[빅데이터를 지탱하는 기술]을 읽고- 2.빅데이터의 탐색

2.빅데이터의 탐색
2-1.크로스 집계의 기본
- 크로스 테이블
행과 열이 교차하는 부분에 숫자 데이터가 들어간다.- 트랜잭션 테이블
행 방향으로만 증가하고,열 방향으로는 데이터를 증가시키지 않도록 해야 한다.
=> 트랜잭션 테이블에서 크로스 테이블로 변환하는 과정을
크로스 집계라고 한다.
2-2. 열지향 스토리지에 의한 고속화
| 데이터베이스의 지연을 줄이기
3계층의 데이터 집계 시스템
원 데이터는 용량적인 제약이 적어서 대량의 데이터를 처리할 수 있는 '데이터 레이크'와 '데이터 웨어하우스'에 저장 => 원하는 데이터를 추출하여 데이터 마트를 구축하고 여기에서는 항상 초단위의 응답을 얻을 수 있도록 한다.데이터 처리의 지연
지연이 적은 데이터 마트 작성을 위한 기초 지식
- 데이터 마트를 만들 때는 가급적 지연이 적은 데이터베이스가 있어야 한다. - 가장 간단한 방법은 모든 데이터를 메모리에 올리는 것 ex)MySQL이나 PostgreSQL등의 일반적인 RDB가 적합 - RDB는 원래 지연이 적고,많은 클라이언트가 동시 접속해도 성능이 나빠지지 않으므로,데이터 마트로 특히 우수하다. 반면,메모리가 부족하면 급격히 성능이 저하된다.'압축'과 '분산'에 의한 지연 줄이기 - MPP 기술
- 데이터를 가능한 한 작게 압축하고 그것을 여러 디스크에 분산함으로써,데이터의 로드에 따른 지연을 줄인다.
- 분산된 데이터를 읽어 들이려면 멀티 코어를 활용하면서
디스크 I/O를 병렬 처리하는 것이 효과적이다.
=> 이러한 아키텍쳐는MPP(대규모 병렬 처리)
=> 대량 데이터 분석을 위해 데이터베이스에서 널리 사용
ex) Amazone Redshift 및 Google Bigquery등
- MPP의 특징
1.데이터의 집계에 최적화 되어 있다.
2.데이터 웨어하우스와 데이터 분석용의 데이터베이스에서 특히 많이 사용
| 열 지향 데이터베이스 접근
- 데이터 압축을 고려한 후
열 지향개념을 알아야 한다.
- 일반 데이터베이스는 레코드 단위의 읽고 쓰기에 최적화됨
=> 이를행 지향 데이터베이스라고 부른다.
ex)Oracle Database MySQL과 같은 일반적인 RDB

- 데이터 분석에 사용되는 데이터베이스는
칼럼 단위의 집계에 최적화되어 있으며,
이를열 지향 데이터베이스또는
칼럼 지향 데이터베이스라고 한다.
ex) Teradata와 Amazone Redshift등
행 지향 데이터 베이스
- 테이블의 각 행을 하나의 덩어리로 디스크에 저장한다.
- 새 레코드를 추가 할때 빠르게 추가 할 수 있다.
- 매일 발생하는 대량의 트랜잭션을 지연 없이 처리하기 위해 데이터 추가를 효율적으로 할 수 있도록 하는 것이 특징
- 행 지향 데이터베이스에서는 데이터 검색을 고속화하기 위해
인덱스를 만든다.
열 지향 데이터 베이스
- 데이터 분석에서는 종종 일부 칼럼만이 집계 대상이 된다.
행 지향 데이터베이스에서는 레코드 단위로
데이터가 저장되어 있으므로,
필요 없는 열까지 디스크로부터 로드된다.=> 필요한 컬럼만을 로드하여 디스크 I/O를 줄인다.
- 데이터의 압축 효율도 우수하다.
특히,같은 문자열의 반복은 매우 작게 압축할 수 있다.MPP 데이터베이스의 접근 방식
aㅋㅁㅇㄹㄴㅇㄹaaa- 쿼리 지연을 줄일 방법은
MPP아키텍쳐에 의한
데이터 처리의 병렬화다.1.행 지향 데이터베이스 보통 하나의 쿼리는 하나의 스레드에서 실행 =>많은 쿼리를 동시에 실행함으로써 여러개의 cpu코어를 활용할 수 있지만, 개별 쿼리가 분산 처리되는 것은 아니다. 2.열 지향 데이터베이스 대량의 데이터를 읽기 때문에 1번의 쿼리 실행 시간이 길어진다. =>압축된 데이터의 전개 등으로 CPU리소스를 필요로 하므로, 멀티 코어를 활용하여 고속화하는 것이 좋다. 3.MPP에서는 하나의 쿼리를 다수의 작은 테스크로 분해하고, 이를 가능한 한 병렬로 실행한다.MPP 데이터베이스와 대화형 쿼리 엔진
- MPP를 사용한 데이터의 집계는 CPU코어 수에 비례하여 고속화된다.
단, 디스크로부터의 로드가 병목 현상이 발생하지 않도록
데이터가 고르게 분산되어 있어야 한다.
- MPP는 고속화를 위해 CPU와 디스크 모두를 균형 있게 늘려야 한다.
=> 일부 제품은 하드웨어와 소프트웨어가 통합된 제품으로 제공된다.=> 따라서, 하드웨어 수준에서 데이터 집계에 최적화된 데이터베이스를
MPP 데이터베이스라고 한다.2-4.데이터 마트의 기본 구조
| 시각화에 적합한 데이터 마트 만들기-OLAP
다차원 모델과 OLAP 큐브
- OLAP
1.데이터 집계를 효율화하는 접근 방법 중의 하나.
2.다차원 모델의 데이터 구조를MDX등의 쿼리 언어로 집계
=> 데이터 분석을 위해 만들어진 다차원 데이터를
OLAP 큐브라고 부르며,
그것을 크로스 집계하는 구조가OLAP이다.| 테이블을 비정규화하기
데이터베이스의 설계에서는 종종 테이블을
마스터와트랜잭션으로 구분한다.
- 트랜잭션
시간과 함께 생성되는 데이터를 기록한 것- 마스터
트랜잭션에서 참고되는 각종 정보=> 트랜잭션은 한번 기록하면 변화하지 않지만,
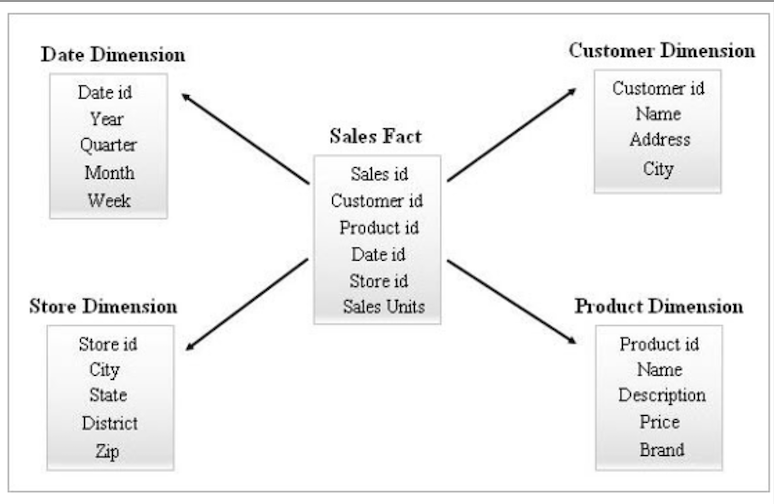
마스터는 상황에 따라 다시 쓰인다.팩트 테이블과 디멘전 테이블
팩트 테이블
데이터 웨어하우스의 세계에서는
트랜잭션처럼 사실이 기록된 것디멘전 테이블
팩트 테이블에서 참고되는 마스터 데이터등=> 숫자 데이터등은
팩트 테이블에 기록
디멘젼 테이블은 데이터를 분류하기 위한 속성값으로 사용스타 스키마와 비정규화
팩트 테이블을 중심으로 여러 디멘전 테이블을 결합
데이터 마트를 만들때는 팩트 테이블을 중심으로 여러 디멘전 테이블을 결합하는 것이 좋다. => 이를 '스타 스키마'라고 부른다. 디멘전 테이블을 작성하려면 정규화에 의해 분해된 테이블을 최대한 결합하여 하나의 테이블로 정리한다. => 그 결과로 데이터가 중복되어도 괜찮다. => 이를 '비정규화'라고 한다.
- 데이터 마트에서
스타 스키마가 사용되는 이유
1.단순하므로 이해가 쉽고,데이터 분석을 쉽게 할 수 있다.
2.성능상의 이유이다.팩트 테이블을 될 수 있는 한 작게 하는 것이 고속화에 있어 중요하며, 팩트 테이블에는 ID와 같은 키만을 남겨두고 나머지는 디멘전 테이블로 옮긴다.비정규화 테이블 -데이터 마트에는 정규화는 필요 없다.
- 스타 스키마에서 좀 더 비정규화를 진행해 모든 테이블을 결합한 팩트 테이블을
비정규화 테이블이라고 부른다.
=> 데이터 마트는 비정규화 테이블로 하는 것이 가장 단순하고,효율적인 방법이다.| 다차원 모델 시각화에 대비하여 테이블을 추상화하기
비정규화 테이블을 준비했다면 그것을
다차원 모델에 의해 추상화한다.
- 다차원 모델
1.'디멘전'과 '측정값'으로 분류한다.
2.숫자 데이터와 그 집계 방법을 정의하는 것 =>측정값
3.크로스 집계에 있어서 행과 열을 이용하는 것 =>디멘전