딥러닝이란?
머신러닝의 한 종류로, 연속된 층을 깊게 쌓아 학습을 하는 방식을 말한다. 보통 신경망이라는 용어로도 쓰인다. 대표적인 블랙박스 모델이다.
기존 머신러닝의 경우, 인간이 직접 특성을 선택하여 예측값을 출력했는데 딥러닝의 경우 다량의 데이터를 기반으로 인공지능이 스스로 특징을 도출하여 예측값을 출력한다.

이 말은 무엇이냐 하면, 정형 데이터 뿐 아니라 비정형 데이터도 다룰 수 있다는 말이다. 예를 들어 내가 고양이와 강아지를 분류하는 작업을 한다고 했을 때 정형 데이터로 머신러닝을 돌리려면
| 귀 | 꼬리 구부러짐 | 무늬 |
|---|---|---|
| 접힘 | o | 줄무늬 |
| 서있음 | x | 얼룩 |
| 서있음 | x | 없음 |
이런 식으로 데이터를 넣어 주어야 했다면, 딥러닝에서는 그냥 냅다 고양이와 강아지 사진 수천장을 때려박으면 모델이 알아서 피처를 찾아서 예측을 해 준다는 뜻이다!
인공 신경망
그러나 우선 익숙한 정형 데이터로 인공 신경망을 이해해 보자. 패션 MNIST 데이터를 이용한다.
from tensorflow import keras
(train_input, train_target), (test_input, test_target) = keras.datasets.fashion_mnist.load_data()
print(train_input.shape, train_target.shape)
print(test_input.shape, test_target.shape)(60000, 28, 28) (60000,)
(10000, 28, 28) (10000,)
이 데이터는 60000개의 train 데이터셋과 10000개의 test데이터셋으로 구성되어 있으며, 각 이미지는 28x28 크기이다.
또 이 문제는 다중 분류로, 타깃 클래스는 10 개가 있다.
이 문제를 인공신경망으로 그림을 그려 보면,
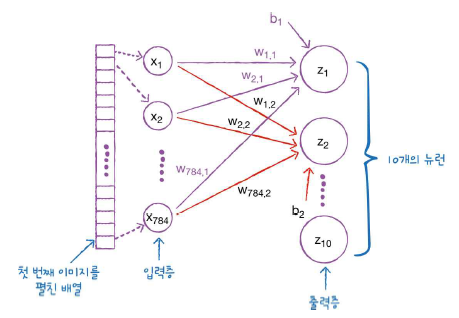
이렇게 된다.
저 첫 번째 이미지를 펼친 배열 : 각 픽셀갯수만큼 특성이라고 생각하면 된다. 28x28 =784이므로 784개가 된다.
그럼 이 특성을 입력층에 넣어 준다. 특성을 입력시켜 주는 것이다.
그에 따라 모델이 돌아가면서 예측을 하기 위해 가중치(a.k.a 파라미터)를 열심히 계산할 것이다. 그게 바로 저 w들이다. 저 가중치들은 각각 클래스에 대해 전부 계산된다.
저 출력층의 노드들은 타깃 클래스의 갯수만큼이다. 그러니 패션 MNIST의 경우에는, 10개.
10개를 계산하고 이를 바탕으로 클래스를 예측하기 때문에 신경망의 최종 값을 만든다는 의미에서 출력층이라고 부른다. (계산된 파라미터를 출력)
이 그림에서는 생략되었지만, 저 가중치들의 선이 밀집되어 있는 층은 굉장히 빽빽하기 때문에 밀집층(Dense layer) 이라고 부른다.
여기선 784(입력층의 노드 갯수)X10(출력층의 노드 갯수)일테니 7840개의 선이 있겠다!
케라스의 Dense 클래스를 사용해 밀집층을 만들어 보면,
dense = keras.layers.Dense(10, activation='softmax', input_shape=(784,))코드를 뜯어보면,
10 : 뉴런의 갯수 (출력층 노드의 개수)
activation = 활성화함수 종류. 여기서는 다중분류이므로 softmax를 사용
input_shape : 입력층의 크기
가 되겠다!
그럼 밀집층은 만들었으니, 이 밀집층을 사용하는 모델을 만드는 코드는 다음과 같다.
model = keras.Sequential(dense)신경망 모델을 만들어따!
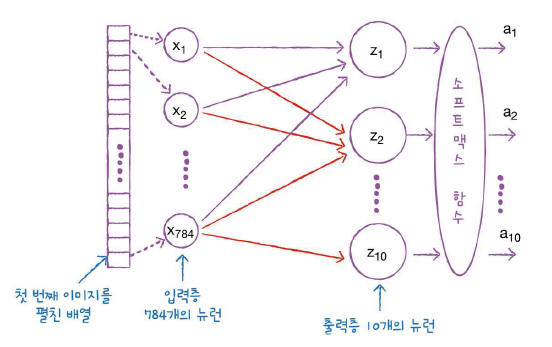
데이터 전처리
모델을 돌리기에 앞서, 데이터를 전처리 해줘야 할 것이 있다.
특성마다 값의 범위가 다르면 손실 함수의 경사를 올바르게 내려갈 수 없으므로 정규화를 해 주고, (이 데이터셋의 경우 각 픽셀은 0~255 사이의 정수값을 가지므로 255로 나눠준다.)
2차원 배열인 각 샘플을 1차원 배열로 펼쳐 줘야 한다.
train_scaled = train_input / 255.0
train_scaled = train_scaled.reshape(-1, 28*28)
print(train_scaled.shape)(60000, 784)
그러면, 784개의 픽셀을 가진 60000개의 데이터가 만들어졌다.
그리고 또,
딥러닝에서는 교차 검증 대신 train 세트에서 세트를 덜어내서 검증을 한다. 왜냐하면
1. 딥러닝 분야의 데이터셋은 충분히 크기 때문에 검증 점수가 안정적이고,
2. 교차 검증을 수행하면 훈련 시간이 너무 오래 걸린다.
따라서,
from sklearn.model_selection import train_test_split
train_scaled, val_scaled, train_target, val_target = train_test_split(
train_scaled, train_target, test_size=0.2, random_state=42)이 코드를 이용해 훈련 세트에서 20%를 검증 세트로 떼어냈다.
모델 다듬기
케라스 모델은 훈련하기 전에 설정값을 지정해 주는 단계가 있다. 바로 compile 단계다. 여기서 손실 함수의 종류와 측정값을 지정해 준다.
model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy')-
다중 분류 문제이기 때문에 categorical crossentropy 함수를 사용한다.
-
이진 분류의 경우 정답값이 0과 1로 구분이 되기 때문에 하나의 노드만으로도 양성 클래스에 대한 확률(a,이 사진이 강아지일 확률)과 음성 클래스에 대한 확률(1-a, 이 사진이 고양이일 확률)을 모두 구할 수 있었다.
하지만 다중 분류에서의 크로스 엔트로피는?
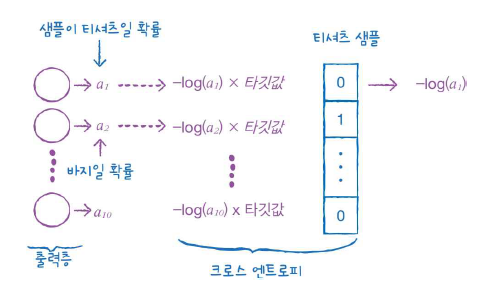
이진 분류와 달리 각 클래스에 대한 확률이 모두 출력되기 때문에 타깃에 해당하는 확률만 남겨놓기 위해 나머지 확률에는 모두 0을 곱해준다.
결국 신경망은 손실을 낮추기 위해 정답값의 확률을 가능한 1에 가깝게 만들게 된다.
이런 식으로 정답값만 1, 나머지는 0인 배열을 원핫 인코딩이라고 하는데, 다중분류에서 크로스엔트로피를 사용하려면 타깃값이 원핫인코딩 되어 있어야 한다. -
Q. 하지만 우리 타겟 데이터셋은 원핫인코딩 아니고 1,2,3,...9중 하난데?
A. 그래서 그걸 그냥 사용할 수 있게 해 주는 것이 sparse_categorical_crossentropy 함수이다.
-
-
그럼 metrics는 무엇인가.
- 케라스는 모델이 훈련할 때 기본으로 에포크마다 손실 값을 출력해 준다. 손실이 줄어드는 것을 보고 훈련이 잘 되었다는 것을 알 수 있지만 정확도도 함께 출력해 주면 더 좋을 것이다. 그를 위해 metrics에 정확도인 accuracy를 넣어 준 것이다.
준비는 끝났다! 입력값과 타깃값을 넣고, 훈련할 횟수를 에포크에 넣어주자.
model.fit(train_scaled, train_target, epochs=5)실행을 해 보면, 정확도가 85%를 넘는다! 나쁘지 않다. 그럼 검증 세트로 모델의 성능을 확인해 보자.
model.evaluate(val_scaled, val_target)0.8483333587646484
좋다!
출처 : 혼자 공부하는 머신러닝 (책)
