Feature Scaling?
normalization 에 대해 이해하려면 feature scaling 의 개념에 대해 알아야 합니다. feature scaling 은 서로 다른 feature 값들을 동일한 척도로 바꾸어 주는 작업을 말합니다. 이 작업은 feature 의 값이 크게 차이 난다고 해서 차이 나는 값 자체들에 차이를 두지 않게 하기 위한 것입니다. 예를 들면 색을 나타낼 때 0-255 값으로 나타낼 수 있지만, 이 0부터 255 의 값이 서로 다른 중요도를 가지고 있지는 않습니다. 0부터 255 값이 서로 다른 중요도를 가지지 않는 것처럼 대하기 위해 0-1 사이의 값으로 바꿔주는 작업이 feature scaling 작업의 대표적인 예 중에 하나라고 할 수 있겠습니다!
Z-Score 표준화?
아마 고등학교 통계 시간에 들어보셨을겁니다. z-score 표준화는 모든 피쳐들의 값의 평균을 0으로 만들고 표준 편차가 1이 되게끔 수를 바꿔줍니다.
BN 의 필요성(Internal Covariate Shift)
입력값들이 네트워크나 레이어를 통과하게 되면서 입력 분포가 달라지게 되는 현상을 Internal Covariate Shift 라고 합니다. 이런식으로 레이어가 많이 붙게 된다면 분포가 처음과는 엄청 달라질 것입니다. 이 때문에 레이어 중간중간에 출력값의 분포를 규제할 수 있도록 하는 BN 의 필요성이 대두 된 것 입니다.
Batch Normalization

이 사진의 마지막 수식을 보면 normalize 된 값을 scaling 하고 shifting 시키는 과정이 있습니다. 스케일링과 쉬프팅은 값들을 계속 정규화 하게 되면 activation 함수의 비선형성을 잃어버릴 수도 있는데, 이를 막기 위해 진행 되는 step 이고, 스케일 변수 감마와 쉬프트 변수 베타는 역전파를 통해 학습이 되는 값들입니다.
With VS Without BN
tensorflow 코드를 통해 간단하게 BN 을 넣지 않은 버전과 넣은 버전의 모델을 테스팅 해봤습니다. (코드는 https://github.com/soomin9106/Deep-Learning/tree/main/CNN 에 있습니다!)
BN 을 넣지 않은 버전의 정확도는 다음과 같습니다. (테스트 evaluation 을 기준으로 봐주세요!)
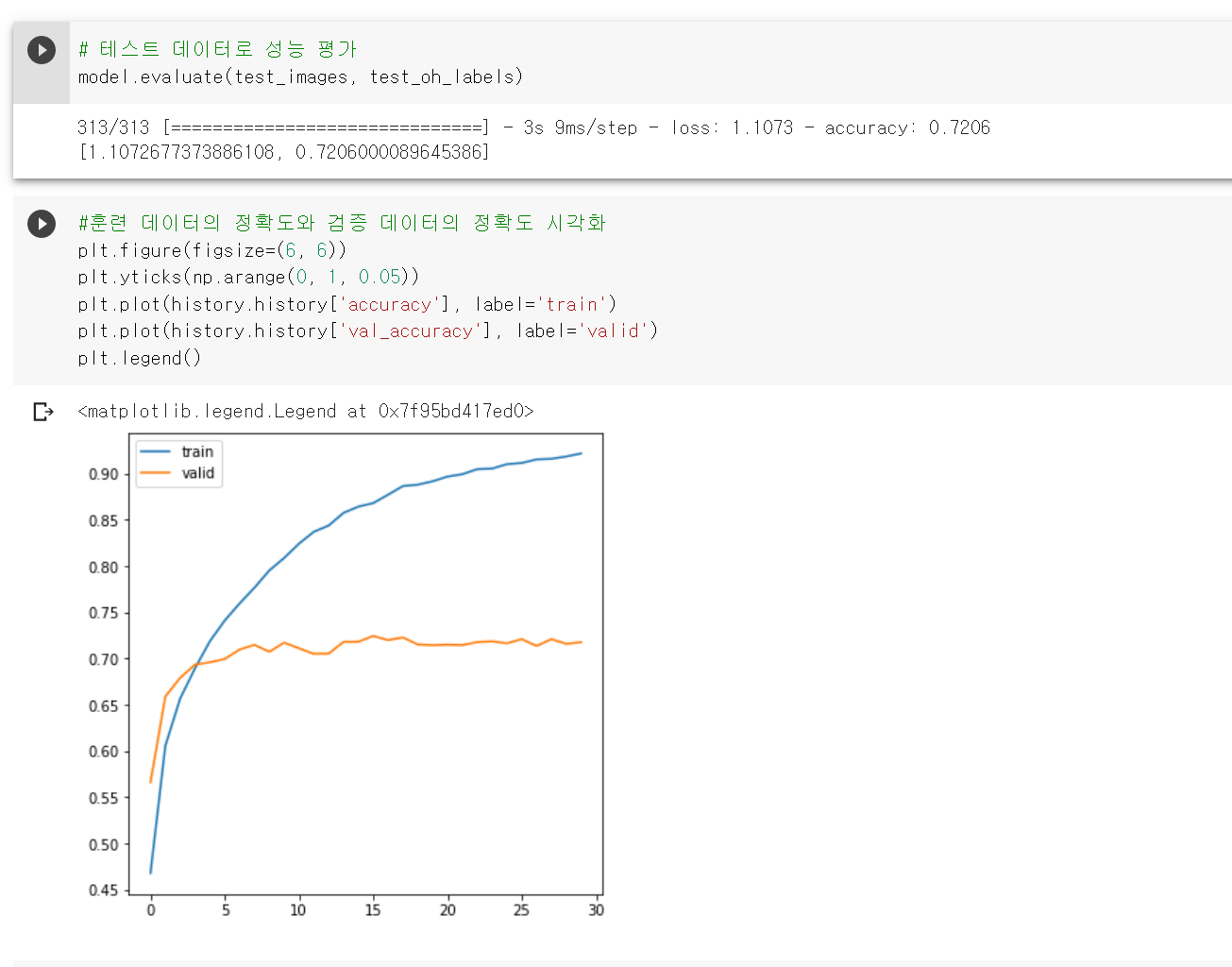
BN 을 포함한 버전의 정확도는 다음과 같습니다.
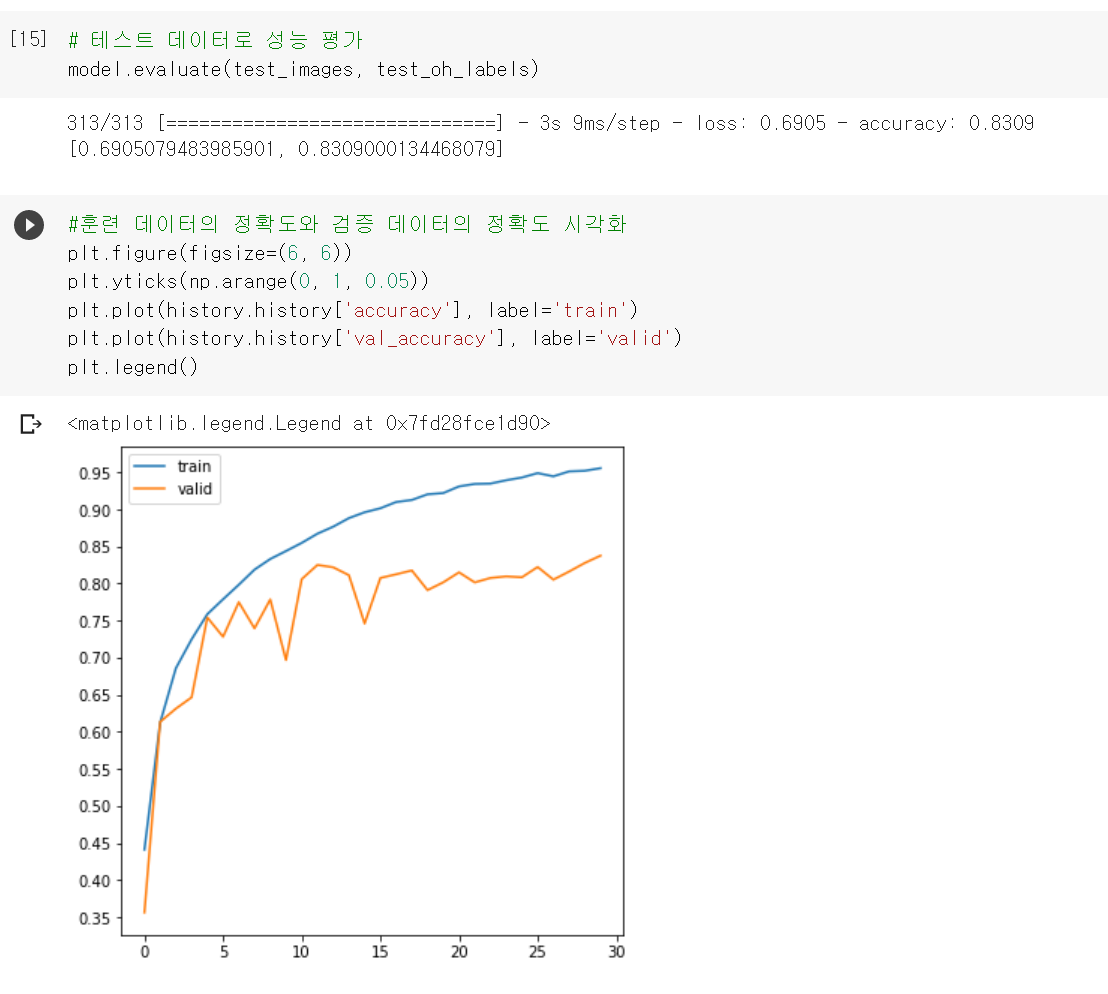
test data 로 검증 해봤을 때도 약 0.1 정도 차이가 나고 validation accuracy 또한 BN 을 포함 했을 때 더 높은 것을 확인 할 수 있습니다!
테스트 데이터의 정확도가 나오지 않을 때 BN 을 적용 했는지 안했는지 체크 해보고 모델을 테스트 해보면 좋을 것 같습니다 ㅎㅎ
