논문에 앞서 OCR 이해하기
OCR (Optical Character Recognition)
-
개념 : 컴퓨터가 글자의 위치와 정보를 인식하는 것
-
구성
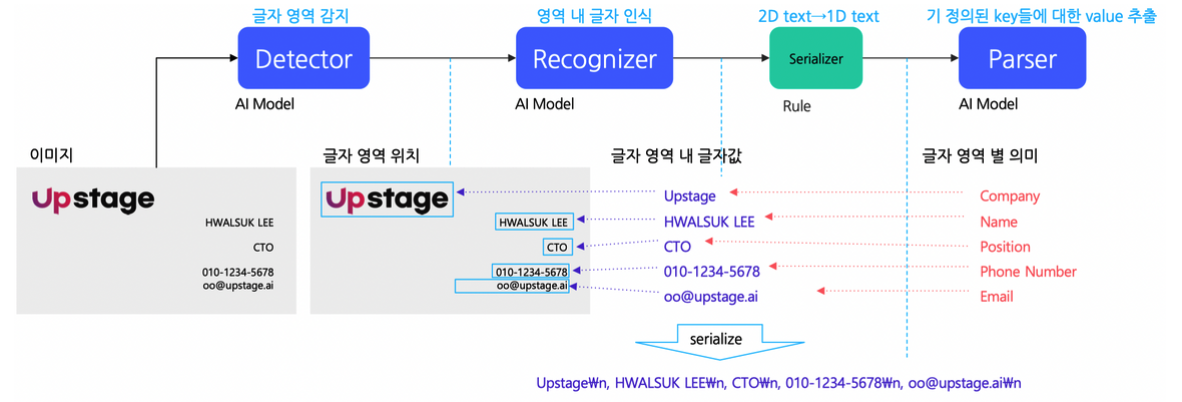
- Detector : 글자의 위치만을 검출한다.
- 글자검출은 글자의 클래스 정보는 필요 없고, 글자의 위치만 찾는 task 이다.
- 영역의 종횡비가 극단적인 경우가 많다.
- 객체 밀도가 매우 높은 경우가 있다.
- Recognizer : 영역 내의 글자를 인식한다.
- 이미지 전체가 입력이 아니라, 하나의 글자 영역에 해당하는 일부가 인식기의 입력임을 유의
- 글자인식기는 Computer Vision과 NLP의 교집합 영역
- Serializer : 좌표 값으로 나와있는 글자들을 사람이 읽기 쉽게 정렬해준다.
- 기본 기조는 사람이 읽는 순서대로 정렬
- Parser : Language-level Application
- 금칙어처리, 요약, 글자의미 파악, 등 사용자가 원하는 기능을 하도록
- Application 단계의 일을 수행
- 많은 경우 NLP와 결합해서 많은 기능 구현
- Detector : 글자의 위치만을 검출한다.
EAST (An Efficient and Accurate Scene Text Detector)
EAST 는 위와 같은 4단계의 OCR에서 1단계인 Detector의 역할을 수행하는 네트워크이다.
특징
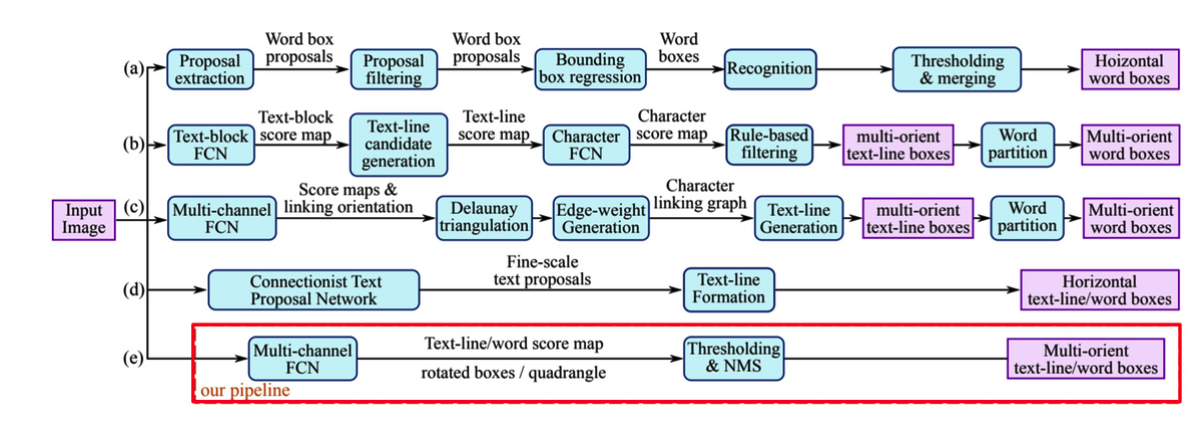
- OCR에서 Text Detector만을 수행하는 네트워크이다.
- 간단한 2-stage system 이다 - 이전 모델들에 비해 구조가 간단하다.
- 빠른 Inference와 end-to-end 학습이 가능하다.
Idea
-
구조

segment-based로 FCN을 통해 각 화소별 단위정보를 추출해서 그것을 후처리하는 방식으로 학습한다.
-
Fully Convolutional Network (FCN)
본 논문에서는 U-net 구조의 segmentation base를 사용한다.
pixel-wise prediction 이 가능하다.
-
FCN의 output 은 픽셀별로 다음과 같은 것들을 output으로
(1) score map : 글자 영역 중심에 해당하는지
(2) geometry map : (글자영역의 화소에 대하여) bbox의 위치는 어디인지
이 두 가지를 내보내도록 학습한다.
→ 굳이 글자 전체 영역인지 아닌지 학습하지 않고 위와 같이 나누어서 학습하는 이유는
글자 중심영역을 먼저 파악함으로써, 겹치는 글자간 간섭이 일어나지 않도록 하기 위해서다.
( = score map 을 가지는 글자 중심영역은, 다른 글자의 중심영역과 겹치기 힘들다.)
-
Output
1) Score Map : 글자 영역의 중심에 해당하는지
- 일반적으로 H와 W를 1/4크기로 줄여서 확인한다.
- GT bounding box를 줄여서 생성한다. 30%만큼 endpoint를 축소시키고 학습한다.
2) Geormetry map : 특정 화소가 글자영역이라면, 해당 bbounding box의 위치는 어디까지인지
- 영역으로부터 bbox의 4개의 경계선까지의 거리를 예측한다. 4-channel로 결과가 나온다.
- 박스가 얼마나 회전해있나 Angle (1-channel) 정보를 결과로 내보낸다.
-
Inference
1) Score Map 이진화
2) 사각형 좌표값 복원
3) Angle 역변환을 통해 기존의 box 복원
4) 화소별로 복원된 box들을 Locality-Aware NMS를 통해 하나의 박스로 출력
- Locality-Aware NMS 를 통해 일반 NMS보다 훨씬 빠른 속도를 확보가능하다
- Naive NMS → O(n^2), LA-NMS → O(n)

- Box들을 score map 값으로 weighted merge를 한다
-
Training
-
Loss
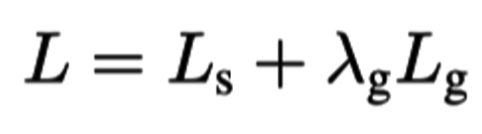
전체 Loss 는 Loss for score map + Loss for geometry map 으로 이루어져있다.
Loss별 자세한 설명은 생략한다.
-
