Vector Databases
다른 데이터항목과 함께 벡터를 저장할 수 있는 데이터베이스.
빠른 검색 및 유사성 검색을 위해 벡터 임베딩을 인덱싱하고 저장하며, CRUD 작업, 메타데이터 필터링, 수평적 확장, 서버리스와 같은 기능 제공
(벡터 임베딩: AI가 복잡한 작업을 실행할 때 활용할 수 있는 장기 메모리를 유지하고 이해하는데 중요한 의미 정보를 포함하는 벡터 데이터 표현 유형)
Vector Database의 필요성
-
데이터를 효율적으로 저장하고 관리할 수 있음
: vector db는 데이터 포인트를 벡터 형태로 저장해 유사도 기반 검색에 최적화되어 있어, 임베딩된 데이터를 다루기 위한 목적으로 유용함 -
검색속도가 빠름
: vector db 적용했을 때 유사도 검색에서 두드러지는 측면을 보임 -
LLM과의 결합
: LLM과 vector db가 결합될때, vector db는 효율적인 유사도 검색과 임베딩 데이터 저장에 필수적이다. 또한, LLM이 단독으로 문서의 의미를 이해하고 연결하는 데에는 한계가 있지만, vector db가 결합되면 문맥에 맞는 정확한 정보를 제공하는 데 도움이 됨.
Vector Database 동작방식

(1) Indexing: PQ(Product Quantization), LSH(Locality-Sensitive Hashing), HNSW(최근접 이웃 검색 알고리즘) 등을 사용하여 벡터 색인.
(2) Query: 유사도 메트릭을 적용하여 가장 가까운 벡터를 찾기
(3) Post Processing: 데이터셋에서 최종 최근접 이웃을 검색하고 후처리하여 최종결과 반환
Vector Database 종류
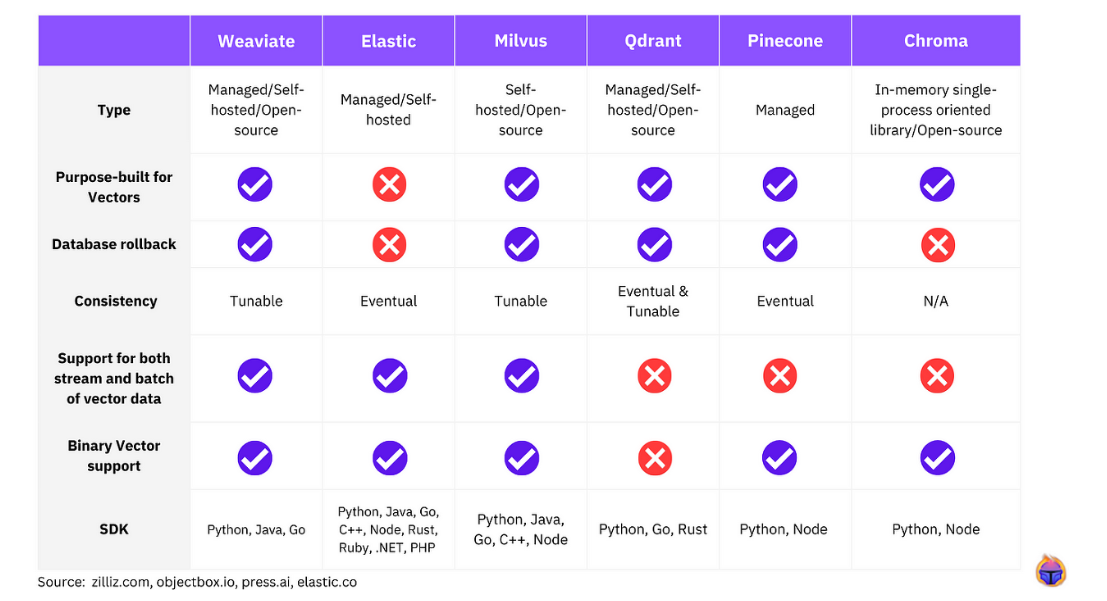
Pinecone을 제외하고는 로컬에서 직접 실행가능함
(1) Weaviate
- 오픈소스 벡터 데이터베이스로 자연어 처리에 강함
- Hugging Face, OpenAI와 통합가능
- 텍스트 이외에도 이미지, 오디오 등 다양한 형태의 벡터 저장 검색 가능
- RESTful API와 GraphQL을 지원하여 사용이 간편함
(2) Milvus
- 고성능의 근사 최근접 이웃 검색 엔진
- 다양한 알고리즘 지원하며, 대규모 데이터셋에 최적화
- 분산 아키텍처를 제공하여, 데이터가 커지더라도 성능을 유지가능
(3)Qdrant
- 문서 및 임베딩 저장을 위한 벡터 데이터베이스
