default
m = Prophet()
m.fit(df)future = m.make_future_dataframe(periods=365) # 2021.12.31까지의 데이터를 예측, 365일
forecast = m.predict(future)
forecast[['ds', 'yhat', 'yhat_lower', 'yhat_upper']].tail()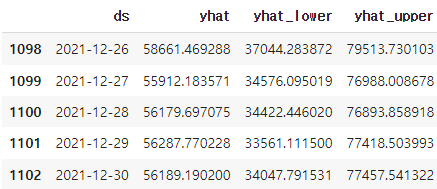
forecast 시각화
m.plot(forecast);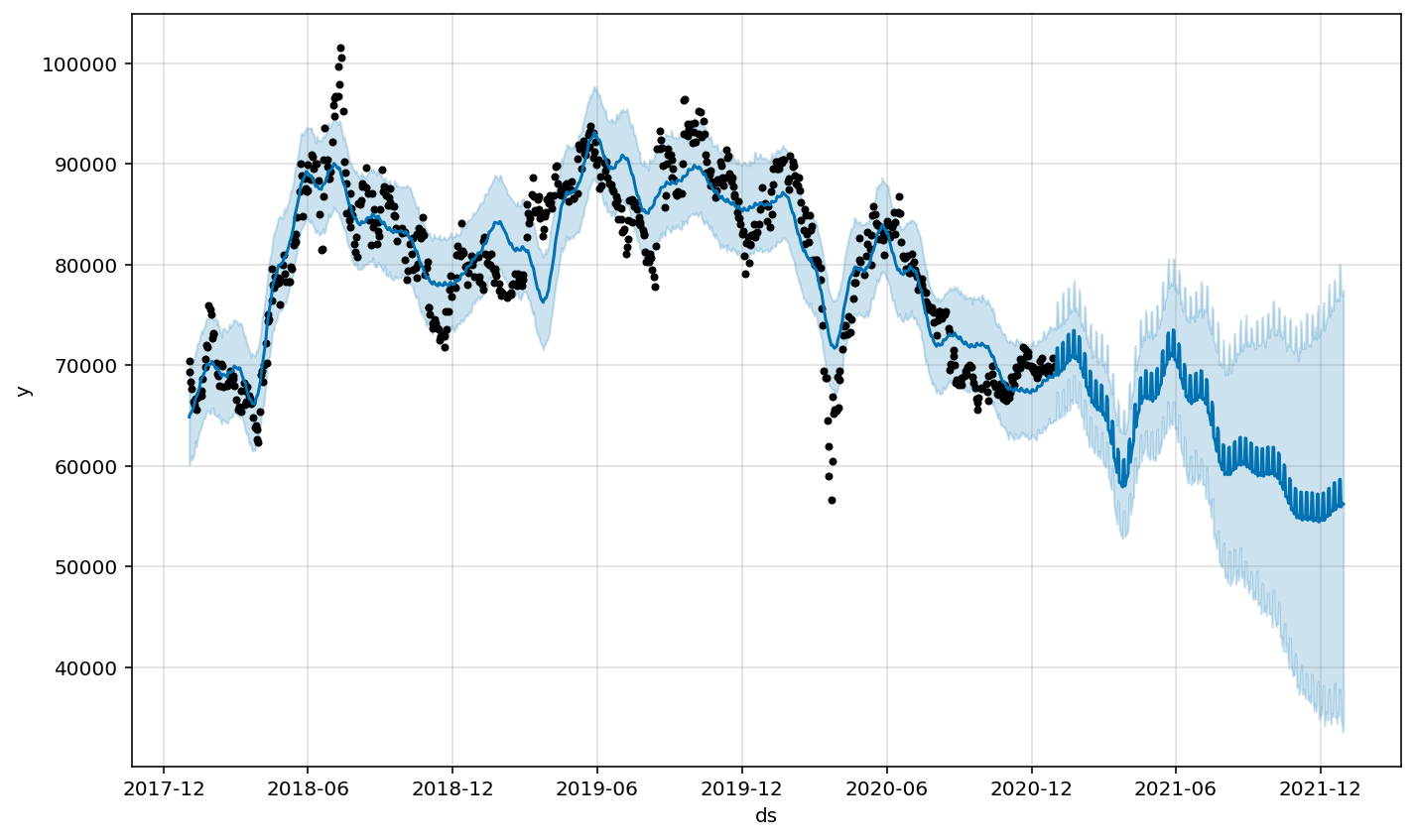
cross_validation
- initial = 초기 학습 범위
- period = 학습 간격 (~마다)
- horizon = 예측 범위
# ex
from prophet.diagnostics import cross_validation
df_cv = cross_validation(m, initial='365 days', period='180 days',horizon = '180 days')
→ 1년치 데이터 학습, 180일마다 180일간의 값을 예측한다.
# input
df_cv.cutoff.unique()
# output
array(['2019-01-15T00:00:00.000000000', '2019-07-14T00:00:00.000000000',
'2020-01-10T00:00:00.000000000', '2020-07-08T00:00:00.000000000',
'2021-01-04T00:00:00.000000000', '2021-07-03T00:00:00.000000000'],
dtype='datetime64[ns]')df_cv 확인
df_cv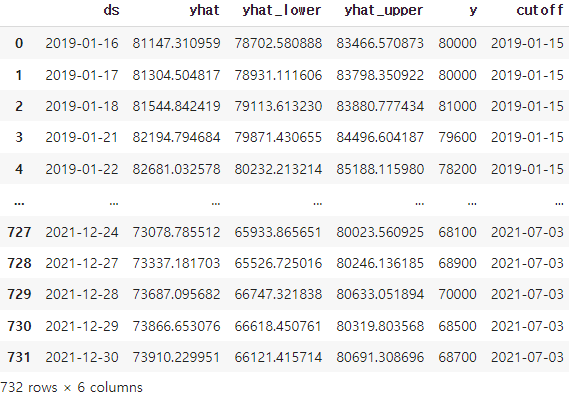
교차검증 시각화
m.plot(df_cv);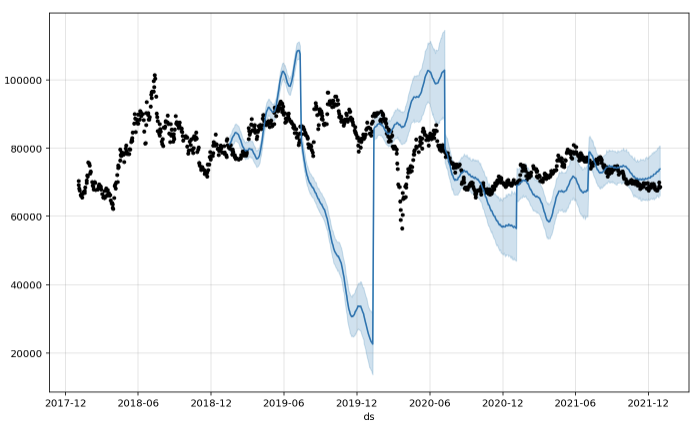
cutoff
- 교차 검증 중에 사용할 컷오프 날짜 벡터
- 입력하지 않는 경우 (끝-horizon)에서 시작하는 작업은 초기값에 도달할 때까지 간격을 두고 컷오프를 만드는 역방향으로 작업
# Python
cutoffs = pd.to_datetime(['2013-02-15', '2013-08-15', '2014-02-15'])
df_cv2 = cross_validation(m, cutoffs=cutoffs, horizon='365 days')
→ 6월 간격으로 3개의 컷오프 지정
performance_metrics
- MSE mean squared error
- RMSE root mean squared error
- MAE mean absolute error
- MAPE mean absolute percent error
- MDAPE median absolute percent error
- coverage of the yhat_lower and yhat_upper estimates
# Python
from prophet.diagnostics import performance_metrics
df_p = performance_metrics(df_cv)
df_p.head()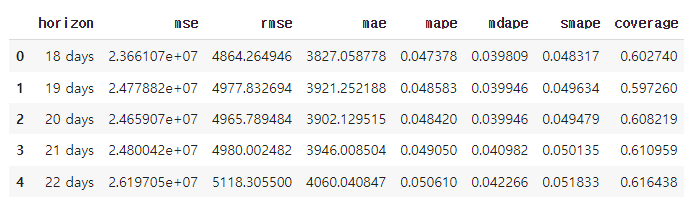
plot_cross_validation_metric
- 교차 검증 metricss는 plot_cross_validation_metric 함수를 사용하여 시각화 가능
- 파란색 선은 MAPE 값을 나타내며, 점은 각 예측에 대한 MAPE를 df_cv 단위로 나타낸 것
from prophet.plot import plot_cross_validation_metric
fig = plot_cross_validation_metric(df_cv, metric='rmse') # mse, mae, mape, ...
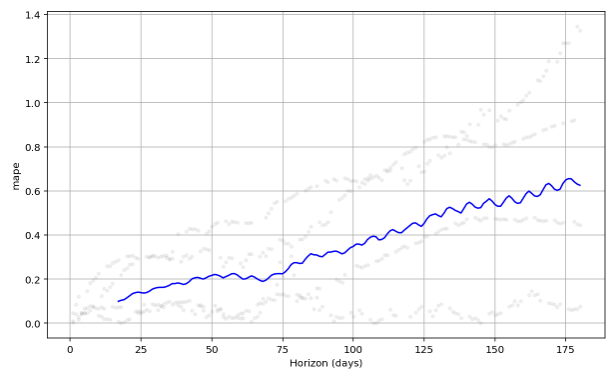
→ 향후 50일 뒤 20% 안팎의 오류가 일반적으로, 180일 후 예측에 대해서는 최대 60%까지 오류가 증가함을 확인
Hyperparameter tuning
prophet의 교차 검증에서 changepoint_prior_scale 이나 seasonality_prior_scale 에 대한 Hyperparameter 값을 조정할 수 있다.
import itertools
import numpy as np
import pandas as pd
param_grid = {
'changepoint_prior_scale': [0.001, 0.01, 0.1, 0.5],
'seasonality_prior_scale': [0.01, 0.1, 1.0, 10.0],
}
# Generate all combinations of parameters
all_params = [dict(zip(param_grid.keys(), v)) for v in itertools.product(*param_grid.values())]
rmses = [] # Store the RMSEs for each params here
# Use cross validation to evaluate all parameters
for params in all_params:
m = Prophet(**params).fit(df) # Fit model with given params
df_cv = cross_validation(m, initial='365 days', period='180 days',horizon = '180 days', parallel="processes")
df_p = performance_metrics(df_cv, rolling_window=1)
rmses.append(df_p['rmse'].values[0])
# Find the best parameters
tuning_results = pd.DataFrame(all_params)
tuning_results['rmse'] = rmses
print(tuning_results)
tuning_results.sort_values('rmse')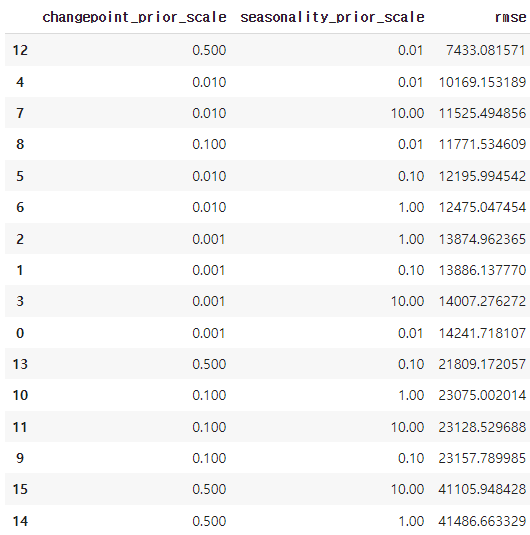
best parameter
best_params = all_params[np.argmin(rmses)]
print(best_params){'changepoint_prior_scale': 0.5, 'seasonality_prior_scale': 0.01}+)
best parameter로 rmse값이 가장 적게 기록된 hyper parameter 값을 조정하여 모델 학습 및 시각화를 다시 진행
m = Prophet(changepoint_prior_scale = 0.5,seasonality_prior_scale = 0.01)
m.fit(df21)
future = m.make_future_dataframe(periods=365)
forecast = m.predict(future)forecast 시각화
m.plot(forecast);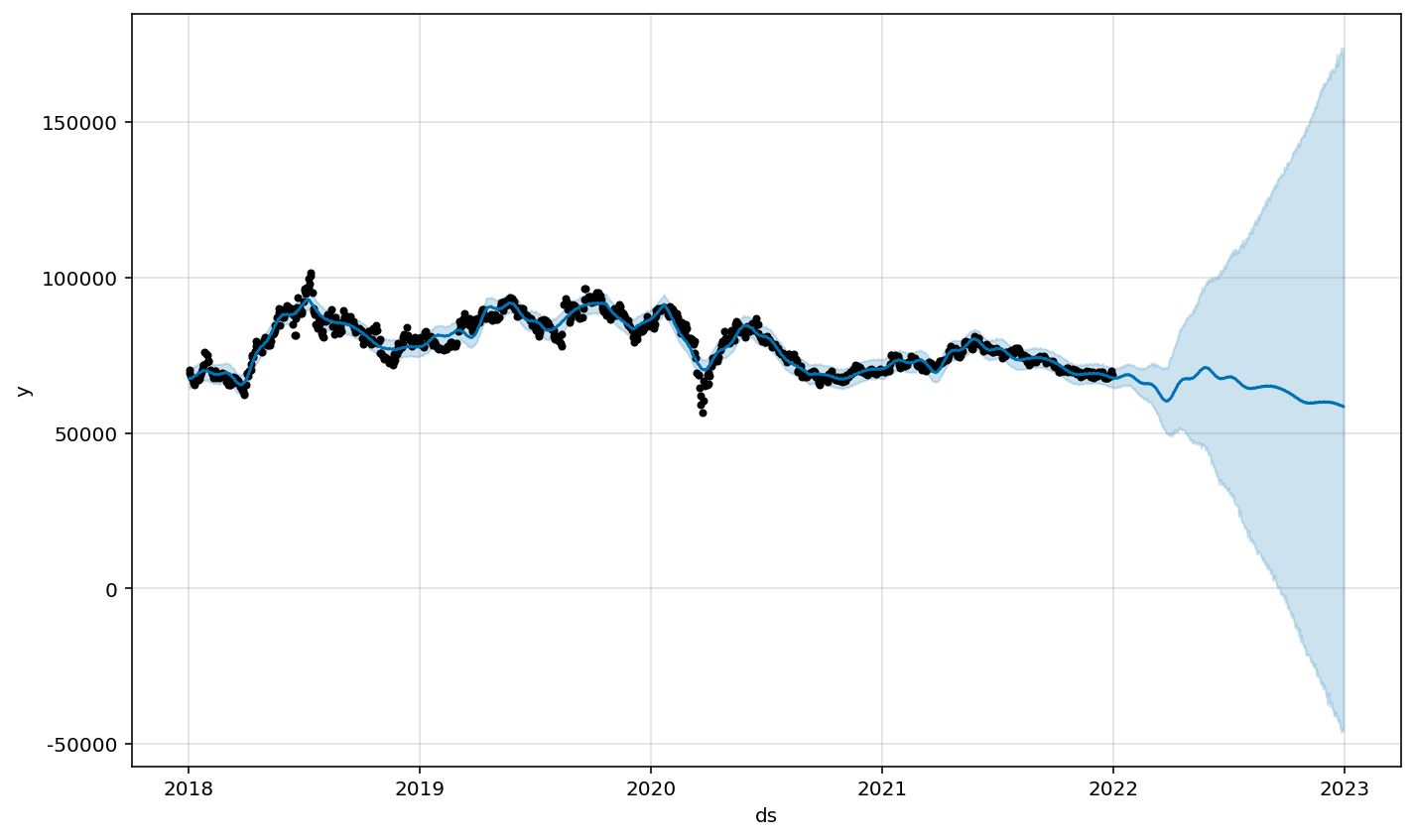
교차검증 시각화
df_cv = cross_validation(m, initial='365 days', period='180 days',horizon = '180 days')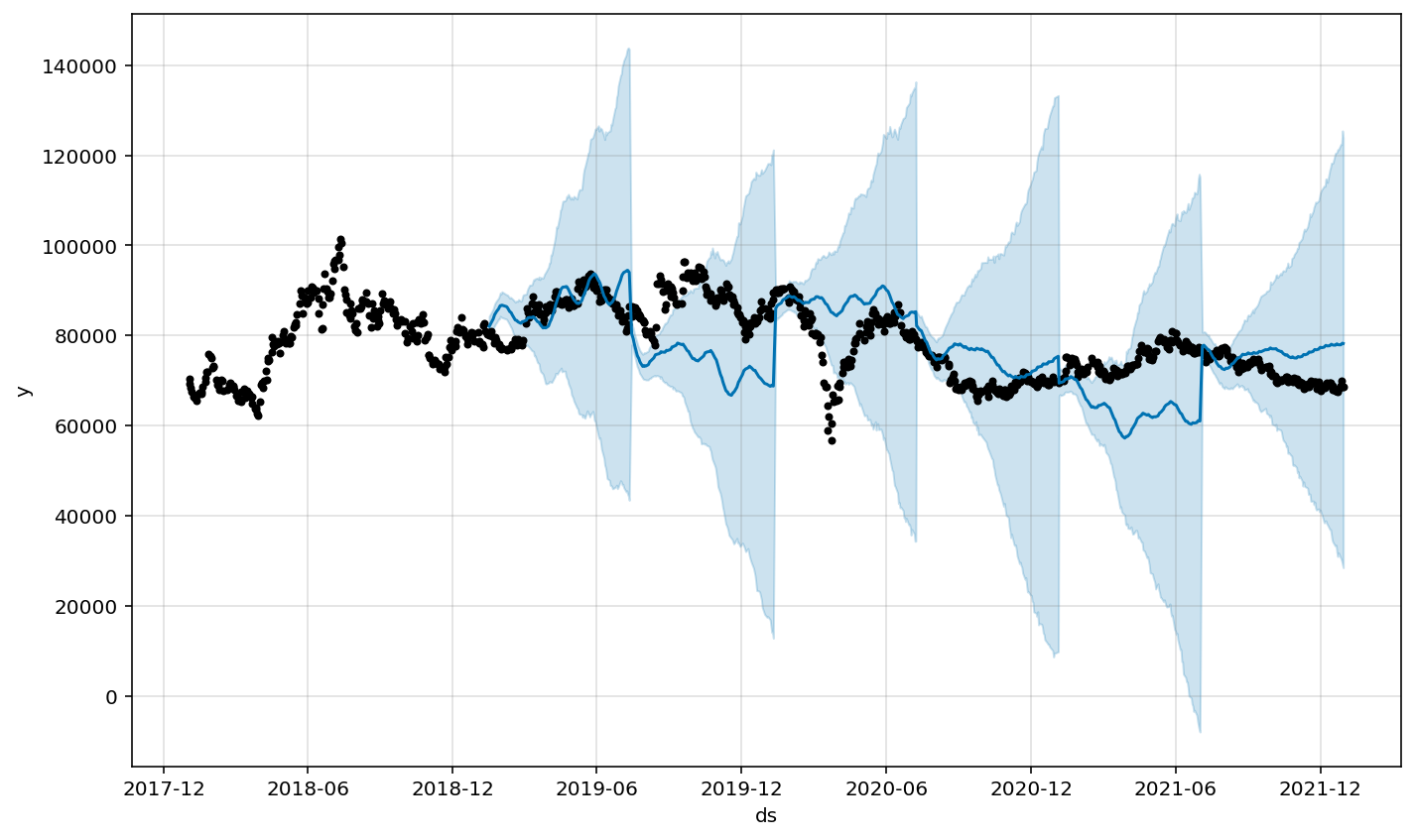
참고
