던 고리를 다시 그 고리로 옮기는 것은 비효율적)
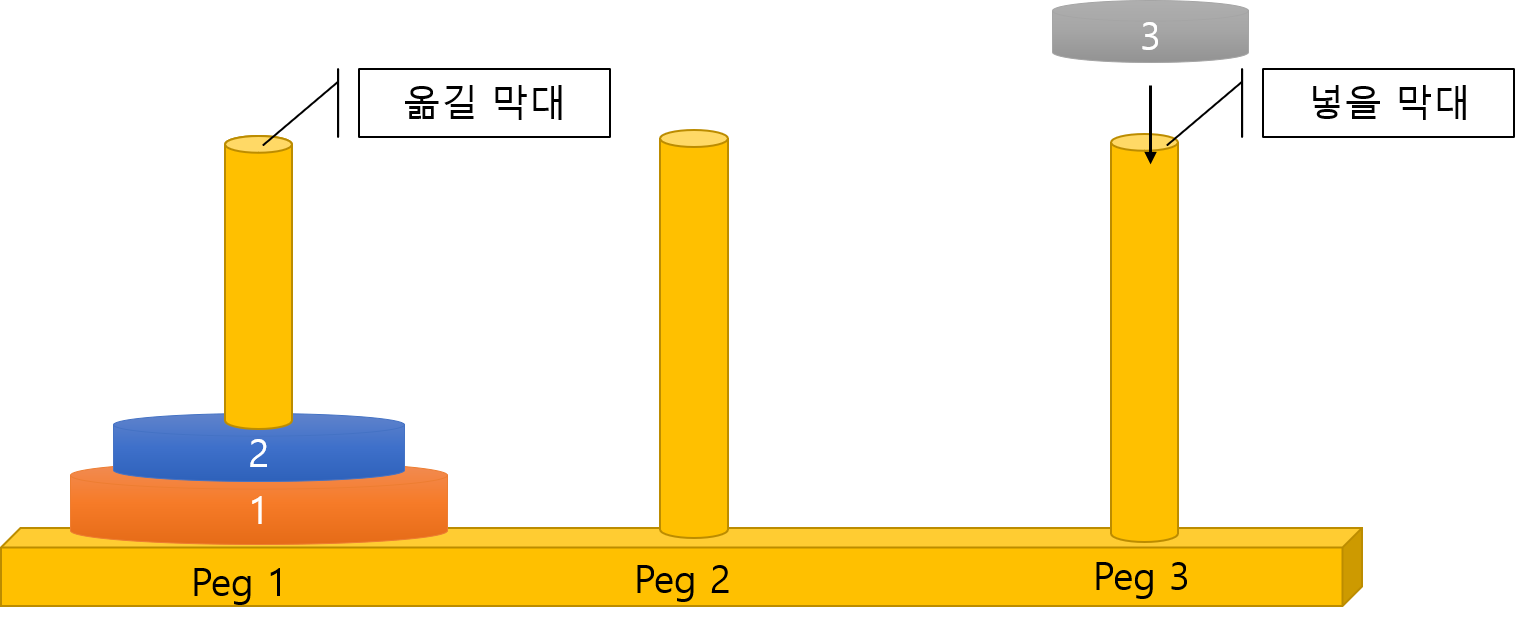
옮길 고리의 크기보다 들어갈 막대의 가장 위에 있는 고리가 작으면 1번으로 돌아가 다시 옮길 고리를 찾는다.
[3] 성공 여부 확인하기
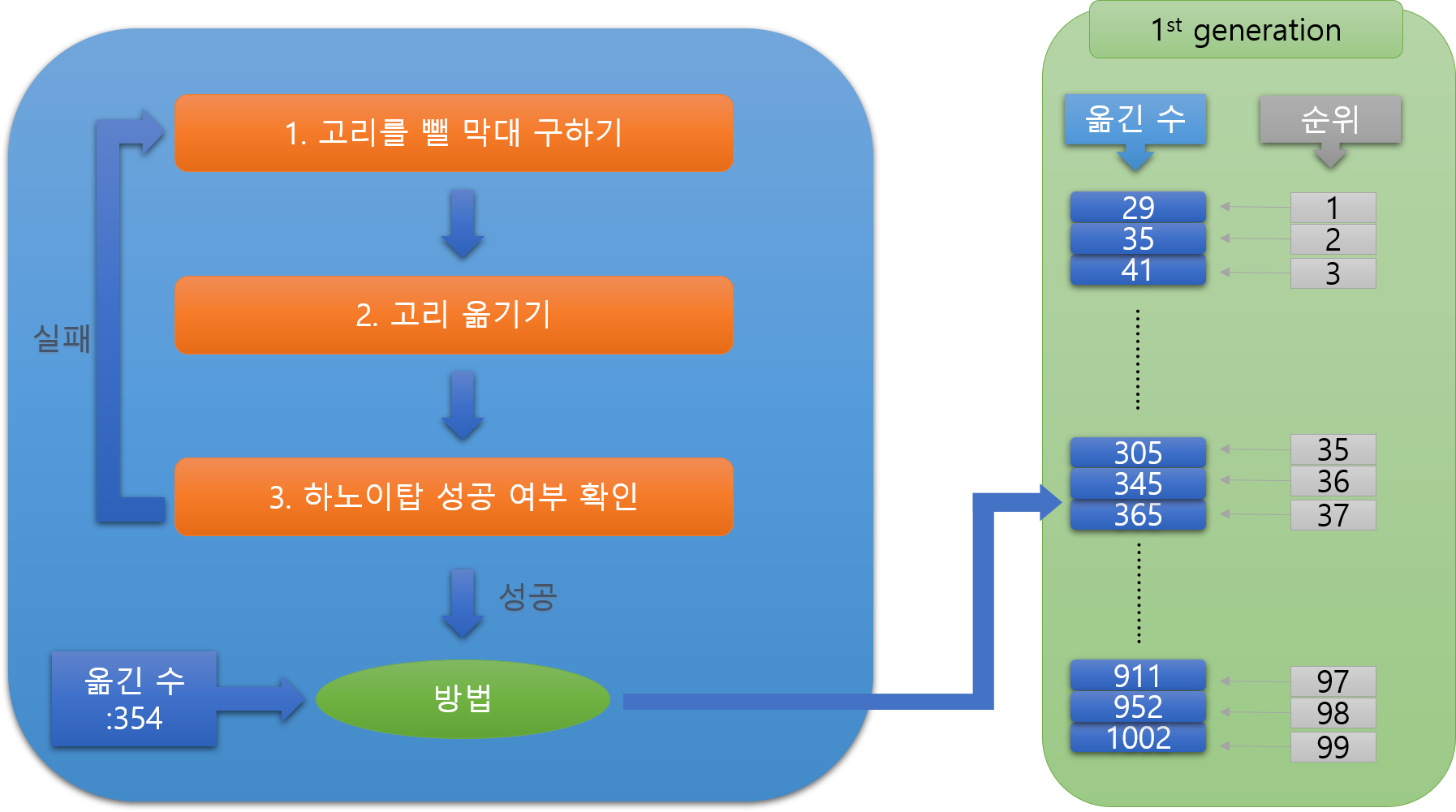
그림과 같이 막대가 옮겨지면 성공이다. 성공여부를 확인해서 실패하면 다시 1번으로 돌아간다. 성공이면 해당 방법의 옮긴횟수를 다른 방법의 옮긴횟수와 비교하여 순위를 매긴 후 오름차순으로 정렬합니다.
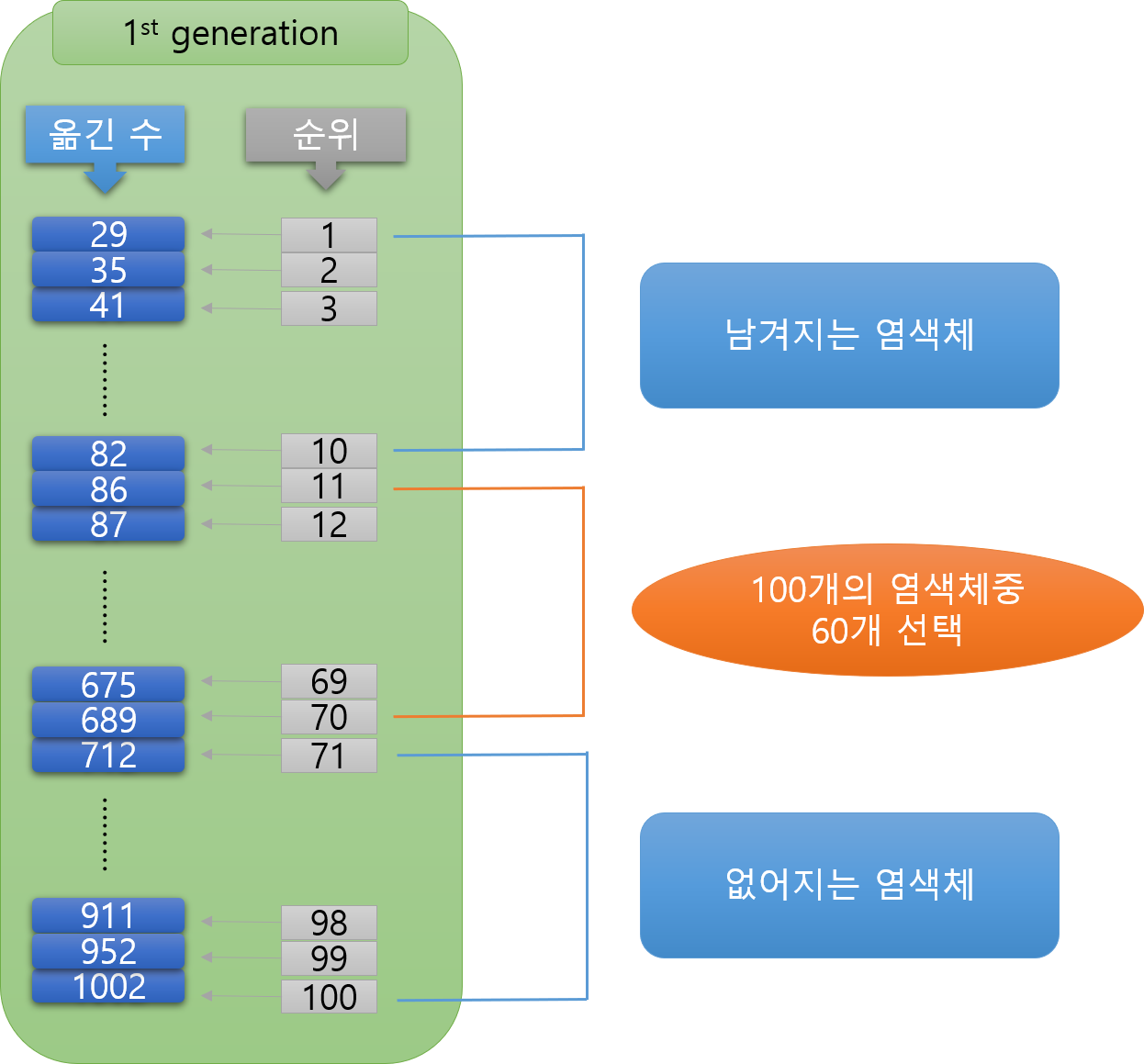
2. 유전알고리즘 구현
유전알고리즘은 진화의 핵심 원리인 자연 선택과 유전자의 개념을 이용한 최적화 기법이다.
주어진 문제에 대한 해답을 무작위로 생성한 뒤 생성된 집단을 진화시켜 더 좋은 해답을 찾는 방법이다.
유전 알고리즘은 선택, 교차, 변이, 대치 등 몇가지 주요 연산으로 구성된다.
[1] 진화시킬 염색체 선택
염색체란 하나의 해이다. 선택은 교차와 변이를 시킬 염색체를 골라준다. 성능이 좋은 염색체를 선택하고 성능이 좋지 않은 염색체는 배제시킨다.
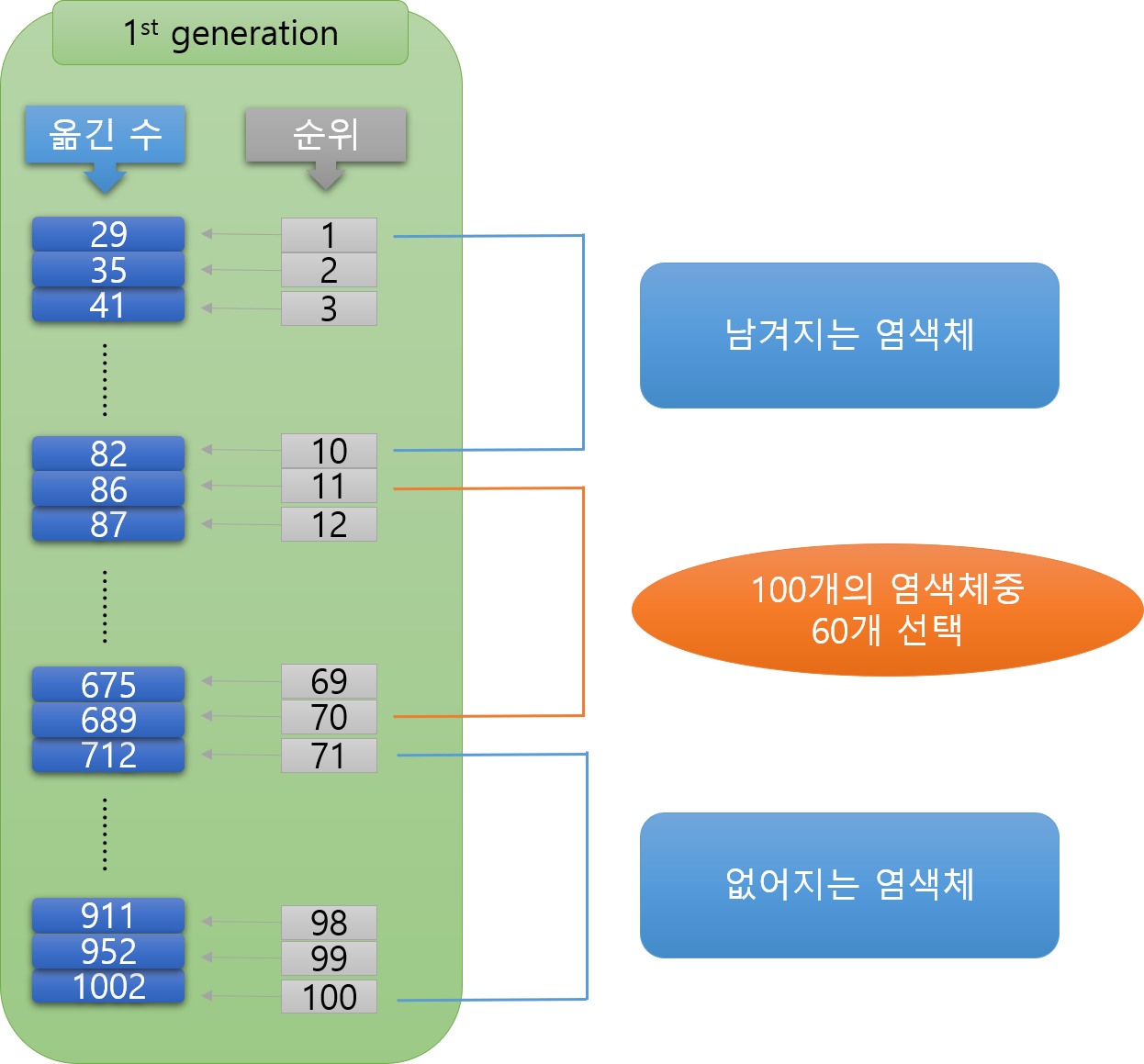
하노이탑 AI 에서 선택을 시키는 방법으로는 그림과 같이 상위 10개를 제외한 상위 60개를 선택한다.
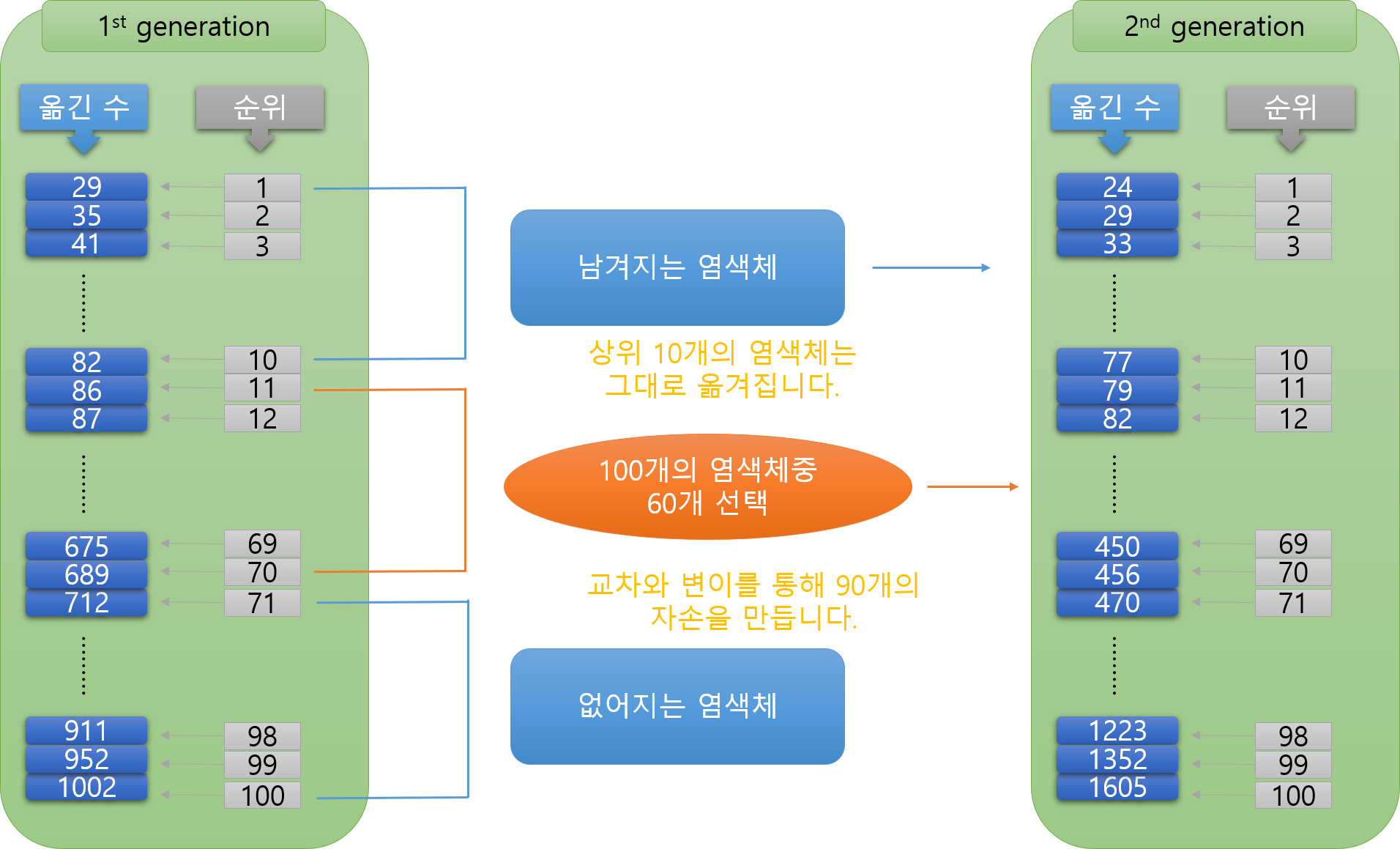
이후 60개를 통해 90개의 염색체가 교차를 통해 70개의 염색체를 생성하고, 변이를 통해 20개의 염색체를 생성한다.
새로 생성되는 염색체 (100개)
- 10개: 상위 10개 그대로 가져옴
- 70개: 교차를 통해 생성
- 20개: 변이를 통해 생성
선택받지 못한 염색체 30개는 소멸된다.
[2] 교차를 통해 진화하기
교차는 유전 알고리즘에서 자연 선택된 해들을 교배를 통해 다음 세대의 해들을 생성하는 방식이다.
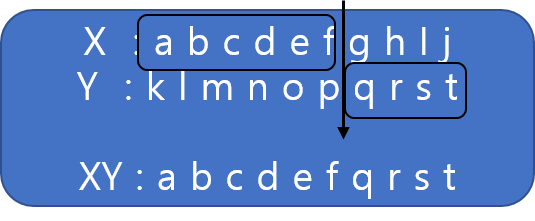
예를들면, 염색체 X에서 유전인자(abcdef)를 선택하고 염색체 Y에서 유전인자(qrst)를 선택한다. 염색체 X와 Y의 교차인 XY 염색체는 염색체 X의 유전인자(abcdef)와 염색체 Y의 유전인자(qrst)가 합쳐진 유전인자(abcdefqrst)를 가진다.
하노이탑 AI 에서 교차시키는 방법을 아래 그림을 통해 예시를 들어 설명하겠다.
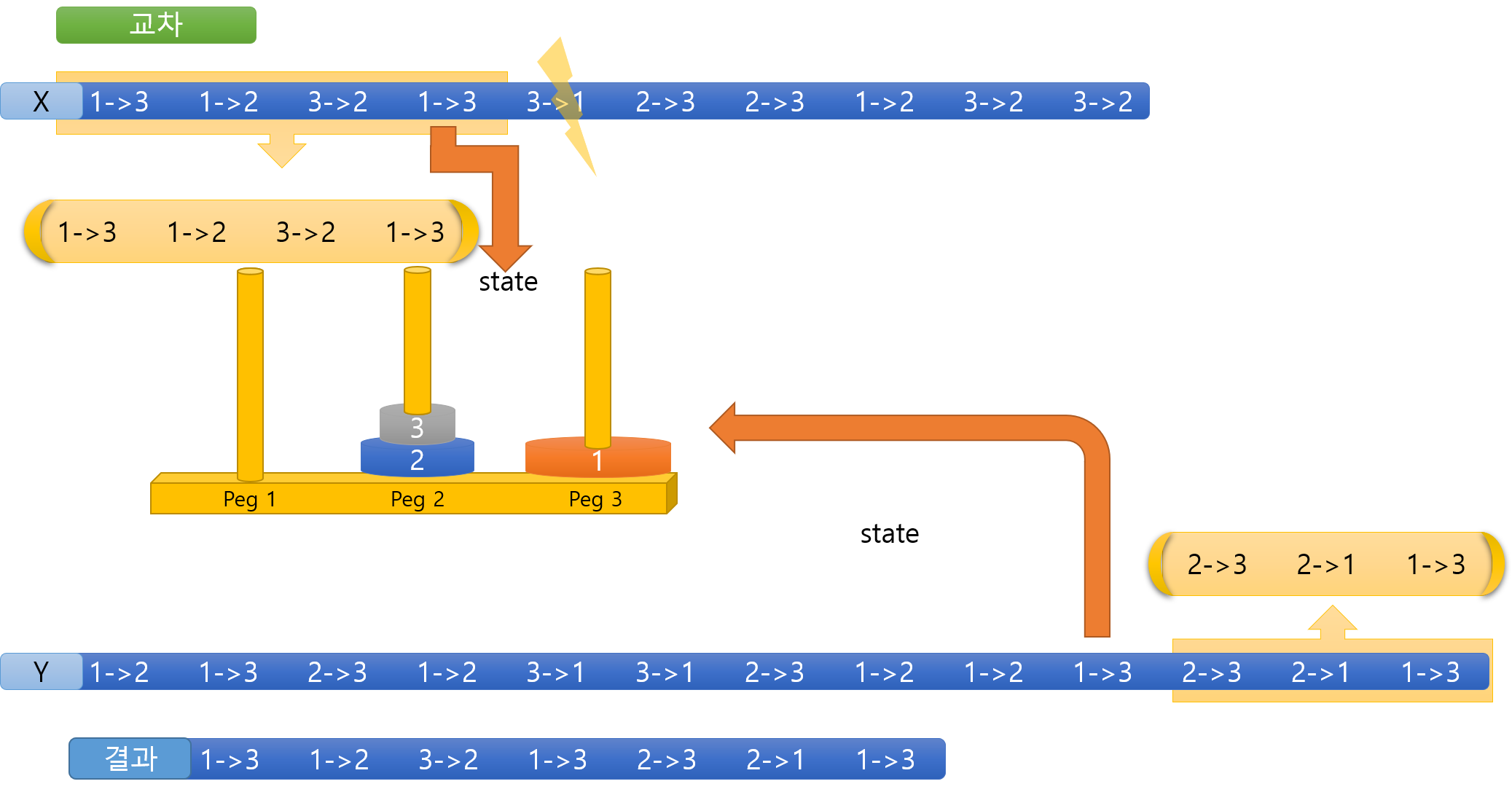
두개의 염색체(X, Y)를 다음과 같은 방식으로 선택한다.
- X 염색체에 임의로 유전인자 중 하나를 선택한다.
- X 염색체의 유전인자의 마지막 부분의 상태(000, 011, 100)와 같은 유전인자를 Y염색체에서 찾는다.
이 때 Y염색체의 유전인자는 뒤에서부터 찾는다. - X 염색체에서 찾은 유전인자의 앞부분만 따로 가져온다.
 4. Y염색체에서 찾은 유전인자의 뒷부분만 따로 가져온다.
4. Y염색체에서 찾은 유전인자의 뒷부분만 따로 가져온다.

- 둘을 합친 XY 염색체가 만들어진다.

[3] 변이를 통해 진화하기
변이는 주어진 해의 염색체 내 유전 인자의 순서 혹은 값이 임의로 변경되어 다른 해로 변형되는 연산이다.
하노이탑 AI 에서 변이를 하는 방법은 아래 그림을 통해 예시를 들어 설명하겠다.
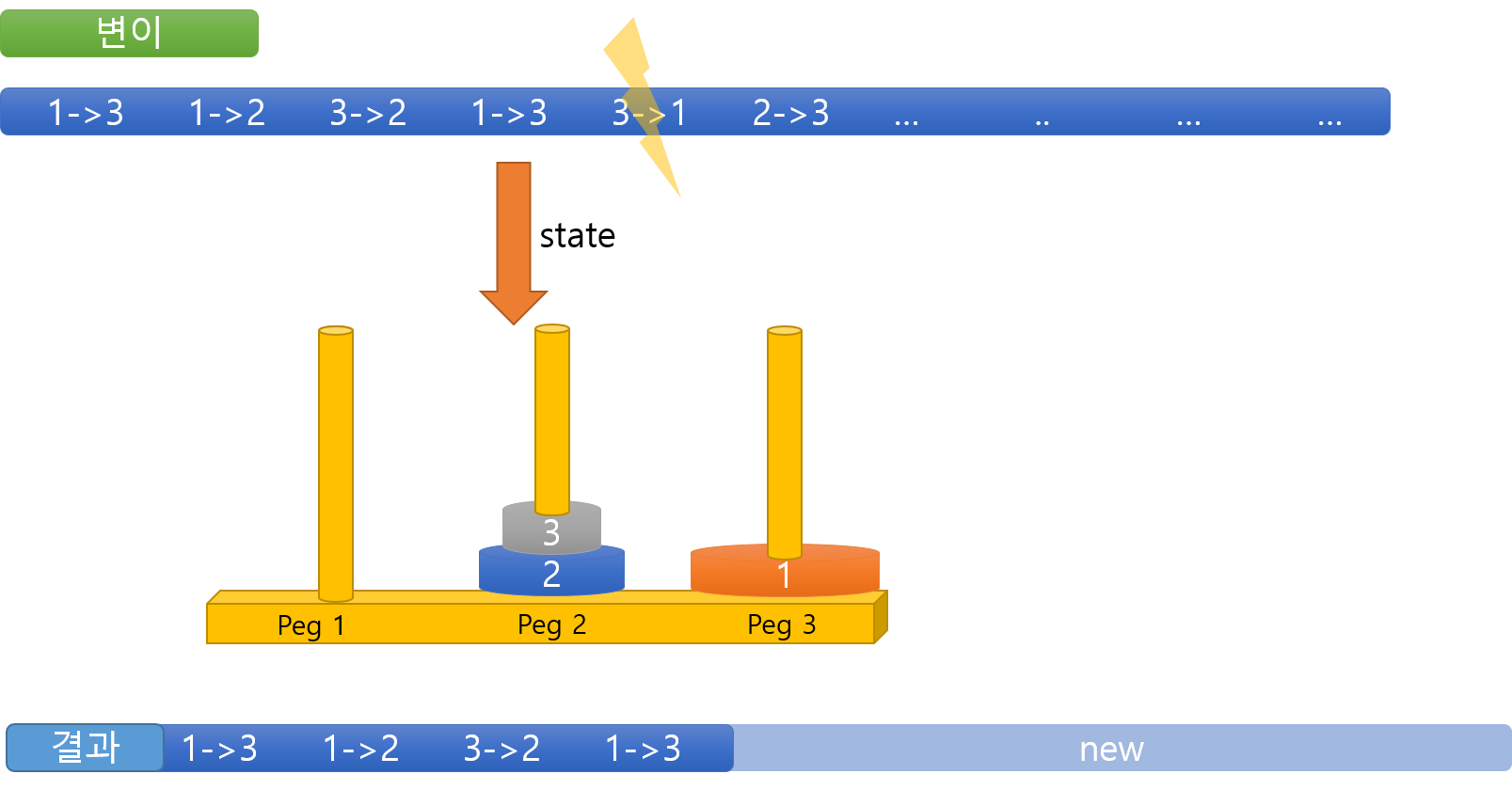
염색체에서 임의로 유전인자 중 하나를 선택한다. 그 후 그 뒤에있는 유전인자를 전부 제거한다.
그럼 다음과 같은 X 염색체가 나온다.
X 염색체는 아직 성공하지 못한 상태이다. 그래서 성공한 상태로 만들기 위해 기본 알고리즘을 사용하여 나머지 부분을 생성한다.

3. OpenCV를 이용하여 영상 받아오기
OpenCV는 실시간 영상 처리를 사용할 수 있는 프로그래밍 라이브러리 이다.
막대와 고리의 위치 및 개수 파악
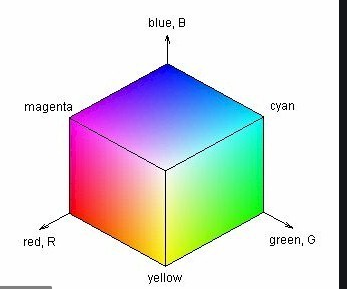
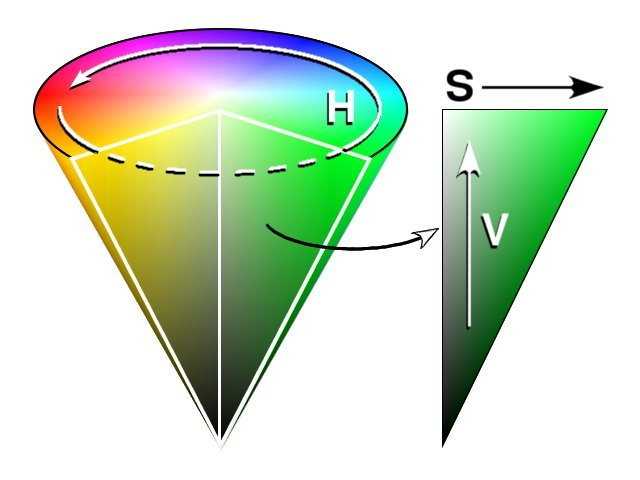
색변환 (RGB → HSV)
RGB는 색상을 표현할 때 3채널로 직관적인 색을 세부적으로 구현하는데 초점을 두는 반면, HSV는 실제 색상을 기준으로 한 상태에서 채도(S)와 명도(V)의 차이를 두며 변경하는 방식이다.
색을 기준으로 고리를 구별할 때 HSV색공간을 사용하면 H(색상)값을 조절하여 색을 구별할 수 있다. 그래서 RGB에서 HSV로 색공간을 변화하였다.
라벨링
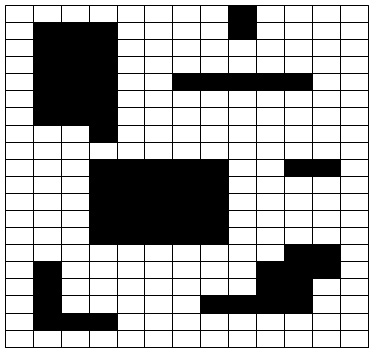
라벨링은 영상을 흰색과 검은색으로만 구성된 이진화 영상으로 바꾸고 각 흰색 영역들을 구분하기 위해 영역마다 점수를 부여하는 것이다.
이진화 기법으로 배경과 객체를 구별한다. 객체로 나뉘면, 서로 떨어진 곳의 객체와는 서로 다른 객체일 가능성이 크기 때문에 이를 독립적인 객체로 분류하는 작업이 필요하다. 이 때 사용되는 것이 라벨링 기법이다.
검은색 픽셀(0)은 배경으로 인식하고, 흰색 픽셀(255)은 객체로 간주한다. 라벨링을 실행할 때, 서로 연결된 흰색 픽셀의 집합이 하나의 객체로 인식된다. 인식된 것들에 고유번호를 붙이고 다음 흰색 픽셀을 탐구하며 새로운 집합을 탐색하고 또 거기에 고유번호를 붙이는 방식으로 구분한다.
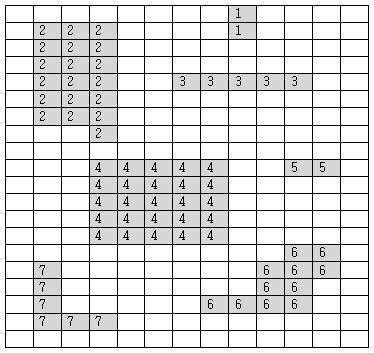
라벨링 과정을 통해 색깔이 다른 각 고리마다 숫자를 부여한다.
예) 고리가 큰 순서대로 (빨강, 파랑, 회색) 번호를 부여하면, 그림과 같이 숫자가 부여된다.
고리에 숫자를 부여하는 과정이 끝나면 이제 기본 알고리즘으로 첫 세대를 생성한다.
첫 세대가 생성되고 나면 유전 알고리즘을 통해 다음 세대를 생성한다.
상위 10개의 염색체에서 모두 같은 횟수를 가지면 최적해를 도출했다고 판단하여 사용자에게 UI로 고리를 옮기는 방법을 보여준다.
프로젝트를 마치며
한계점
프로젝트에서 해결하지 못한 한계점이 존재하였다.
- 색인식을 활용하였기 때문에 비슷한 색(ex. 초록색, 연두색)의 고리가 붙어있을 경우 하나의 고리로 인식한다.
- H값 더불어 S, V를 조절하였지만 해결하지 못하였다.
- 색인식을 활용하였기 때문에 조명에 영향을 많이 받는다.
- 프로젝트를 시연할 때 조명 환경에 따라 H,S,V 값을 조절해야 했다.
- 고리가 7개를 넘어가면 프로그램이 답을 도출하지 못한다.
- 내가 구현한 유전 알고리즘의 한계점이다.
- 최적의 해가 아닐 수 도 있다.
- 고리 갯수가 많아질 수 록 최적해가 아닐 확률도 증가했다.
느낀점
알고리즘의 중요성을 뼈저리게 느끼게 해준 프로젝트였다. (감사한 프로젝트)
한계점에 부딪히고 있을 때 BFS 알고리즘을 사용하면 훨씬 빠르게 구현할 수 있었다는 것을 선배님께서 말씀해주셨다. 그래서 실험해보니 해결책을 도출하는데 1초도 안걸렸다. 🫢
알고리즘을 아는 것과 모르는 것은 마치 요리를 할 때 레시피를 아는 것과 모르는 것의 차이인거 같다. 레시피를 모르면 많은 노력과 시간을 들여 레시피와 비슷한 맛을 낼 수 있을 수 있다. 또는 그렇게 투자를 했는데도 비슷한 맛을 내지 못할 수 도 있다.
알고리즘을 공부해야겠다고 생각하여 이 프로젝트가 끝나고 난 뒤 알고리즘 스터디를 8개월간 참여하였다. 지금도 계속 알고리즘을 공부하고 PS 문제를 푸는 등 나중에 시간 낭비를 하지 않게 대비하고 있다.
