[Pytorch] 1-3
1.텐서다루기
2.텐서 연산
3.자동미분
4.linearRegression
5.deeplearningFlow
6.modeling
7.training
8.model save
9ImageFolder
10.Custom dataset
11.Transforms
1.텐서 다루기
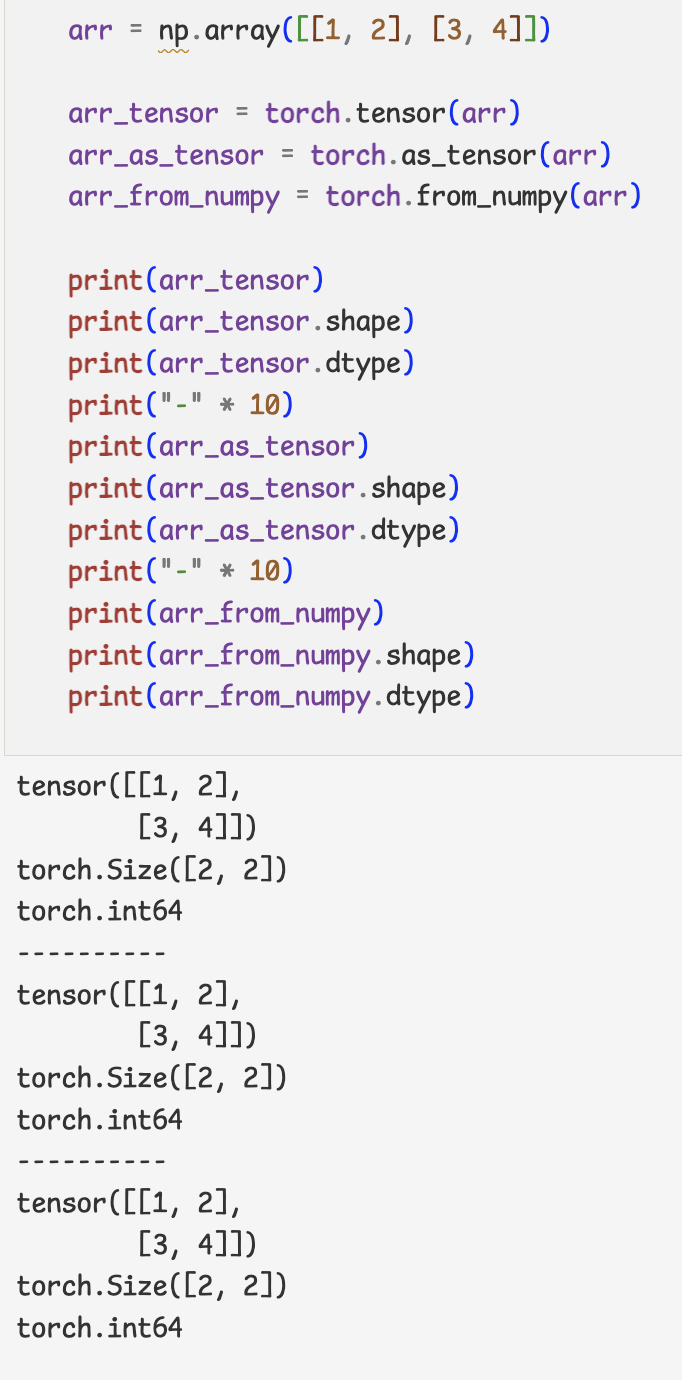
- 기존의 데이터를 Torch의 Tensor로
- Torch 의 Tensor 속성값 확인
- Torch를 numpy 배열로
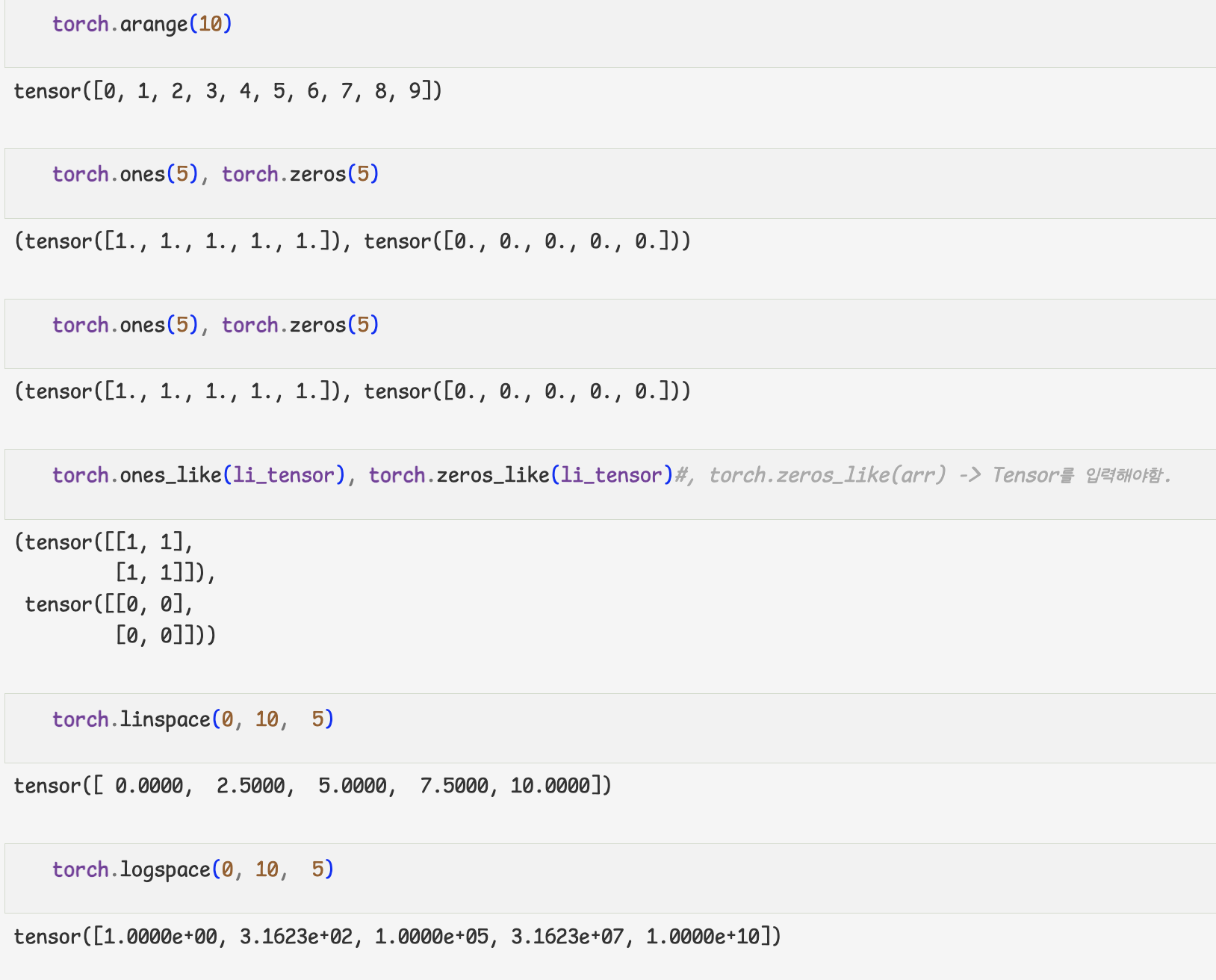
- 특정한 값의 Tensor 생성하기
- 난수 생성하기
- 데이터 타입
- GPU 사용하기
-Torch에서는 GPU 사용을 위해서 데이터 타입을 변환해줘야 함
-GPU를 사용하기 위해 Cuda에서 사용하는 데이터타입으로 변환해줘야함
1.만들 때,device 설정해두기
2.tensor_var.cuda()
3.tensor_var.to(device)
=> 대부분은 이렇게 사용







2.텐서 연산
기본 연산
torch.abs: 절대값torch.sign: 부호torch.round: 반올림torch.ceil: 올림torch.floor: 내림torch.square: 제곱torch.sqrt: 제곱근torch.maximum: 두 텐서의 각 원소에서 최댓값만 반환.torch.minimum: 두 텐서의 각 원소에서 최솟값만 반환.torch.cumsum: 누적합torch.cumprod: 누적곱
- 차원 축소 연산
- 행렬 연산
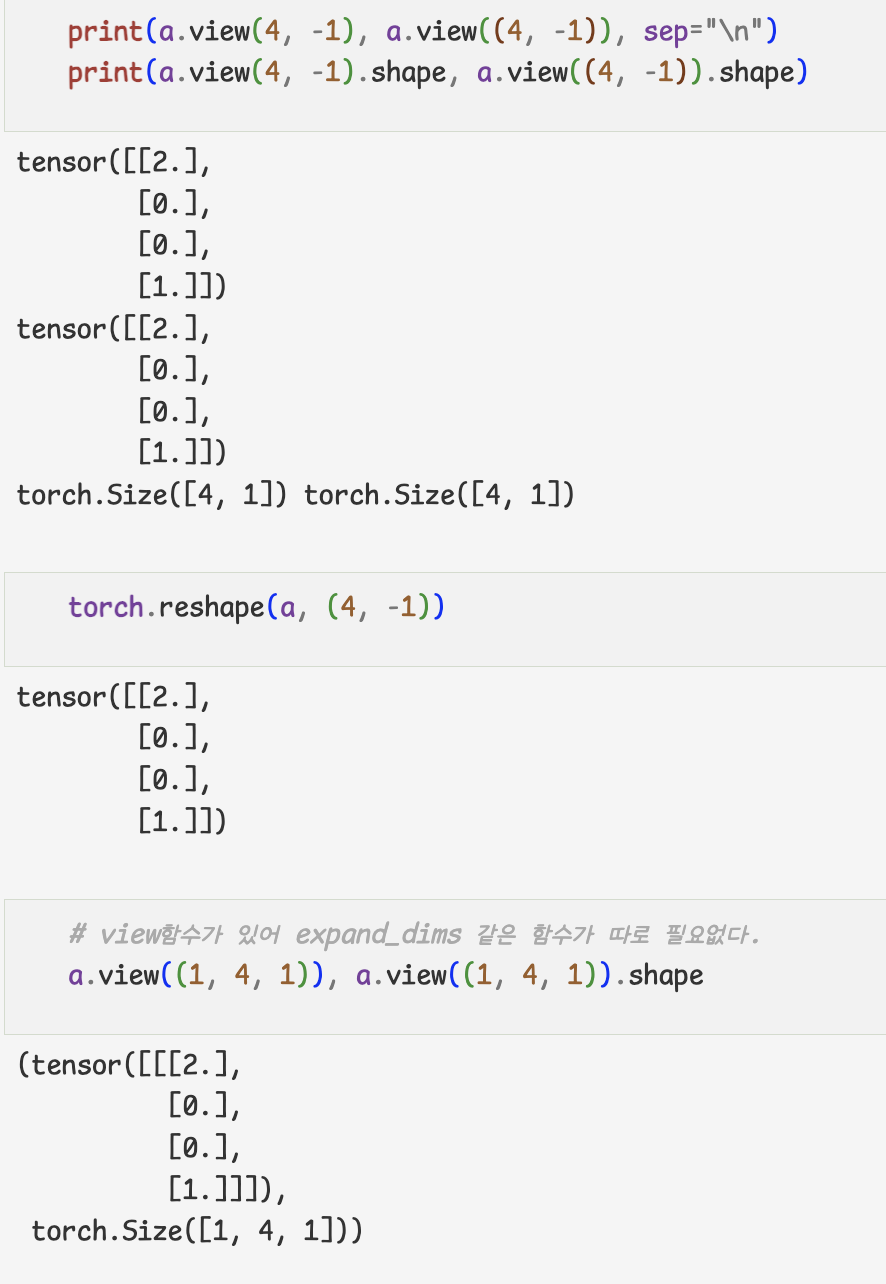
- 크기와 차원을 바꾸는 명령
- 여러 함수가 torch.명령어 형태,tensor.명령어로 사용할 수 있다.
- 함수 끝에 _를 붙이면 inplace명령이 된다.
- indexing,slicing
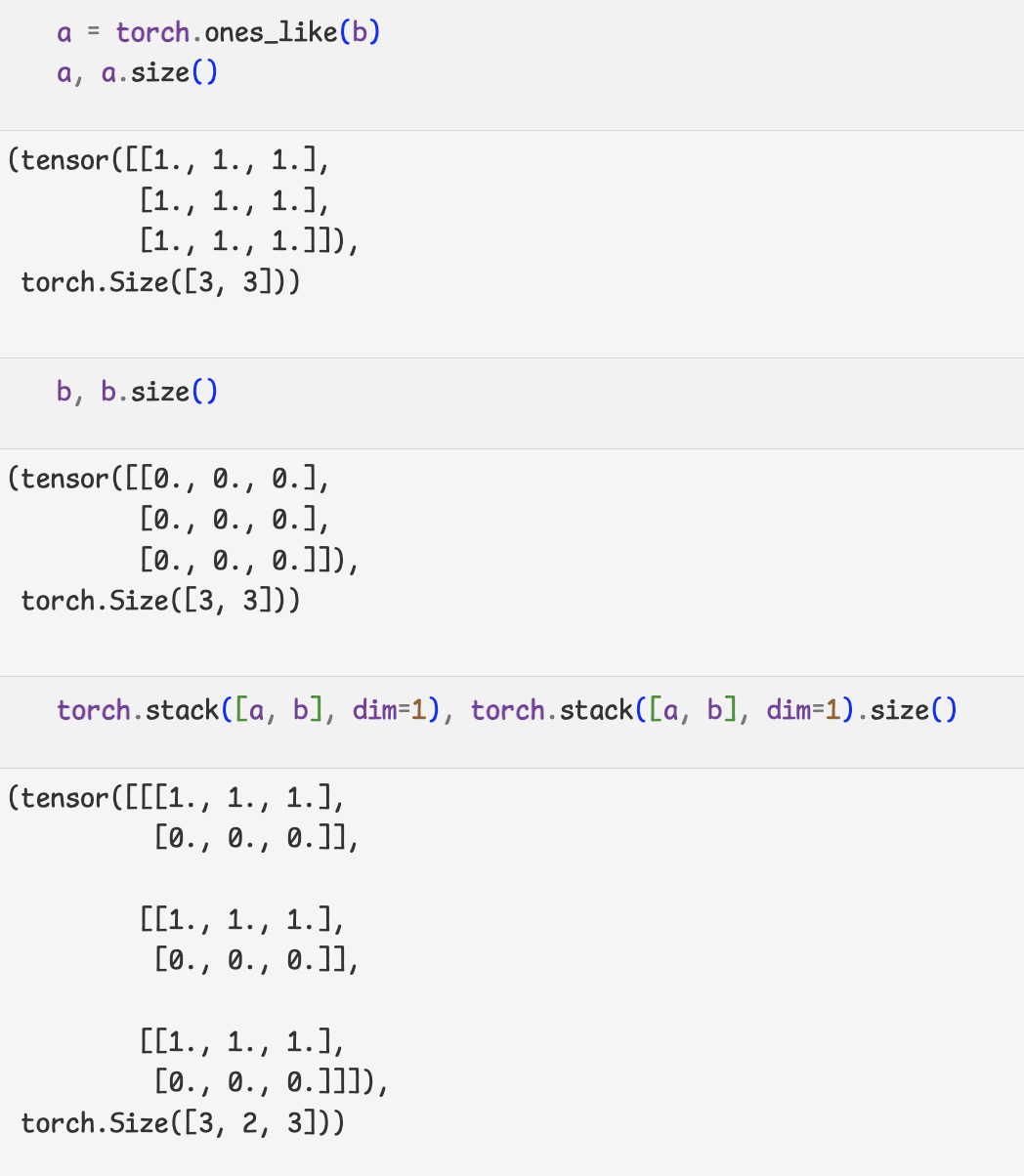
- 텐서를 나누거나 두개 이상의 텐서를 합치는 명령
-나누는 연산
-결합하는 연산















3.자동 미분
- 'autograd'는 Pytorch에서 핵심적인 기능
-텐서의 연산에 대해 자동으로 미분값을 구해주는 기능
-텐서 자료를 생성할 때 'requiresgrad'인수를 true 설정 혹은 .requires_grad(True)를 실행 하면 미분값 계산
- 'grad_fn'속성을 출력해 미분 함수 확인 가능
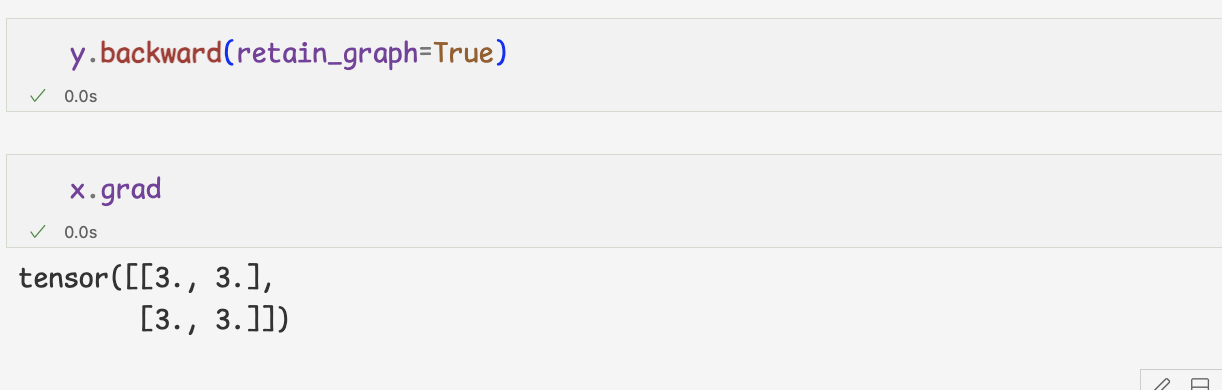
- x의 grad속성을 확인하면 미분값 확인 가능
-backward()함수는 자동으로 미분값을 계산해,requires_grad 인수가 True로 설정된 변수의 grad속성의 값을 갱신
-retain_graph는 미분을 연산하기 위한 임시 그래프 유지여부 설정
기본값은 false,동일한 연산에 대해 여러번 미분을 위해서는 True 설정
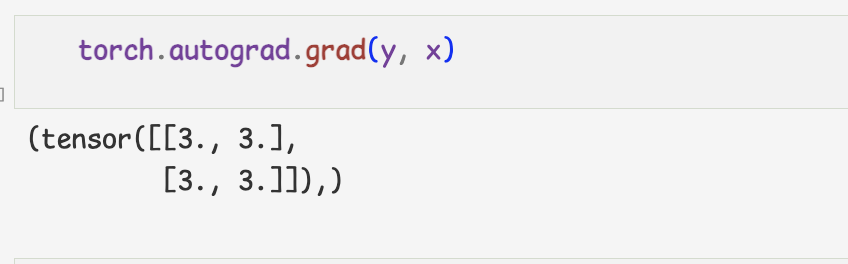
- torch.autograd.grad()함수를 사용해 tf.GradientTape 처럼 사용할 수 있다.
- 특정 연산에는 미분값을 계산하고 싶지 않은 경우에는
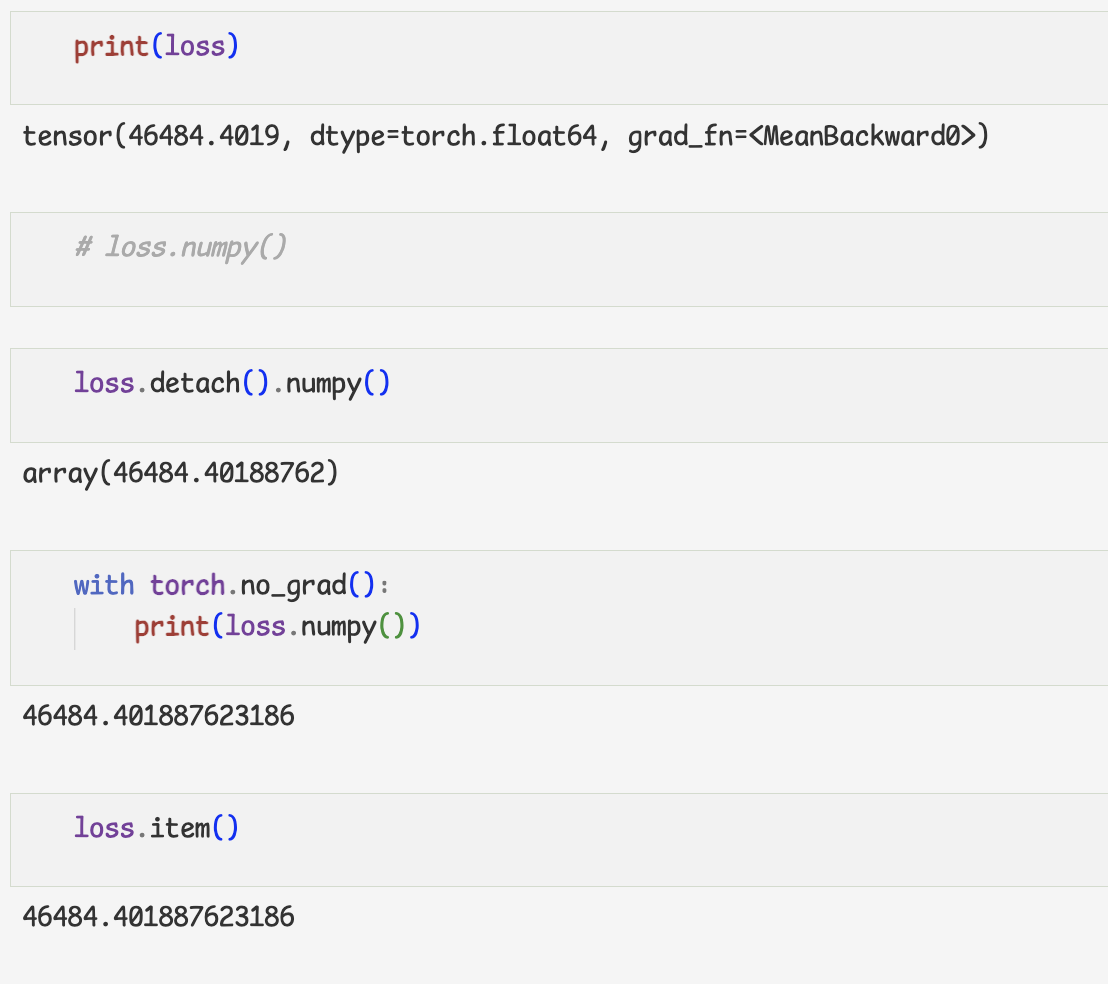
-.detach()함수
-with torch.no_grad()



4.linearRegression
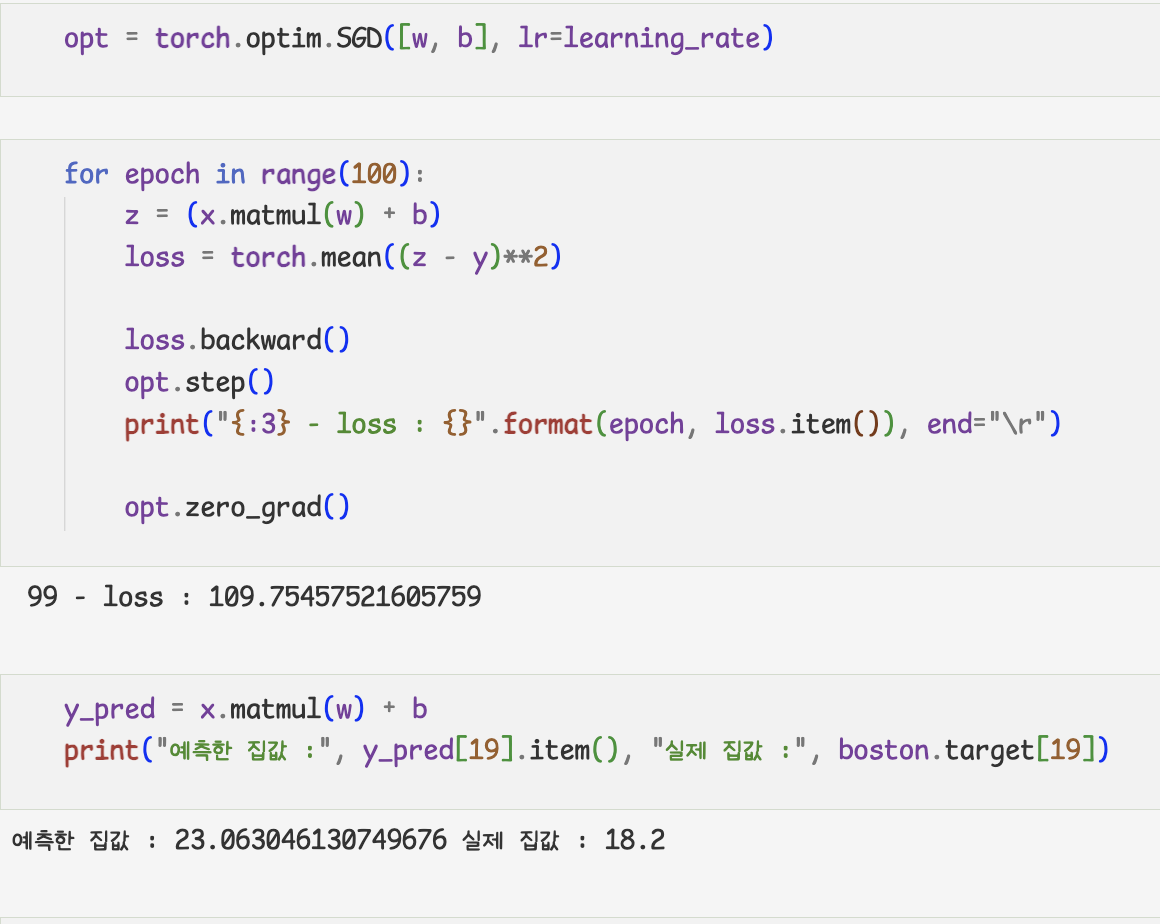
- Pytorch 선형 회귀 구현
- Gradient descent 방식
- assing대신에 data에 접근해서 값을 수정
-tensor.data=다른 데이터
- optimizer 사용하기




5.deeplearningFlow
전체 딥러닝 플로우 구현 해보기
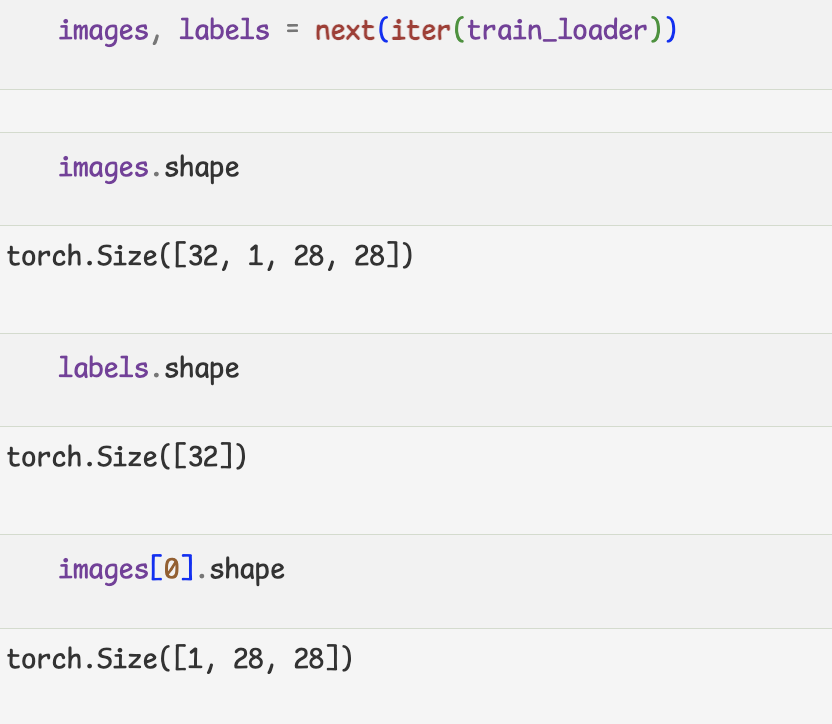
- 데이터 Load와 전처리
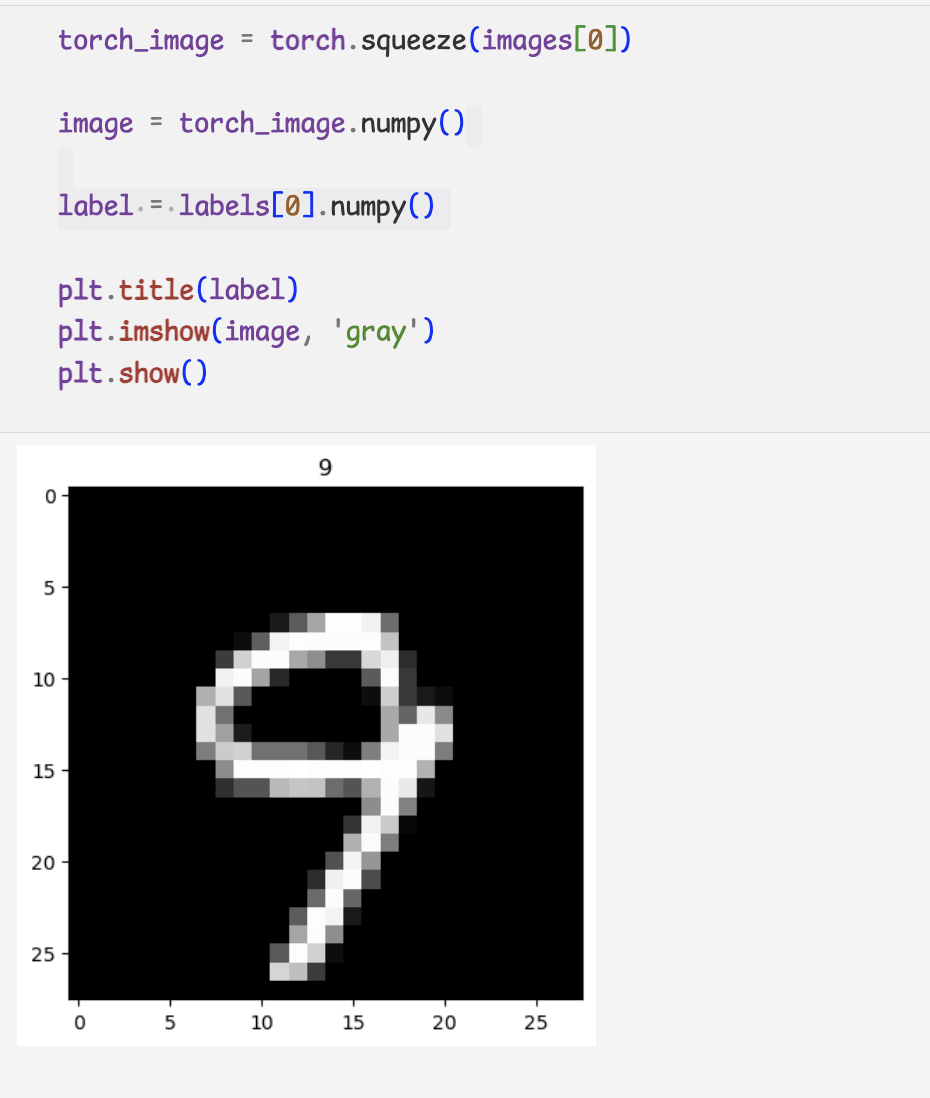
- 데이터 확인
PyTorch에서는 TF와 이미지를 표현하는데 있어서 차이점이 있음.
-TF - (batch, height, width, channel)
-PyTorch - (batch, channel, height, width)
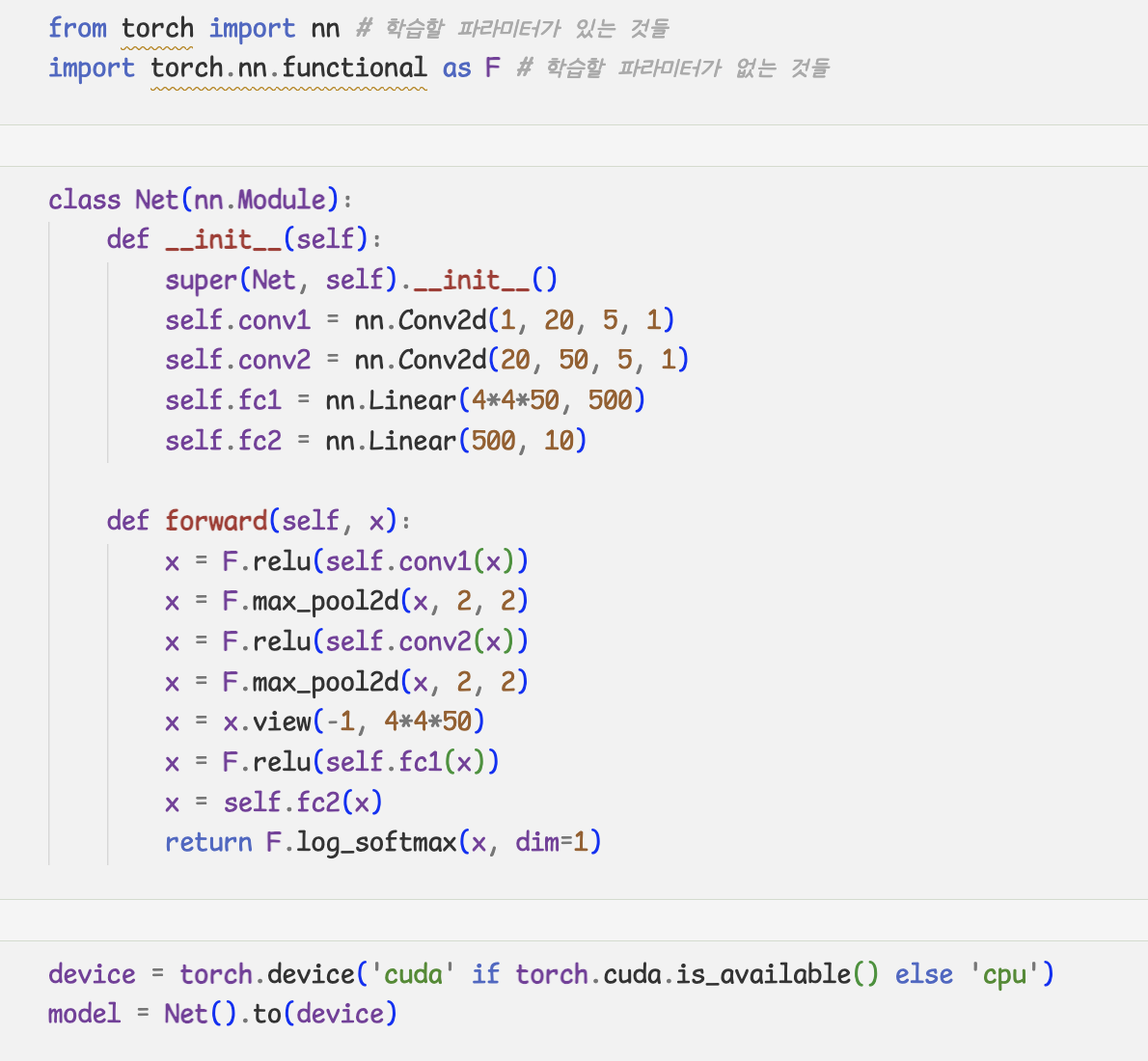
- 모델 정의
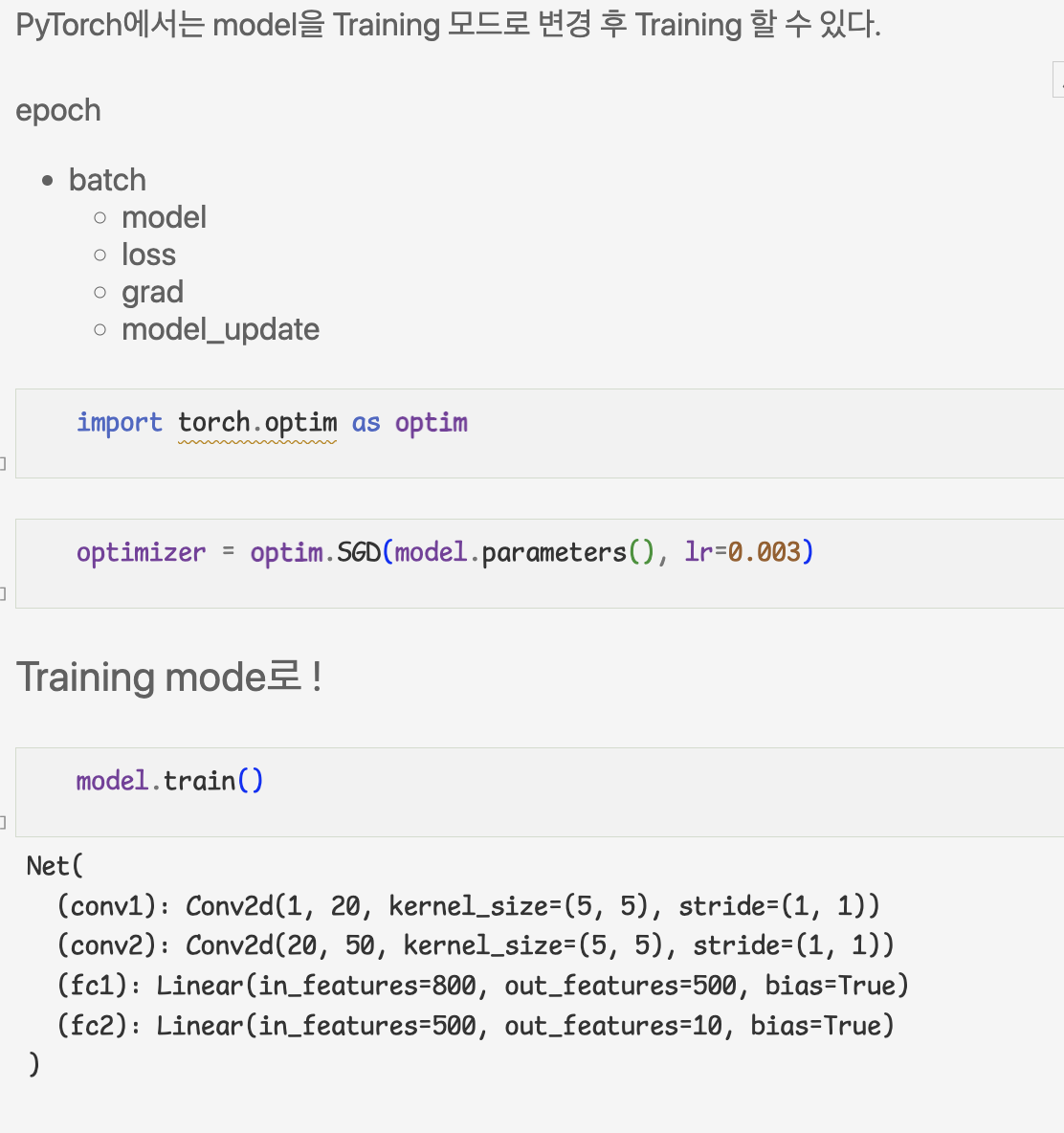
- 학습 로직
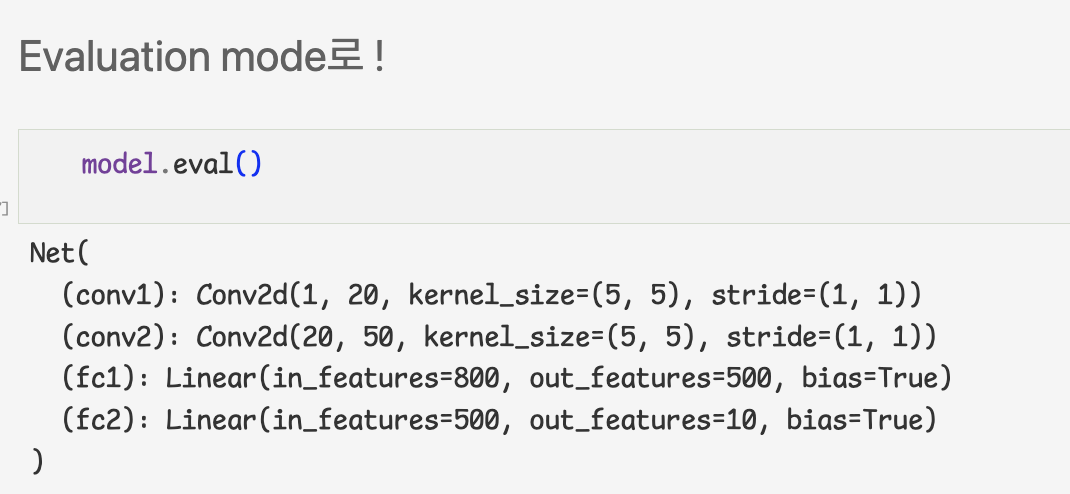
- Evaluation
-autograd engine, 즉 backpropagatin이나 gradient 계산 등을 꺼서 memory usage를 줄이고 속도를 높임



6.Modeling
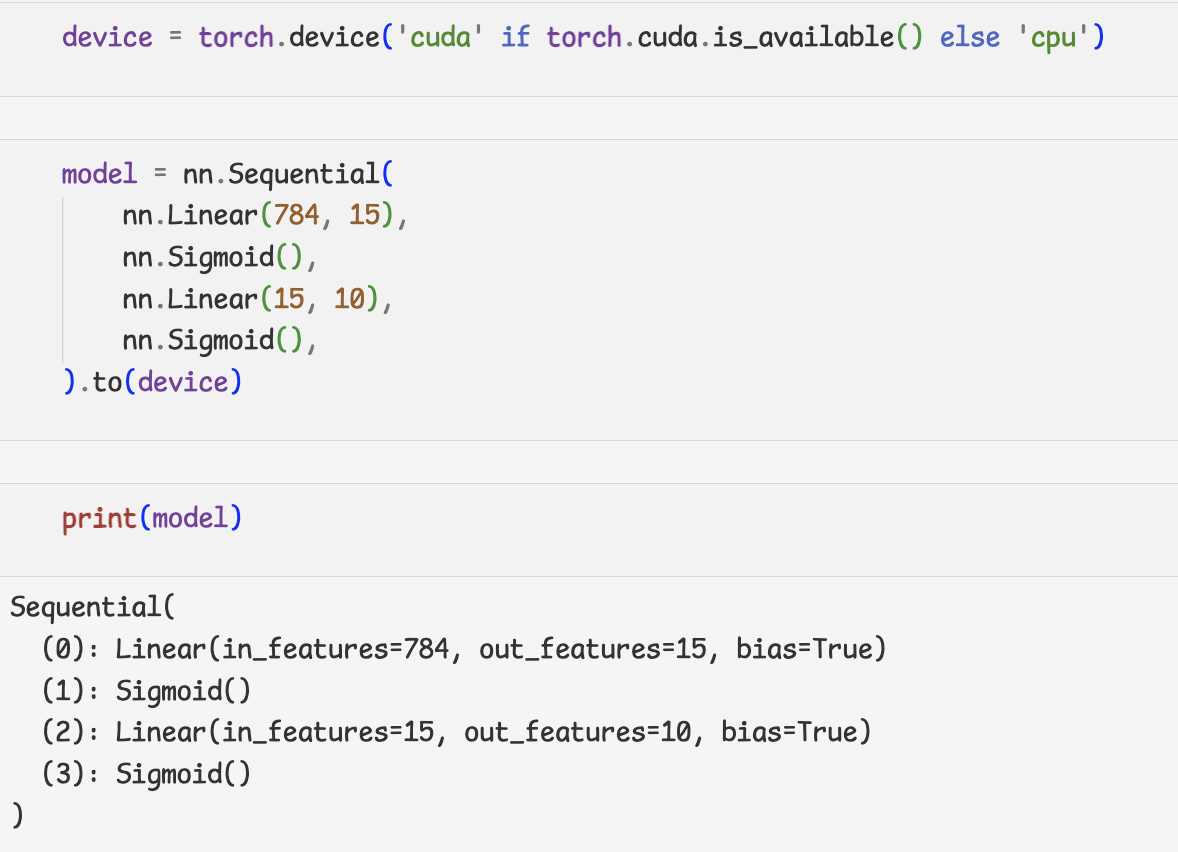
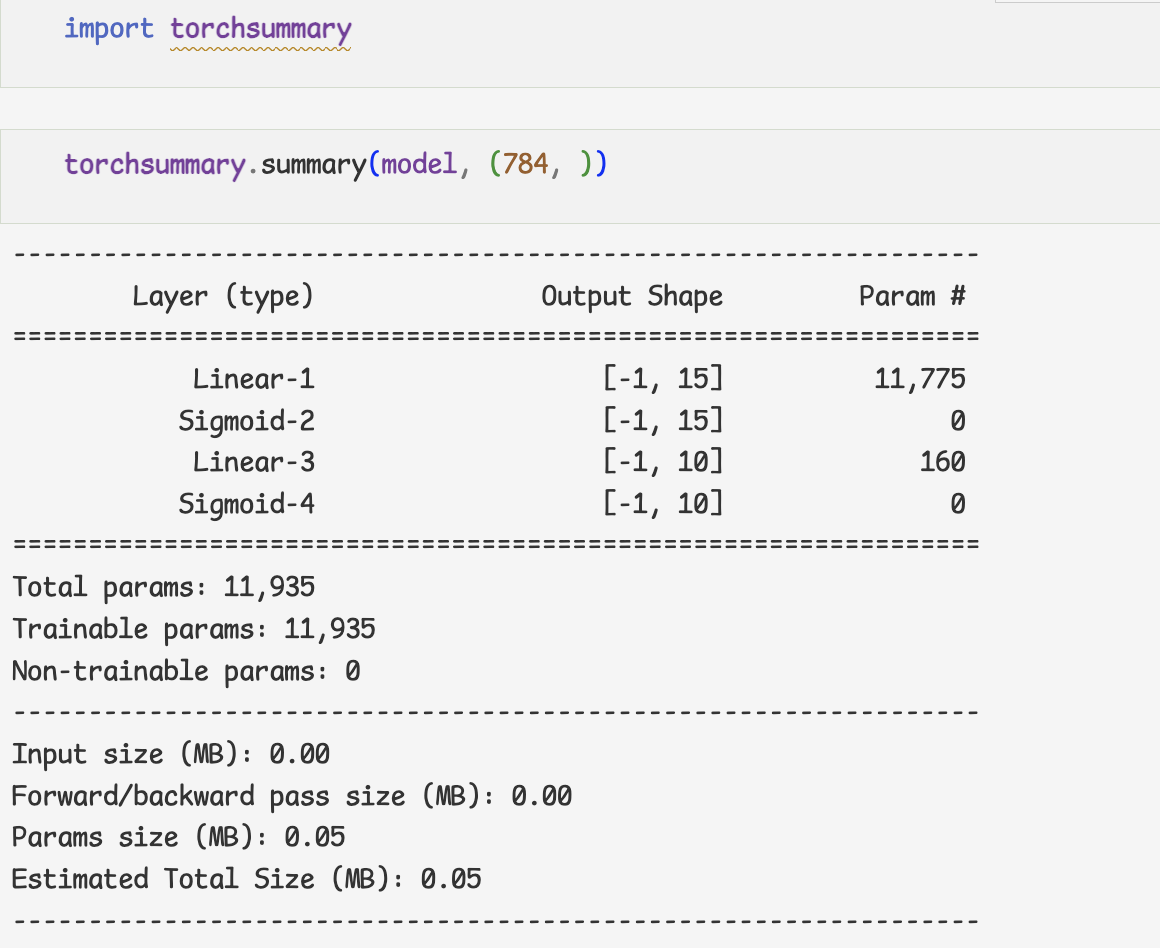
- nn.Sequential
- Sub-class of nn.Module
- nn의 모듈
- nn.Sequential
- nn.Moudle sub class
-init()에서 Layers를 초기화 함
-forward함수를 구현
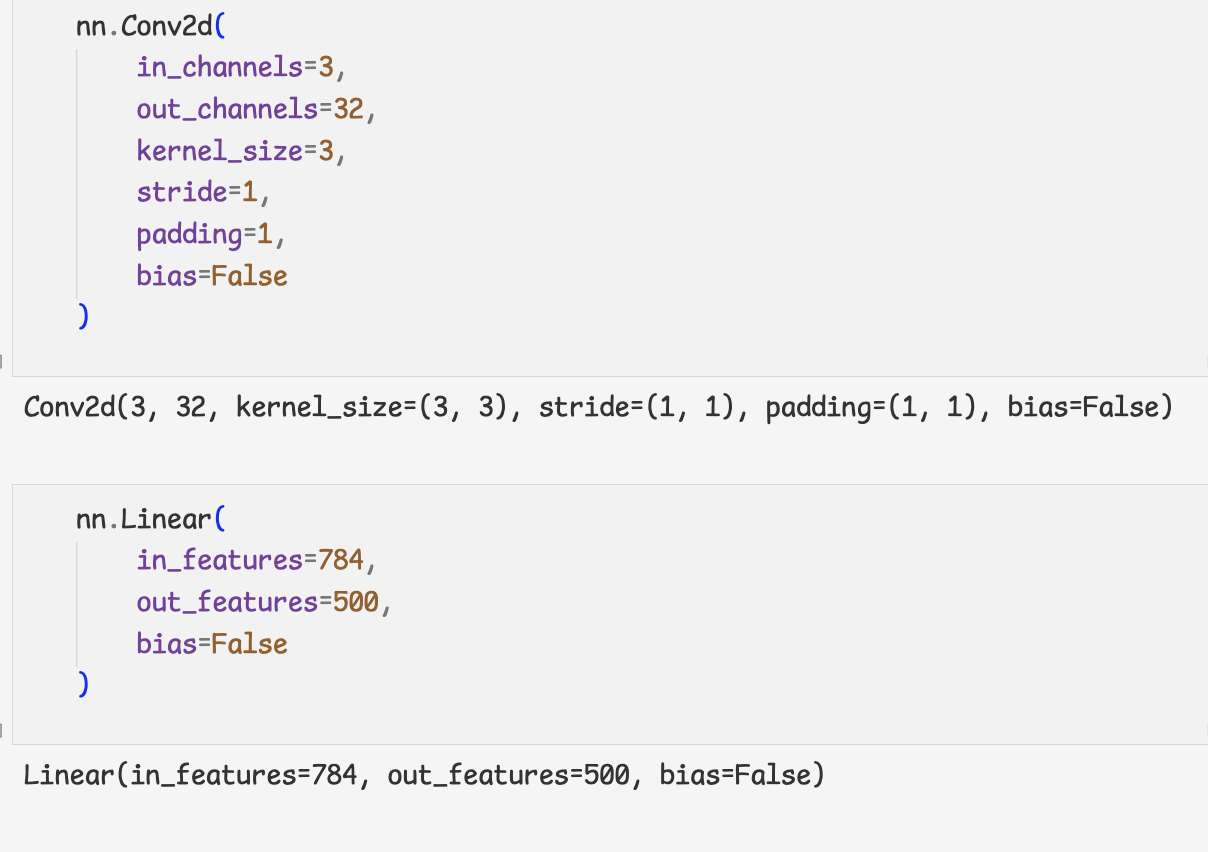
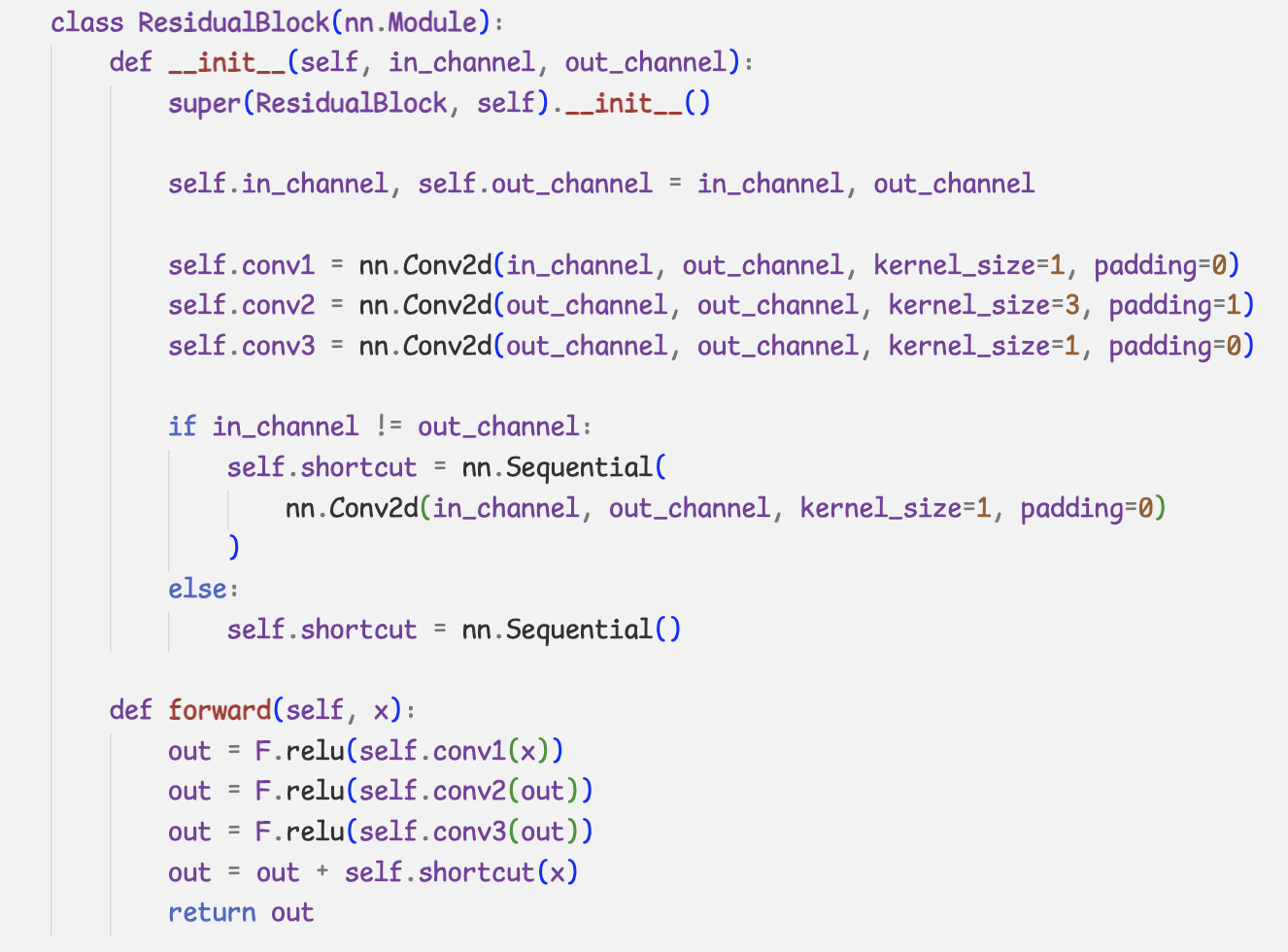
- 간단한 ResNet 구현


7.training
- learning rate scheduler
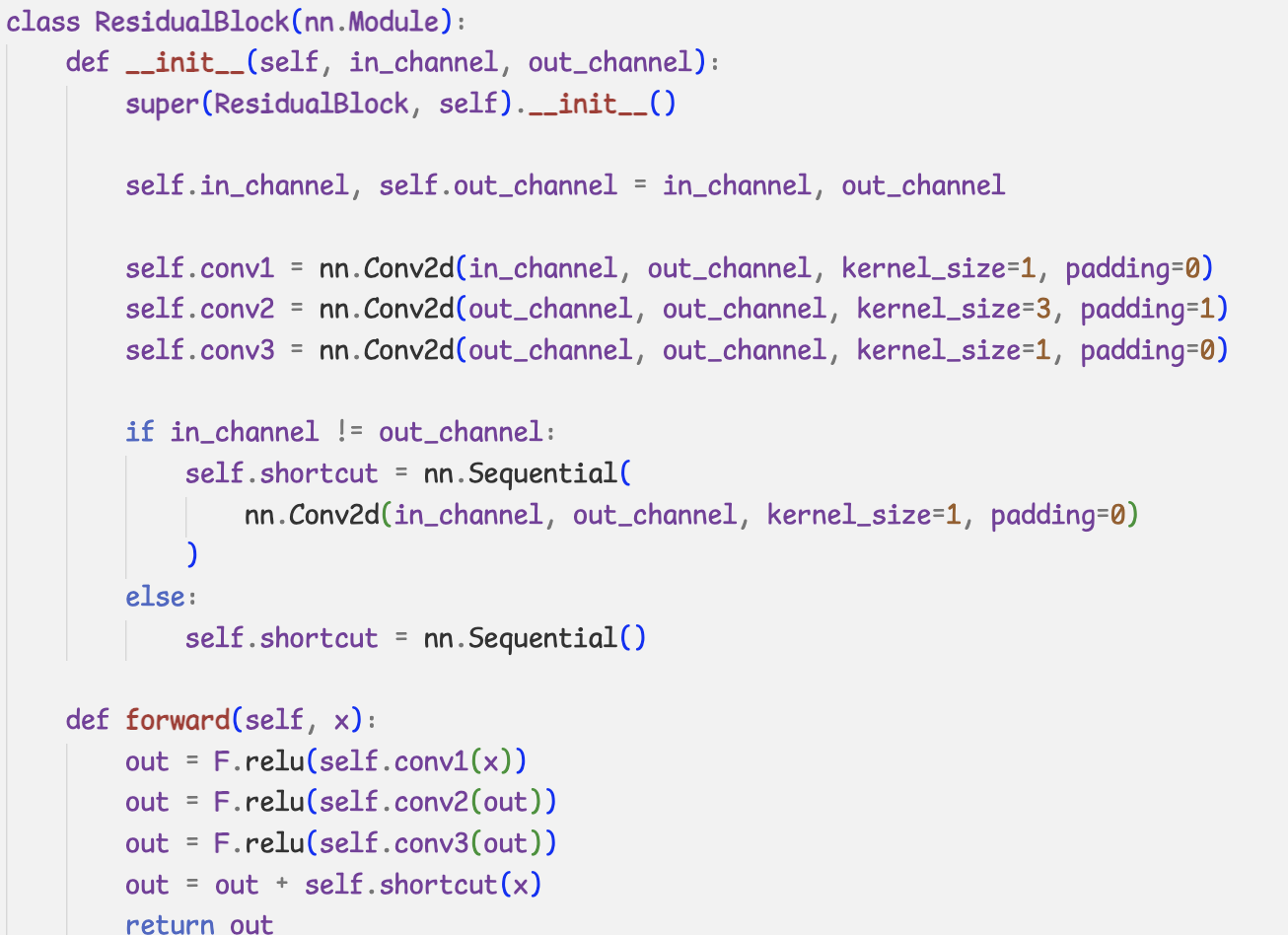


8.model save
class ResidualBlock(nn.Module):
def __init__(self, in_channel, out_channel):
super(ResidualBlock, self).__init__()
>
self.in_channel, self.out_channel = in_channel, out_channel
>
self.conv1 = nn.Conv2d(in_channel, out_channel, kernel_size=1, padding=0)
self.conv2 = nn.Conv2d(out_channel, out_channel, kernel_size=3, padding=1)
self.conv3 = nn.Conv2d(out_channel, out_channel, kernel_size=1, padding=0)
>
if in_channel != out_channel:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channel, out_channel, kernel_size=1, padding=0)
)
else:
self.shortcut = nn.Sequential()
>
def forward(self, x):
out = F.relu(self.conv1(x))
out = F.relu(self.conv2(out))
out = F.relu(self.conv3(out))
out = out + self.shortcut(x)
return out
>
class ResNet(nn.Module):
def __init__(self, color='gray'):
super(ResNet, self).__init__()
if color == "gray":
self.conv1 = nn.Conv2d(1, 32, kernel_size=3, stride=1, padding=1)
elif color == "rgb":
self.conv1 = nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1)
>
self.resblock1 = ResidualBlock(32, 64)
self.resblock2 = ResidualBlock(64, 64)
>
self.avgpool = nn.AdaptiveAvgPool2d((1,1))
self.fc1 = nn.Linear(64, 64)
self.fc2 = nn.Linear(64, 10)
>
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.max_pool2d(x, 2, 2)
x = self.resblock1(x)
x = self.resblock2(x)
x = self.avgpool(x)
x = torch.flatten(x,1)
x = F.relu(self.fc1(x))
x = self.fc2(x)
x = F.log_softmax(x, dim=1)
return x
model=ResNet().to(device)
- weight만 저장
- 구조도 함께 저장


27_Custom dataset
28_Transforms
9.ImageFolder
-간단하게 로컬에 있는 이미지 데이터셋을 불러옴
-디렉토리 구조가 다음과 같아야 함

10.Custom dataset


11.Transforms