1. 1-stage detector 특징
- RPN 과정을 생략하고, 전체 맵을 보고 Localization, Classification 동시에 진행
- 간단하고 쉬운 디자인
- 빠른 속도
- 영역 추출이 없으므로 객체에 대한 맥락적 이해가 높음 → Background error가 낮음
2. YOLO : You Only Look Once
- Bbox Regression, Classification 동시에 하는 첫 번째 1-stage od
- Background는 2-stage보다 더 잘 잡아낸다
- 물체의 일반화 된 표현을 학습 → 새로운 도메인 이미지에 좋은 성능
방법
-
Backbone : GoogLeNet 변형
24conv layers → Feature Map
-
입력 이미지를 SxS 그리드 영역으로 나누기 (S=7) → Feature map = 7x7
-
셀마다 B 개의 bounding box, confidence score 계산 (B=2)
→ [x,y,w,h,c] x B개
-
셀마다 C 개 클래스 확률 계산 (C=30)
⇒ 맨 마지막 예측 값 : 7x7x(B * 5 + C) = 49x30 = 1470
-
총 49x2 = 98개의 bbox에 대해서 class 예측
-
Threshold Cutting + NMS Pruning
Loss
- Localization Loss + Confidence Loss + Classification Loss
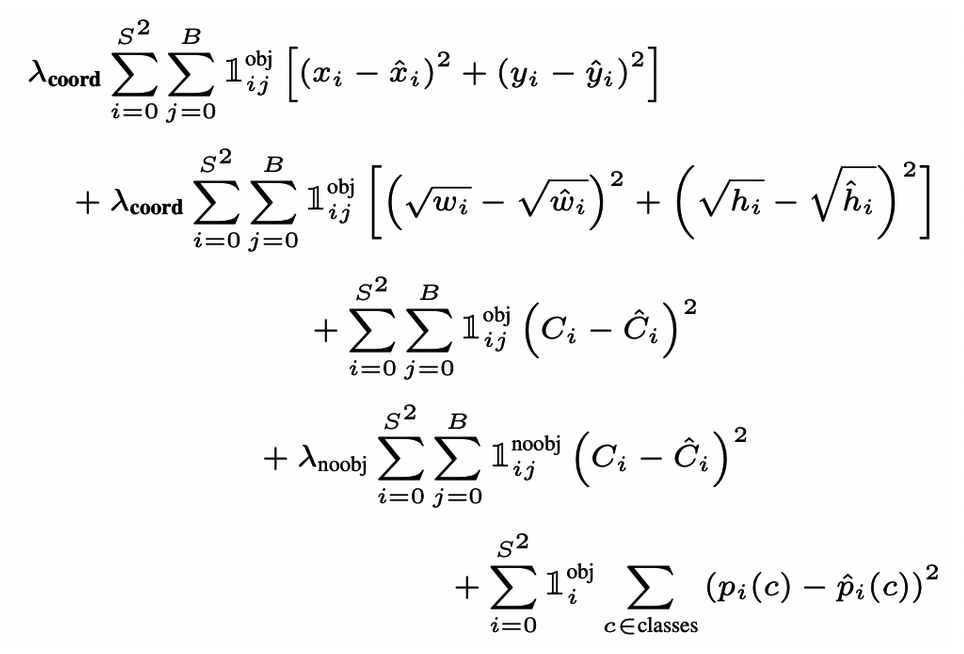
단점
-
7x7 그리드로 나누어 bb regression 수행
→ 더 작은 크기의 크기 검출 불가능
-
신경망의 마지막 Feature만 사용
→ 정확도 하락
3. SSD
- Single Shot Detector
- (내 생각) FPN버전의 1-stage OD
- 구조 : VGG16을 Backbone으로 하고 뒤에 Extra Convolution Layers 추가 + 300x300 images
- Extra Convolution Layers 에서 나온 feature map 모두 detection 수행에 사용
- 6개의 서로 다른 scaled feature map 사용
- early stage feature map → 작은 물체 탐지
- late stage feature map → 큰 물체 탐지
- Fully Connected Layer 대신 Convolution Layer 사용하여 속도 향상
- Anchor box처럼 default box 사용 (multi-scale, multi-ratio boxes)
- Output : 셀 x (박스 수 x (4+21)) Total output : 9732 Bboxes (38x38x4 + 19x19x6 + 10x10x6 + 5x5x6 + 3x3x4 + 1x1x4)
- Loss Localization Loss (Smooth L1) + Confidence Loss (Softmax)
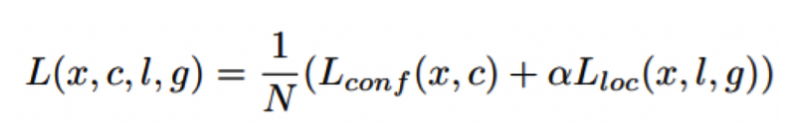
4. YOLO v2
- 3가지 파트에서 model 향상
- 정확도, 속도, 다
- 정확도 향상
- Batch Normalization
- High Resolution Classifier
- Fully Connected layer → Convolution layer
- Anchor Box 도입 + 좌표 값 대신 offset 예측
- Passthrough Layer 도입 (26x26 featuremap 분할 후 결합 → late stage에 추가)
- Multi-scale training
- 속도 향상
- Backbone : GoogLeNet → Darknet-19
- 다양성
- WordTree 구성해서 계층적인 물체파악이 가능
5. YOLO v3
- Backbone change → skip connection → max pooling 대신 convolution with stride 2 사용
- Multi-scale Feature Maps
- FPN 사용
6. RetinaNet
- Focal Loss : 1-stage 의 문제점인 class imbalance 를 해결함 = cross entropy + scaling factor 쉬운 예제에 작은 가중치, 어려운 예제에 높은 가중치
