[Paper Review] Fast and Accurate Network Embeddings via Very Sparse Random Projection(FastRP)
Graph
FastRP 란 무엇인가?
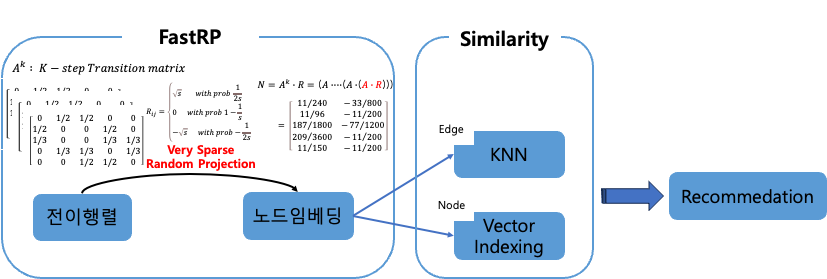
한줄 요약 : FastRP는 그래프의 노드 임베딩 벡터를 빠르고 확장성있게 생성하는 방법이다.
이 알고리즘은 다른 그래프 노드 임베딩 기법(Deepwalk, node2vec)과 달리 very sparse random projection 기법을 활용하여 노드의 벡터 표현 방식을 간소화하고 전이행렬을 활용하여 이웃 노드의 정보를 집계하여 노드 간의 관계와 그래프의 구조적 특성을 반영하는 임베딩을 생성한다.
- 노드 임베딩이란? 그래프 상에서 노드 간의 복잡한 관계를 컴퓨터가 이해할 수 있는 형태로 변환하여 벡터(숫자의 배열)로 표현하는 방법.
FastRP
여기서 전이행렬(Transition matrix)이란 노드 간의 인접행렬(Adjacency matrix)과 차수행렬(Degree matrix) 의 역행렬을 곱한 행렬로 이 전이행렬을 여러 번 반복하여 곱해줌으로써() 이웃 노드의 정보를 반영할 수 있다.
전이행렬
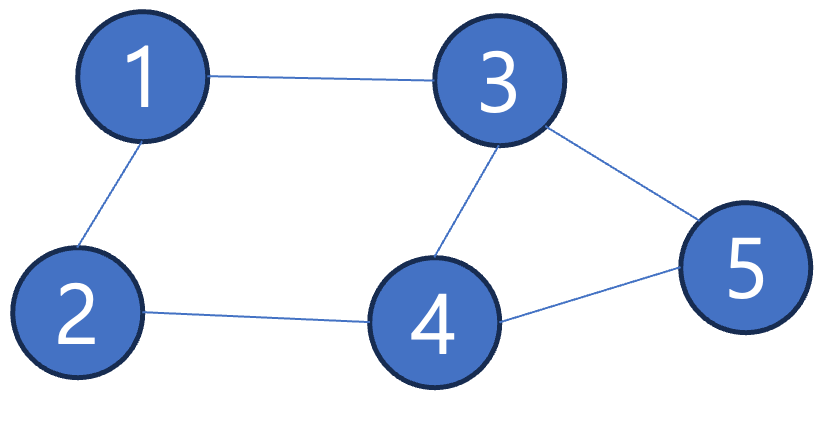
| 1 | 2 | 3 | 4 | 5 | |
|---|---|---|---|---|---|
| 1 | 2 | 0 | 0 | 0 | 0 |
| 2 | 0 | 2 | 0 | 0 | 0 |
| 3 | 0 | 0 | 3 | 0 | 0 |
| 4 | 0 | 0 | 0 | 3 | 0 |
| 5 | 0 | 0 | 0 | 0 | 2 |
Transition matrix() = Inv. Degree matrix() × Adjacency matrix()

Degree matrix의 역행렬()과 Adjacency matrix()을 곱한 것이 Transition matrix().

노드 임베딩
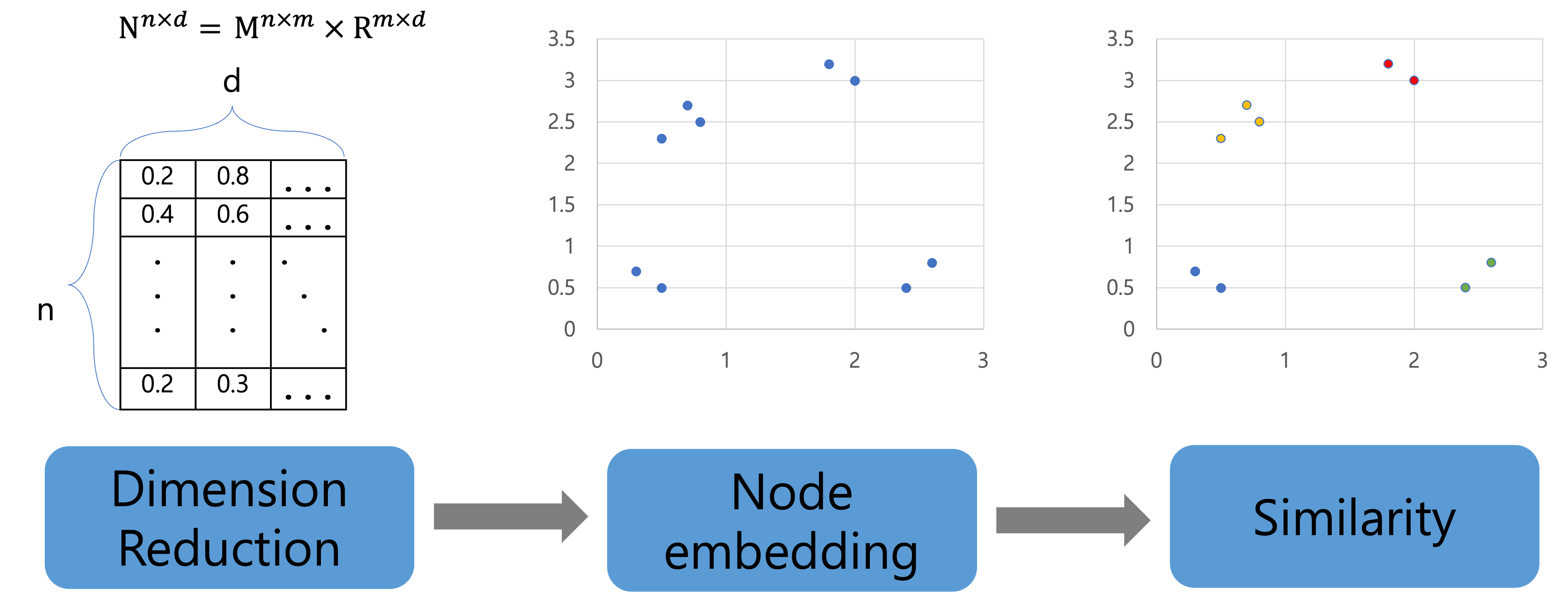
이러한 전이행렬을 랜덤한 분포에 투영하여 차원 축소를 시켜 노드의 임베딩 벡터를 빠르게 생성한다.
( 은 , 은 Random Projection matrix)
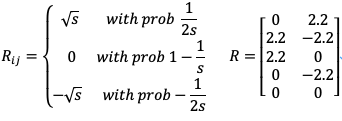
여러 번 반복하여 곱한 전이행렬()을 Random Projection 행렬과 곱해주어 차원 축소를 시켜줌.
Similarity
생성된 노드 임베딩 벡터를 기반으로 노드 간의 유사도를 계산하는데 유사도(similarity)의 최종 결과물에 따라 두 가지 방식으로 나뉜다.
1) KNN
최종 결과물 : 유사도의 최종 결과물이 유사한 노드 간의 연결(edge)로 나옴.
작동 방식 : KNN을 사용하여 노드 임베딩 벡터 간의 유사도를 측정할 때, 특정 노드의 벡터가 주어지면 다른 모든 노드의 벡터와의 거리(유사도)를 계산하여 가장 가까운 k개의 이웃을 찾음.
장점 : edge가 있기 때문에 시각화 측면에서 강점
단점 : 대규모 데이터셋에서는 모든 노드 간의 거리를 계산하는 것이 비효율적.
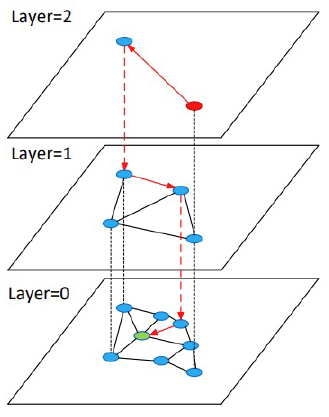
2) Vector Indexing(HNSW)
최종 결과물 : 유사도의 최종 결과물이 유사한 노드의 프로퍼티로 나옴
작동 방식 : 여러 계층의 그래프를 구성하여 최상위 계층에서부터 임의의 노드로 시작하여 소스 노드에 도달할 때까지 각 계층에서 방문했던 노드를 유사한 노드로 탐색함. 즉, 소스 노드 검색 시 상위 계층에서 시작하여 점차 하위 계층으로 내려가면서 유사한 노드를 찾아감.
장점 : 대규모 데이터셋에서 유사한 벡터를 효율적으로 인덱싱하고 검색할 수 있음. edge가 없기 때문에 저장 용량 측면에서 강점
단점 : KNN과 달리 노드 별로 유사한 노드에 대해 연결관계(edge)를 부여해줘야 함.
Recommendation
앞서 전이행렬을 랜덤한 분포에 투영하여 차원 축소를 시켜 생성된 노드 임베딩 벡터를 특정 유사도 함수를 통해 벡터 간의 유사도를 파악하여 가장 유사한 노드 k개(Top-k)를 추천할 수 있다.
ex) 카드 상품 추천 task에서 카드 상품 안의 혜택들을 기반으로 카드 상품 간의 유사도를 측정하여 혜택이 유사한 카드 추천 가능.
Advantages of FastRP
FastRP와 그 외 그래프 노드 임베딩 방법의 node representation)
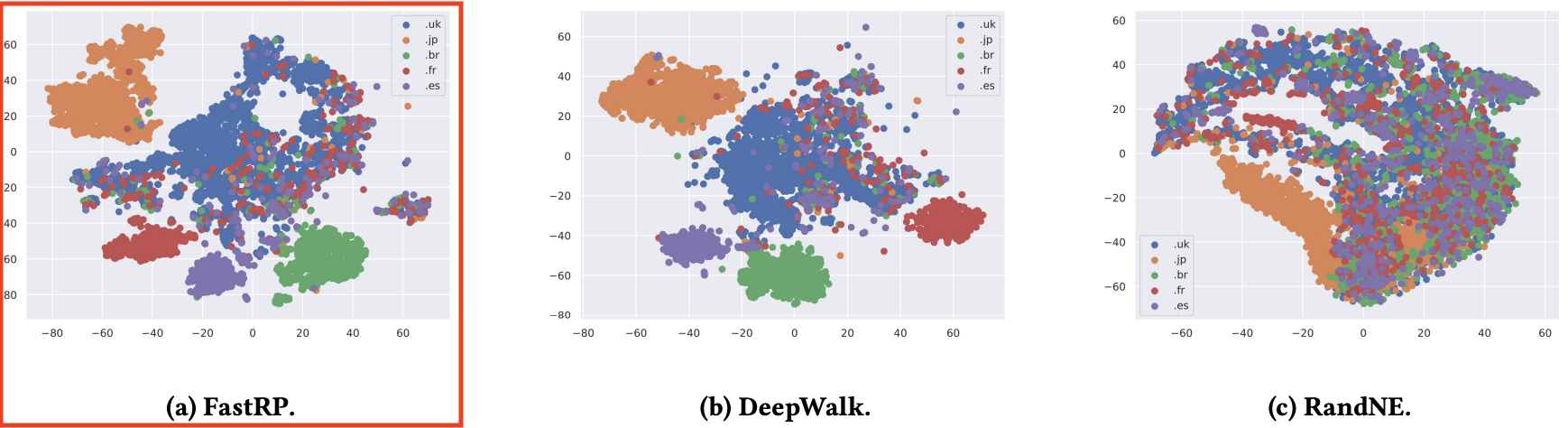
각 노드 임베딩 방법 별 노드 임베딩 벡터를 2차원으로 시각화하여 표현한 그림이다.
각 노드의 실제 레이블 별(uk, jp, br, fr, es)로 데이터 포인트의 색이 다르게 표현되어있는데 그림에서 볼 수 있듯이 FastRP와 DeepWalk 방법론이 레이블 별로 꽤 잘 분리된 클러스터를 형성하는 것을 확인할 수 있다.
노드 임베딩 속도 비교)
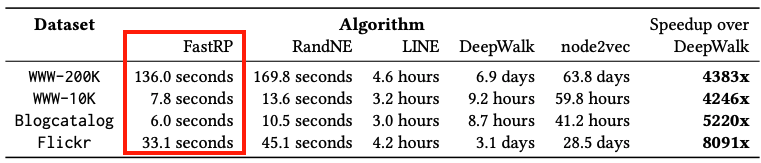
FastRP는 가장 최신의 좋은 성능을 보이는 방법론인 DeepWalk 보다도 모든 데이터셋에서 4,000 배 이상 속도가 빠르다.(맥북 m1, 16g 기준 엣지 2800만개, 15분 걸렸고 더 감속될 가능성이 있음)
Node-classification F1 score)
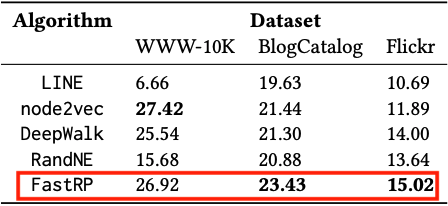
Node classification 은 그래프 주요 Task 중 하나로 여러 종류의 노드 레이블이 존재할 때 노드가 어떠한 종류에 속하는 레이블인지를 분류한다.
-
F1-score 설명
'정밀도(Precision)'와 '재현율(Recall)'을 조화 평균한 값으로 분류 모델에서 사용되는 평가지표이다.
class imbalance 문제를 방지하기 위해 사용한다.
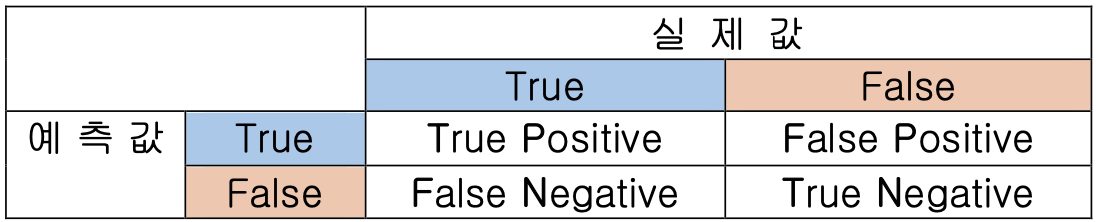
Precision = (예측값이 True인 것 중에서 실제값이 True인 비율)
Recall = (실제값이 True인 것 중에서 예측값이 True인 비율)
결론적으로, F1 score는 precision과 Recall이 모두 높으면 F1 score도 높다.
분류모델의 측정지표로 사용되는 F1 score는 값이 높을수록 좋은 성능을 나타낸다. FastRP는 BlogCatalog와 Flickr 데이터셋에서 가장 좋은 성능을 나타내고 있다. WWW-10K 데이터셋에서 2번째로 좋은 성능을 나타내고 있지만 가장 좋은 성능을 나타내는 node2vec과 성능 차이가 거의 없다.
위의 결과를 통해 확인할 수 있듯이, Speed와 F1-score 측면에서 기존 노드 임베딩 방법론들에 비해 빠르고 정확하다는 것을 확인할 수 있다.
기존 그래프 노드 임베딩 기법과 비교했을 때 2가지 장점.
- 속도
very sparse random projection 방식과 행렬곱 형태를 통해 DeepWalk에 비해 4,000배 이상의 속도 향상
- 확장성
구현, 하이퍼파라미터 튜닝이 용이하여 커스터마이징이 쉽고 행렬 계산이라 병렬화가 가능하다.
구현이 용이하다는 뜻은 optimization free method 라서 가중치 없데이트 과정이 없음.
