Uplift Modeling: A Quick Introduction
출처 : https://towardsdatascience.com/a-quick-uplift-modeling-introduction-6e14de32bfe0
An insurance company is allocating new leads to insurance agents from the prior day based on the order they were gathered. Via outbound phone call campaigns agents can convert 5% of worked leads to sales.
The company has realized they now generate more leads in a day than agents are able to work. There is also a sense that a lot of the leads are a waste of time.
With a desire to be more data-driven, the company’s data science team wants to optimize the order in which leads are worked. Using the lead data collected from the website, they built a model scoring the probability each lead was likely to convert to a sale.
This way an agent can start each day paying close attention to leads that have the best chance to convert to a sale in the future. They can also avoid wasting time on leads that will most likely never result in a sale.
Once the model was put into production the company observed that agents were now converting 10% of worked leads into sales. That is 100% improvement over the old operation!
미래에 전환율이 높을 것으로 기대되는 고객들을 상대로만 영업을 하고자,
전환율 예측을 통해 스코어링을 했고, 높은 스코어의 고객들을 대상으로 영업을 해서
성과가 좋았다!
하지만 여기엔 결점이 존재한다.
We need to hit the breaks! No high-fives just yet…
There is a major flaw with this data science project.
It may seem like the project was a success but how do you know if the outbound call campaign caused the customer to convert? It could just be cherry picking easy wins.
In other words, all the propensity model did was gather the leads that were most likely going to convert to sales. It did not separate the customers who were already going to purchase from the customers that needed the outbound call to be persuaded.
전환된 고객들에는 2가지 종류가 있다.
영업을 하지 않아도 적극적으로 전환하려는 고객과
영업을 해야만 전환하는 수동적인 고객.
경향(확률) 예측 모델은 이러한 고객 분류를 하지 않는다.
Welcome to the world of uplift modeling — a bridge between causal inference and machine learning.
What the case study above forgot to consider is persuasion, incrementality, or the true effect of the outbound lead campaign.
이전의 나쁜 사례에선 증분/캠페인 효과를 고려하지 않았다.
The propensity to purchase model, highlighted in the last section, uses machine learning to answer the question:
“How likely is the customer going to purchase in the future?”
Uplift modeling improves on that by answering more important questions:
업리프트 모델링은 구매 확률보다 더 중요한
- 광고가 구매에 효과가 있었나?
- 원래 구매하려던 고객에게 광고하는건 가성비가 구린가?
- 광고가 어떤 사람에겐 악효과가 있었나?
와 같은 질문에 답을 내리려 노력한다.
“Did my advertising cause the customer to purchase from me?”
“Did I waste money advertising to customers who were already going to purchase from me?”
Did my advertising make the probability of someone purchasing worse (negative impact)?
In other words, the classic propensity model (and most machine learning algorithms) predict target (y) given features (x).
전통적인 확률 모델은 입력데이터 x에 대해서 확률 값인 y를 내뱉는다.
Uplift looks to solve for the impact of treatment (t) on target (y) given features (x).
업리프트는 x 라는 입력데이터에 y 결과에 대한 treatment의 효과를 찾는다.
Uplift modeling is often explained by using four customer segments (Siegel 2011):
업리프트 모델링은 자주 시겔의 2011의 고객 세그먼트로 설명된다.

- People who will purchase no matter what (sure things)
뭘 하든 안하든 구매할 사람 - People who will purchase only if they are exposed to an advertisement (persuadables)
광고를 해야만 구매를 하는 사람 - People who will not purchase no matter what (lost causes)
광고를 하든 안하든 구매를 안할 사람 - People who will not purchase if they are exposed to an advertisement (sleeping dogs)
광고를 하면 구매를 안할 사람
A propensity model adds value by helping you avoid lost causes. Uplift modeling improves the targeting even further by focusing on only the customers who are in the persuadables segment.
확률 모델은 3번 케이스를 회피함으로써 가치를 추가한다.
업리프트 모델은 2번 케이스에 집중함으로써 타겟을 향상(?) 시킨다.
Common Applications
일반적인 활용법
How can this be applied to any business unit or industry?
Political Campaigns:
Uplift modeling has been used to identify and target voters who are on the fence (Stedman 2013). By leveraging uplift models, a political marketing campaign can avoid people who are dead set on their party and instead only focus on persuadables.
A New Health Treatment:
Rather than just evaluating the results to the whole treatment group vs control group uplift modeling can help understand how treatments might impact certain groups differently. Also, by how much those impacts differ.
Perhaps the treatment has a large positive impact to people who are age 50+ and have underlying health conditions, but has a small impact to people who are under 50 and healthy.
Lead Optimization: (this should sound familiar)
A company has a lead database but they generate more leads than can be worked and a lot of the leads are a waste of time — currently agents can work the leads in any order they choose.
Cross-Sell:
A company wants to run a cross-sell campaign and the assumption is they don’t want to cross-sell to their entire customer base because budget is limited and some people may not need or want the other products.
Retention:
A company wants to reach out to customers who are about to churn and save them. The company wants to prevent further upsetting customers when reaching out and to only focus on high risk savable customers.
User Experience Testing:
A company wants to understand if a change to their website or app caused the intended result.
일반적인 기술적인 접근들
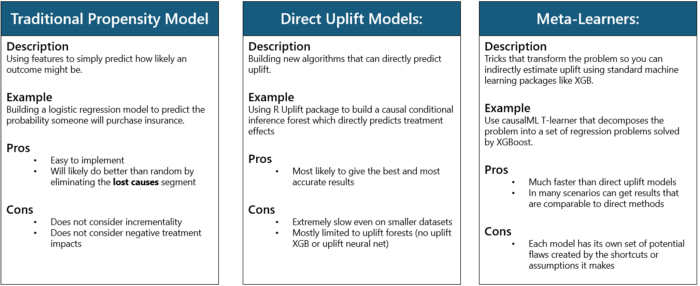
Traditional Propensity Model
This is actually not an uplift model but needs to be included because it is the classic approach to the uplift problem. The algorithm will typically be a classifier like logistic regression. These algorithms can output a probability 0 to 1 that can be used to sort the audience. Then a threshold can be selected (perhaps .70 probability or greater) as the cutoff for those who should be treated.
Direct Uplift Models
This pillar represents techniques and algorithms that allow you to directly model treatment effects. It requires the algorithm like random forest to be completely redesigned to feature select, hyper parameter tune, and fit to solve for the impact of (t) on (y) given (x). Typical algorithms found in a package like Scikit-learn cannot do that. You can implement uplift trees with the package Uplift for R and CausalML for Python.
Meta-Learners
The final pillar represents techniques and algorithms that can be used to model uplift but use some sort of shortcut to get to a proxy for uplift.
업리프트 대신 일종의 지름길을 사용하는 방법(?)
The proxy approaches tend to be useful in most applications and these shortcuts usually provide benefits in speed and/or simplicity.
빠르고 간단하다(?)
There seems to be many techniques so the list below is by no means comprehensive. There also seems to be different ways to implement each of these techniques depending on where you go.

- 싱글 모델(하나의 모델로 fit 한 후, 테스트 데이터의 treatment를 1,0으로 각각 채운 후 2개 데이터셋의 결과치가 나오면 2개 결과의 차이를 구한다)
- 투 모델(A/B 테스팅한 데이터가 있으면 실험군 데이터와 대조군 데이터를 분리한다. 2개의 분류 모델은 각각 fit 된다. 새로운 데이터에 2개 모델로 확률을 뱉는다. 2개 모델의 확률값을 뺌으로써 업리프트와 유사한 값을 얻을 수 있다.)
- 4개의 값을 뱉는 다중 분류기이다. ( 자세한 내용은 추가로 확인해봐야겠다. )
- T 러너
- R 러너
- X 러너
Current Challenges with Uplift Modeling (허들포인트)
Why Uplift modeling can be tricky.
The ground truth labels aren’t available unless the data is synthetic.
In machine learning, you usually have features (inputs to help with a prediction) and the ground truth labels (the target to predict).
In uplift modeling, the ground truth is never available because an individual cannot both see and not see the advertisement. Causal inference simulates the scenario that didn’t happen so then it is possible to estimate the ground truth labels and treat it as a machine learning problem.
Because the ground truth labels are not available, this makes measurement and validation a little less straightforward. Typically, you can see how the model is performing by comparing the predictions to actual. In uplift modeling, you see how the model is performing by comparing to an estimated actual.
Generating synthetic data for validation has an advantage in that it can be constructed to have both scenarios simulated. That way different techniques can be more cleanly evaluated to select a winner. However, the synthetic data probably will never perfectly reflect the real world data you want to uplift model on.
- Highly optimized packages like Scikit-learn are not set up to solve for uplift.
As previously mentioned, machine learning algorithms are set up to predict target (y) given features (x). Direct modeling requires both the algorithm and the entire machine learning pipeline to be adapted. Feature selection, model selection, hyper parameter tuning, and fitting with an optimized package like Scikit-learn is not straightforward.
Currently, (at the time of writing) direct methods are available but are slow even on small datasets.
- The names of things and techniques are unorganized with no consensus.
To prove the point, even the name of uplift modeling changes depending on where you look:
Estimating heterogeneous treatment effects (Example)
Incremental response modeling (Example)
Net scoring (Example)
True response modeling (Example)
Based on my own research, I am unsure if there is a comprehensive list of the techniques or a consensus on how to implement each technique.
