
백준 2179번 : 비슷한 단어(골드 4)
문자열 문제이다. N개의 영단어들이 주어지고 문자열들을 서로 비교하며 A 문자열과 B 문자열의 접두사의 길이가 가장 길다면 A 문자열과 B 문자열을 출력하는 문제이다. 여기서 접두사는 공통 접두사로 정의하겠다
문제의 예제 입력 1에서 "noon"과 "noone"의 공통 접두사는 "noon"이므로 "noon"과 "noone"를 차례로 출력하면 된다. 예제 입력 2에서는 "abcd"와 "abc"의 접두사인 "abc"가 가장 기므로 두 문자열을 출력한다
정답이 여러개일 수 있는데 예제 입력 2에서 "abcd"와 "abchldp"도 접두사가 "abc"이므로 이것도 정답이 될 수 있다. 그런데 문제에서 우선 S가 입력되는 순서대로 제일 앞쪽에 있는 단어인 경우를 출력하고, 그런 경우도 여러 개 있을 때에는 그 중에서 T가 입력되는 순서대로 제일 앞쪽에 있는 단어인 경우를 출력한다.라고 단호하게 조건을 걸어두었다
이런 조건을 생각해보면 (i1, i2), (j1, j2)가 정답일 때 i1과 j1으로 먼저 오름차순하고 i2랑 j2로 오름차순하는 순서로 생각하면 됨
그리고 공통 접두사가 아예 없는 경우 ""로 두는데 이 경우에는 모든 단어의 공통 접두사의 길이가 0이라는 것이므로 처음부터 정답을 0번째 문자열과 1번째 문자열으로 초기화한다
풀이
위 문제를 어떻게 풀어야 할 지 고민했는데 문자열 하나와 다른 문자열 하나를 서로 비교해가면서 접두사를 구하는 건 시간 복잡도면에서 틀릴 것 같아 배제했다. 문자열의 길이가 최대 2만이므로 O(N^2)이면 위험함
그래서 저번에 공부한 트라이 자료구조를 여기서 써보기로 했다(지난 포스트)
먼저 트라이 자료구조를 구현해야한다. TrieNode라는 노드를 구현한다
class TrieNode
{
public:
unordered_map<char, TrieNode*> children;
int firstIndex = -1; // 이 노드를 방문하는 첫 번째 단어의 인덱스
};이 노드의 자식 노드들을 저장할 unordered_map과 이 노드를 처음 방문한 인덱스를 기록해둔다. 이 인덱스는 이 문제의 제일 앞쪽에 있는 단어를 출력하기 위함임
그리고 트라이를 나타내는 Trie를 구현하자
class Trie
{
private:
TrieNode* root;
public:
Trie()
{
root = new TrieNode();
}
void Insert(string& word, int index)
{
TrieNode* curNode = root;
for (char ch : word)
{
if (curNode->children.find(ch) == curNode->children.end())
{
curNode->children[ch] = new TrieNode();
}
curNode = curNode->children[ch];
// 현재 노드를 처음 방문하면 인덱스를 갱신
if (curNode->firstIndex == -1)
{
curNode->firstIndex = index;
}
}
}
/// <summary>
/// 어떤 단어의 접두사를 확인하는 함수
/// 접두사의 길이와 어떤 단어와의 접두사인지를 리턴함
/// </summary>
pair<int, int> GetPrefixLength(string& word, int index)
{
TrieNode* curNode = root;
int length = 0; // 접두사의 길이
int ret_index = -1; // 어떤 단어 인덱스와의 접두사인지
for (char ch : word)
{
curNode = curNode->children[ch];
if (curNode->firstIndex != index)
{
length++;
ret_index = curNode->firstIndex;
}
}
return { length, ret_index };
}
};트라이를 생성할 때 root 노드를 초기화하고 이제 단어들을 입력받으면서 이 노드를 가장 처음 만든 단어의 인덱스들을 저장한다
GetPrefixLength 멤버 함수는 어떤 영단어와 그 영단어의 인덱스를 매개변수로 받는다. 이 함수는 매개변수로 주어진 영단어와 같지 않은 영단어의 공통 접두사의 길이와 같지 않은 영단어가 어떤 인덱스임을 리턴하는 함수이다
설명보다는 예시를 설명하는게 좋은데 먼저 문제의 예제 입력 2를 가지고 트라이를 그려보았다
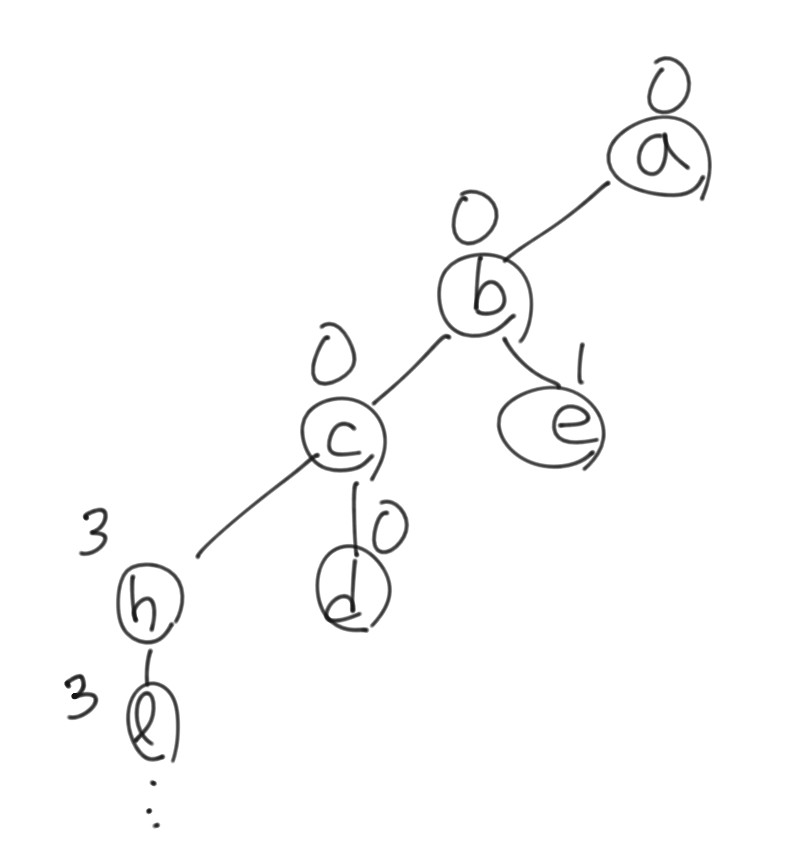
노드에 적혀진 숫자는 그 노드를 가장 먼저 만든 영단어의 인덱스임을 기억하자
트라이를 만든 뒤 영단어들을 차례대로 순회해보자
0번째 인덱스인 "abcd"로 함수를 호출하면 처음부터 끝까지 자기 자신의 인덱스라 공통 접두사가 길이가 0이고 ""이다. -1을 리턴해 정답에는 포함되지 않는다
1번째 인덱스는 "abe"인데 가장 처음 방문하는 'a' 노드는 처음 0번째 인덱스가 방문했으며 자기 자신이 아닌 단어와 공통 접두사가 있다는 말이다. "ab"까지 인덱스가 다르고 'e'는 자기 자신이 방문했으니 길이 2를 리턴하고 0번째 인덱스와 공통 접두사를 이룬다. answer 벡터에 {다른 단어의 인덱스, 자기 자신 인덱스}를 추가한다
2번째 인덱스는 "abc"이고 "abc"까지 이미 0번째 인덱스가 기록되어 있다. 그래서 길이가 3이고 0번째 인덱스를 리턴한다. 현재까지 최대 접두사 길이가 3이므로 정답 벡터를 초기화하고 현재 데이터를 벡터에 추가한다
3번째 인덱스도 "abc"까지 0번째 인덱스와 공통 접두사이므로 길이가 3이고 0번째 인덱스를 리턴한다. 최대 길이와 동일하므로 정답 벡터에 그대로 추가만 한다
그렇게 모든 영단어를 방문했다면 정답 벡터에 여러 데이터가 있을텐데 여기서 중요한 건 pair<int, int>의 first를 기준으로 오름차순 해줘야 한다. 그래서 데이터를 추가할 때도 반대로 추가함. 그래서 정렬을 해주고 정답 벡터의 첫 번째를 출력해주면 끝
전체 코드
#include <bits/stdc++.h>
#include <unordered_map>
using namespace std;
int N;
vector<string> words;
class TrieNode
{
public:
unordered_map<char, TrieNode*> children;
int firstIndex = -1; // 이 노드를 방문하는 첫 번째 단어의 인덱스
};
class Trie
{
private:
TrieNode* root;
public:
Trie()
{
root = new TrieNode();
}
void Insert(string& word, int index)
{
TrieNode* curNode = root;
for (char ch : word)
{
if (curNode->children.find(ch) == curNode->children.end())
{
curNode->children[ch] = new TrieNode();
}
curNode = curNode->children[ch];
// 현재 노드를 처음 방문하면 인덱스를 갱신
if (curNode->firstIndex == -1)
{
curNode->firstIndex = index;
}
}
}
/// <summary>
/// 어떤 단어의 접두사를 확인하는 함수
/// 접두사의 길이와 어떤 단어와의 접두사인지를 리턴함
/// </summary>
pair<int, int> GetPrefixLength(string& word, int index)
{
TrieNode* curNode = root;
int length = 0; // 접두사의 길이
int ret_index = -1; // 어떤 단어 인덱스와의 접두사인지
for (char ch : word)
{
curNode = curNode->children[ch];
if (curNode->firstIndex != index)
{
length++;
ret_index = curNode->firstIndex;
}
}
return { length, ret_index };
}
};
void Input()
{
cin >> N;
for (int i = 0; i < N; i++)
{
string s;
cin >> s;
words.push_back(s);
}
}
void Solve()
{
Trie trie;
int max_len = 0;
vector<pair<int, int>> answer;
// 모든 단어가 겹치지 않는다면 0번째, 1번째 단어를 출력한다
answer.push_back({ 0, 1 });
for (int i = 0; i < N; i++)
{
trie.Insert(words[i], i);
}
for (int i = 0; i < N; i++)
{
int length, index;
tie(length, index) = trie.GetPrefixLength(words[i], i);
if (index != -1)
{
// 접두사 길이가 지금까지 구한 것보다 길다면
// 새로 갱신
if (length > max_len)
{
max_len = length;
answer.clear();
answer.push_back({ index, i });
}
// 같다면 정답에 추가
else if (length == max_len)
{
answer.push_back({ index, i });
}
}
}
// 인덱스가 빠른 것부터 출력해야 함
sort(answer.begin(), answer.end());
cout << words[answer[0].first] << '\n' << words[answer[0].second];
}
int main()
{
Input();
Solve();
}
회고
사실 트라이로 풀면 쉬울 줄 알았는데 괜히 더 이상해진 것 같다. 설명도 어렵고 ㅠㅠ
다른 영단어와의 접두사를 구하기가 좀 어려웠다. 문제의 태그도 트라이가 없어 다른 사람들은 어떻게 풀었나 찾아봤는데 그냥 이중 반복문으로 푼 것 같다. 아마 백트래킹을 잘해서 그런 걸지도
트라이가 단순히 검색, 삽입은 쉬운데 접두사나 삭제 이런건 구현이 좀 어려운 것 같다 ㅎ;; 일단 완탐을 해보는 것도 좋은 방법일지도,,,
