현재 배달의민족 서버를 클론하는 프로젝트를 하고있습니다.
그 과정에서 ENUM을 통해 카테고리를 관리할지, DB에 저장하여 관리할지 고민한 경험을 정리했습니다.
기존 상황 - enum
기존에 카테고리는 아래와 같이 enum 클래스로 관리하였습니다.
public enum Category {
KOREAN(1L),
CHINESE(2L),
JAPANESE(3L),
CHICKEN(4L),
PIZZA(5L),
FAST_FOOD(6L);
....
}enum을 관리할 경우 장점과 단점을 생각해보면
장점으로는
- 자바 코드만 보고 어떤 카테고리가 있는지와 ID를 파악할 수 있다.
- DB에 접근하기 위한 네트워크를 타지 않으므로 빠르다.
단점으로는
- 카테고리에 변경이 발생하면 재컴파일 및 재배포가 되어야한다.
제가 생각하기에 카테고리의 변경은 그렇게 잦지않고, 현재 로컬에서만 개발중인 상황인데 코드를 수정하고 컴파일 하는일이 어렵지 않으므로 enum으로 관리하는 쪽을 택했었습니다.
그러나 만약 실제 production 상황이었다면 다음과 같은 상황도 생각해봐야 했습니다.
- 만약 PM 또는 누군가 카테고리 수정을 요청했을 때, 개발자가 모두 부재중인 경우
- 이 경우 개발자들이 돌아오기 전까지 서비스가 변경되지를 못합니다.
- 아직 서비스가 자주 변경되는 상황이라 카테고리의 변경 또한 잦을 경우
- 매번 코드를 수정하고 재배포하는 번거로운 상황이 발생합니다.
이러한 문제점은 DB에 카테고리를 저장함으로서 개발자가 코드 수정을 하지않아도 쿼리 한번으로 카테고리 수정이 가능해지는데요,
DB에 저장할 경우 치명적인 단점이 하나 있습니다.
- 배달 앱의 경우, 카테고리를 보여주는게 메인 페이지 격인데, 매번 데이터베이스를 조회한다면?
- 매번 네트워크를 타야하고 동시접속자가 많아졌을 때 엄청난 부하가 될 것입니다.
네트워크를 타서 데이터베이스를 조회한다는 단점만 해결한다면 요구사항을 충족할 수 있었는데,
이를 충족할 방법으로 캐시(Cache) 를 떠올렸습니다.
- 캐시란, 자주 사용되는 데이터 또는 계산결과 등을 저장해놓는 저장소입니다.
- 예를 들어 캐시에 데이터베이스 쿼리 결과를 저장하면, 데이터베이스가 다시 쿼리를 수행하는 과정이 생략되므로 그만큼 처리 속도가 빨라집니다.
과연 카테고리가 캐싱하기 좋은 데이터인지 다음을 고려해봤습니다.
- 자주 사용되는가
- → 메인페이지 격이므로 가장 많이 사용됌.
- 변경이 자주 발생하진 않는가
- 변경이 잦으면 DB와 캐시간의 정합성 문제가 발생할 수 있다.
- → 사용자 요청과 무관하게 서비스 관리자에 의해 변경되므로 컴퓨터의 시간을 봤을 때 잦지 않음.
크게 위의 관점에서 보면 카테고리는 캐싱에 아주 적합한 기술이었습니다.
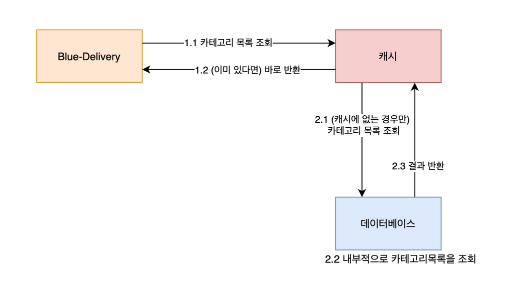
애플리케이션과 데이터베이스 사이에 캐시를 두고, 한번 조회된 내용은 캐시에 저장하여 데이터베이스를 조회하지 않고도 캐시를 통해 데이터를 가져올 수 있습니다.
만약 캐시서버 또한 네트워크를 탄다 하더라도 데이터베이스 내에서 조회하는 과정이 생략되고 가져오기만 하면 되니, 직접 조회보단 효과적이라고 생각할 수 있었습니다.
물론 ConcurrentHashMap 같은 자료구조를 이용해서 직접 캐시를 구현해도 되지만, Cache는 Eviction Strategy를 설정할 수 있고, 직접 구현하는 경우 TTL(Time-To-Live) 같은 설정이나, 각 캐시마다 제공하는 기능들을 누리지 못하거나 직접 구현해야 하므로 이미 존재하는 캐시들을 사용하는 편이 안전합니다.
캐시 종류
캐시는 Local Cache와 Global Cache로 나눠질 수 있습니다.
Local Cache
- 각각의 애플리케이션 서버 자원을 사용하는 캐시입니다.
- 서버의 자원을 바로 사용하니 네트워크 트래픽을 유발하지 않아서 처리속도가 빠릅니다.
- 그러나 scale-out 시 서버간의 정합성 문제가 생길 수 있습니다.
- 대표적으로 Caffeine, EhCache 등이 있습니다. 특히 Caffeine은 캐시 구현체 또한 제공됩니다.
Global Cache
- 별도의 캐시 서버를 운영하는 방식입니다.
- 여러 서버가 같은 서버를 참조할 수 있으므로 정합성 문제는 해결됩니다.
- 그러나 네트워크 트래픽을 발생시키므로 로컬 캐시에 비해 처리 속도가 느립니다.
- Redis와 MemCached 등이 있습니다.
캐시를 검색하면 Redis가 워낙 장점도 많고 유명해서 널리 사용되고 있음을 알 수 있습니다.
그러나 두 종류의 캐시 모두 장단점이 명확하기 때문에 유명하다고 무턱대고 사용할 순 없었고 저의 상황과 비교할 필요가 있었습니다.
카테고리는
- 데이터가 10~20개 사이로 매우 작은 데이터셋입니다.
- JOIN 없이 하나의 테이블만 조회하면 되므로 조회가 복잡하지 않습니다.
- 배달앱을 사용하는 모든 유저가 반드시 거쳐가므로 매우 자주 사용됩니다.
이렇게 단순 데이터를 처리하기 위해 매번 네트워크 트래픽을 발생시키는건 효율이 떨어진다고 판단했습니다.
그래서 저는 로컬캐시 중 카페인을 사용하기로 하였고, 레디스와 속도를 비교해보았습니다.
// 카테고리를 1000번 조회하는 루프를 10번 테스트해본다.
public void applicationRunner() {
for (int i = 0; i < 10; i++) {
long start = System.currentTimeMillis();
for (int j = 0; j < 1000; j++) {
service.getAllCategories(); // cache가 적용된 카테고리 조회 서비스
}
}
}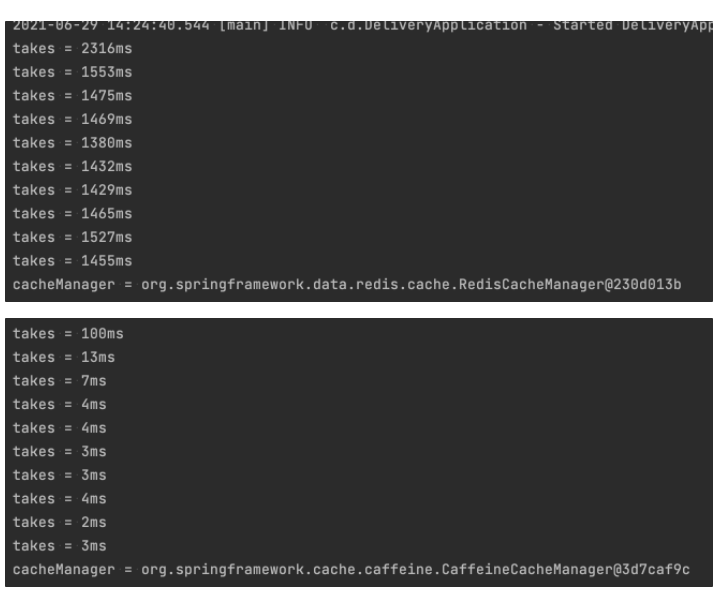
로컬캐시인 카페인이 압도적인 속도를 보여줬습니다. 실제로 제가 실행했을 때도 카페인은 바로 결과가 나온 반면, 레디스는 타임아웃이 걸린것 처럼 한참이 걸렸습니다.
(스프링에서 PSA로서 캐시 추상화 인터페이스를 제공하기 때문에 간단하게 적용할 수 있습니다.)
scale-out시 정합성 문제
Local Cache를 사용할 경우 scale-out시 정합성 문제가 발생할 수 있다고 하였습니다.
정합성 문제는 데이터간의 논리적 모순이 생기는 것입니다. 같은 질문을 했는데 두 서버가 다른 데이터를 가지고 있어서 다른 답을 주는 경우가 생깁니다.
-
A, B 서버가 있고 카테고리 '치킨' 을 '닭고기'로 변경하는 상황이라고 가정하겠습니다.
-
요청을 했을 때, A서버가 이 작업을 처리했습니다.
-
A서버의 Local Cache에는 이 변경사항이 반영되었고, B서버는 아직 이 사실을 모릅니다.
-
사용자들이 접속하였습니다. 카테고리 메뉴를 보여줘야 합니다.
1번 사용자는 A서버를, 2번 사용자는 B서버를 통해 카테고리 메뉴를 요청합니다.
어떤 서버가 처리하는지는 로드밸런서의 영역이므로 다른 글을 참고해주세요.
-
A, B 서버 캐싱된 데이터를 활용하는데
문제는 A서버는 변경된 '닭고기', B서버는 변경전인 '치킨' 을 보여줍니다.
이러한 정합성 문제를 해결하기 위해선 동기화 과정이 필요한데, 저는 Eventual Consistency를 만족하는 동기화를 하였습니다.
Eventual Consistency를 간단하게 설명하자면,
모든 서버가 당장 일관되진 않지만 시간이 지나면 결국 동기화가 된다.는 아이디어로 보시면 되겠습니다.
그 이유는
-
카테고리 자체가 변경이 잦지 않으며, 그 변경이 다른 기능에 영향을 줄 가능성이 적다.
-
카테고리가 변경되더라도 전혀 의미가 다른 카테고리로 변경되는 없을 것이라고 본다.
(예를들어 치킨→ 닭고기 정도가 될것. 치킨→한식 이 된다면 그 파급효과가 클것이기 때문에 이런 변경은 하지 않을것이라 봄)
그렇다면 일시적으로 반영이 늦는 것 정돈 괜찮다고 보았습니다.
로컬 캐시 Caffeine 에서의 Eventual Consistency
expireAfterWrtie 이라는 옵션은 캐싱 이후 일정 시간이 지나면 캐시를 삭제하는 옵션입니다.
1분를 주기로 하면 서버간 데이터가 불일치가 생겨도 60초를 넘어가지 않습니다.
새로 지워지고 최신의 데이터를 데이터베이스에서 가져와 캐싱할 것 이기 때문입니다.
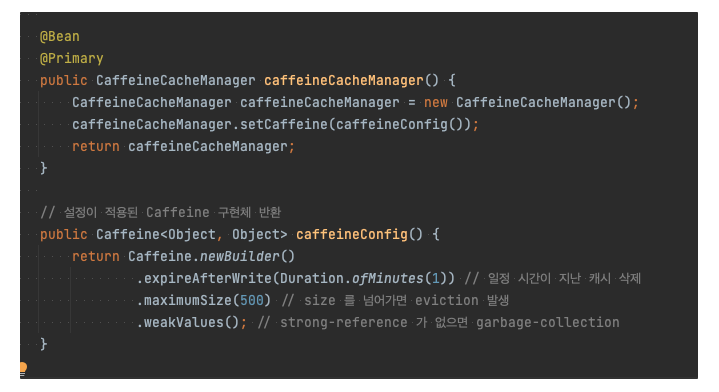
아래는 서비스의 코드입니다. 카테고리에 변화가 생길시 작업을 처리하는 서버의 캐시는 @CacheEvict 를 통해 직접 삭제하고 있습니다. (작업을 처리하지 않은 서버들은 위의 설정에 따라 1분 뒤에 삭제가 되겠죠.)
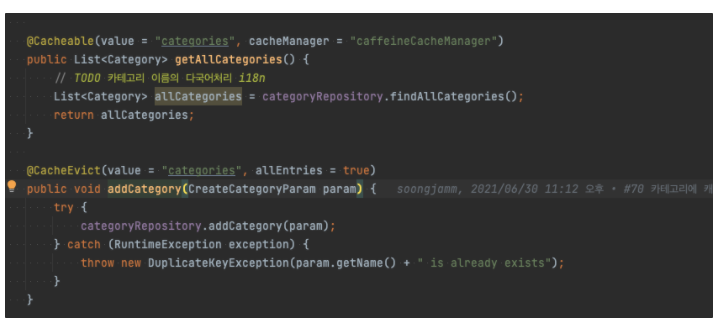
자 이제 확인해보겠습니다.
카테고리를 반복적으로 조회했더니, 이미지에는 다 안나오지만, blue-delivery1~3 모두 데이터베이스에 쿼리를 한번씩 날렸습니다. (이제 캐싱이 된 상태입니다.)
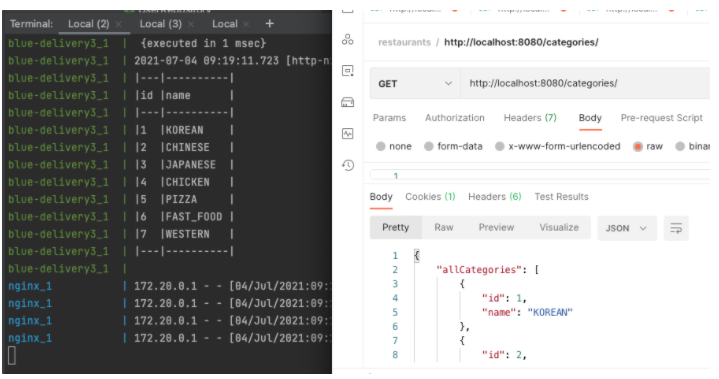
다음과 같이 ID=1에 해당하는 카테고리의 이름을 KOREAN 에서 KOREAN_DELICIOUS 로 변경하겠습니다.
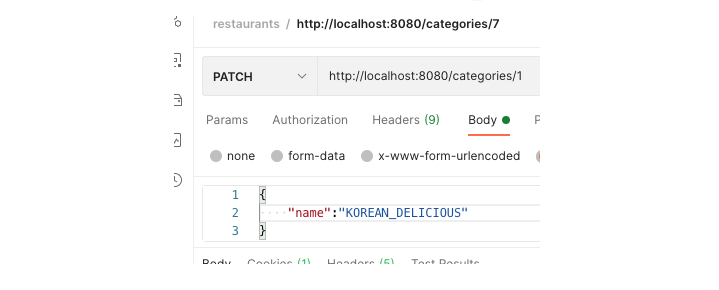
보시다시피 UPDATE 쿼리가 나갔습니다.(blue-delivery1_1이 처리했네요)
그리고 다시 카테고리 목록을 조회했는데, 수정된 데이터 KOREAN_DELICIOUS 가 아닌 KOREAN 이 아직 보입니다.
- 업데이터 되기 전에 캐싱된 데이터를 보내주고 있습니다.
- PATCH 요청은 1번 서버가 처리했으나, GET요청은 2 또는 3에서 받았을겁니다.
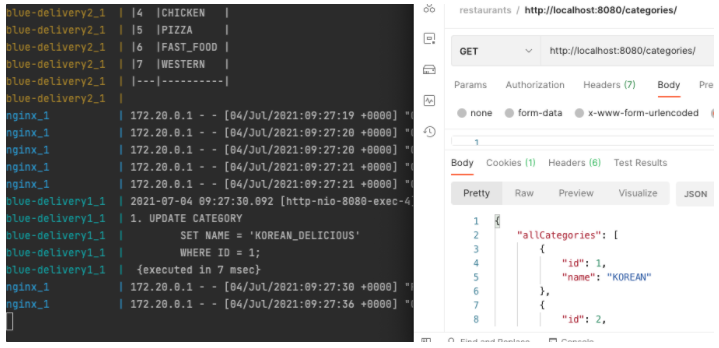
60초가 지났으니 다시 요청을 보내보겠습니다.
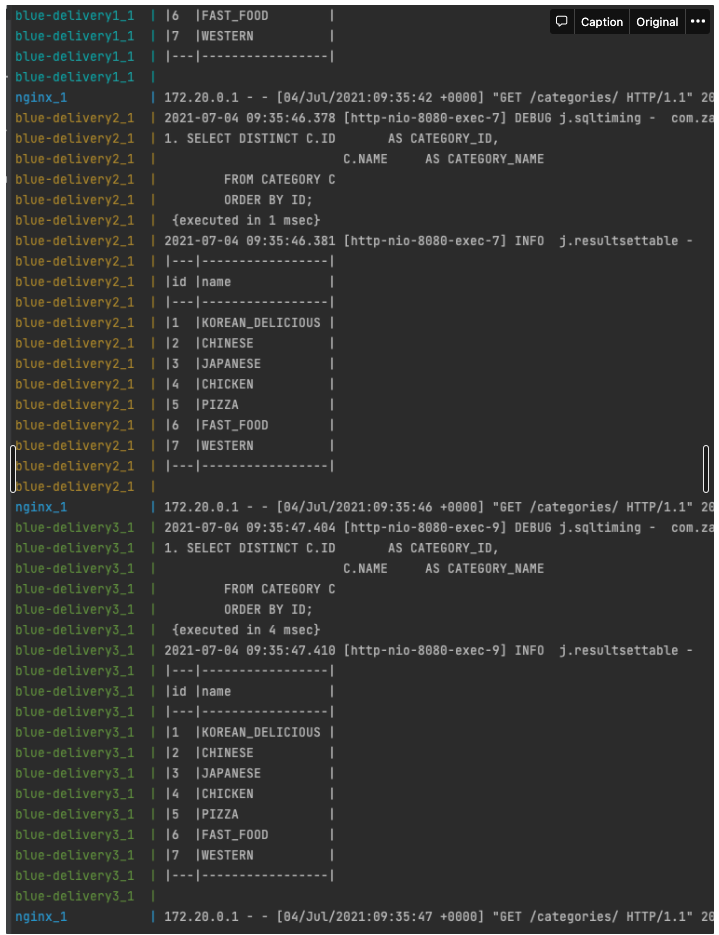
사진이 조금 짤렸지만 모든 서버에서 캐시 재사용이 아닌, 데이터베이스에 쿼리를 보내는 것을 확인할 수 있습니다.
이로써 로컬 캐시의 동기화과 완료되었습니다.
