서론 :
많은 정보를 DB에 저장하게 되면 그것을 읽는 작업이 필요하다.
기본적으로 엔티티 기반으로 Getmapping을 통해 해당 값을 읽으면 되는데
방대한 데이터 경우 그냥 데이터를 찾으려면 모든 컬럼을 조회하는 구조상
100만건의 데이터를 한번씩 다 읽어야 하기에 상당히 오래 걸린다.
이러한 시간 리소스를 줄이고자 만들어 진 것이 Index 개념이다.
Index :
하나의 게임을 예시로 들면 좋을 것 같다.
1~100이라는 숫자 중 상대방이 무슨 숫자를 생각했는지 맞추는 게임이다.
정답이 70이라고 가정한다면,
기존 읽기 형식이라면 질문이
정답은 1인가요? 2인가요? 3인가요? 이렇게 순서대로 물어 볼 것이다.
하지만 Index를 적용한 읽기 형식이라면 질문이
50보다 큰가요? 75보다 작은가요? 63보다 큰가요? 이렇게 물어 볼 것인데
이럴 경우 기존 읽기 형식보다 빠르고 대량의 정보도 쉽게 처리가 가능하다
Index 구조 :
Index
 (출처 : '코딩애플' index가 뭔지 설명해보세요 (개발면접시간))
(출처 : '코딩애플' index가 뭔지 설명해보세요 (개발면접시간))
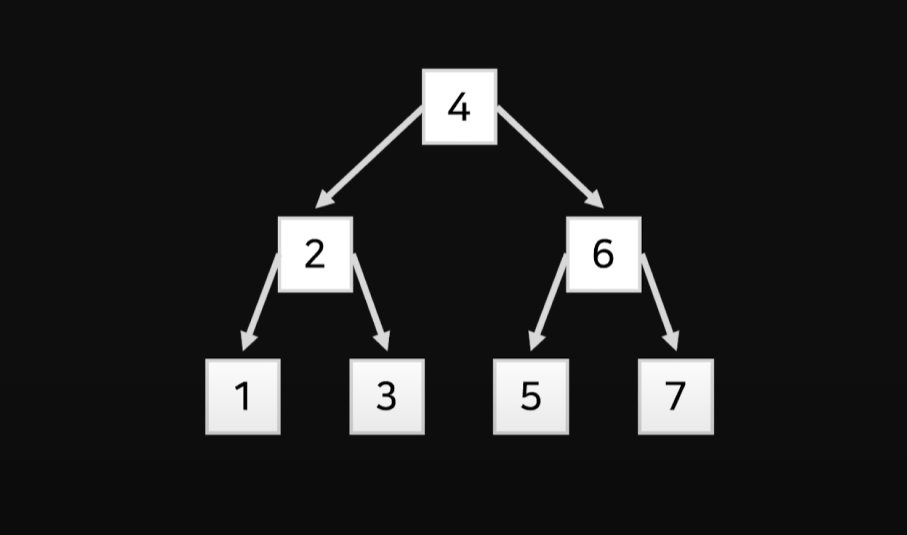
그냥 Index라고 말하면 HashTable 구조를 가진 Index를 말하게 된다.
위 그림은 HashTable 참조하여 읽는 방식을 설명하기 위한 그림이다.
위에 있는 리프노드를 통해 아래에 있는 내부노드를 읽는 방식으로 개념이 구조화 되어있다.
Key-Value 쌍으로 데이터를 저장하는 자료구조로 빠르게 데이터를 찾는게 장점이지만
한 요청에 하나의 응답만 가능하다. 한 요청에 여러 응답을 원한다면 B-tree 구조를 사용한다.
B-tree Index
 (출처 : '코딩애플' index가 뭔지 설명해보세요 (개발면접시간))
(출처 : '코딩애플' index가 뭔지 설명해보세요 (개발면접시간))
언뜻 보면 기존 Index와 비슷한 구조이지만 한 key에 여러 value를 가짐으로써
한 요청에 여러 응답을 하기에 보다 더 적합하고 처리가 빠르지만
리프노드에 여러 데이터가 들어가니 리프노드 데이터 크기가 클 수 밖에 없다.
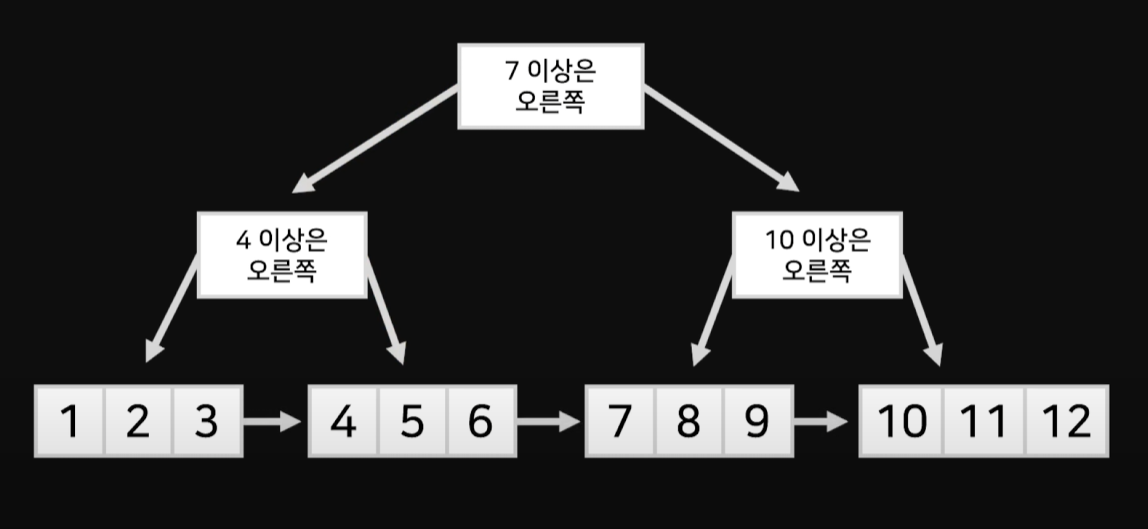
B+tree Index
 (출처 : '코딩애플' index가 뭔지 설명해보세요 (개발면접시간))
(출처 : '코딩애플' index가 뭔지 설명해보세요 (개발면접시간))
B-tree 구조의 개선판으로 내부노드에 데이터를 전부 집어 넣어 두고 리프노드에는 가이드만 넣어서
리프노드의 데이터 크기는 줄었지만, 전체 데이터 크기는 가이드 수 만큼 늘어나게 된다.
하지만 내부노드가 순차 조회가 가능하게되어 한 요청에 범위 응답이 가능해지면서 처리 더욱 빨라졌다.
예시 :
email과 id를 레파지토리에서 조회하여 index의 조회 속도 차이를 비교해 볼 것이다.
@Import(TestSecurityConfig.class)
@ActiveProfiles("test")
@SpringBootTest
public class UserRepositoryIndexTest {
@Autowired
private UserRepository userRepository;
private final String testEmail = "emailnY8HtX"; //9998 번째
private final Long testId = 9998L;
private final int REPEAT_COUNT = 100;
@BeforeEach
void checkDummyData() {
Optional<User> byEmail = userRepository.findByEmail(testEmail);
Optional<User> byId = userRepository.findById(testId);
if (byEmail.isEmpty() || byId.isEmpty()) {
throw new RuntimeException("테스트용 사용자(email100000, id 100000)가 DB에 존재해야 합니다.");
}
}
@Test
@DisplayName("이메일 기반 조회 성능 측정")
void testFindByEmailPerformance() {
long start = System.currentTimeMillis();
for (int i = 0; i < REPEAT_COUNT; i++) {
userRepository.findByEmail(testEmail);
}
long end = System.currentTimeMillis();
System.out.println("이메일 조회 평균 시간: " + (end - start) / (double) REPEAT_COUNT + " ms");
}
@Test
@DisplayName("ID 기반 조회 성능 측정")
void testFindByIdPerformance() {
long start = System.currentTimeMillis();
for (int i = 0; i < REPEAT_COUNT; i++) {
userRepository.findById(testId);
}
long end = System.currentTimeMillis();
System.out.println("ID 조회 평균 시간: " + (end - start) / (double) REPEAT_COUNT + " ms");
}
}위 테스트 코드는 1만건에 더미 데이터가 있다고 가정하고
9998번째 정보의 email과 id를 조회하는 쿼리이다.
REPEAT_COUNT의 역활은 각 메소드가 100번의 조회를 했을때 얻을 수 있는
평균값을 내기위해 만들었다.
이에 대해 다음과 같은 결과를 얻을 수 있었다.
이메일 조회 평균 시간: 4.19 ms,
ID 조회 평균 시간: 1.21 ms
이처럼 email을 직접 찾는것 보다 index인 id로 찾는 것이
유의미 하게 빠르다고 볼 수 있다.
여담 :
-
처음에는 테스트를 컨트롤쪽에서 만들려고 시작했다. 나중에 튜어님에게 물어보니 인덱스 같은 DB 연관된 테스트는 레파지토리에서 테스트 하는거였다.
-
security가 테스트도 필터링 하고 있어서 testsecurity를 만들어 적용하고
기존 security에는 @Profile("!test") 이용해서 테스트에 영향을 주지 않도록 만들었다. -
더미 파일을 10만개 만들었다. 이것만 1시간 이상 걸렸는데. 처음에는 100만개를 만들려고 했는데 하루 사라질뻔 했다. 그런데 그 10만개도 뒤늦게 email에 유니크를 걸어서 자동으로 b+index로 저장되어 있다는 걸 알아서, 결국 1만개로 생성하여 테스트를 진행하게 되엇다.
참조 :
https://dev.mysql.com/doc/refman/8.0/en/mysql-indexes.html (공식 문서)
https://hudi.blog/db-index-and-indexing-algorithms (인덱스 설명 블로그)
https://engineerinsight.tistory.com/336 (B+ tree 인덱스 구조 설명 블로그)
https://www.youtube.com/watch?v=iNvYsGKelYs (인덱싱 개념설명 동영상)
