데이터 필터링
하나 이상의 테이블에서 여러 데이터를 가져온다.
단, 조건에 맞는 데이터만 가져옴
기본 문법
SELECT [COLUMN], [COLUMN], […]
FROM [TABLE]
WHERE [CONDITIONS]
- 컬럼 값과 VALUE 를 비교함.
- 자바의 비교연산과 동일한 방법.
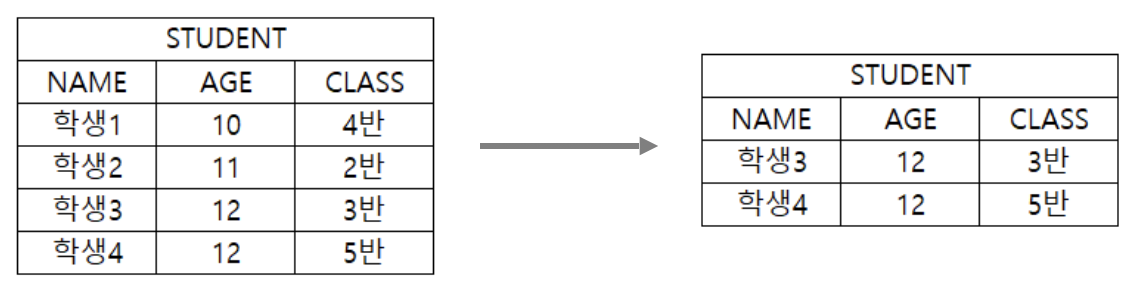
예시 실습
-- EMPLOYEES 테이블에서 COMMISSION_PCT(인센티브)를 0.2보다 크거나 같은 정보를 SALARY로 내림차순 정렬해서 모든 정보를 조회.
SELECT *
FROM EMPLOYEES
WHERE COMMISSION_PCT >= 0.2
ORDER BY SALARY DESC
;
-- DEPARTMENTS 테이블에서 LOCATION_ID가 1500부터 2000 사이에 있는 모든 정보를 조회.
SELECT *
FROM DEPARTMENTS
WHERE LOCATION_ID BETWEEN 1500 AND 2000
;
-- DEPARTMENTS 테이블에서 MANAGER_ID(부서장 사원의 번호)가 없는 것만 조회.
SELECT *
FROM DEPARTMENTS
WHERE MANAGER_ID IS NULL
;
-- DEPARTMENTS 테이블에서 MANAGER_ID(부서장 사원의 번호)가 있는 것만 조회.
SELECT *
FROM DEPARTMENTS
WHERE MANAGER_ID IS NOT NULL
;
-- EMPLOYEES 테이블에서 DEPARTMENT_ID(근무중인 부서번호)가 90이거나 30이거나 60이거나 100인 모든 정보를 조회.
SELECT *
FROM EMPLOYEES
WHERE DEPARTMENT_ID IN (90, 30, 60, 100) -- IN 에 넣을 수 있는 비교값은 1000개 까지만 사용.
;
- EMPLOYEES 테이블에서 JOB_ID(직무아이디)가 IT_PROG 이거나 AD_VP 이거나 FI_ACCOUNT 인
-- EMPLOYEE_ID, JOB_ID, SALARY를 조회.
SELECT EMPLOYEE_ID
, JOB_ID
, SALARY
FROM EMPLOYEES
WHERE JOB_ID IN ('IT_PROG', 'AD_VP', 'FI_ACCOUNT')
;
-- EMPLOYEES 테이블에서 JOB_ID(직무아이디)가 IT_PROG이 아니고 AD_VP도 아니고 FI_ACCOUNT도 아닌
-- EMPLOYEE_ID, JOB_ID, SALARY를 조회.
SELECT EMPLOYEE_ID
, JOB_ID
, SALARY
FROM EMPLOYEES
WHERE JOB_ID NOT IN ('IT_PROG', 'AD_VP', 'FI_ACCOUNT')
;
SQL 연산자의 종류
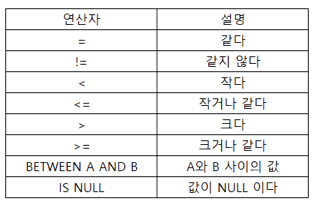
- WHERE MANAGER_ID IS NULL / WHERE MANAGER_ID IS NOT NULL 부등호 없이 사용
그 외의 연산자
IN, LIKE, NOT
- IN : 하나의 컬럼에 여러 개의 값을 검색함. (-> IN과 같이 쓸 수 없음)
- LIKE : 하나의 컬럼에 “포함된” 값을 검색함. (-> LIKE 도 CPU를 많이 써서 실무에서는 잘 쓰지 않음)
WILD CARD 가 사용된다.- % , _
-- LIKE (자리수 체크) - 문자열 검색.
-- WILD CARD
-- "_" : 아무글자 하나.
-- "%" : 포함되어있음.
-- "A%": A로 시작하는 것
-- "%A": A로 끝나는 것
-- "%A%": A가 포함되어 있는 것.-- EMPLOYEES 테이블에서 FIRST_NAME이 5글자인 모든 정보를 조회.
SELECT *
FROM EMPLOYEES
WHERE FIRST_NAME LIKE '_____'
;
-- EMPLOYEES 테이블에서 FIRST_NAME이 5글자가 아닌 모든 정보를 조회.
SELECT *
FROM EMPLOYEES
WHERE FIRST_NAME NOT LIKE '_____'
;
-- EMPLOYEES 테이블에서 EMAIL이 S로 시작하는 모든 정보를 조회.
SELECT *
FROM EMPLOYEES
WHERE EMAIL LIKE 'S%'
;
-- EMPLOYEES 테이블에서 PHONE_NUMBER가 "2"로 끝나고
-- SALARY가 5000 이상이며
-- JOB_ID 가 "SA_REP" 인 모든 정보를 조회한다.
SELECT *
FROM EMPLOYEES
WHERE PHONE_NUMBER LIKE '%2'
AND SALARY >= 5000
AND JOB_ID = 'SA_REP'
;
-- EMPLOYEES 테이블에서 FIRST_NAME이 6자리이고
-- JOB_ID가 "AD_PRES" 이거나, "IT_PROG" 인 모든 정보를 조회한다.
-- IN 을 이용한 작성
SELECT *
FROM EMPLOYEES
WHERE FIRST_NAME LIKE '______'
AND JOB_ID IN ('AD_PRES', 'IT_PROG')
;
- WHERE절은 여러 개의 조건을 지원한다.
AND, OR 를 사용해 여러 개의 조건을 사용할 수 있다. --> 논리연산
WHERE [CONDITION1] --> 반드시 WHERE로 시작하고 AND
AND [CONDITION2] --> 수 제한 X
AND [CONDITION3]- AND와 OR 가 동시에 사용될 때 AND 가 우선순위를 가진다.
WHERE [CONDITION1]
AND [CONDITION2]
AND [CONDITION3]
OR [CONDITION4]
AND [CONDITION5]
➔ CONDITION1 AND CONDITION2
➔ CONDITION2 AND CONDIDTION3
➔ CONDITION3 OR (CONDITION4 AND CONDITION5)
// CONDITION4 AND CONDITION5 가 우선처리됨.- 우선순위를 높여주기 위해서 괄호를 사용한다.
WHERE [CONDITION1]
AND [CONDITION2]
AND ([CONDITION3]
OR [CONDITION4])
AND [CONDITION5]
➔ CONDITION1 AND CONDITION2
➔ CONDITION2 AND (CONDIDTION3 OR CONDITION4) AND CONDITION5
// 우선순위를 높여주기 위해 괄호를 사용 예제
-- EMPLOYEES 테이블에서 FIRST_NAME이 6자리이고
-- JOB_ID가 "AD_PRES" 이거나, "IT_PROG" 인 모든 정보를 조회한다.
SELECT *
FROM EMPLOYEES
WHERE FIRST_NAME LIKE '______'
AND (JOB_ID = 'AD_PRES'
OR JOB_ID = 'IT_PROG')
;
-- EMPLOYEES 테이블에서 MANAGER_ID 가 NULL 이 아니고
-- COMMISSION_PCT 는 NULL 이고
-- EMPLOYEE_ID 는 200 미만이면서
-- EMAIL이 "S" 혹은 "D"로 시작하는 모든 정보를 조회.
SELECT *
FROM EMPLOYEES
WHERE MANAGER_ID IS NOT NULL
AND COMMISSION_PCT IS NULL
AND EMPLOYEE_ID < 200
AND (EMAIL LIKE 'S%'
OR EMAIL LIKE 'D%')
;그룹 함수
데이터의 요약이 필요할 때 사용
- Row 의 수 ➔ COUNT(COLUMN)
전체 사원의 수 등등 - 특정 컬럼 값 중 가장 큰 수 ➔ MAX(COLUMN)
전체 사원 중 가장 많은 연봉
전체 사원 중 가장 최신에 입사한 날짜 등등 - 특정 컬럼 값 중 가장 작은 수 ➔ MIN(COLUMN)
전체 사원 중 가장 적은 연봉
전체 사원 중 가장 일찍 입사한 날짜 등등 - 특정 컬럼 값 중 평균 값 ➔ AVG(COLUMN)
전체 사원의 평균 연봉 등등 - 특정 컬럼의 총 합계 ➔ SUM(COLUMN)
전체 사원의 연봉 총 합 등등
-- 모든 사원들의 연봉 총합, 최대 연봉, 최소 연봉, 평균 연봉, 사원의 수를 조회.
SELECT SUM(SALARY)
, MAX(SALARY)
, MIN(SALARY)
, AVG(SALARY)
, COUNT(EMPLOYEE_ID) -- COUNT 함수의 파라미터는 PK를 쓰는게 원칙
, MAX(HIRE_DATE) --가장 최근의 입사일자
, MIN(HIRE_DATE) --가장 과거의 입사일자
FROM EMPLOYEES
;데이터 그룹핑
Row를 특정 기준으로 분류해, 분류별 그룹함수를 사용할 수 있다.
SELECT [COLUMN], [COLUMN], […]
FROM [TABLE]
WHERE [CONDITIONS]
GROUP BY [COLUMN], [COLUMN], […] -- CPU와 메모리를 넘 많이 사용해서 잘 안쓰는게 좋음
// (ORDER BY가 젤 마지막 / ORDER BY가 없다면 GROUP BY 가 마지막)
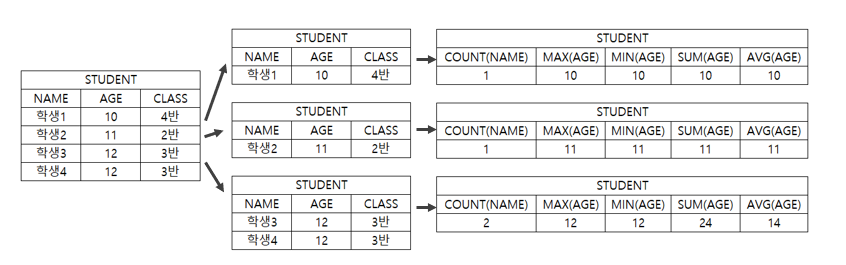
데이터 그룹 필터링
- GROUP BY된 결과에서 집계함수로 필터링 할 수 있다.
SELECT COUNT(NAME)
, MAX(AGE)
, MIN(AGE)
, SUM(AGE)
, AVG(AGE)
FROM STUDENT
GROUP BY CLASS
HAVING COUNT(NAME) > 1
-- GROUP BY 이용.
-- 부서별 근무중인 부서 번호, 연봉의 합계, 최대 연봉, 가장 늦게 입사한 날짜, 가장 일찍 입사한 날짜, 사원의 수 조회.
SELECT DEPARTMENT_ID -- ORA-00937: 단일 그룹의 그룹 함수가 아닙니다
, SUM(SALARY)
, MAX(SALARY)
, MAX(HIRE_DATE)
, MIN(HIRE_DATE)
, COUNT(EMPLOYEE_ID)
FROM EMPLOYEES
GROUP BY DEPARTMENT_ID -- ORA-00937: 단일 그룹의 그룹 함수가 아닙니다 <-- 이 에러가 나지 않음
;
-- 사원 정보에서 '직무 아이디'별 사원의 수와 '직무 아이디'를 조회한다.
SELECT COUNT(EMPLOYEE_ID)
, JOB_ID
FROM EMPLOYEES
GROUP BY JOB_ID
;-- 사원 정보에서 동일한 '성'이 두명 이상이 있는 사원들만 조회한다.
-- '성'별 사원의 수, '성'
SELECT COUNT(EMPLOYEE_ID)
, LAST_NAME
FROM EMPLOYEES
GROUP BY LAST_NAME
HAVING COUNT(EMPLOYEE_ID) > 1 --> 데이터 검증할때만 가끔 쓰고 평소에는 성능때문에 잘 안씀
;
-- 사원 정보에서 직무 아이디별 사원의 수와 직무 아이디를 조회하는데
-- 사원의 수가 3명 이상인 정보만 조회한다.
SELECT COUNT(EMPLOYEE_ID)
, JOB_ID
FROM EMPLOYEES
GROUP BY JOB_ID
HAVING COUNT(EMPLOYEE_ID) >= 3
;