POJO (Plain Old Java Object)
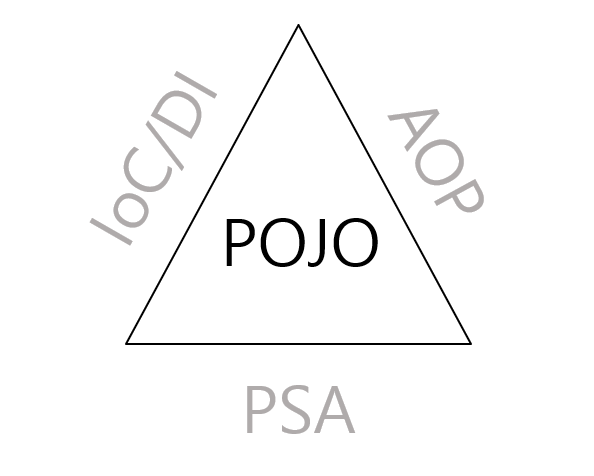
위 그림은 POJO라는 것을 IoC/DI, AOP, PSA를 통해서 달성할 수 있다는 것을 의미함.
POJO란?
POJO: Plain Old Java Object
Java로 짜여진 코드는 어떤식으로든 객체와 객체가 관계를 맺을 수 밖에 없는 객체지향 프로그래밍임. -> JO
Java로 생성하는 순수한 객체 -> PO
POJO 프로그래밍이란?
POJO 프로그래밍이란 POJO를 이용해서 프로그래밍 코드를 작성하는 것을 의미함. POJO 프로그래밍으로 작성한 코드로 불리우기 위해서는 두 가지 정도의 기본적이 규칙을 지켜주어야 함.
- Java나 Java의 스펙(사양)에 정의된 것 기오이에는 다른 기술이나 규약에 얽매이지 않아야 함
public class User {
private String userName;
private String id;
private String password;
public String getUserName() {
return userName;
}
public void setUserName(String userName) {
this.userName = userName;
}
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
}위 코드는 자바에서 제공하는 기능만 사용하여 getter, setter만 가지고 있는 코드임. 해당 클래스의 코드에서는 Java 언어 이외에 특정한 기술에 종속되어 있지 않은 순수한 객체이기 때문에 POJO라고 부를 수 있음.
public class MessageForm extends ActionForm{ // (1)
String message;
public String getMessage() {
return message;
}
public void setMessage(String message) {
this.message = message;
}
}
public class MessageAction extends Action{ // (2)
public ActionForward execute(ActionMapping mapping, ActionForm form,
HttpServletRequest request, HttpServletResponse response)
throws Exception {
MessageForm messageForm = (MessageForm) form;
messageForm .setMessage("Hello World");
return mapping.findForward("success");
}
}위 코드는 Java 코드가 특정 기술에 종속적인 예를 보여주기 위한 코드임. ActionForm 클래스는 과거에 Struts라는 웹 프레임워크에서 지원하는 클래스임. (1)에서는 Struts라는 기술을 사용하기 위해서 ActionForm을 상속하고 있음. (2)에서는 역시 Struts 기술의 Action 클래스를 상속받고 있음.
이렇게 특정 기술을 상속해서 코드를 작성하게 되면 나중에 애플리케이션의 요구사항이 변경되서 다른 기술로 변경하려면 Struts의 클래스를 명시적으로 사용했던 부분을 전부 다 일일이 제거하거나 수정해야함. 그리고 Java는 다중 상속을 지원하지 않기 때문에 'extends' 키워드를 사용해서 한 번 상속을 하게 되면 상위 클래스를 상속받아서 하위 클래스를 확장하는 객체지향 설계 기법을 적용하기 어려워지게 됨.
- 특정 환경에 종속적이지 않아야 함
서블릿(Servlet) 기반의 웹 애플리케이션을 실행시키는 서블릿 컨테이너(Servlet Container)인 아피치 톰캣(Apache Tomcat)을 예로 듦. 순수 Java로 작성한 애플리케이션 코드내에서 Tomcat이 지원하는 API를 직접 가져다가 사용한다고 가정함. 만약 시스템의 요구 사항이 변경되어서 Tomcat 말고 제티(Zetty)라는 다른 서블렛 컨테이너를 사용하게 된다면, 애플리케이션 코드에서 사용하고 있는 Tomcat API 코드들을 모두 걷어내고 Zetty로 수정하든가, 최악의 경우에는 애플리케이션을 전부 뜯어 고쳐야함.
POJO 프로그래밍이 필요한 이유
- 특정 환경이나 기술에 종속적이지 않으면서 재사용이 가능하고, 확장 가능한 유연한 코드를 작성할 수 있음
- 저수준 레벨의 기술과 환경에 종속적인 코드를 애플리ㅔ이션 코드에서 제거함으로써 코드가 깔끔해짐
- 코드가 깔끔해지기 때문에 디버깅하기도 상대적으로 쉬움
- 특정 기술이나 환경에 종속적이지 앟기 때문에 테스트 역시 단순해짐
- 객체지향적인 설계를 제한없이 적용할 수 있음
POJO와 Spring의 관계
Spring은 POJO 프로그래밍을 지향하는 Framework임. 최대한 다른 환경이나 기술에 종속적이지 않도록 하기 위한 POJO 프로그래밍 코드를 잓어하기 위해서 Spring에서는 세가지 기술을 지원하고 있음: IoC/DI, AOP, PSA
IoC(Inversion of Control)
Ioc(Inversion of Control)이란?
Library는 애플리케이션 흐름의 주도권이 개발자에게 있고, Framework는 애플리케이션 흐름의 주도권이 Framework에 있음. 여기서 마하는 애플리케이션 흐름의 주도권이 뒤바뀐 것을 IoC라고 함.
Java 콘솔 애플리케이션의 일반적인 제어권
public class Example2_10 {
public static void (String[] args) {
System.out.println("Hello IoC!");
}
}일반적으로 위와 같은 Java 콘솔 애플리케이션을 실행하려면 main() 메서드가 있어야함. 그래야 main()메서드 안에서 다른 객체의 메서드를 호출한다던가 하는 프로세스가 진행되기 때문임. 위의 코드에서는 main() 메서드가 호출되고 난 다음에 System 클래스를 통해서 static 멤버변수인 out의 println()을 호출함. 이렇게 개발자가 작성한 코드를 순차적으로 실행하는게 애플리케이션의 일반적인 제어 흐름임.
Java 웹 애플리케이션에서 IoC가 적용되는 예
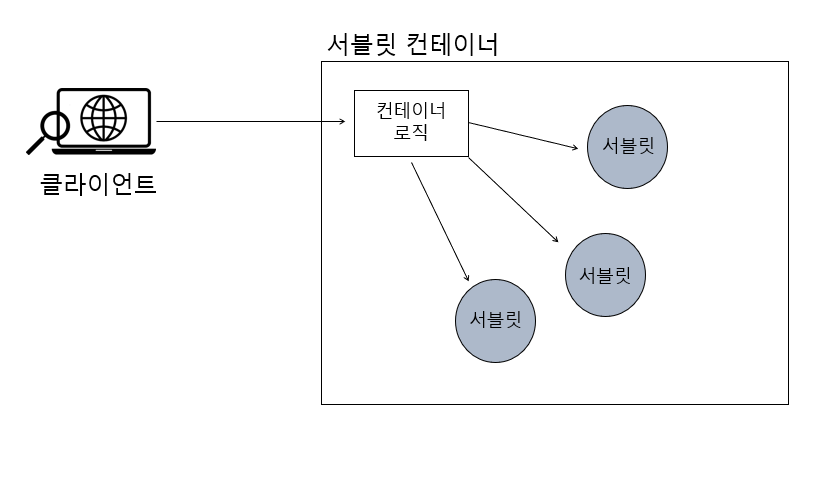
위 그림은 서블릿 기반의 애플리케이션을 웹에서 실행하기 위한 서블릿 컨테이너의 모습임. Java 콘솔 애플리케이션의 경우 main() 메서드가 종료되면 애플리케이션의 실행이 종료됨. 하지만 웹에서 동작하는 애플리케이션의 경우 클라이언트가 외부에서 접속해서 사용하는 서비스이기 때문에 main() 메서드가 종료되지 않아야 할 것. 그런데 서블릿 컨테이너에는 서블릿 사양(Specification)에 맞게 작성된 서블릿 클래스만 존재하지, 별도로 main() 메서드가 존재하지 않음.
main()메서드처럼 애플리케이션이 시작되는 지점을 엔트리 포인트(Entry point)라고 부름.
서블릿 컨테이너의 경우, 클라이언트의 요청이 들어올 때마다 서블릿 컨테이너 내의 컨테이너 로직(server() 메서드)이 서블릿을 직접 실행시켜주기 때문에 main() 메서드가 필요없음. 이 경우에는 서블릿 컨테이너가 서블릿을 제어하고 있기 때문에 애플리케이션의 주도권은 서블 컨테이너에 있음. -> 서블릿과 웹 애플리케이션간에 IoC의 개념이 적용되어져 있음.
DI (Dependency Injection)
IoC(제어의 역전)는 서버 컨테이너 기술, 디자인 패턴, 객체 지향 설계 등에 적용하게 되는 일반적인 개념인데 비해 DI(Dependency Injection)는 IoC 개념을 조금 구체화시킨 것. Dependency는 '의존하는, 종속되는'이라는 의미를 가지고 있음. Injection은 '주입'이라는 의미를 가지고 있음. DI는 '의존성 주입'이라는 의미가 됨.
What (의존성 주입이란?)
객체지향 프로그래밍에서 의존성이란 대부분 객체 간의 의존성을 의미함.
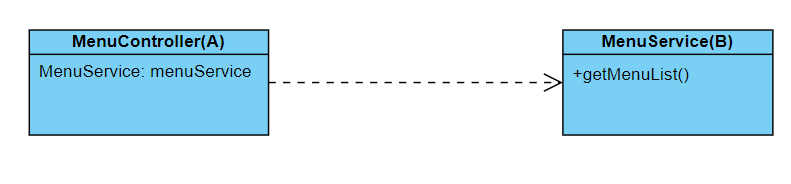
A, B라는 두 개의 클래스 파일을 만들어서 A 클래스에서 B클래스의 기능을 사용하기 위해 B 클래스에 구현되어 있는 어떤 메서드를 호출하는 상황. A 클래스가 B 클래스의 기능을 사용할 때, 'A클래스는 B클래스에 의존한다'라고 함. 'A 클래스의 프로그래밍 로직 완성을 위해 B클래스에게 도움을 요청한다' = 'B 클래스에게 의지(의존)한다'
- 클래스 간의 의존 관계 성립
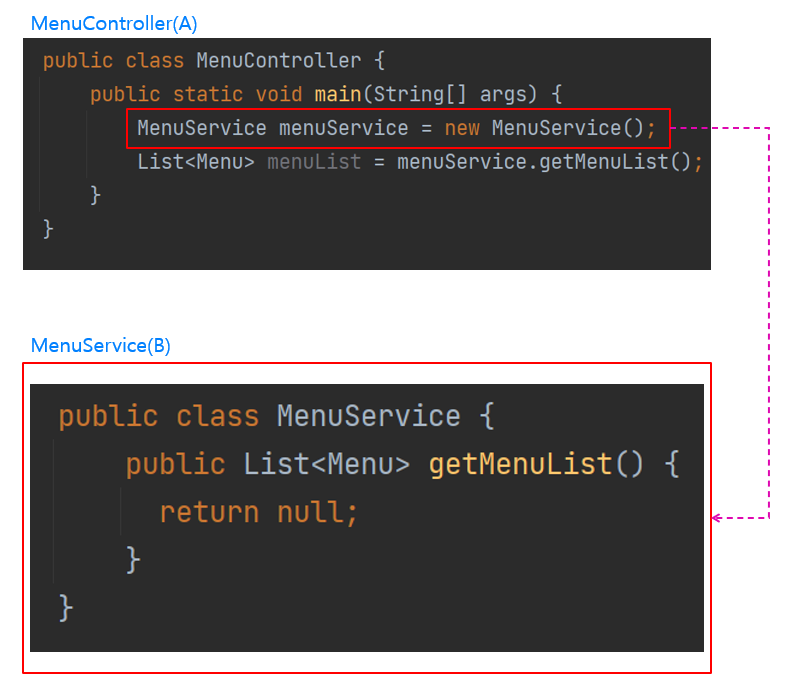
위 그림에서 MenuController 클래스는 클라이언트의 요청을 받는 엔드포인트(Endpoint) 역할을 하고, MenuService 클래스는 MenuController클래스가 전달받은 클라이언트의 요청을 처리하는 역할을 함.
클라이언트 측면에서 서버의 엔드포인트(Endpoint)란 클라이언트가 서버의 자원(리소스 Resoruce)을 이용하기 위한 끝 지점을 의미함
MenuController 클래스는 메뉴판에 표시되는 메뉴 목록을 조회하기 위해서 MenuService의 기능을 사용하고 있음. Java의 객체 생성 방법인 new 키워드를 사용해서 MenuService 클래스의 객체를 생성한 후, 이 객체로 MenuService의 getMenuList() 메서드를 호출하고 있음. 이처럼 클래스끼리는 사용하고자하는 클래스의 객체를 생성해서 참조하게 되면 의존 관계를 성립하게 됨.
두 클래스 간의 의존 관계는 성립되지만 아직까지 의존성 주입은 이루어지지 않음
- 의존성 주입
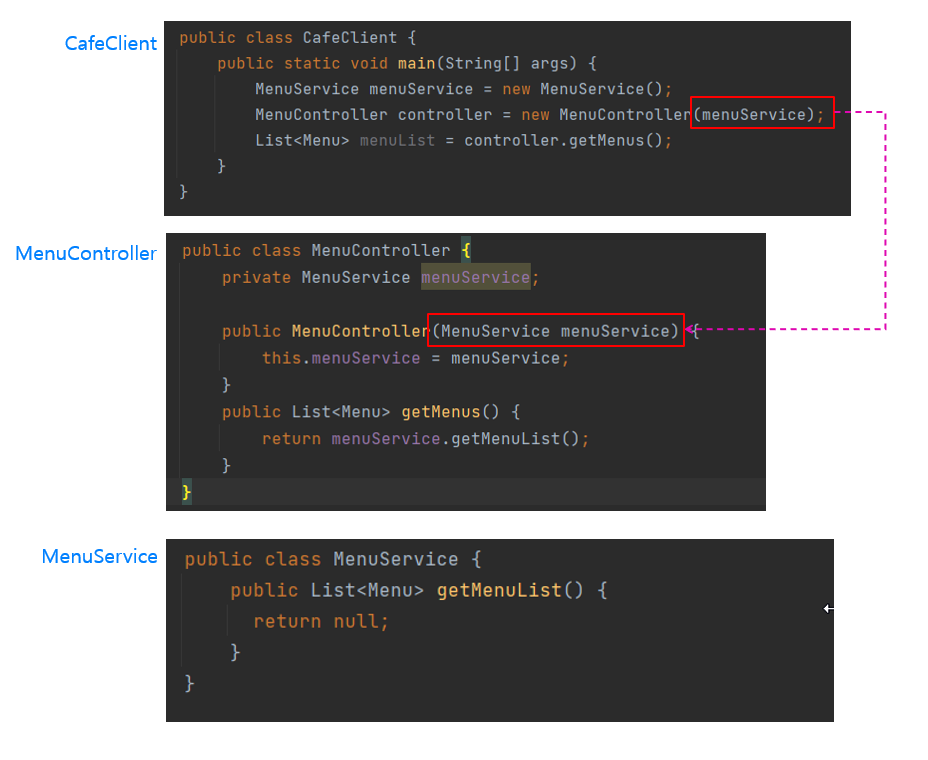
MenuController 생성자로 MenuService의 객체를 전달받고 있음. 이처럼 생성자를 통해서 어던 클래스의 객체를 전달받는 것을 '의존성 주입'이라고 함. 생성자의 파라미터로 객체를 전달하는 것을 '외부에서 객체를 주입한다'라고 표현함. 여기서 의미하는 객체를 주입해주는 '외부'는 CafeClient 클래스가 MenuController의 생성자 파라미터로 menuService를 전달하고 있기 때문에 객체를 주입해주는 외부가 됨.
Why (의존성 주입은 왜 필요할까?)
의존성 주입을 사용할 때, 항상 염두에 두어야 하는 부분: 현재의 클래스 내부에서 외부 클래스의 객체를 생성하기 위한 new 키워드를 쓸지 말지 여부를 결정하는 것임.
일반적으로 Java에서 new 키워드를 사용해서 객체를 생성하는데, Reflection이라는 기법을 이용하여 Runtime시에 객체를 동적으로 생성할 수 있는 방법도 있음.
그런데 애플리케이션 코드 내부에서 직접적으로 new 키워드를 사용할 경우 객체지향 설계의 관점에서 중요한 문제가 발생함.
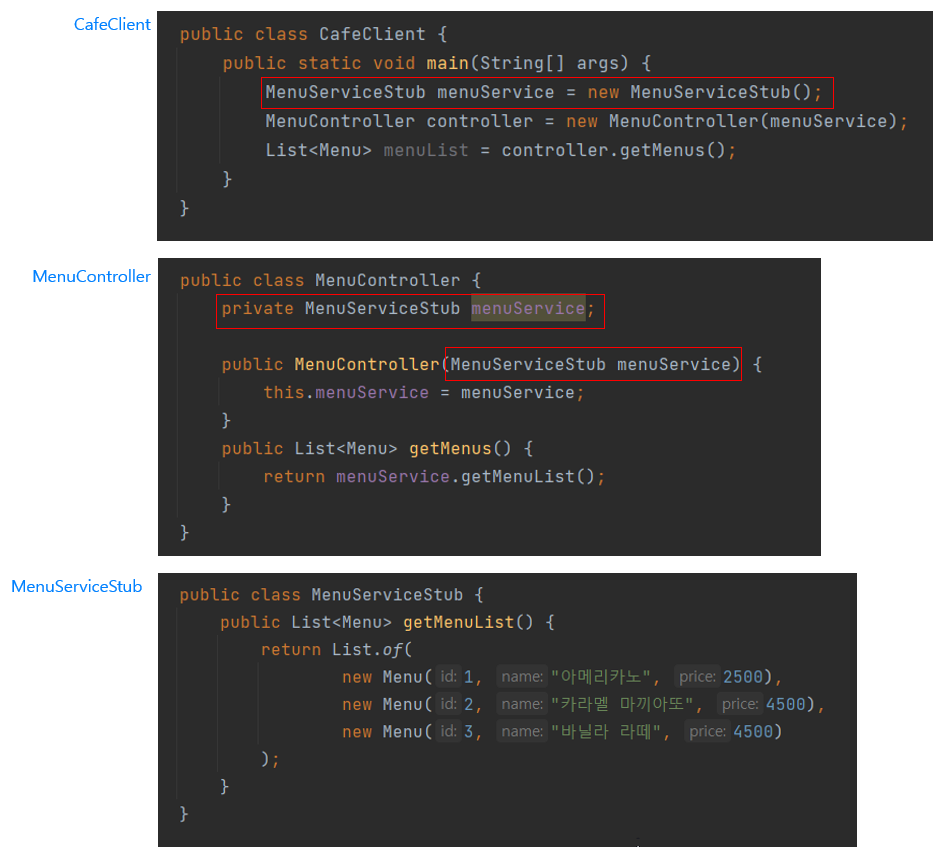
스텁(Stub)은 메서드가 호출되면 미리 준비된 데이터를 응답하는 것임. 즉, 고정된 데이터이기 때문에 몇 번을 호출해도 동일한 데이터를 리턴함. 몇 번을 호출해도 동일한 데이터를 리턴하는 것을 전문 용어로 멱등성(idempotent)을 가진다 라고 함.
메뉴 목록 조회 API로 Stub을 제공하기 위해서 MenuServiceStub 클래스를 사용한 것으로 변경되었음. MenuServiceStub 클래스를 보면 getMenuList() 에 Stub 데이터로 채워져 있는 것을 확인할 수 있음. 그런데 MenuSericeStub 클래스를 사용하려고 보니, 이 MenuService 클래스를 의존하고 있는 CafeClient와 MenuController에서 MenuService를 MenuServieStub 클래스로 불가피하게 변경해야되는 상황이 발생함.
결국 new 키워드를 사용해서 객체를 생성하게 되면 참조할 클래스가 바뀌게 될 경우 이 클래스를 사용하는 모든 클래스들을 수정할 수 밖에 없음. 이처럼 new 키워드를 사용해서 의존 객체를 생성할 때, 클래스들 간에 강하게 결합(Tight Coupling)되어 있다라고 함.
결론적으로 의존성 주입을 하더라도 의존성 주입의 혜택을 보기 위해서는 클래스들 간의 강한 결합은 피하는 것이 좋아보임. 느슨한 결합(loose coupling)이 피룡한 때임.
How (느슨한 의존성 주입은 어떻게 할까?)
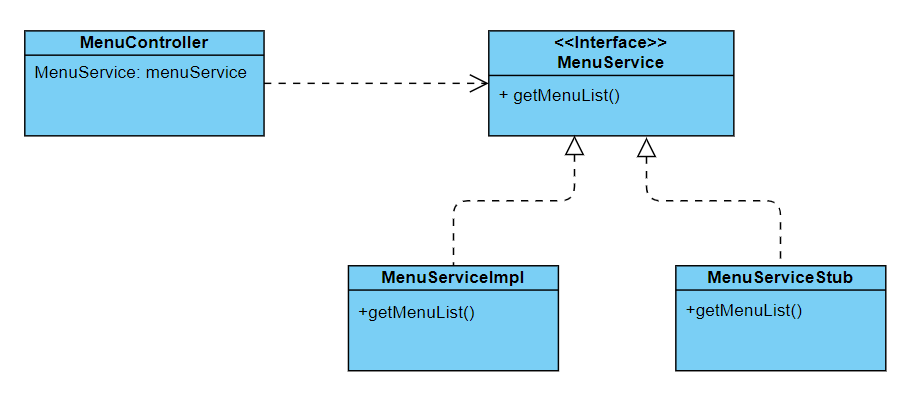
Java에서 클래스들 간의 관계를 느슨하게 만드는 대표적인 방법은 바로 인터페이스(interface)를 사용하는 것임.
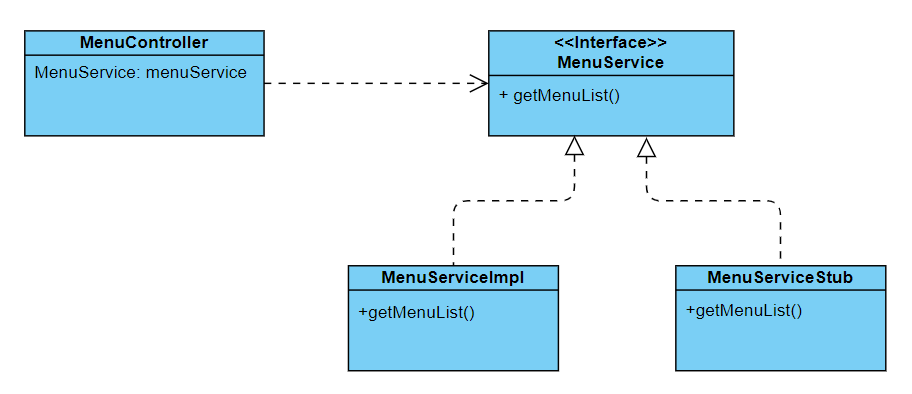
위의 사진의 클래스 다이어그램에 따르면 MenuController가 MenuService라는 클래스를 직접적으로 의존하는 것이 아니라 클래스 이름은 같지만 인터페이스를 의존하고 있음. MenuController가 MenuService를 의존하고 있지만 MenuService의 구현체는 MunuServiceImpl인지 MenuServiceStub인지 알 필요가 없음. MenuController 입장에서는 그저 메뉴 목록 데이터를 조회할 수 있으면 그만이기 때문임. 이처럼 어떤 클래스가 인터페이스같이 일반화된 구성 요소에 의존하고 있을 때, 클래스들간에 느슨하게 결합되어 있다고 함.
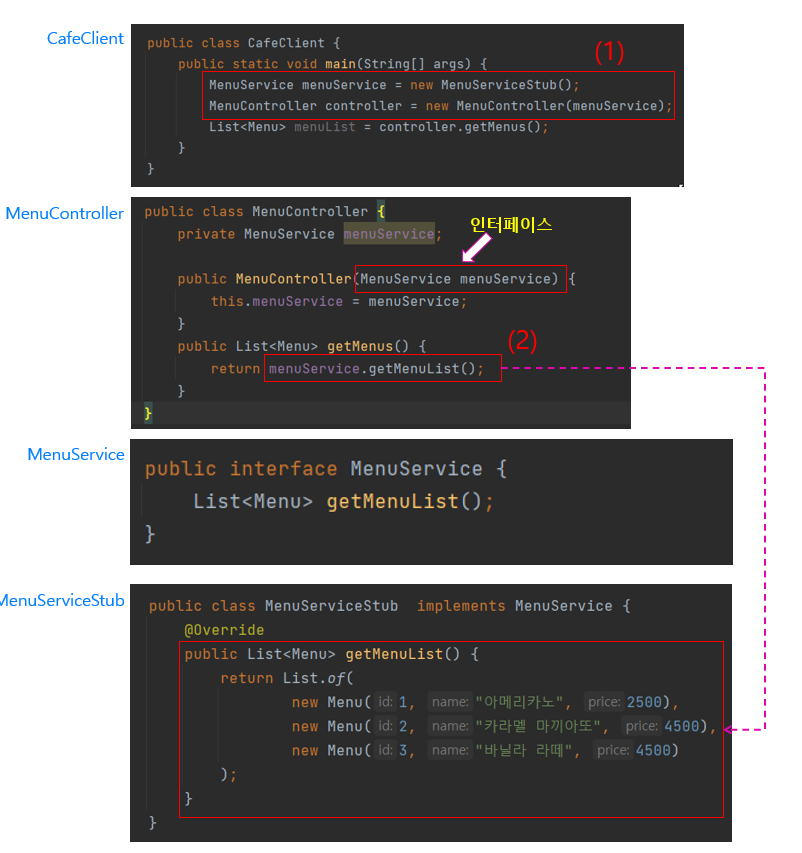
MenuController는 Stub 데이터를 받을 수 있는데도 불구하고 아무런 변경이 발생하지 않음. (1)을 보면 new로 MenuServiceStub 클래스의 객체를 생성하서 MenuService 인터페이스에 할당함. 이처럼 인터페이스 타입의 변수에 그 인터페이스의 구현 객체를 할당할 수 있는데, 이를 업캐스팅(Upcasting) 이라고 함. 이제 업캐스팅을 통한 의존성 주입으로 인해 MenuController와 MenuService는 느슨한 결합관계를 유지하게 됨.
클래스들간의 관계를 느슨하게 만들기 위해서는 new 키워드는 사용하지 않아야하는데, CafeClient 클래스의 (1)을 보면 MenuServiceStub의 객체와 MenuController 객체를 생성하기 위해 여전히 new를 사용하고 있음. 이 new 키워드는 어덯게하면 제거하고 의존한 관계를 느슨하게 만들 수 있을까? -> Spring!
Who (Spring 기반 애플리케이션에서는 의존성 주입을 누가 할까?)
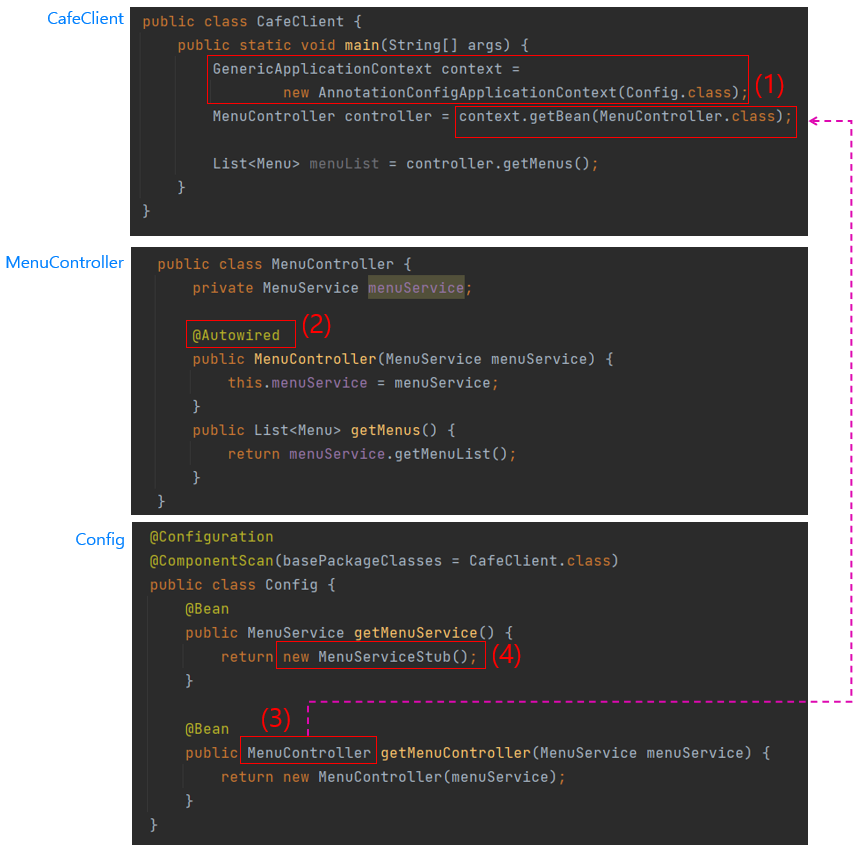
(1)의 Spring코드 덕분에 new 키워드는 없애를데 성공함. new 키워드를 없앨 수 있었던 방법 -> 위의 그림에 제일 하단에 있는 Config라는 클래스. Config 클래스에서 (3)과 같이 MenuController 객체 생성을 정의해두면 (1)을 이용해서 이 객체를 애플리케이션 코드에서 사용하게 됨. = Config 클래스에 정의해둔 MenuController 객체를 Spring의 도움을 받아 CafeClient 클래스에게 제공하고 있음.
이처럼 Spring 기반의 애플리케이션에서는 Spring이 의존 객체들을 주입해주기 때문에 애플리케이션 코드를 유연하게 구성할 수 있음.
만약 백엔드 팀에서 메뉴 목록 조회 기능을 완성했다면 이제 Stub 데이터 대신에 실제 데이터를 데이터베이스에서 제공해주면 된텐데 이럴 경우 애플리케이션 코드에서 변경할 내용들이 있을까? -> (4)와 같이 Spring Framework 영역에 있는 MenuServiceStub 클래스를 MenuServiceImpl 클래스로 단 한번만 변경해주면 됨.
AOP (Aspect Oriented Programming)
AOP (Aspect Oriented Programming)이란?
관심 지향 프로그래밍. 애플리케이션에 필요한 기능 중에서 공통적으로 적용되는 공통 기능에 대한 관심.
공통 관심 사항과 핵심 관심 사항
애플리케이션을 개발하다보면 애플리케이션 전반에 걸쳐 공통적으로 사용되는 기능들이 있기 마련인데, 이러한 공통 기능들에 대한 관심사를 바로 공통 관심 사항(Cross-cutting concern) 이라고 함. 비즈니스 로직, 즉 애플리케이션의 주목적을 달성하기 위한 핵심 로직에 대한 관심사를 핵심 관심 사항(Core Concern) 이라고 함.
핵심 관심 사항에 반대되는 개념으로 공통 관심 사항을 부가적인 관심 사항이라고 표현하기도 함
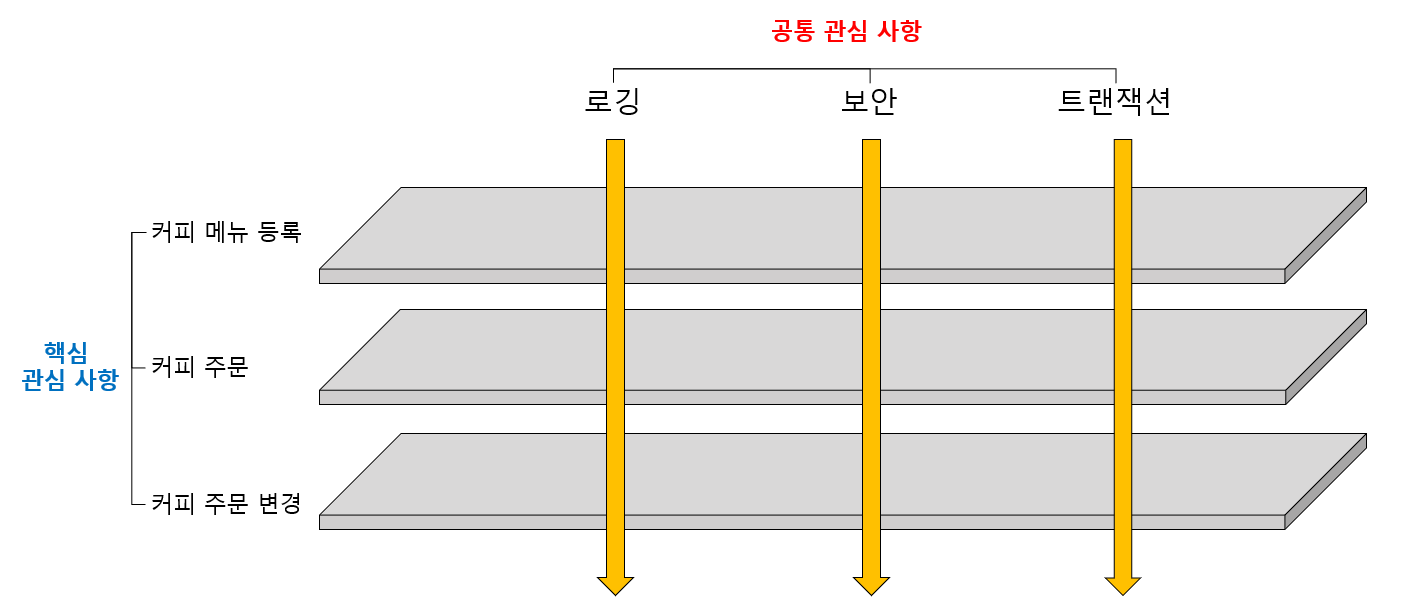
커피 주문을 위한 애플리케이션을 에로 들면, 커피 전문점의 주인이 고객에게 제공하는 커피 메뉴를 구성하기 위해 커피 종류를 등록하는 것과 고객이 마시고 싶은 커피를 주문하는 기능은 애플리케이션의 핵심 관심 사항에 해당됨. 하지만 커피 주문 애플리케이션에 아무나 접속하지 못하도록 제한하는 애플리케이션 보안에 대한 부분은 애플리케이션 전반에 공통적으로 적용되는 기능이기 때문에 공통 관심 사항에 해당됨.
그림에서 보다시피 로깅, 보안, 트랙잭션같은 공통 관심 사항 기능들의 화살표가 애플리케이션의 핵심 관심 사항들을 관통하고 있음. 이것은 공통 관심 사항의 기능들이 애플리케이션의 핵심 로직에 전반적으로 두루 사용된다는 의미임. 그리고 공통 관심 사항이 핵심 관심 사항에 멀찌감치 떨어져있는 것을 볼 수 있는데, 이는 공통 관심 사항이 핵심 관심 사항에서 분리되어 있다는 것을 의미함.
결국 AOP라는 것은 애플리케이션의 핵심 업무 로직에서 로깅이나 보안, 트랜잭션같은 고통 기능 로직들을 분리하는 것임.
AOP가 필요한 이유
AOP가 필요한 이유
애플리케이션의 핵심 로직에서 공통 기능을 분리하는 이유
- 코드의 간결성 유지
- 객체 지향 설계 원칙에 맞는 코드 구현
- 코드의 재사용
애플리케이션의 핵심 로직에 공통적인 기능의 코드들이 여기저기 보이면 코드 자체가 복잡해짐. 코드 구성이 복잡해짐에 따라 버그가 발생할 가능성도 높아지고 유지 보수도 당연히 어려워지게 되는 코드가 될 가능성이 높음. 그리고 만약 이런 공통 기능들에 수정이 필요하게 되면 애플리케이션 전반에 적용되어있는 공통 기능에 해당하는 코드를 일일이 수정해야하는 치명적인 문제가 발생함.
public class Example2_11 {
private Connection connection;
public void registerMember(Member member, Point point) throws SQLException {
connection.setAutoCommit(false); // (1)
try {
saveMember(member); // (2)
savePoint(point); // (2)
connection.commit(); // (3)
} catch (SQLException e) {
connection.rollback(); // (4)
}
}
private void saveMember(Member member) throws SQLException {
PreparedStatement psMember =
connection.prepareStatement("INSERT INTO member (email, password) VALUES (?, ?)");
psMember.setString(1, member.getEmail());
psMember.setString(2, member.getPassword());
psMember.executeUpdate();
}
private void savePoint(Point point) throws SQLException {
PreparedStatement psPoint =
connection.prepareStatement("INSERT INTO point (email, point) VALUES (?, ?)");
psPoint.setString(1, point.getEmail());
psPoint.setInt(2, point.getPoint());
psPoint.executeUpdate();
}
}트랜잭션 기능에 대해 AOP가 적용되지 않은 예제코드.
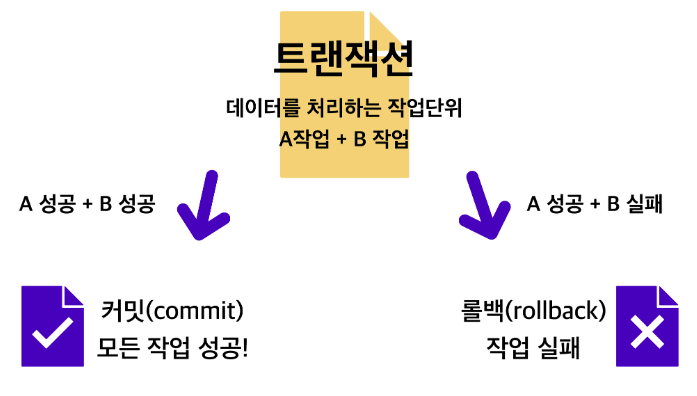
트랜잭션(Transaction)이란 '데이터를 처리하는 하나의 작업 단위'를 의미함. 예를 들어 데이터베이스에 A 데이터와 B 데이터를 두 번에 걸쳐 각각 insert하는 작업을 하나의 트랜잭션으로 묶는다면 A 데이터와 B 데이터는 모두 데이터베이스에 저장되든가 아니면 둘 중에 하나라도 오류로 인해 저장되지 않는다면 A, B 데이터는 모두 데이터베이스에 반영되지 않아야 함 (All or Nothing).
이러한 처리를 위해 일반적으로 트랙잭션에는 커밋(commit) 또는 롤백(rollback)이라는 기능이 있음. 커밋은 모든 작업이 성공적으로 수행됐을 경우 수행한 작업을 데이터베이스에 반영하는 것이고, 롤백은 작업이 하나라도 실패한다면 이전에 성공한 작업들을 작업 수행 이전 상태로 되돌리는 것을 말함.
위의 코드는 registerMember() 메서드는 커피 주문 애플리케이션을 사용할 회원 정보를 등록하는 기능을 함. registerMember() 메서드 내에서 실제로 비즈니스 로직을 수행하는 코드는 회원정보를 저장하는 (2)의 saveMember()와 회원의 포인트 정보를 저장하는 savePoint()임. 이 외에 (1)의 connection.setAutoCommit(false나 (3)의 connection.commit(), (4)의 connection.rollback()은 saveMember()와 savePoint() 작업을 트랜잭션으로 묶어서 처리하기 위한 기능들임. 문제는 이렇게 트랜잭션 처리를 하는 코드들이 애플리케이션의 다른 기능에도 중복되어 나타날 것임.
서버 애플리케이션은 데이터베이스에 데이터를 저장하는 기능없이 구성되는 것은 사실상 불가능함. 이처럼 애플리케이션 전반에 걸쳐서 트랜잭션 관련한 중복된 코드가 수도 없이 나타난다면, 중복된 코드를 공통화해서 재사용 가능하도록 만들어야함. 이러한 이 공통화 작업은 AOP를 통해서 할 수 있음. Spring에서는 이미 이런 트랜잭션 처리 기능을 AOP를 통해서 공통화해둠.
@Component
@Transactional // (1)
public class Example2_12 {
private Connection connection;
public void registerMember(Member member, Point point) throws SQLException {
saveMember(member);
savePoint(point);
}
private void saveMember(Member member) throws SQLException {
// Spring JDBC를 이용한 회원 정보 저장
}
private void savePoint(Point point) throws SQLException {
// Spring JDBC를 이용한 포인트 정보 저장
}
}위의 코드는 Spring AOP 기능을 사용하여 registerMember()에 트랜잭션을 적용한 예제 코드임. 트랜잭션 처리를 위한 코드들이 모두 사라지고 순수하게 비즈니스 로직을 처리하기 위한 saveMember(member)와 savePoint(point)만 남음.
(1)의 @Transactional 애노테이션 하나만 붙이면 Spring 내부에서 이 애노테이션 정보를 활용해서 AOP 기능을 통해 트랜잭션을 적용함.
이처럼 AOP를 활용하면 애플리케이션에 전반에 걸쳐 적용되는 공통 기능(트랜잭션, 로깅, 보안, 트레이싱, 모니터링) 등을 비즈니스 로직에서 깔끔하게 분리하여 재사용 가능한 모듈로 사용할 수 있음.
PSA(Portable Service Abstraction)
PSA(Portable Service Abstration)란?
추상화(Abstraction)의 개념
어떤 클래스의 본질적인 특성만을 추출해서 일반화하는 것이 추상화임.
추상화의 예
예를 들어 미취학 아동을 관리하는 애플리케이션을 설계하면서 아이 클래스를 일반화(추상화)한다고 가정해봄. Java의 클래스는 속성을 나타내는 멤버 변수와 동작을 나타내는 메서드로 구성되므로 아기의 속성과 동작을 일반화해서 멤버 변수와 메서드로 표현하도록 함. 먼저 아이를 관리하는 관점에서 아이의 일반적인 속성으로는 이름, 키, 몸무게, 혈액형, 나이 등이 있음. 일반적으로 아이가 할 수 있는 동작으로는 웃다, 울다, 자다, 먹다 등이 있음.
public abstract class Child {
protected String childType;
protected double height;
protected double weight;
protected String bloodType;
protected int age;
protected abstract void smile();
protected abstract void cry();
protected abstract void sleep();
protected abstract void eat();
}위 코드는 미취학 아동을 관리하기 위한 관점에서 아이의 일반적인 특징을 추상 클래스로 작성하였음.
추상화를 하는 이유
// NewBornBaby.java(신생아)
public class NewBornBaby extends Child {
@Override
protected void smile() {
System.out.println("신생아는 가끔 웃어요");
}
@Override
protected void cry() {
System.out.println("신생아는 자주 울어요");
}
@Override
protected void sleep() {
System.out.println("신생아는 거의 하루 종일 자요");
}
@Override
protected void eat() {
System.out.println("신생아는 분유만 먹어요");
}
}
// Infant.java(2개월 ~ 1살)
public class Infant extends Child {
@Override
protected void smile() {
System.out.println("영아는 많이 웃어요");
}
@Override
protected void cry() {
System.out.println("영아는 종종 울어요");
}
@Override
protected void sleep() {
System.out.println("영아부터는 밤에 잠을 자기 시작해요");
}
@Override
protected void eat() {
System.out.println("영아부터는 이유식을 시작해요");
}
}
// Toddler.java(1살 ~ 4살)
public class Toddler extends Child {
@Override
protected void smile() {
System.out.println("유아는 웃길 때 웃어요");
}
@Override
protected void cry() {
System.out.println("유아는 화가나면 울어요");
}
@Override
protected void sleep() {
System.out.println("유아는 낮잠을 건너뛰고 밤잠만 자요");
}
@Override
protected void eat() {
System.out.println("유아는 딱딱한 걸 먹기 시작해요");
}
}위 코드는 Child 클래스를 확장한 하위 클래스의 예임. 추상 클래스를 통해서 아이의 일반적인 특징을 Child 클래스로 작성했다면 위의 코드의 클래스들은 Child 클래스의 일반화된 동작을 자신만의 고유한 동작으로 재구성하고 있음.
public class ChildManageApplication {
public static void main(String[] args) {
Child newBornBaby = new NewBornBaby(); // (1)
Child infant = new Infant(); // (2)
Child toddler = new Toddler(); // (3)
newBornBaby.sleep();
infant.sleep();
toddler.sleep();
}
}
실행 결과
=========================================
신생아는 거의 하루 종일 자요
영아부터는 밤에 잠을 자기 시작해요
유아는 낮잠을 건너뛰고 밤잠만 자요위의 코드에서는 Child라는 상위 클래스에 일반화시켜놓은 아이의 동작을 NewBornBaby, Infant, Toddler라는 클래스로 연력별 아이의 동작으로 구체화시켜서 사용을 하고 있음. 여기서 중요한 것은 클라이언트(여기서는 ChildManageApplication 클래스의 main() 메서드)는 NewBornBaby, Infant, Toddler를 사용할 때 구체화 클래스의 객체를 자신의 타입에 할당하지 않고, (1) ~ (3)과 같이 Child 클래스 변수에 할당을 해서 접근함.
이렇게 되면 클라이언트 입장에서는 Child라는 추상 클래스만 일관되게 바라보며 하위 클래스의 기능을 사용할 수 있음. 이처럼 클라이언트가 추상화 된 상위 클래스를 일관되게 바라보며 하위 클래스의 기능을 사용하는 것이 바로 일관된 서비스 추상화(PSA)의 기본 개념임.
일반적으로 서버/클라이언트 측면에서는 서버 측 기능을 이용하는 쪽을 클라이언트라고 함. 대표적인 클라이언트는 웹 브라우저임. 코드 레벨에서 어떤 클래스의 기능을 사용하는 측 역시 클라이언트라고 불림.
서비스에 적용하는 일관된 서비스 추상화(PSA) 기법
서비스 추상화란 위와 같은 추상화의 개념을 애플리케이션에서 사용하는 서비스에 적용하는 기법임.
위 그림은 Java 콘솔 애플리케이션에서 클라이언트가 데이터베이스에 연결하기 위해 JdbcConnector를 사용하기 위한 서비스 추상화의 예임. 즉, JdbdConnector가 애플리케이션에서 이용하는 하나의 서비스가 되는 것임. Java에서 특정 데이터베이스에 연결하기 위해서는 해당 데이터베이스의 JDBC 구현체로부터 Connection을 얻어야하는데 위 그림은 이 동작을 재현해보기위한 클래스 다이어그램임. 위 그림에서 DbClient는 OracleJdbcConnection, MariaDBJdbcConnector, SQLiteJdbcConnector같은 JdbcConnector 인터페이스의 구현체에 직접적으로 연결해서 Connection을 얻는 것이 아니라 JdbcConnector 인터페이스를 통해 간접적으로 연결되어(느슨한 결합) Connection 객체를 얻는 것을 볼 수 있음.
그런데 DbClient에서 어떤 JdbcConnector 구현체를 사용하더라도 Connection을 얻는 방식은 getConnection() 메서드를 사용해야하기 때문에 동일함. 즉, 일관된 방식으로 해당 서비스의 기능을 사용할 수 있다는 의미임. 이처럼 애플리케이션에서 특정 서비스를 이용할 때, 서비스의 기능을 접근하는 방식 자체를 일관되게 유지하면서 기술 자체를 유연하게 사용할 수 있도록 하는 것을 PSA(일관된 서비스 추상화)라고 함.
// DbClient.java
public class DbClient {
public static void main(String[] args) {
// Spring DI로 대체 가능
JdbcConnector connector = new SQLiteJdbcConnector(); // (1)
// Spring DI로 대체 가능
DataProcessor processor = new DataProcessor(connector); // (2)
processor.insert();
}
}
// DataProcessor.java
public class DataProcessor {
private Connection connection;
public DataProcessor(JdbcConnector connector) {
this.connection = connector.getConnection();
}
public void insert() {
// 실제로는 connection 객체를 이용해서 데이터를 insert 할 수 있다.
System.out.println("inserted data");
}
}
// JdbcConnector.java
public interface JdbcConnector {
Connection getConnection();
}
// MariaDBJdbcConnector.java
public class MariaDBJdbcConnector implements JdbcConnector {
@Override
public Connection getConnection() {
return null;
}
}
// OracleJdbcConnector.java
public class OracleJdbcConnector implements JdbcConnector {
@Override
public Connection getConnection() {
return null;
}
}
// SQLiteJdbcConnector.java
public class SQLiteJdbcConnector implements JdbcConnector {
@Override
public Connection getConnection() {
return null;
}
}위 코드는 위 그림의 클래스 다이어그램을 기반으로 JdbcConnector 서비스를 사용하는 예제코드인데, 편의상 6개의 .java 파일을 하나로 표시함. DbClient 클래스의 (1)에서 SQLiteJdbcConnector 구현체의 객체를 생성해서 JdbcConnector 인터페이스 타입의 변수에 할당(업캐스팅)하고 있는 것을 볼 수 있음. 그리고 (2)에서 실제로 데이터를 데이터베이스에 저장하는 기능을 하는 DataProcessor 클래스의 생성자로 JdbcConnector 객체를 전달하고 있음(의존성 주입). 만약 다른 애플리케이션에서 SQLite 데이터베이스를 사용하는 것이 아니라 Oracle 데이터베이스를 사용해야한다면, JdbcConnector 서비스 모듈을 그대로 가져와서 (1)의 new SQLiteJdbcConnector()를 new OracleJdbcConnector()로 바꿔서 사용하면 됨.
PSA가 필요한 이유
PSA가 필요한 주된 이유는 어떤 서비스를 이용하기 위한 접근 방식을 일관된 방식으로 유지함으로써 애플리케이션에서 사용되는 기술이 변경되더라도 최소한의 변경만으로 변경된 요구 사항을 반영하기 위함. 즉, PSA를 통해서 애플리케이션의 요구 사항 변경에 유연하게 대처할 수 있음. Spring은 상황에 따라 기술이 바뀌더라도 변경된 기술에 일관된 방식으로 접근할 수 있는 PSA를 적극적으로 지원하고 있음. Spring에서 PSA가 적용된 분야로는 트랜잭션 서비스, 메일 서비스, Spring Data 서비스 등이 있음.
