이상치 탐지 분야에서 T(Teacher)-S(Student) 구조의 모델들의 문제점을 짚고, 기존 T-S 모델과는 다른 구조의 새로운 모델을 제안하는 2022년도 논문이다. MvTec 데이터를 가지고 실험이 진행 되었고, 현재 다른 SOTA 들과 비슷하거나 높은 성능을 내고 있다.
기존 T-S 모델의 문제점과 논문이 제시한 해결책
그렇다면 기존 T-S 모델의 문제점은 무엇인가?
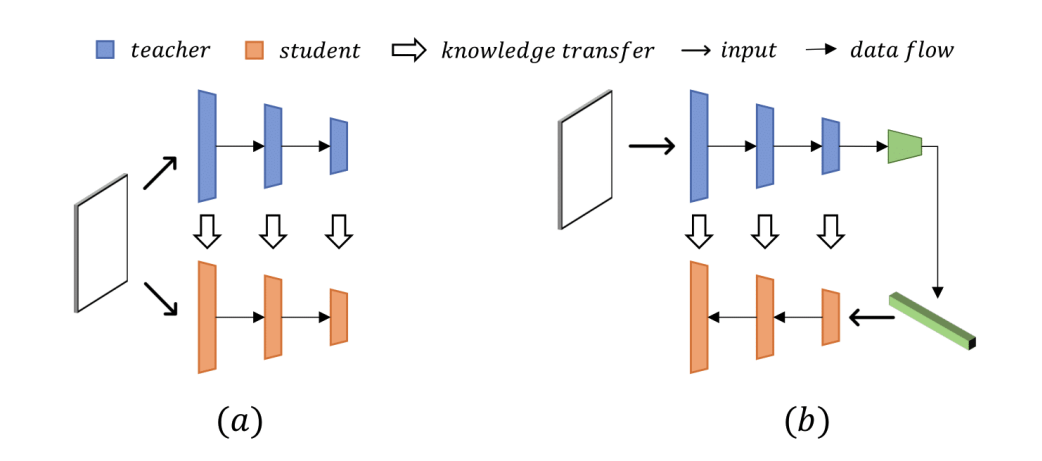
위 이미지의 (a) 를 보면 이를 이해할 수 있다. 기존 T-S 모델을 통한 이상치 탐지에서는 S 모델은 정상 이미지로만 훈련 되었으니까 이상치 이미지가 test 이미지로 들어오게 되면 T 모델과는 다른 representation 을 만들어 낼거야 라는 가정이 있었다. 이 논문에서는 이와 같은 말이 틀린 가정은 아니지만 예외 상황이 있을 것이라고 했다. T 모델과 S 모델은 아키텍쳐가 비슷하거나 같기 때문에 이상치 이미지가 들어왔을 때 비슷한 representation 을 만들어 낼 수도 있고, 같은 데이터를 인풋으로 받기 때문에 이상치를 잘 감지할 수 있는 가능성이 낮아질 수 있다.
이 논문에서는 위에 말한 2가지의 문제점을 해결하는 새로운 T-S 모델 아키텍쳐를 주장한다. T 모델을 feature 을 추출하는 encoder 로 만들고, S 모델을 feature 를 복원하는 decoder 로 만들어서 T,S 모델의 아키텍쳐를 다르게 만들었다. 또한 T 모델의 인풋값은 이미지 이지만, S 모델의 인풋값을 논문에서 제시하는 또 다른 개념인 One Class Embedding 이라는 집약적인 feature 로 하여 두 모델의 인풋값을 다르게 만들어 주었다.
모델 아키텍쳐
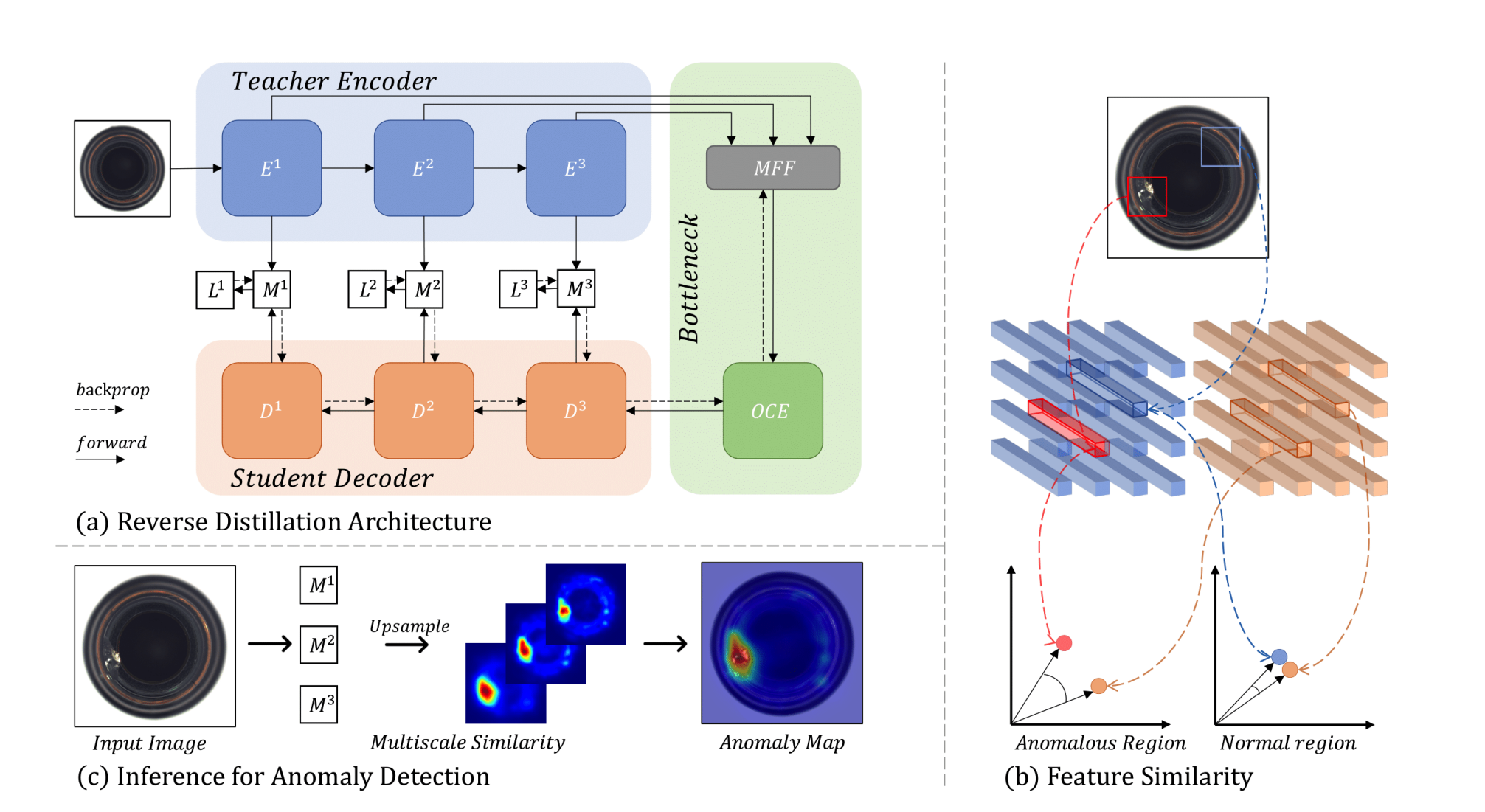
모델 아키텍쳐는 다음과 같다.
(a) 앞서 말한 것처럼 T 모델은 encoder 이고 S 모델은 decoder 이다. 이 모델이 훈련 시키고 자 하는 바는 D 가 E 와 최대한 비슷하게 하는 것이다. 즉, S 모델에서 복원하는 내용이 T 에서 생성한 feature 들과 최대한 비슷하게 하는 것이 목표인 것이다. 녹색 부분을 보면 S 모델의 인풋값을 만드는 아키텍쳐가 보여진다. MFF 에서 T 모델이 만들어낸 여러 개의 feature 를 하나의 feature 로 집약 시키고, 이를 훈련 가능한 OCE block 에 넣어 가장 잘 집약된 normal feature 를 훈련 시킨다.
(b) 훈련 과정을 거치면 예측 시 T 모델은 이상치 이미지의 feature 를 뽑아내지만 훈련 된 OCE 를 통해 Decoding 된 결과 값은 T 모델에서 뽑아낸 값과 많은 차이를 가지게 된다.
(c) T 모델이 만들어낸 feature 와 S 모델이 만들어낸 feature 의 유사도를 계산 한 anomaly map M 들을 통해 localization 을 수행할 수 있고, 또한 anomaly map 에서 가장 높은 점수를 계산하여 이미지 레벨의 이상치 점수를 계산할 수 있다.
모델 평가
아래 이미지는 다른 모델들과 RD 모델의 AUROC 를 비교한 것이다.
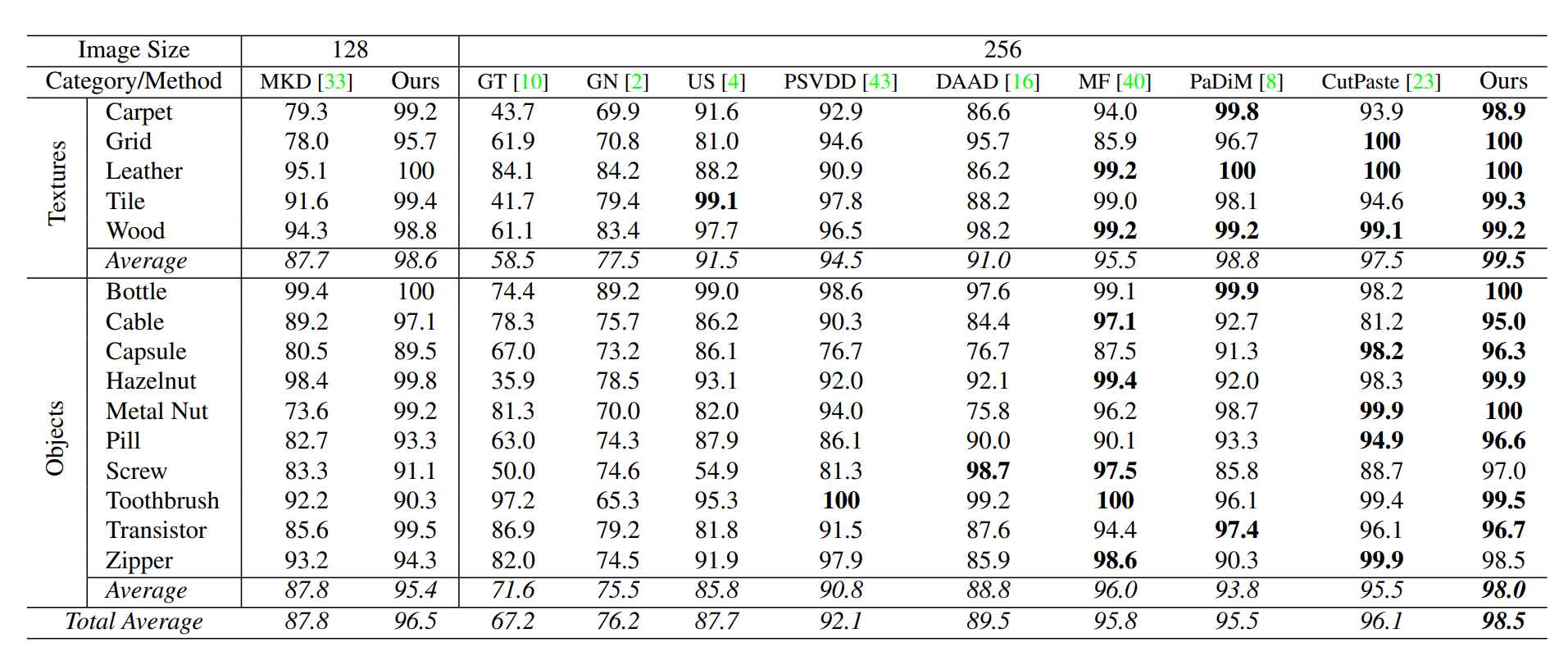
확인해보면 다른 SOTA 모델에 비해 준수한 성능을 냄을 알 수 있다.
다른 모델들과의 inference speed, memory size 를 비교한 결과이다.
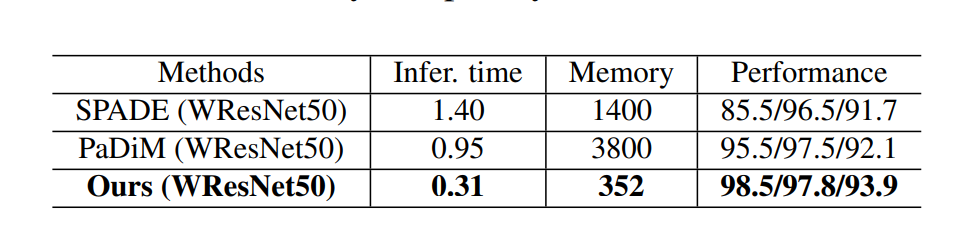
개인적으로는 요즘 Anomaly detection SOTA 모델들은 memory bank, normalizing flow 기반인 것이 많았는데, self-supervised learning 기법을 이용해서 이정도 성능이 나온 다는 것을 알 수 있게 해준 모델이었다고 생각한다.
