빅 데이터란,
대용량 데이터를 활용, 분석하여 가치있는 정보를 추출하고
생성된 지식을 바탕으로 능동적으로 대응하거나 변화를 예측하기 위한 정보화 기술이다.
빅 데이터의 5V
- Volume (용량)
- 기업이 관리하고 분석하는 빅 데이터 크기와 양 - Velocity (속도)
- 회사가 데이터를 수신, 저장 및 관리하는 속도
ex) 특정 기간 내에 수신된 특정 소셜 미디어 게시물 또는 검색 쿼리 수 - Variety (다양성)
- 비정형 데이터, 반정형 데이터 및 원시 데이터를 포함하는 다양한 데이터 유형
ex) 스마트폰, 사내 장치, SNS 채팅 프로그램, 주식 시세 데이터 및 금융 거래 데이터 - Veracity (진실성)
- 경영진들의 신뢰도에 영향을 미치는 데이터 및 정보 자신의 진실 또는 정확성 - Value (가치)
- 비즈니스 관점에서 가장 중요한 'V'인 빅 데이터의 가치는 일반적으로 보다 효과적인 운영, 더 강력한 고객 관계 및 기타 명확하고 수량화 가능한 비즈니스 이점으로 이어지는 통찰력 발견 및 패턴 인식에서 나옴
빅데이터 기술
Hadoop & NoSQL
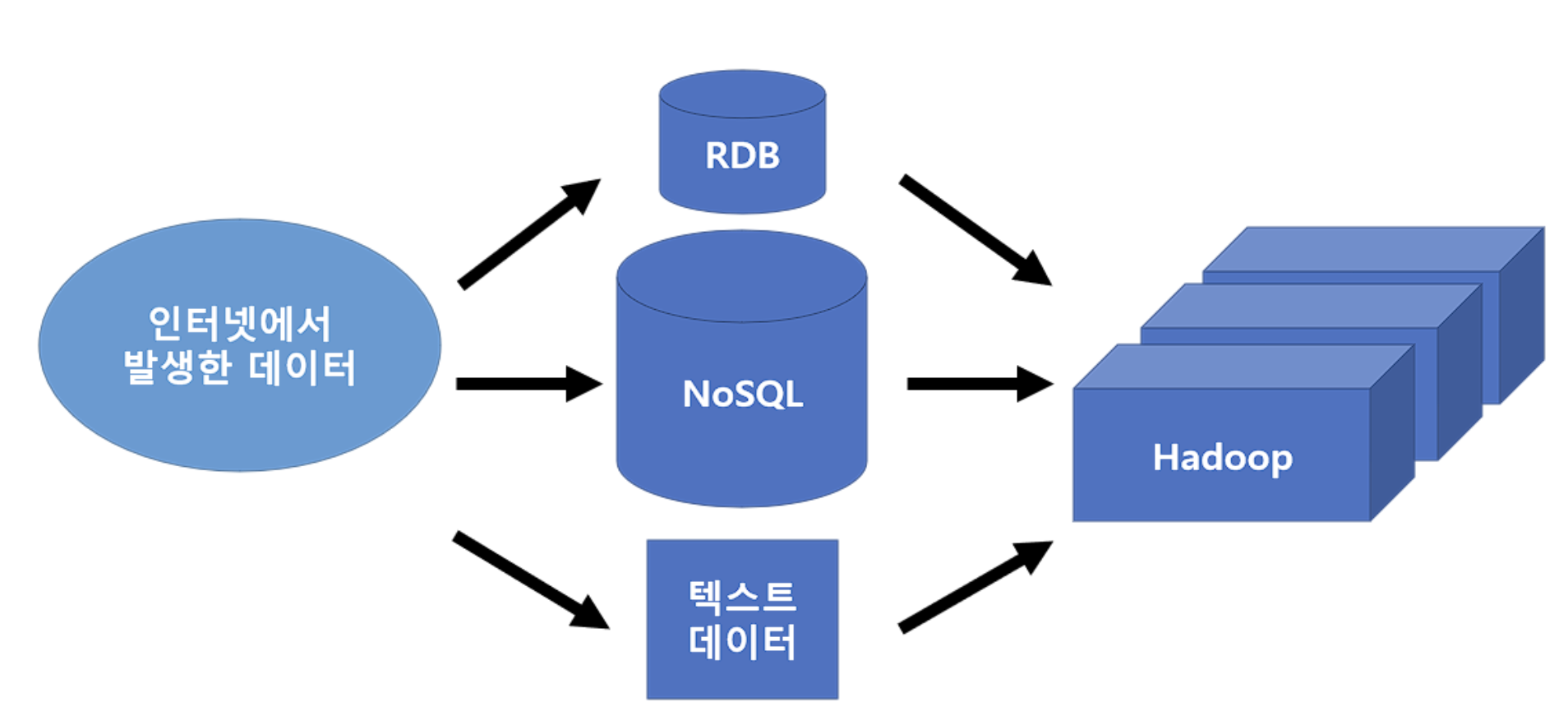
웹 서버에서 생성된 데이터는 RDB나 NoSQL에 텍스트 데이터 형태로 저장되고,
그 후 모든 데이터가 Hadoop에 모여서 대규모 데이터처리가 실행된다.
Hadoop
다수의 컴퓨터로 대량의 데이터를 처리하기 위한 시스템
방대한 데이터를 저장할 스토리지와 이를 순차적으로 처리할 수 있는 구조가 필요해 !
→ 이를 가능하게 해주는 툴이 Hadoop이고, 구글에서 개발된 분산 처리 프레임워크인 ‘MapReduce’를 기반으로 제작됨
NoSQL
NoSQL은 기존의 RDB의 정형화된 데이터 형태에서 벗어난 데이터베이스의 총칭을 의미한다.
대표적인 3가지는 Key-Value, Document, wide-column 이다.
- Key-value: 문자 그대로 키값 밸류값이 한쌍으로 저장되어지는 데이터 베이스
- Document: Json과 같은 복잡한 데이터 구조를 저장
- Wide-column: 여러 키를 사용하여 확장성에 장점이 있는 데이터베이스
ETL 파이프라인
ETL은 Extraction Transform Loading의 약자로,
데이터를 추출하고 가공한 뒤 적재하는 일련의 과정을 의미한다.
하기 그림은 추출한 데이터를 데이터 웨어하우스에 저장하기까지의 과정이다.
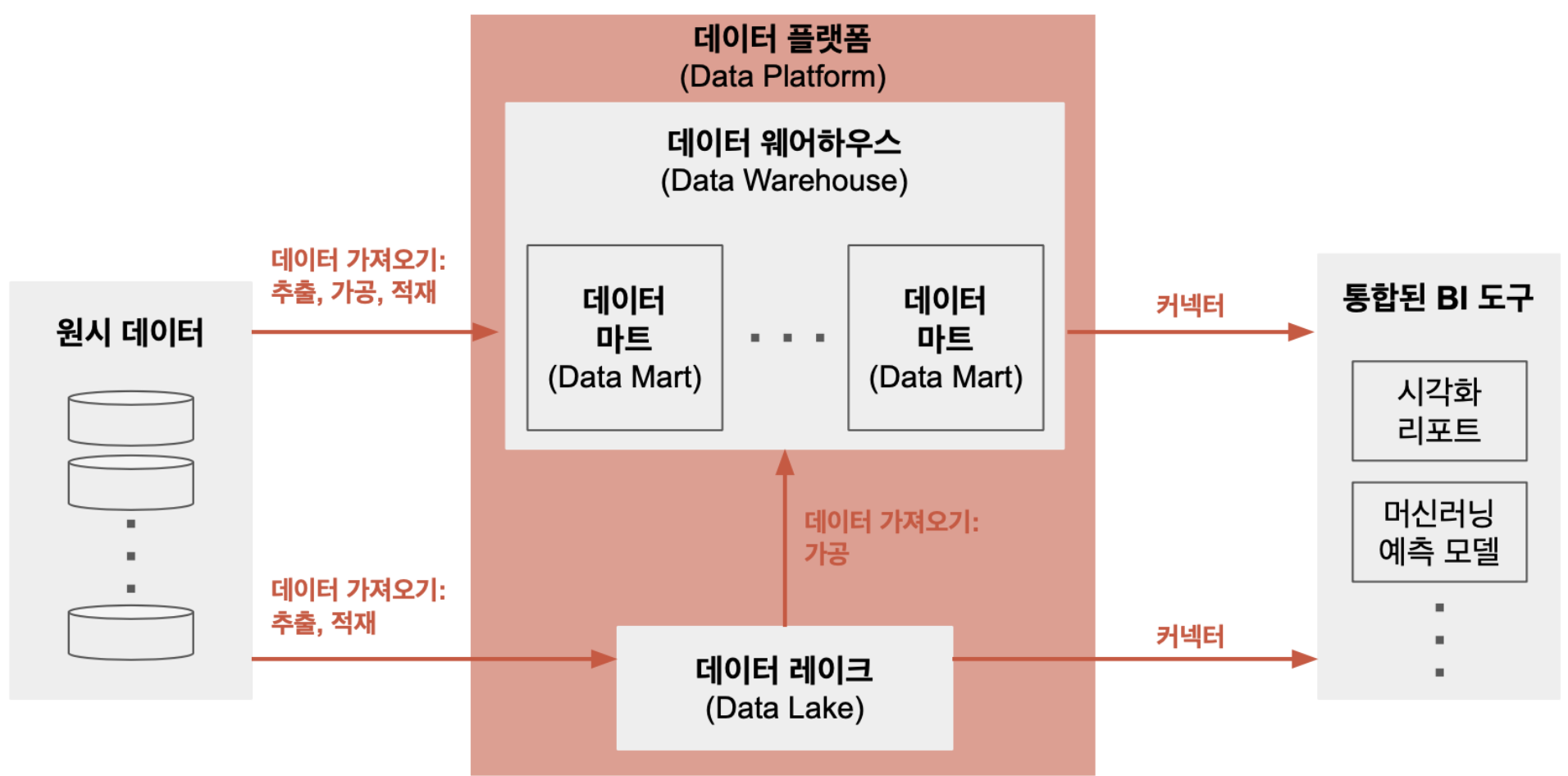
데이터 레이크 (Data Lake)
: 다양한 형태와 경로에서 생성된 데이터를 한 곳에 가공 없이 그대로 저장하는 것
ex) 아마존 - S3
데이터 가져오기 (Data Ingestion)
: 데이터를 활용할 수 있는 형태로 저장하는 과정 (=전처리 과정)
데이터 웨어하우스 (Data Warehouse)
: '데이터 가져오기'가 완료된 데이터를 저장하는 장소
ex) 아마존 - Redshift / 구글 - BigQuery / IBM - Db2
데이터 마트 (Data Mart)
: '데이터 웨어하우스'의 하위 영역
데이터를 실제로 사용하는 부서의 레벨이나 관련 주제 위주로 접근할 수 있도록 가공한 시스템
커넥터 (Connector)
: '데이터 웨어하우스'의 데이터가 각 사용처로 흘러들어가 다양한 용도로 사용될 수 있도록 DB와 각종 어플리케이션을 연결하는 과정
ex) 실시간으로 품절된 상품을 고객이 구매하지 못하도록 표시하는 데에 사용
BI (Business Intelligence)
: 데이터를 정리하고 분석해, 비스니스 의사결정을 돕는 시각화 기술
빅 데이터 실행
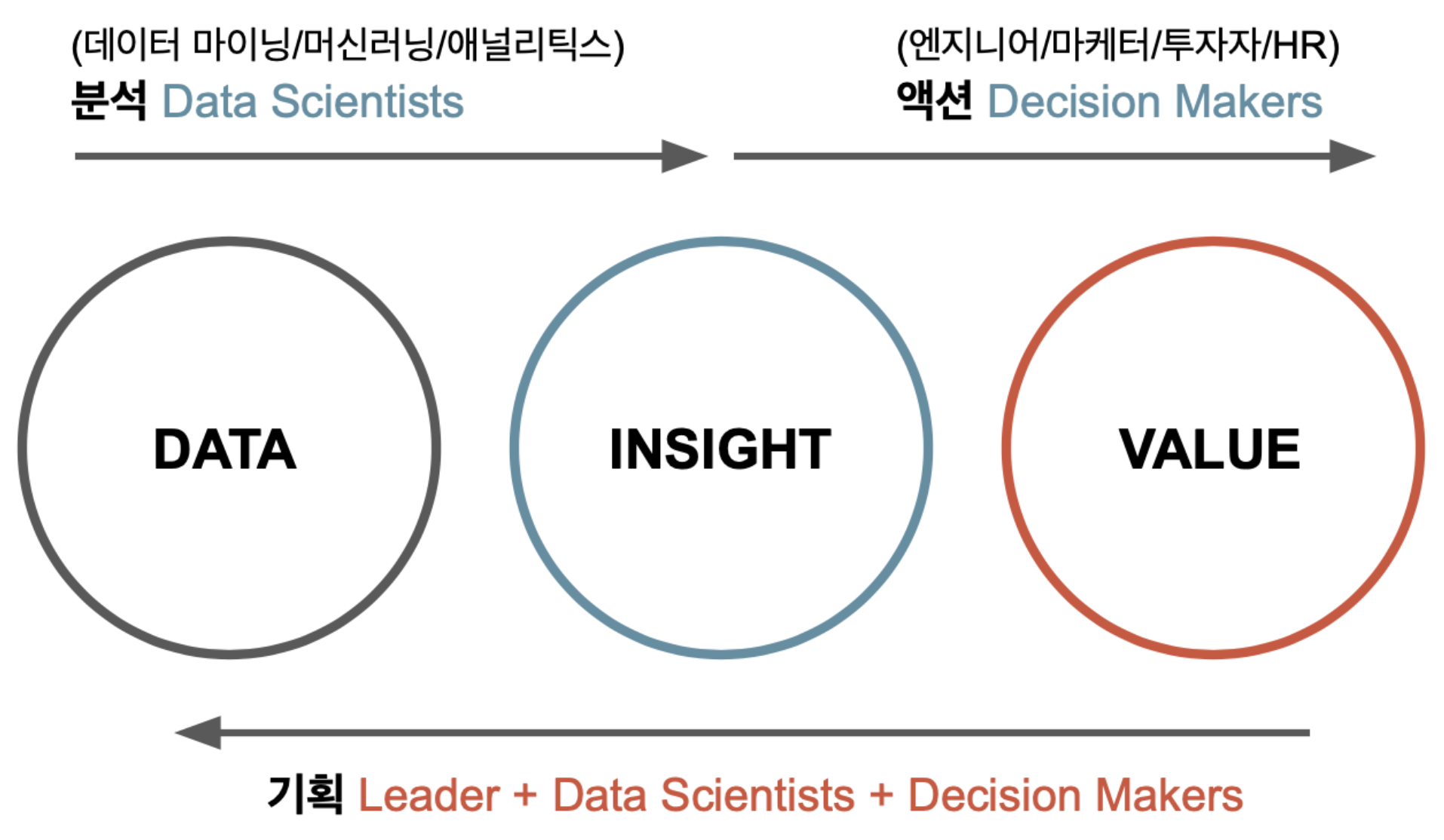
Data에서 Insight를 도출하여 Value를 창출해내는 일련의 과정을 의미한다.
즉, 데이터에서 사업적 가치를 창출하는 것을 말한다.
ex) 아마존 - 고객의 구매정보를 이용한 고객 추천 서비스 제작 -> 매출 40% 향상
