[ pandas의 cut과 qcut의 차이 ] p285
- 절대평가(cut)와 상대평가(qcut)의 의미와 비슷합니다.
- 절대평가는 특정 점수 이상일 경우에 성적을 부여하는 것이고,
- 상대평가는 인원수에 따라 상위 몇 %인지에 따라 성적이 부여됩니다.
- cut의 경우 특정 점수가 부여되고 그 점수를 경계로 성적이 부여되고,
- qcut의 경우 상위 퍼센트가 부여되고 그 퍼센트를 경계로 성적이 부여됩니다.
- pd.cut() 함수와 pd.cut() 함수를 이용하여
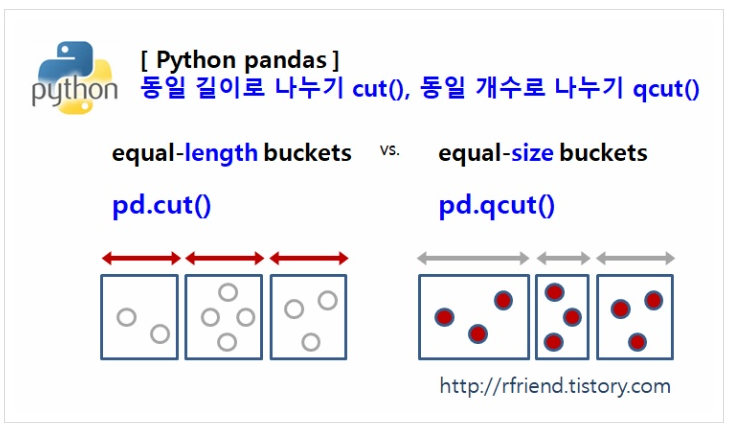
수치형 변수를 특정 구간으로 나눈 범주형 레이블을 생성할 수 있다.- 위 함수들을 이용하여 특정 구간들에 대한 그룹별 통계량을 구하는 것이 가능해진다.
-
cut 함수의 사용방법은 [데이터, 구간의 갯수, 레이블명] 에 해당하는 인자값을 지정해주는 것이다.
-
qcut 함수는 cut 함수와 다르게 동일한 길이로 구간을 나누는 개념이 아닌 동일한 갯수로 구간을 나누는 함수이다.
[ get_dummies() ] p291
- 머신러닝에서 문자로 된 데이터는 모델링이 되지 않는 경우가 있다.
- 대표적으로 회귀분석은 숫자로 이루어진 데이터만 입력을 해야한다.
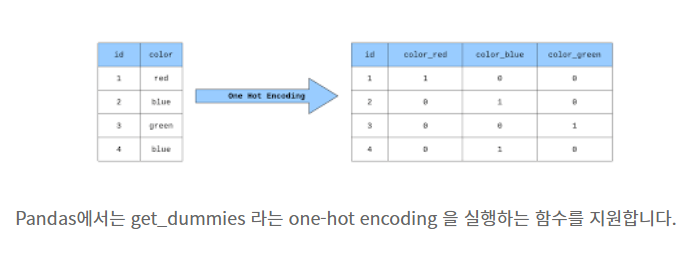
- 문자를 숫자로 바꾸어 주는 방법 중 하나로 One-Hot Encoding이 있다.
- 가변수(dummy variable)로 만들어주는 것인데, 이는 0과 1로만 이루어진 열을 생성하는 것이다.
- 이때 1은 있다, 0은 없다를 나타낸다.

[ 문자열 포함 확인 str.contains() ] p303
파이썬 DataFrame에 저장한 데이터에 문자열이 검색 문자열이 포함되어 있는지 판단하는 방법을 알아보겠습니다.
pandas.Series 문자열 메서드인 str.contains()를 사용하면 지정한 문자열이 포함되어 있는지 확인할 수 있습니다.
검색 문자열이 포함되어 있는 경우에는 True를 반환합니다.
- 문자열이 포함된 행은 True를 반환하고 문자열이 포함되지 않은 행은 False를 반환했습니다.
[ pandas의 stack과 unstack의 차이 ] p309
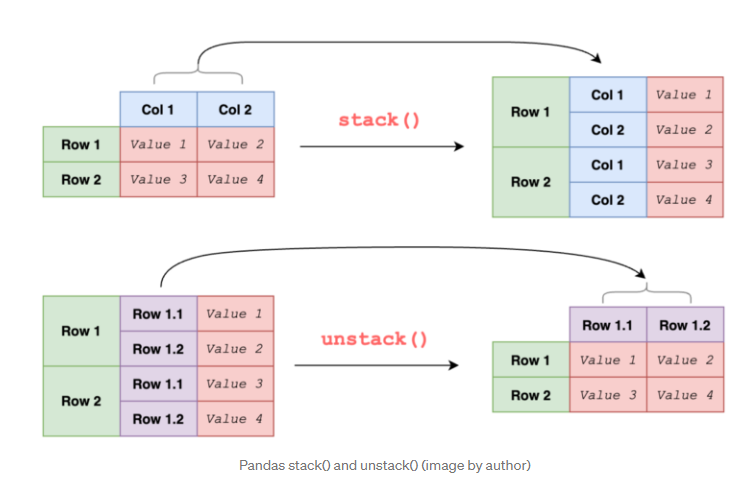
- stack은 위 아래로 키가 크고 unstack은 옆으로 뚱뚱해진다!
- stack과 unstack은 블록을 쌓고, 분해하는 것과 비슷합니다.
-
stack행의 개수 * 컬럼의 수
stack에는 dropna라는 파라미터가 True로 설정되기 때문인데요.
Nan값은 기본적으로 drop하도록 설정되어 있습니다. -
unstack은 반대로 행의 인덱스를 컬럼으로 보내는 겁니다!
unstack에는 dropna 메소드가 없습니다.
대신, fill_value=0를 사용하면 unstack으로 인해 nan이 된 값들을 채워줍니다.
[ pandas의 concat과 merge과 join의 차이 ] p329
다수의 데이터프레임(dataframe) 또는 시리즈(Series)를 결합하거나 key값을 활용해 매칭하는 방법에 대해 알아보자.
데이터를 다루면서 아마 가장 기본적이고 많이 사용하게 될 부분이고, 데이터프레임의 구조에 대한 이해가 필수적이다.
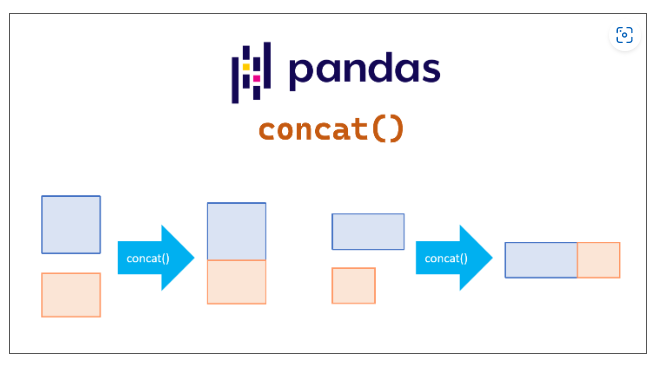
- 데이터 프레임 붙이기 : pd.concat()
pd.concat()함수는 데이터프레임을 말그대로 물리적으로 이어 붙여주는 함수로,
pd.concat(데이터프레임리스트)로 사용한다.
axis=0이 적용되기 때문에 행방향(위아래)으로 데이터프레임을 이어붙인다.
열이 없으면 NaN값이 채워진다.
열방향axis=1(좌우)으로 이어붙여보자.
pd.concat()함수는 또한 default로 outer를 가진다.
이어붙이는 방식을 outer는 합집합, inner는 교집합을 의미한다.
- 데이터프레임 병합 : pd.merge()
merge()함수는 두 데이터프레임을 각 데이터에 존재하는 고유값(key)을 기준으로 병합할때 사용한다.
pd.merge(df_left, df_right, how='inner', on=None)이 default이다.
아무 옵션을 적용하지 않으면, on=None이므로 두 데이터의 공통 열이름(id)을 기준으로 inner(교집합) 조인을 하게 된다
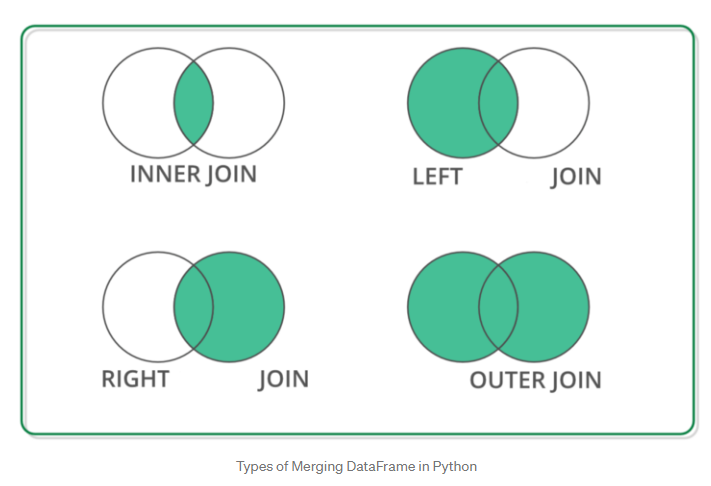
- 3 .데이터프레임 결합 : join()
join함수는 merge()함수를 기반으로 만들어졌기 때문에 기본 작동방식이 비슷하다.
하지만 join()은 행 인덱스를 기준으로 결합한다는 점에서 차이가 있다. 그래도 이 함수도 on=keys 옵션이 존재한다.
Dataframe1.join(Dataframe2. how='left')이 default값이다.
[ pandas의 pivot과 melt의 차이 ] p342
데이터 재구조화, 전처리 과정에서 pivot과 함께 melt 함수도 많이 사용된다. 하지만 pivot()과는 반대로 작동함.
-
melt()는 dataframe format을 wide에서 long으로 바꿔주는 함수이다.
그래서 wide_to_long() 메서드와 함께 쓰이기도 한다.
원래 df의 형식이 녹여지고 식별변수(id_variable)을 기준으로 정렬된다고 생각하면 된다.
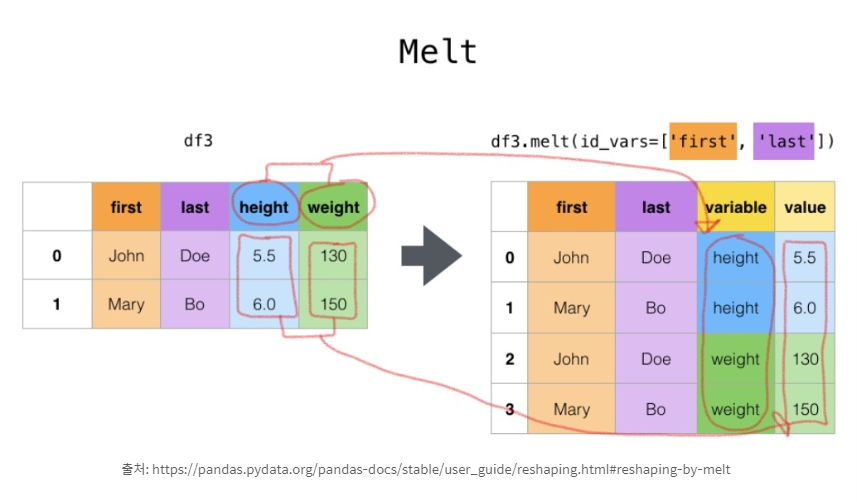
- id_var과 value_vars의 차이
- id_vars는 기준이 되는 칼럼을 지정하는것.(변하지 않는 칼럼)
- value_vars는 녹여서 값과 같이 행으로 들어갈 컬럼을 의미한다.(녹여지는 주인공 칼럼)-
pivot()은 여러 형태로 이루어진 dataframe에 index, columns, values를 각각 지정해주어
melt된 df를 보기 좋은 형태로 재구조화 시켜주는 메서드이다.즉, unmelt의 개념이다.
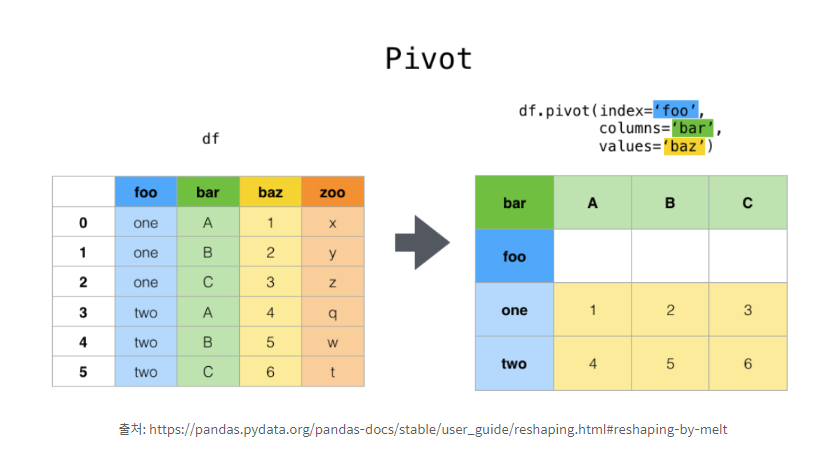
<정리하자면>
pivot()이 인덱스와 행, 열을 하나하나 지정해서 데이터를 재구조화/보기 좋게 구축화하는 것이라면,
melt()는 ID 변수를 하나 혹은 여러 개 지정해서 그것들을 기준으로 나머지 열의 이름과 열 값들을 아래로 쭉 나열하여 재구조화한다.
melt()를 쓰면 얇고 긴 데이터프레임이 만들어 진다.
출처:
https://journey-to-serendipity.tistory.com/9 ->cut
https://kimdingko-world.tistory.com/209 ->cut
https://mizykk.tistory.com/13 -> get_dummies()
https://hongl.tistory.com/89 -> get_dummies()
https://ponyozzang.tistory.com/622 -> str.contains()
https://steadiness-193.tistory.com/22-> split
https://gibles-deepmind.tistory.com/41 ->stack
https://yganalyst.github.io/data_handling/Pd_12/ -> merge
https://jhleeeme.github.io/merging-dataframe-in-pandas/ -> merge
https://koreadatascientist.tistory.com/12 -> id_var
