.jpg)
Advanced Join > Interviews [Hard]
현재 작성중...
내 답안
문제를 보아하니,
목적은 결국 sum 값을 구하는 것인데
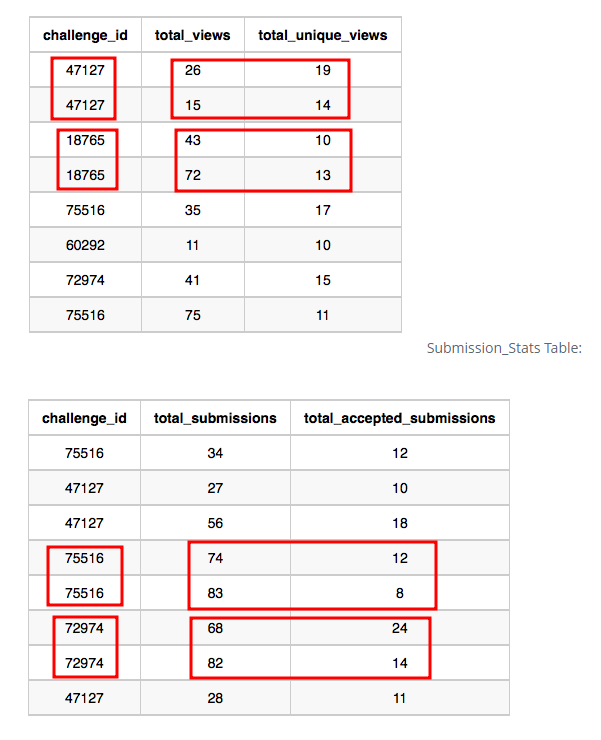
조인할 대상의 테이블에서 challenge_id 가 유니크 하지 않는다는 것을 발견했다.
조인할 대상의 테이블에서 먼저 group by & sum 계산은 안해주면 left join시
null 값이 생기는 문제가 발생해서
먼저 group by & sum 해주었다.
그런데 쿼리 시간이 너무 오래 걸리는 것 같아서 문제인 것 같다.
select A.contest_id, A.hacker_id, A.name
, sum(E.total_submissions), sum(E.total_accepted_submissions)
, sum(D.total_views), sum(D.total_unique_views )
from Contests A
left join Colleges B
on A.contest_id = B.contest_id
left join Challenges C
on B.college_id = C.college_id
left join (
select challenge_id, sum(total_views) as total_views, sum(total_unique_views) as total_unique_views
from View_Stats
group by challenge_id
) D
on C.challenge_id = D.challenge_id
left join (
select challenge_id, sum(total_submissions) as total_submissions, sum(total_accepted_submissions) as total_accepted_submissions
from Submission_Stats
group by challenge_id
) E
on C.challenge_id = E.challenge_id
group by A.contest_id, A.hacker_id, A.name
having 1=1
and sum(E.total_submissions)+sum(E.total_accepted_submissions)+sum(D.total_views)+sum(D.total_unique_views) != 0
and sum(E.total_submissions) is not null
and sum(E.total_accepted_submissions) is not null
and sum(D.total_views) is not null
and sum(D.total_unique_views) is not null
order by 1;다른 사람의 답
쿼리중에 서브쿼리가 있으면 가독성이 떨어지므로
with 문을 이용해서 서브쿼리 부분을 밖으로 빼주는게 좋다는 글을 본 적 있다.
무지성으로 서브쿼리를 쓰는 것보다 서브쿼리를 쓸 일이 있으면
with로 빼놓는 습관을 들여야 할 것 같다.
WITH SUM_View_Stats AS (
SELECT challenge_id
, total_views = sum(total_views)
, total_unique_views = sum(total_unique_views)
FROM View_Stats
GROUP BY challenge_id
)
,SUM_Submission_Stats AS (
SELECT challenge_id
, total_submissions = sum(total_submissions)
, total_accepted_submissions = sum(total_accepted_submissions)
FROM Submission_Stats
GROUP BY challenge_id
)
SELECT con.contest_id
, con.hacker_id
, con.name
, SUM(total_submissions)
, sum(total_accepted_submissions)
, sum(total_views)
, sum(total_unique_views)
FROM Contests con
INNER JOIN Colleges col
ON con.contest_id = col.contest_id
INNER JOIN Challenges cha
ON cha.college_id = col.college_id
LEFT JOIN SUM_View_Stats vs
ON vs.challenge_id = cha.challenge_id
LEFT JOIN SUM_Submission_Stats ss
ON ss.challenge_id = cha.challenge_id
GROUP BY con.contest_id,con.hacker_id,con.name
HAVING (SUM(total_submissions)
+sum(total_accepted_submissions)
+sum(total_views)
+sum(total_unique_views)) <> 0
ORDER BY con.contest_IDAdvanced Join > 15 Days of Learning SQL [Very Hard]
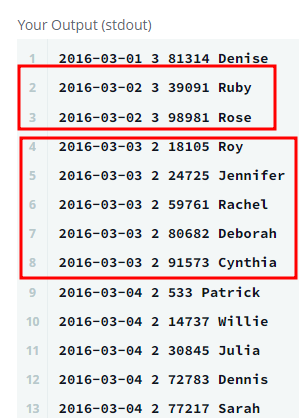
Write a query to print total number of unique hackers
who made at least submission each day (starting on the first day of the contest)
, and find the hacker_id and name of the hacker
who made maximum number of submissions each day.
If more than one such hacker has a maximum number of submissions,
print the lowest hacker_id.
내 답안
우선 group by 된 테이블에 대해서 id 기준으로 sort 하고
distinct 한 날짜 기준으로 뽑아보려 했는데 안된다.
( 서브쿼리로 따로 테이블을 구성했는데도 안되는거 보면, 여러 기준으로 group by 한 뒤, distinct를 적용하는게 안되는건가 싶다. )
계속 짱구를 굴려봤지만 row_numbers를 쓰는 것 말곤 답이 안떠오른다.
( 하루에 max 제출횟수가 같은 사람이 여러명인 경우 낮은 id 순으로 필터링하는 것에서 막힘 )
그렇다면 mysql 내에서 row_numbers를 자체 구현해야하는데
이 방법보다는 다른 사람의 답을 확인해보기로 했다.
/*
WITH aaa AS (
select submission_date, count(*) submit_num, A.hacker_id, name
from submissions A
left join hackers B
on A.hacker_id = B.hacker_id
group by submission_date, A.hacker_id, name
order by 1,2,3
)
*/ -- hacker rank 에선 with 구문이 mysql version 이슈로 되지 않는다.
select AA.submission_date, AA.submit_num, AA.hacker_id, AA.name--, row_number() over(partition by AA.submission_date order by AA.hacker_id asc) as rank
from (
select submission_date, count(*) submit_num, A.hacker_id, name
from submissions A
left join hackers B
on A.hacker_id = B.hacker_id
group by submission_date, A.hacker_id, name
order by 1,3
) as AA
left join (
select BB.submission_date, max(submit_num) as max_submit
from (
select submission_date, count(*) submit_num, A.hacker_id, name
from submissions A
left join hackers B
on A.hacker_id = B.hacker_id
group by submission_date, A.hacker_id, name
order by 1,2,3
) BB
group by BB.submission_date
) as max_submit_per_day
on AA.submission_date = max_submit_per_day.submission_date
where 1=1
and AA.submit_num = max_submit_per_day.max_submit
-- and row_number() over(partition by AA.submission_date order by AA.hacker_id asc) = 1
order by 1, 3다른 사람의 답안
이 사람은 어떻게 풀었을까...

SELECT s.submission_date, n.Num_Everyday_hacker, s.hacker_id, h.name
FROM Submissions s
JOIN Hackers h ON s.hacker_id = h.hacker_id
-- submission 에 해커 네임을 붙여준다.
JOIN (
SELECT submission_date, COUNT(DISTINCT a.hacker_id) AS Num_Everyday_hacker
-- submission 에 일별 해커 제출수를 붙여준다.
FROM Submissions a
WHERE a.hacker_id IN (
SELECT c.hacker_id
FROM Submissions c
WHERE c.submission_date < a.submission_date
GROUP BY c.hacker_id
-- 서브미션 테이블에서 해커 아이디로 group by 해준 뒤
HAVING 1=1
OR COUNT(DISTINCT c.submission_date) = DATEDIFF(a.submission_date,'2016-03-01'))
OR a.submission_date = '2016-03-01'
-- 문제 조건인 15일 기준 필터링 해주고
GROUP BY a.submission_date
-- 2중 group by는 처음 본다. 이게 뭐지 ???
) n
ON s.submission_date = n.submission_date
WHERE s.hacker_id = (
SELECT b.hacker_id
FROM Submissions b
WHERE b.submission_date = s.submission_date
GROUP BY b.submission_date, b.hacker_id
ORDER BY COUNT(*) DESC, b.hacker_id ASC
LIMIT 1
)
GROUP BY s.submission_date, n.Num_Everyday_hacker, s.hacker_id,h.name
ORDER BY s.submission_date;